cassandra es index
1.0.0
<type>Dokumentasi ini menjelaskan penggunaan dan konfigurasi "EsIndex" yang merupakan indeks sekunder berbasis Elasticsearch untuk Cassandra.
Plugin ini membutuhkan kluster Elasticsearch (ES) yang sudah dikonfigurasi.
Plugin akan menginstal dalam rilis Cassandra 4.0.x biasa yang diunduh dari http://cassandra.apache.org/. Tidak ada yang bisa diubah dalam file konfigurasi cassandra untuk mendukung indeks. Perilaku Cassandra tetap tidak berubah untuk aplikasi yang tidak menggunakan indeks.
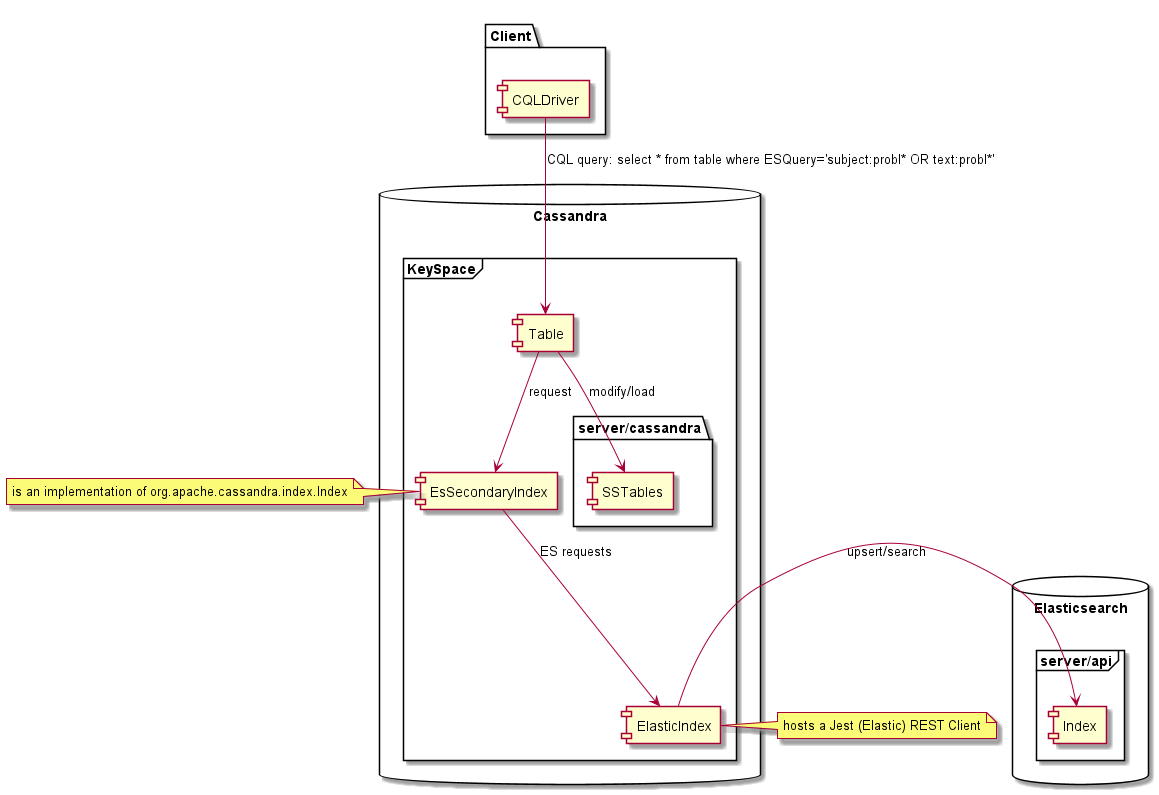
Setelah dibuat pada tabel Cassandra, indeks ini memungkinkan untuk melakukan kueri "pencarian teks lengkap" Elasticsearch di Cassandra menggunakan CQL dan mengembalikan baris pencocokan dari data Cassandra. Penggunaan plugin ini tidak memerlukan mengubah kode sumber Cassandra, kami telah mengimplementasikan indeks Elasticsearch untuk cassandra menggunakan:
Versi yang diuji adalah Elasticsearch 5.x, 6.x, 7.x dan Cassandra 4.0.x. Namun plugin juga dapat bekerja dengan versi Elasticsearch yang berbeda (1.7, 2.x 5.x, 6.x, 7.x) Jika aplikasi menyediakan pemetaan dan opsi yang sesuai. Versi lain dari Apache Cassandra seperti 1.x 2.x, 3.x atau 4.1 tidak didukung sebagai antarmuka indeks sekunder yang digunakan oleh plugin berbeda. Vendor Cassandra lainnya tidak diuji, Scylladb tidak didukung.
| Versi | Elasticsearch 1.x | Elasticsearch 2.x | Elasticsearch 5.x | Elasticsearch 6.x | Elasticsearch 7.x |
|---|---|---|---|---|---|
| Cassandra 1.x | TIDAK | TIDAK | TIDAK | TIDAK | TIDAK |
| Cassandra 2.x | TIDAK | TIDAK | TIDAK | TIDAK | TIDAK |
| Cassandra 3.x | TIDAK | TIDAK | TIDAK | TIDAK | TIDAK |
| Cassandra 4.x | Terbatas | Terbatas | Terbatas | Ya | Ya |
Proyek ini membutuhkan Maven dan kompilasi dengan Java 8. untuk membangun plugin, pada akar proyek dieksekusi:
Paket Bersih MVN
Ini akan membangun "semua dalam satu toples 'di target/distribution/lib4cassandra
<dependency>
<groupId>com.genesyslab</groupId>
<artifactId>es-index</artifactId>
<version>9.2.000.00</version>
</dependency>
Lihat Paket GitHub
Lihat Repositori Maven
Letakkan es-index-9.2.000.xx-jar-with-dependencies.jar di folder lib Cassandra bersama dengan toples Cassandra lainnya, misalnya '/usr/share/cassandra/lib' pada semua node Cassandra. Mulai atau restart simpul Cassandra Anda.
Karena kurangnya pengujian, tabel dengan kunci pengelompokan tidak didukung. Hanya kunci partisi yang didukung, tombol partisi komposit yang harus berfungsi tetapi tidak diuji secara luas.
EsIndex hanya mendukung level baris TTL di mana semua sel akan kedaluwarsa pada saat yang sama dan dokumen ES yang sesuai dapat dihapus pada saat yang sama. Jika baris memiliki sel yang kedaluwarsa pada waktu yang berbeda, dokumen yang sesuai akan dihapus ketika sel terakhir berakhir. Jika menggunakan TTL sel yang berbeda, data yang dikembalikan dari pencarian masih akan konsisten karena data dibaca dari SStables, tetapi masih mungkin untuk menemukan baris menggunakan data yang kadaluwarsa menggunakan kueri ES.
