cassandra es index
1.0.0
<type>Esta documentación explica el uso y la configuración de "Esindex" que es un índice secundario basado en Elasticsearch para Cassandra.
Este complemento requiere un clúster Elasticsearch (ES) ya configurado.
El complemento se instalará en una versión regular de Cassandra 4.0.x descargada de http://cassandra.apache.org/. No hay nada que cambiar en los archivos de configuración de Cassandra para admitir el índice. El comportamiento de Cassandra sigue sin cambios para las aplicaciones que no usan el índice.
Una vez creado en una tabla de Cassandra, este índice permite realizar consultas de Elasticsearch "Búsqueda de texto completo" en Cassandra utilizando CQL y devolver filas coincidentes de los datos de Cassandra. El uso de este complemento no requiere cambiar el código fuente de Cassandra, hemos implementado el índice Elasticsearch para Cassandra usando:
Las versiones probadas son Elasticsearch 5.x, 6.x, 7.x y Cassandra 4.0.x. Sin embargo, el complemento también puede funcionar con diferentes versiones de ElasticSearch (1.7, 2.x 5.x, 6.x, 7.x) si la aplicación proporciona las asignaciones y opciones correspondientes. Otras versiones de Apache Cassandra como 1.x 2.x, 3.x o 4.1 no son compatibles como la interfaz de índice secundario utilizada por el complemento es diferente. Otros vendedores de Cassandra no se prueban, ScylladB no es compatible.
| Versiones | Elasticsearch 1.x | Elasticsearch 2.x | Elasticsearch 5.x | Elasticsearch 6.x | Elasticsearch 7.x |
|---|---|---|---|---|---|
| Cassandra 1.x | No | No | No | No | No |
| Cassandra 2.x | No | No | No | No | No |
| Cassandra 3.x | No | No | No | No | No |
| Cassandra 4.x | Limitado | Limitado | Limitado | Sí | Sí |
Este proyecto requiere Maven y se compila con Java 8. Para construir el complemento, en la raíz del proyecto ejecutar:
Paquete de limpieza MVN
Esto construirá un "todos en un jar 'en target/distribution/lib4cassandra
<dependency>
<groupId>com.genesyslab</groupId>
<artifactId>es-index</artifactId>
<version>9.2.000.00</version>
</dependency>
Ver paquete Github
Ver repositorio de Maven
Ponga es-index-9.2.000.xx-jar-with-dependencies.jar en la carpeta LIB de Cassandra junto con otros frascos de Cassandra, por ejemplo '/usr/share/cassandra/lib' en todos los nodos de Cassandra. Inicie o reinicie sus nodos Cassandra.
Debido a la falta de pruebas, las tablas con claves de agrupación no son compatibles. Solo se admite una clave de partición, las teclas de partición compuesta deberían funcionar, pero no se probaron ampliamente.
ESIndex solo admite el nivel de fila TTL, donde todas las celdas caducarán al mismo tiempo y el documento ES correspondiente se puede eliminar al mismo tiempo. Si una fila tiene celdas que expira en diferentes momentos, el documento correspondiente se eliminará cuando expire la última celda. Si se usa TTL de celda diferente, los datos devueltos de una búsqueda seguirán siendo consistentes a medida que los datos se lean de SSTABLE, pero aún así será posible encontrar la fila utilizando datos caducados utilizando una consulta ES.
Es posible crear varios índices en la misma tabla, Esindex no evitará eso. Sin embargo, si existe más de un ESINDEX, el comportamiento puede ser inconsistente, dicha configuración no es compatible. El comando cqlsh 'describe la tabla <KshableName>' se puede usar para mostrar índices creados en la tabla y soltarlos si es necesario.
En aras de la simplicidad, cree este espacio de tecla primero:
CREATE KEYSPACE genesys WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1}
Usemos la tabla a continuación como ejemplo:
CREATE TABLE genesys.emails (
id UUID PRIMARY KEY,
subject text,
body text,
userid int,
query text
);
Debe dedicar una columna de texto ficticia para el uso del índice. Esta columna nunca debe recibir datos. En este ejemplo, la columna query es la columna ficticia.
Aquí le mostramos cómo crear el índice para la tabla de ejemplo y usar eShost para elasticsearch:
CREATE CUSTOM INDEX ON genesys.emails(query)
USING 'com.genesyslab.webme.commons.index.EsSecondaryIndex'
WITH OPTIONS = {'unicast-hosts': 'eshost:9200'};
Por ejemplo, si su servidor Elasticsearch está escuchando en localhost , reemplace ESHOST con LocalHost .
Los errores devueltos por CQL son muy limitados, si algo sale mal, como su host Elasticsearch no disponible, obtendrá un tiempo de espera u otro tipo de excepción. Tendrá que consultar los registros de Cassandra para comprender qué salió mal.
No proporcionamos ningún mapeo, por lo que confiamos en el mapeo dinámico de Elasticsearch, insertemos algunos datos:
INSERT INTO genesys.emails (id, subject, body, userid)
VALUES (904b88b2-9c61-4539-952e-c179a3805b22, 'Hello world', 'Cassandra is great, but it''s even better with EsIndex and Elasticsearch', 42);
Puede ver que el índice se está creando en ElasticSearch si tiene acceso a registros:
[o.e.c.m.MetaDataCreateIndexService] [node-1] [genesys_emails_index@] creating index, cause [api], templates [], shards [5]/[1], mappings []
[INFO ][o.e.c.m.MetaDataMappingService] [node-1] [genesys_emails_index@/waSGrPvkQvyQoUEiwqKN3w] create_mapping [emails]
Ahora podemos buscar en Cassandra usando ElasticSearch a través del índice, aquí hay una búsqueda de sintaxis de Lucene:
select id, subject, body, userid, query from emails where query='body:cassan*';
id | subject | body | userid | query
--------------------------------------+-------------+-------------------------------------------------------------------------+--------+-------
904b88b2-9c61-4539-952e-c179a3805b22 | Hello world | Cassandra is great, but it's even better with EsIndex and Elasticsearch | 42 |
{
"_index": "genesys_emails_index@",
"_type": "emails",
"_id": "904b88b2-9c61-4539-952e-c179a3805b22",
"_score": 0.24257512,
"_source": {
"id": "904b88b2-9c61-4539-952e-c179a3805b22"
},
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.24257512
}
}
(1 rows)
(Json fue formateado)
Todas las filas contendrán datos de Cassandra cargados de SSTABLE utilizando la consistencia CQL. Los datos en la columna 'consulta' son los metadatos devueltos por Elasticsearch.
Aquí se explica cómo consultar ElasticseSearch para verificar la asignación generada: GET http://eshost:9200/genesys_emails_index@/emails/_mapping?pretty
{
"genesys_emails_index@" : {
"mappings" : {
"emails" : {
"properties" : {
"IndexationDate" : {
"type" : " date "
},
"_cassandraTtl" : {
"type" : " long "
},
"body" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"id" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"subject" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"userid" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
}
}
}
}
}
}El complemento de Esindex agregó dos campos:
Podemos ver que el mapeo se ve bien, pero Elasticsearch no se dio cuenta de que el usuario de usuario es un entero y se agregó campos [palabra clave] a todo el texto.
Así es como se ven los datos en ElasticSearch:
GET http://localhost:9200/genesys_emails_index@/emails/_search?pretty&q=body:cassandra
{
"took" : 2 ,
"timed_out" : false ,
"_shards" : {
"total" : 5 ,
"successful" : 5 ,
"skipped" : 0 ,
"failed" : 0
},
"hits" : {
"total" : 1 ,
"max_score" : 0.2876821 