Dimungkinkan untuk membuat beberapa indeks di tabel yang sama, EsIndex tidak akan mencegahnya. Namun jika lebih dari satu EsIndex ada, perilaku tidak konsisten, konfigurasi tersebut tidak didukung. Perintah cqlsh 'menjelaskan tabel <ks.tablename>' dapat digunakan untuk menampilkan indeks yang dibuat di atas tabel dan letakkan jika perlu.
Demi kesederhanaan, buat ruang tombol ini terlebih dahulu:
CREATE KEYSPACE genesys WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1}
Mari kita gunakan tabel di bawah ini sebagai contoh:
CREATE TABLE genesys.emails (
id UUID PRIMARY KEY,
subject text,
body text,
userid int,
query text
);
Anda perlu mendedikasikan kolom teks dummy untuk penggunaan indeks. Kolom ini tidak boleh menerima data. Dalam contoh ini, kolom query adalah kolom dummy.
Berikut adalah cara membuat indeks untuk tabel contoh dan menggunakan Eshost untuk Elasticsearch:
CREATE CUSTOM INDEX ON genesys.emails(query)
USING 'com.genesyslab.webme.commons.index.EsSecondaryIndex'
WITH OPTIONS = {'unicast-hosts': 'eshost:9200'};
Misalnya, jika server Elasticsearch Anda mendengarkan di localhost , ganti Eshost dengan LocalHost .
Kesalahan yang dikembalikan oleh CQL sangat terbatas, jika ada yang salah, seperti tuan rumah Elasticsearch Anda tidak tersedia, Anda akan mendapatkan batas waktu atau pengecualian lain. Anda harus memeriksa log Cassandra untuk memahami apa yang salah.
Kami tidak memberikan pemetaan apa pun sehingga kami mengandalkan pemetaan dinamis Elasticsearch, mari kita masukkan beberapa data:
INSERT INTO genesys.emails (id, subject, body, userid)
VALUES (904b88b2-9c61-4539-952e-c179a3805b22, 'Hello world', 'Cassandra is great, but it''s even better with EsIndex and Elasticsearch', 42);
Anda dapat melihat bahwa indeks sedang dibuat di Elasticsearch jika Anda memiliki akses ke log:
[o.e.c.m.MetaDataCreateIndexService] [node-1] [genesys_emails_index@] creating index, cause [api], templates [], shards [5]/[1], mappings []
[INFO ][o.e.c.m.MetaDataMappingService] [node-1] [genesys_emails_index@/waSGrPvkQvyQoUEiwqKN3w] create_mapping [emails]
Sekarang kita dapat mencari Cassandra menggunakan Elasticsearch melalui indeks, berikut adalah pencarian sintaks Lucene:
select id, subject, body, userid, query from emails where query='body:cassan*';
id | subject | body | userid | query
--------------------------------------+-------------+-------------------------------------------------------------------------+--------+-------
904b88b2-9c61-4539-952e-c179a3805b22 | Hello world | Cassandra is great, but it's even better with EsIndex and Elasticsearch | 42 |
{
"_index": "genesys_emails_index@",
"_type": "emails",
"_id": "904b88b2-9c61-4539-952e-c179a3805b22",
"_score": 0.24257512,
"_source": {
"id": "904b88b2-9c61-4539-952e-c179a3805b22"
},
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.24257512
}
}
(1 rows)
(json diformat)
Semua baris akan berisi data dari Cassandra yang dimuat dari SSTables menggunakan konsistensi CQL. Data di kolom 'Query' adalah metadata yang dikembalikan oleh Elasticsearch.
Berikut adalah cara menanyakan Elasticsearch untuk memeriksa pemetaan yang dihasilkan: GET http://eshost:9200/genesys_emails_index@/emails/_mapping?pretty
{
"genesys_emails_index@" : {
"mappings" : {
"emails" : {
"properties" : {
"IndexationDate" : {
"type" : " date "
},
"_cassandraTtl" : {
"type" : " long "
},
"body" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"id" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"subject" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"userid" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
}
}
}
}
}
}Plugin EsIndex menambahkan dua bidang:
Kita dapat melihat bahwa pemetaan terlihat bagus, tetapi Elasticsearch tidak melihat bahwa UserID adalah integer dan menambahkan bidang [kata kunci] ke semua teks.
Beginilah datanya di Elasticsearch:
GET http://localhost:9200/genesys_emails_index@/emails/_search?pretty&q=body:cassandra
{
"took" : 2 ,
"timed_out" : false ,
"_shards" : {
"total" : 5 ,
"successful" : 5 ,
"skipped" : 0 ,
"failed" : 0
},
"hits" : {
"total" : 1 ,
"max_score" : 0.2876821 ,
"hits" : [
{
"_index" : " genesys_emails_index@ " ,
"_type" : " emails " ,
"_id" : " 904b88b2-9c61-4539-952e-c179a3805b22 " ,
"_score" : 0.2876821 ,
"_source" : {
"id" : " 904b88b2-9c61-4539-952e-c179a3805b22 " ,
"body" : " Cassandra is great, but it's even better with EsIndex and Elasticsearch " ,
"subject" : " Hello world " ,
"userid" : " 42 " ,
"IndexationDate" : " 2019-01-15T16:53:00.107Z " ,
"_cassandraTtl" : 2147483647
}
}
]
}
} Mari kita perbaiki pemetaan dengan menjatuhkan indeks: drop index genesys.emails_query_idx; Ini juga akan menjatuhkan indeks dan data Elasticsearch!
dan membuatnya kembali dengan pemetaan yang tepat:
CREATE CUSTOM INDEX ON genesys.emails(query)
USING 'com.genesyslab.webme.commons.index.EsSecondaryIndex'
WITH OPTIONS = {
'unicast-hosts': 'localhost:9200',
'mapping-emails': '
{
"emails":{
"date_detection":false,
"numeric_detection":false,
"properties":{
"id":{
"type":"keyword"
},
"userid":{
"type":"long"
},
"subject":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"body":{
"type":"text"
},
"IndexationDate":{
"type":"date",
"format":"yyyy-MM-dd''T''HH:mm:ss.SSS''Z''"
},
"_cassandraTtl":{
"type":"long"
}
}
}
}
'};
Ini akan membuat indeks baru akan memberikan pemetaan dan reindex data yang ada di Cassandra.
Inilah pemetaan ES yang dihasilkan:
{
"genesys_emails_index@" : {
"mappings" : {
"emails" : {
"date_detection" : false ,
"numeric_detection" : false ,
"properties" : {
"IndexationDate" : {
"type" : " date " ,
"format" : " yyyy-MM-dd'T'HH:mm:ss.SSS'Z' "
},
"_cassandraTtl" : {
"type" : " long "
},
"body" : {
"type" : " text "
},
"id" : {
"type" : " keyword "
},
"subject" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"userid" : {
"type" : " long "
}
}
}
}
}
}Sekarang setelah pemetaan didefinisikan dengan benar, kami dapat mencari UserID sebagai angka. Dalam contoh ini kami menggunakan DSL Query Elasticsearch:
select id, subject, body, userid from genesys.emails
where query='{"query":{"range":{"userid":{"gte":10,"lte":50}}}}';
@ Row 1
---------+-------------------------------------------------------------------------
id | 904b88b2-9c61-4539-952e-c179a3805b22
subject | Hello world
body | Cassandra is great, but it's even better with EsIndex and Elasticsearch
userid | 42
Sangat penting untuk mendapatkan pemetaan yang tepat sebelum memulai produksi. Reindexing Tabel besar akan memakan banyak waktu dan akan menempatkan beban signifikan pada Cassandra dan Elasticsearch. Anda harus memeriksa log Cassandra untuk kesalahan dalam pemetaan ES Anda. Pastikan untuk menghindari kutipan tunggal (') dengan menggandakannya dalam opsi JSON yang disediakan untuk perintah CREATE INDEX.
Di bawah ini adalah semua opsi yang terkait dengan konfigurasi Indeks Elasticsearch. Nama-nama kunci dapat menggunakan tanda hubung '-' char, atau titik-titik. Misalnya kedua nama akan berfungsi:
Perhatikan bahwa semua opsi di bawah ini khusus untuk implementasi Genesys dan bukan Elasticsearch sendiri.
Jika kelas Jest tidak ditemukan, mode dummy diaktifkan dan tidak ada kasus lain yang berlaku.
Multi-Datacenter didukung dan data direplikasi hanya melalui replikasi gosip Cassandra. ES Clusters pada DC yang berbeda tidak sama dan tidak boleh bergabung bersama atau kinerja akan terpengaruh. Karena data direplikasi pada tingkat tabel, EsIndex akan mendapatkan pembaruan di setiap DC dan kluster ES lokal akan diperbarui juga.
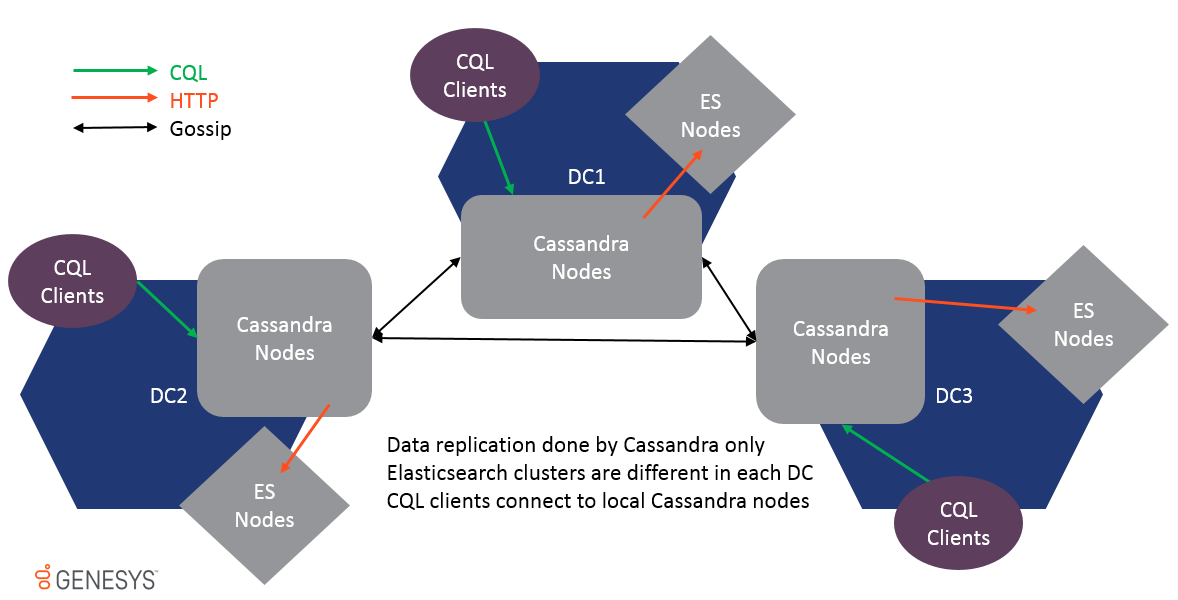
Untuk mendukung multi-DC, semua opsi dapat diawali dengan pusat data dan nama rak untuk membuat pengaturan lokasi spesifik, misalnya:
Untuk memberikan indeks Cassandra untuk Elasticsearch dengan kredensial, setiap node harus memiliki escredential variabel lingkungan dengan benar ditetapkan sebelum memulai. Ini harus ditetapkan pada semua host Cassandra.
Contoh di bawah ini memberikan kata sandi untuk karakter 'elastis' dan kata sandi 'exampsword' yang dipisahkan oleh: (Colon) karakter. Ini dapat dilakukan baik secara langsung dalam sistem sebagai variabel lingkungan atau di jalan pintas yang meluncurkan Cassandra.
Escredentials = elastis: examplePassword Setelah indeks berhasil diinisialisasi, itu akan menulis "kredensial elasticsearch yang disediakan" dalam log cassandra di tingkat info. Setelah pesan ini output dimungkinkan untuk menghapus variabel lingkungan. Jika Cassandra memulai kembali variabel lingkungan harus diatur lagi sebelum memulai. Kredensial disimpan hanya dalam memori dan tidak disimpan di tempat lain. Jika pengguna dan/atau kata sandi diubah, semua node Cassandra harus dimulai kembali dengan nilai variabel lingkungan yang diperbarui.
Di set opsi indeks
unicast-hosts = https : //<host name>:9200
Saat ini tidak mungkin untuk memigrasikan indeks yang ada dari HTTP ke HTTPS, penggunaan satu atau yang lain harus diputuskan sebelum Anda membuat skema Cassandra. Untuk memudahkan penyebaran HTTPS, indeks akan secara otomatis mempercayai semua sertifikat HTTPS.
Dimungkinkan untuk menyimpan data di sisi Elasticsearch untuk waktu yang lebih lama daripada Cassandra TTL yang ditentukan. Mode ini diputar menggunakan opsi mode ES-analitik. Ketika opsi diaktifkan elasticIndex akan melewatkan semua operasi hapus.
Untuk menjaga data agar tidak tumbuh terlalu banyak di sisi ES, disarankan untuk menggunakan pengaturan TTL-shift dan force-delete.
Saat membuat indeks, Anda akan menyediakan opsi indeks, serta opsi indeks Elasticsearch menggunakan perintah 'menggunakan opsi' CQL.
Opsi indeks harus ditentukan pada pembuatan indeks, berikut adalah contoh
CREATE CUSTOM INDEX on genesys.email(query) using 'com.genesyslab.webme.commons.index.EsSecondaryIndex' WITH options =
{
'read-consistency-level':'QUORUM',
'insert-only':'false',
'index-properties': '{
"index.analysis.analyzer.dashless.tokenizer":"dash-ex",
"index.analysis.tokenizer.dash-ex.pattern":"[^\\w\\-]",
"index.analysis.tokenizer.dash-ex.type":"pattern"
}',
'mapping-email': '{
"email": {
"dynamic": "false",
"properties": {
"subject" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}',
'discard-nulls':'false',
'async-search':'true',
'async-write':'false'
};
Anda juga dapat mengatur atau mengganti opsi menggunakan variabel lingkungan atau properti sistem Java dengan opsi awalan dengan 'Genesys-ES-'.
Opsi yang disediakan dalam perintah "Buat Indeks Kustom" digunakan terlebih dahulu. Mereka dapat ditimpa secara lokal menggunakan file bernama ES-Index.properties yang ditemukan di ".", "./Conf/", "../conf/" atau "./bin/". (Dapat diubah dengan -Dgenesys-es-esi-file atau -dgenesys.es.esi.file System Properti)
Berikut adalah contoh untuk konten file:
insert-only = true Discard-nulls = false async-write = false
| Nama | Bawaan | Keterangan |
|---|---|---|
| Max-Hasil | 10000 | Jumlah hasil yang harus dibaca dari pencarian ES untuk memuat baris Cassandra. |
| level baca-konsistensi | SATU | Digunakan untuk pencarian, tingkat konsistensi ini digunakan untuk memuat baris cassandra. |
| masukkan saja | PALSU | Secara default EsIndex akan menggunakan operasi Upsert. Dalam Sisipkan Data Mode Hanya akan selalu ditimpa. |
| async-write | BENAR | Mengirim pembaruan indeks secara asinkron tanpa memeriksa eksekusi yang benar. Ini memberikan penulisan yang jauh lebih cepat tetapi data mungkin menjadi tidak konsisten jika ES Cluster tidak tersedia, karena penulisan tidak akan gagal. Default itu benar. |
| segmen | MATI | Mati, jam, hari, bulan, tahun, segmentasi indeks otomatis khusus dikendalikan oleh pengaturan ini. Jika diatur ke hari, setiap hari indeks baru akan dibuat di bawah alias. Perhatikan bahwa indeks kosong dihapus secara otomatis setiap jam. Catatan: Pengaturan jam tidak disarankan karena akan membuat banyak indeks dan dapat mengurangi kinerja. Pengaturan ini disarankan untuk tujuan pengembangan dan pengujian. |
| nama segmen | Jika segmen = kustom nilai ini akan digunakan untuk pembuatan indeks baru. | |
| Pemetaan- <eype> | {} | Untuk setiap indeks sekunder, nama tabel dilewatkan sebagai jenis, misalnya pemetaan-visit = {JSON definisi}. |
| HOSTS UNICAST | http: // localhost: 9200 | Daftar host yang dipisahkan koma, dapat host1, host2, host3 atau http: // host1, http: // host2, http: // host3 atau http: // host1: 9200, http: // host2: 9200, http: // host3: 9200. Jika protokol atau port hilang HTTP dan 9200 diasumsikan. Dimungkinkan untuk menggunakan HTTPS. |
| Buang-nulls | BENAR | Jangan meneruskan nilai nol ke indeks ES, itu berarti Anda tidak akan dapat menghapus nilai. Default itu benar . |
| Indeks-Properti | {} | Properti sebagai string JSON, diteruskan untuk membuat indeks baru, dapat berisi definisi tokenizer misalnya. |
| JSON-Serialized-Fields | {} | String yang dipisahkan koma yang mendefinisikan bahwa kolom string harus diindeks sebagai string JSON. String parsable non-JSON akan mencegah sisipan di Cassandra. |
| ladang json-flat-serialized | {} | String yang dipisahkan koma yang menentukan bahwa kolom string harus diindeks sebagai dokumen JSON jenis-aman. Pemetaan Elasticsearch JSON tidak memungkinkan untuk mengindeks nilai yang akan mengubah tipe dari waktu ke waktu. Misalnya {"key": "value"} tidak dapat menjadi {"key": {"subkey": "value"}} Dalam penelitian elasticsech Anda akan mendapatkan pengecualian pemetaan. JSON-flat seperti itu akan menjadi konverter ke objek JSON yang memiliki kunci string dan array string sebagai nilai. |
| contoh | PALSU | Benar -benar menonaktifkan indeks sekunder. Perhatikan bahwa jika kelas Jest tidak ditemukan indeks akan dimasukkan ke dalam mode dummy secara otomatis. |
| Validasi-kueri | PALSU | Mengirimkan kueri pencarian ke ES untuk validasi untuk memberikan kesalahan sintaks yang bermakna alih -alih batas waktu Cassandra. |
| Kunci bersamaan | BENAR | Eksekusi Indeks Kunci pada ID Partisi. Ini mencegah masalah konkurensi ketika berhadapan dengan beberapa pembaruan pada partisi yang sama secara bersamaan. |
| Skip-log-replay | BENAR | Ketika node Cassandra dimulai, itu akan memutar ulang log komit, pembaruan tersebut dilewati untuk meningkatkan waktu startup karena telah diterapkan pada ES. |
| Skip-Non-Local-updates | BENAR | Untuk meningkatkan kinerja yang memungkinkan pengaturan ini hanya akan menjalankan pembaruan indeks pada replika master dari rentang token. |
| mode ES-analitik | PALSU | Menonaktifkan penghapusan (ttl atau hapus dari) dokumen ES. |
| tipe-pipelines | tidak ada | Daftar Jenis untuk Mengatur Jipelin. |
| Pipa- <ype> | tidak ada | Definisi pipa untuk jenis ini. |
| index.translog.durability | async | Saat membuat indeks, kami menggunakan mode komit async untuk memastikan kinerja terbaik, itu adalah pengaturan default di ES 1.7. Karena 2.x ini sinkronisasi menghasilkan degradasi kinerja yang serius. |
| Tersedia-setiap-Bebuilding | BENAR | Saat membuat indeks baru, dimungkinkan (atau tidak) untuk menjalankan pencarian pada indeks parsial. |
| truncate-rebuild | PALSU | Potong indeks ES sebelum membangun kembali. |
| Periode Pembersihan | 60 | Setiap 60 menit semua indeks kosong akan dihapus dari alias. |
| tipe per-indeks | BENAR | Persiapkan nama indeks dengan nama tabel. Dalam ES 5.x tidak mungkin lagi memiliki pemetaan yang berbeda untuk nama bidang yang sama dalam berbagai jenis indeks yang sama. Dalam ES 6.x jenis akan dihapus. |
| force-delete | PALSU | Setiap menit permintaan "hapus dengan kueri" dikirim ke ES untuk menghapus dokumen yang telah kedaluwarsa _cassandrattl. Ini untuk meniru fungsi TTL yang dihapus dalam ES 5.x. Perhatikan bahwa sementara pemadatan Cassandra benar -benar akan menghapus dokumen dari ES tidak ada jaminan kapan itu akan terjadi. |
| ttl-shift | 0 | Waktu dalam hitungan detik untuk menggeser Cassandra TTL. Jika TTL 1H di Cassandra dan Shift adalah 3600, itu berarti dokumen dalam ES akan dihapus 1H lebih lambat dari Cassandra. |
| indeks-manajer | com.genesyslab.webme.commons.index.defaultindexManager | Nama kelas Manajer Indeks. Digunakan untuk manajer segmentasi dan fungsi kedaluwarsa. |
| Ukuran segmen | 86400000 | Kerangka waktu segmen dalam milidetik. Setiap indeks baru "ukuran segmen" akan dibuat dengan mengikuti templat: <lias_name> _index@<yyyymmdd't'hhmmss'z '> |
| Max-Connection-Per-Rute | 2 | Jumlah koneksi HTTP per simpul, default adalah nilai kumpulan http apache, dapat meningkatkan kinerja indeks cassandra tetapi meningkatkan beban pada ES. (Baru di WCC 9.0.000.15) |
Anda harus mematikan deteksi tanggal dalam definisi pemetaan Anda.
JSON berikut:
{
"maps" : {
"key1" : " value " ,
"key2" : 42 ,
"keymap" : {
"sss1" : null ,
"sss2" : 42 ,
"sss0" : " ffff "
},
"plap" : " plop "
},
"string" : " string " ,
"int" : 42 ,
"plplpl" : [ 1 , 2 , 3 , 4 ]
}Akan dikonversi menjadi:
{
"maps" : [ " key1=value " , " key2=42 " , " keymap={sss1=null, sss2=42, sss0=ffff} " , " plap=plop " ],
"string" : [ " string " ],
"int" : [ " 42 " ],
"plplpl" : [ " 1 " , " 2 " , " 3 " , " 4 " ]
}Nilai yang mungkin:
<type>Lihat Dokumentasi Elasticsearch Untuk detail tentang pemetaan jenis: http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/mapping.html
Semua jenis kolom Cassandra didukung, data akan dikirim sebagai string, array atau peta tergantung pada jenis Cassandra. Dengan pemetaan yang tepat, Elasticsearch kemudian akan mengubah data menjadi tipe yang relevan. Ini akan memungkinkan pencarian dan pelaporan yang jauh lebih baik.
| Jenis Cassandra | Elasticsearch merekomendasikan pemetaan | Komentar |
|---|---|---|
| ASCII | teks atau kata kunci | Lihat bagian berikutnya tentang jenis teks |
| Bigint | panjang | |
| gumpal | dengan disabilitas | Tidak mungkin mengindeks konten biner |
| Boolean | Boolean | |
| menangkal | panjang | |
| tanggal | tanggal | |
| desimal | dobel | |
| dobel | dobel | |
| mengambang | dobel | |
| inet | kata kunci | Ip tidak diuji |
| int | int | |
| Daftar <YPET> | Sama seperti tipe | ES mengharapkan bahwa suatu jenis dapat berupa nilai tunggal atau array |
| Peta < typek , typev > | obyek | Jika kunci Anda dapat memiliki banyak nilai yang berbeda, waspadalah pada pemetaan ledakan |
| atur <ype> | Sama seperti tipe | ES mengharapkan bahwa suatu jenis dapat berupa nilai tunggal atau array |
| Smallint | int | |
| teks | teks atau kata kunci | Lihat bagian berikutnya tentang jenis teks |
| waktu | kata kunci | |
| cap waktu | "type": "date", "format": "yyyy-mm-dd'hh: mm: ss.sss'z '" | |
| timeuuid | kata kunci | |
| Tinyint | int | |
| tuple <type1 type2, ...> | jenis | |
| UUID | kata kunci | |
| varchar | teks atau kata kunci | Lihat bagian berikutnya tentang jenis teks |
| varint | panjang | |
| Jenis yang ditentukan pengguna | obyek | Setiap bidang UDT akan dipetakan menggunakan nama dan nilai mereka |
Pemetaan jenis teks
Ketika kolom teks (ASCII atau VARCHAR) dikirim ke ES itu dikirim sebagai teks mentah untuk diindeks. Namun jika teksnya adalah JSON yang tepat, dimungkinkan untuk mengirimkannya sebagai dokumen JSON untuk diindeks ES. Ini memungkinkan untuk mengindeks/mencari dokumen alih -alih teks mentah.
Menggunakan pemetaan JSON tersebut memungkinkan untuk mencari data menggunakan "ColumnName.Key: Value".
Jika kunci Anda dapat memiliki banyak nilai yang berbeda, waspadalah pada pemetaan ledakan
JSON-Serialized-Fields (lihat opsi untuk detail)
Isi teks dikirim sebagai JSON. Dalam pemetaan Anda, Anda dapat menentukan setiap bidang dokumen secara terpisah. Perhatikan bahwa sekali bidang telah dipetakan sebagai tipe, baik dengan pemetaan statis atau pemetaan dinamis, memberikan tipe yang tidak kompatibel akan mengakibatkan kegagalan tulis Cassandra.
JSON-FLAT-Serialized-Fields (lihat opsi untuk detail dan contoh konversi)
Isi teks juga dikirim sebagai JSON, namun semua nilai dipaksa untuk menangkis string datar. Ini akan membatasi kemampuan untuk mencari JSON bersarang tetapi lebih aman jika Anda tidak dapat mengontrol jenis nilai JSON.
Ini adalah implementasi khusus dari indeks Cassandra. Ini memperkenalkan beberapa keterbatasan yang terkait dengan model konsistensi Cassandra. Keterbatasan utama adalah karena sifat indeks sekunder Cassandra, masing -masing simpul Cassandra hanya berisi data yang bertanggung jawab dalam cincin Cassandra, dengan indeks sekunder itu hal yang sama, masing -masing node hanya mengindeks data lokalnya. Ini berarti bahwa ketika melakukan kueri pada indeks, kueri dikirim ke semua node dan kemudian hasil dikumpulkan oleh koordinator kueri dan dikembalikan ke klien.
Dengan EsIndex berbeda, karena pencarian indeks didasarkan pada Elasticsearch, setiap node dapat menanggapi kueri. Ini berarti bahwa kueri hanya boleh dikirim ke satu node atau hasilnya akan berisi duplikat. Ini dicapai dengan memaksa token ke kueri CQL seperti di bawah ini.
select * from emails where query='subject:12345' and token(id)=0;
Token harus berupa nilai panjang acak untuk menyebarkan kueri di seluruh node. Itu harus dibangun di atas kunci partisi baris, 'id' dalam contoh di atas.
Dalam contoh di atas permintaan Elasticsearch adalah 'Subjek: 12345'. Ini adalah kueri seperti Lucene. Dimungkinkan juga untuk menjalankan kueri DSL lihat halaman Elasticsearch Query-DSL untuk lebih jelasnya.
Indeks Elasticsearch tunggal akan berisi semua indeks tabel Cassandra untuk ruang kunci yang diberikan. Untuk setiap indeks, tipe Elasticsearch khusus digunakan. Untuk mengizinkan agregasi silang, jenis ini tidak ditegakkan dalam kueri. Ini berarti bahwa jika kueri Anda dapat cocok dengan berbagai jenis, ia akan mengembalikan lebih banyak ID dari yang diharapkan. Karena itu tidak akan cocok dengan baris Cassandra, Anda tidak akan mendapatkan lebih banyak hasil, tetapi Anda juga bisa mendapatkan lebih sedikit jika Anda membatasi jumlah hasil yang dikembalikan.
Jika jumlah baris yang cocok tinggi dan baris besar, pencarian mungkin berakhir pada waktu baca. Anda hanya dapat meminta PK untuk dikembalikan dengan ES Metadata dan kemudian memuat baris secara paralel dari kode Anda menggunakan kueri CQL.
Untuk memberi tahu indeks untuk mengembalikan PKS hanya Anda perlu menggunakan petunjuk kueri di bawah ini #Options: load-baris = false #:
select * from emails where query='#options:load-rows=false#id:ab*';
Penting untuk dicatat bahwa baris yang dikembalikan adalah palsu dan dibangun dari hasil kueri Elasicsearch. Itu berarti bahwa baris yang dikembalikan mungkin tidak ada lagi:
Ketika permintaan pencarian mengembalikan hasilnya, baris pertama akan berisi metadata Elasticsearch sebagai ## string JSON di kolom indeks. Lihat misalnya:
cqlsh:ucs> select id,query from emails where query='id:00008RD9PrJMMmpr';
id | query
------------------+---------------------------------------------------------------------------------------------------------------------
00008RD9PrJMMmpr | {"took":5,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":1,"max_score":7.89821}}
Mekanisme segmentasi EsIndex membagi indeks Elasticsearch monolitik dengan urutan indeks berbasis waktu. Tujuan untuk itu adalah berikut:
Karena Elasticsearch 5.x TTL tidak didukung lagi. Namun proses pemadatan dan perbaikan normal Cassandra secara otomatis menghapus data batu nisan, ElasticIndex akan menghapus data dari Elasticsearch.
EsIndex mendukung penelusuran CQL, dapat diaktifkan pada node atau menggunakan CQLSH dengan perintah di bawah ini:
Menelusuri;
Penelusuran Selects maka Anda akan mendapatkan jejak dari seluruh kueri terhadap semua node yang berpartisipasi:
cqlsh:ucs> select * from "Contact" where "ESQuery"='AttributeValues.LastName:ab*' and token("Id")=0 limit 1;
Id | AttributeValues | AttributeValuesDate | Attributes| CreatedDate | ESQuery | ExpirationDate | MergeIds | ModifiedDate| PrimaryAttributes| Segment| TenantId
1001uiP2niJPJGBa | {"LastName":["IdentifyTest-aBEcKPnckHVP"],"EmailAddress":["IdentifyTest-HHzmNornOr"]} |{} | {'EmailAddress_IdentifyTest-HHzmNornOr': {Id: 'EmailAddress_IdentifyTest-HHzmNornOr', Name: 'EmailAddress', StrValue: 'IentifyTest-HHzmNornOr', Description: null, MimeType: null, IsPrimary: False}, 'LastName_IdentifyTest-aBEcKPnckHVP': {Id: 'LastName_IdentifyTest-aBEcKPnckHVP', Name: 'LastName', StrValue: 'IdentifyTest-aBEcKPnckHVP', Description: null, MimeType: null IsPrimary: False}} | 2018-10-30 02:05:06.960000+0000 | {"_index":"ucsperf2_contact_index@","_type":"Contact","_id":"1001uiP2niJPJGBa","_score":1.0,"_source":{"Id":"1001uiP2niJPJGBa"},"took":485,"timed_out":false,"_shards":{"total":5,"successful":5,failed":0},"hits":{"total":18188,"max_score":1.0}} | null | null | 2018-10-30 02:05:06.960000+0000 | {'EmailAddress': 'IdentifyTest-HHzmNornOr', 'LastName': 'IdentifyTest-aBEcKPnckHVP'} | not-applicable |1
(1 rows)
Maka Anda akan mendapatkan info penelusuran dari sesi Anda:
Sesi Penelusuran: 8ED07B60-180D-11E9-B832-33A777983333
activity | timestamp | source | source_elapsed | client
-----------------------------------------------------------------------------------------------------------------------------------------+----------------------------+---------------+----------------+--------------
Execute CQL3 query | 2019-01-14 16:03:32.118000 | xxx.xx.47.82 | 0 | xxx.xx.40.11
RANGE_SLICE message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:02:30.200000 | xxx.xx.47.49 | 34 | xxx.xx.40.11
Executing read on ucsperf2.Contact using index Contact_ESQuery_idx [ReadStage-1] | 2019-01-14 16:02:30.201000 | xxx.xx.47.49 | 411 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 Searching 'AttributeValues.LastName:ab*' [ReadStage-1] | 2019-01-14 16:02:30.201000 | xxx.xx.47.49 | 693 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 Found 10000 matching ES docs in 514ms [ReadStage-1] | 2019-01-14 16:02:30.716000 | xxx.xx.47.49 | 515336 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 StreamingPartitionIterator initialized [ReadStage-1] | 2019-01-14 16:02:30.717000 | xxx.xx.47.49 | 516911 | xxx.xx.40.11
reading data from /xxx.xx.47.100 [ReadStage-1] | 2019-01-14 16:02:30.717000 | xxx.xx.47.49 | 517121 | xxx.xx.40.11
speculating read retry on /xxx.xx.47.82 [ReadStage-1] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517435 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517436 | xxx.xx.40.11
Sending READ message to /xxx.xx.47.100 [MessagingService-Outgoing-/xxx.xx.47.100-Small] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517445 | xxx.xx.40.11
Sending READ message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517558 | xxx.xx.40.11
Acquiring sstable references [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517866 | xxx.xx.40.11
Bloom filter allows skipping sstable 83 [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517965 | xxx.xx.40.11
Partition index with 0 entries found for sstable 400 [ReadStage-2] | 2019-01-14 16:02:30.719000 | xxx.xx.47.49 | 518300 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:02:30.720000 | xxx.xx.47.49 | 519720 | xxx.xx.40.11
Processing response from /xxx.xx.47.82 [RequestResponseStage-4] | 2019-01-14 16:02:30.720000 | xxx.xx.47.49 | 519865 | xxx.xx.40.11
Bloom filter allows skipping sstable 765 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522352 | xxx.xx.40.11
Bloom filter allows skipping sstable 790 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522451 | xxx.xx.40.11
Bloom filter allows skipping sstable 819 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522516 | xxx.xx.40.11
Bloom filter allows skipping sstable 848 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522662 | xxx.xx.40.11
Bloom filter allows skipping sstable 861 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522741 | xxx.xx.40.11
Skipped 0/7 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522855 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-2] | 2019-01-14 16:02:30.723001 | xxx.xx.47.49 | 523075 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-2] | 2019-01-14 16:02:30.723001 | xxx.xx.47.49 | 523164 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524717 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 StreamingPartitionIterator closed [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524805 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524872 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524971 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.100 [MessagingService-Incoming-/xxx.xx.47.100] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528222 | xxx.xx.40.11
Processing response from /xxx.xx.47.100 [RequestResponseStage-1] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528364 | xxx.xx.40.11
Initiating read-repair [RequestResponseStage-1] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528481 | xxx.xx.40.11
Parsing select * from "Contact" where "ESQuery"='AttributeValues.LastName:ab*' and token("Id")=0 limit 1; [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 174 | xxx.xx.40.11
Preparing statement [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 254 | xxx.xx.40.11
Index mean cardinalities are Contact_ESQuery_idx:-2109988917941223823. Scanning with Contact_ESQuery_idx. [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 418 | xxx.xx.40.11
Computing ranges to query [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2480 | xxx.xx.40.11
Submitting range requests on 1 ranges with a concurrency of 1 (-4.6099044E15 rows per range expected) [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2568 | xxx.xx.40.11
Enqueuing request to /xxx.xx.47.49 [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2652 | xxx.xx.40.11
Submitted 1 concurrent range requests [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2708 | xxx.xx.40.11
Sending RANGE_SLICE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2874 | xxx.xx.40.11
READ message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.640000 | xxx.xx.47.100 | 29 | xxx.xx.40.11
READ message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521263 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521468 | xxx.xx.40.11
Acquiring sstable references [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521566 | xxx.xx.40.11
Partition index with 0 entries found for sstable 1187 [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521775 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-1] | 2019-01-14 16:03:32.641000 | xxx.xx.47.100 | 266 | xxx.xx.40.11
Bloom filter allows skipping sstable 1188 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522130 | xxx.xx.40.11
Acquiring sstable references [ReadStage-1] | 2019-01-14 16:03:32.641000 | xxx.xx.47.100 | 361 | xxx.xx.40.11
Bloom filter allows skipping sstable 1189 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522205 | xxx.xx.40.11
Bloom filter allows skipping sstable 1190 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522259 | xxx.xx.40.11
Skipped 0/5 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522303 | xxx.xx.40.11
Bloom filter allows skipping sstable 1186 [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522415 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522540 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522679 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.49 [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522734 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522863 | xxx.xx.40.11
Partition index with 0 entries found for sstable 1208 [ReadStage-1] | 2019-01-14 16:03:32.644000 | xxx.xx.47.100 | 3756 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.647000 | xxx.xx.47.82 | 528443 | xxx.xx.40.11
Processing response from /xxx.xx.47.49 [RequestResponseStage-2] | 2019-01-14 16:03:32.647000 | xxx.xx.47.82 | 528516 | xxx.xx.40.11
Bloom filter allows skipping sstable 1209 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9090 | xxx.xx.40.11
Bloom filter allows skipping sstable 1210 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9162 | xxx.xx.40.11
Bloom filter allows skipping sstable 1211 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9187 | xxx.xx.40.11
Skipped 0/5 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9237 | xxx.xx.40.11
Bloom filter allows skipping sstable 1207 [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9335 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9571 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9734 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.49 [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9842 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 10116 | xxx.xx.40.11
Request complete | 2019-01-14 16:03:32.646708 | xxx.xx.47.82 | 528708 | xxx.xx.40.11
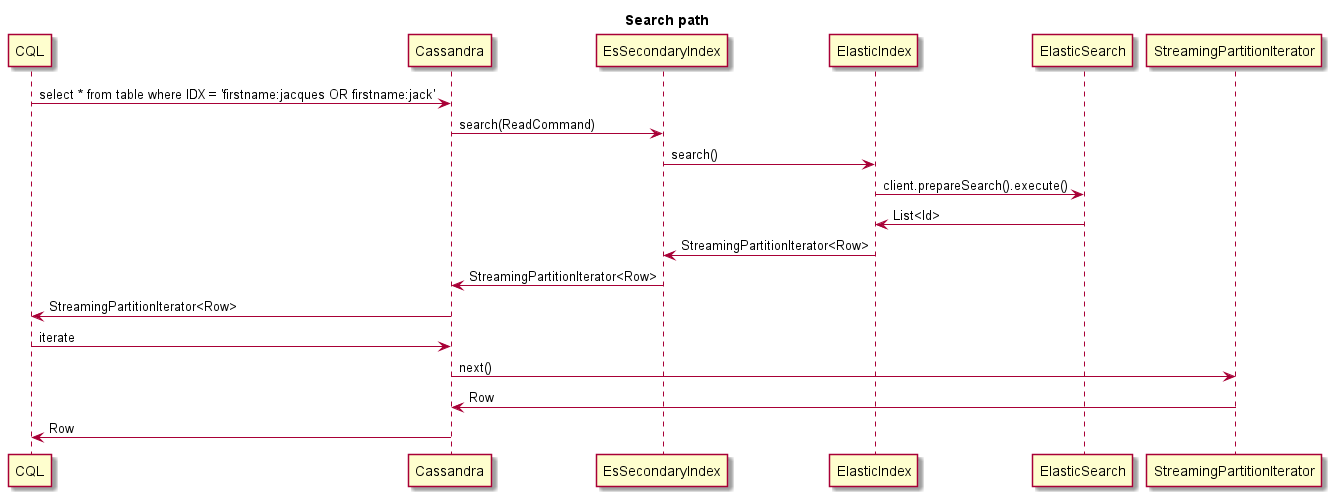
Semua kegiatan yang dimulai dengan ESI adalah kegiatan dari EsIndex:
* ESI <id> Searching 'AttributeValues.LastName:ab*': The query have been received and decoded by the ESIndex, it is now sent to ElasticSearch
* ESI <id> Found 10000 matching ES docs in 514ms: The query to ElasticSearch has found 10000 results
* ESI <id> StreamingPartitionIterator initialized: Streaming partition iterator have been provided with all Ids found, and starts reading rows
* ESI <id> StreamingPartitionIterator closed: Client is done reading rows (limit was 1)
Menelusuri pembaruan/sisipan/penghapusan
cqlsh:ucs> update "Contact" set "CreatedDate"='2017-04-01T11:21:59.001+0000' where "Id"='1001uiP2niJPJGBa';
Sesi Penelusuran: F76E4AC0-180E-11E9-B832-33A777983333
activity | timestamp | source | source_elapsed | client
----------------------------------------------------------------------------------------------------------------------------------------+----------------------------+---------------+----------------+--------------
Execute CQL3 query | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 0 | xxx.xx.40.11
MUTATION message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 22 | xxx.xx.40.11
Appending to commitlog [MutationStage-1] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 354 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-1] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 465 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [MutationStage-1] | 2019-01-14 16:12:35.212000 | xxx.xx.47.49 | 2356 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:12:35.212000 | xxx.xx.47.49 | 2548 | xxx.xx.40.11
Parsing update "Contact" set "CreatedDate"='2017-04-01T11:21:59.001+0000' where "Id"='1001uiP2niJPJGBa'; [Native-Transport-Requests-1] | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 146 | xxx.xx.40.11
Preparing statement [Native-Transport-Requests-1] | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 213 | xxx.xx.40.11
Determining replicas for mutation [Native-Transport-Requests-1] | 2019-01-14 16:13:37.133000 | xxx.xx.47.82 | 1895 | xxx.xx.40.11
Appending to commitlog [MutationStage-2] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2042 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-2] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2149 | xxx.xx.40.11
Sending MUTATION message to /xxx.xx.47.100 [MessagingService-Outgoing-/xxx.xx.47.100-Small] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2186 | xxx.xx.40.11
Sending MUTATION message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2232 | xxx.xx.40.11
MUTATION message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 28 | xxx.xx.40.11
Appending to commitlog [MutationStage-1] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 390 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-1] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 471 | xxx.xx.40.11
ESI decoding row 31303031756950326e694a504a474261 [MutationStage-1] | 2019-01-14 16:13:37.137000 | xxx.xx.47.100 | 579 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:13:37.137000 | xxx.xx.47.82 | 5160 | xxx.xx.40.11
ESI writing 31303031756950326e694a504a474261 to ES index [MutationStage-1] | 2019-01-14 16:13:37.137000 | xxx.xx.47.100 | 664 | xxx.xx.40.11
Processing response from /xxx.xx.47.49 [RequestResponseStage-4] | 2019-01-14 16:13:37.137000 | xxx.xx.47.82 | 5280 | xxx.xx.40.11
ESI index 31303031756950326e694a504a474261 done [MutationStage-1] | 2019-01-14 16:13:37.160000 | xxx.xx.47.100 | 23878 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.100 [MessagingService-Incoming-/xxx.xx.47.100] | 2019-01-14 16:13:37.160000 | xxx.xx.47.82 | 28445 | xxx.xx.40.11
Processing response from /xxx.xx.47.100 [RequestResponseStage-2] | 2019-01-14 16:13:37.160000 | xxx.xx.47.82 | 28549 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [MutationStage-1] | 2019-01-14 16:13:37.162000 | xxx.xx.47.100 | 25614 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:13:37.162000 | xxx.xx.47.100 | 25793 | xxx.xx.40.11
Request complete | 2019-01-14 16:13:37.814048 | xxx.xx.47.82 | 682048 | xxx.xx.40.11
Semua kegiatan yang dimulai dengan ESI adalah kegiatan dari EsIndex:
* ESI decoding row <rowId>: update request have been received by the ESIndex, row is being converted to JSON
* ESI writing <rowId> to ES index: update is being sent to ElasticSearch
* ESI index <rowId> done: ElasticSearch acknowledged the update
Ini adalah contoh dari apa yang terjadi saat mencari:
Ini adalah contoh penulisan sinkron, (operasi Cassandra akan gagal jika ES gagal):
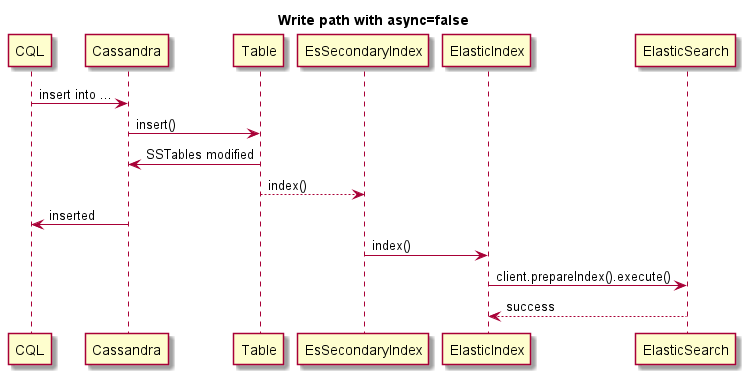
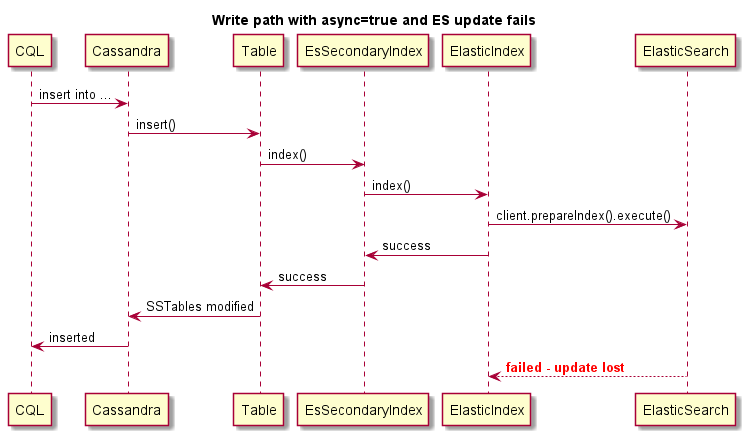
Ini adalah contoh penulisan asinkron:
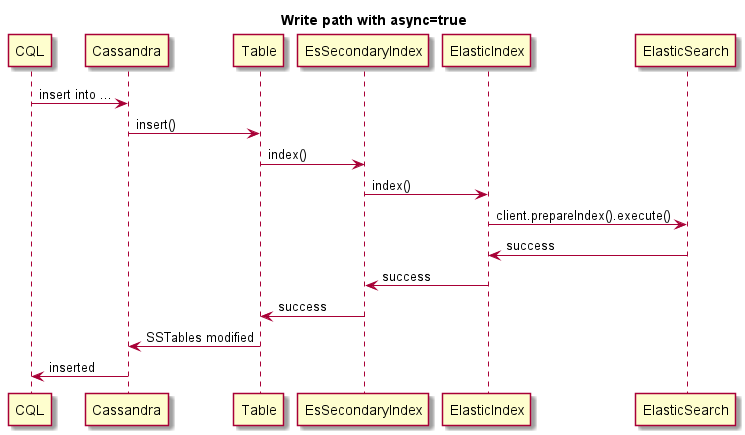
Ini adalah contoh penulisan asinkron, operasi Cassandra tidak akan gagal jika ES gagal: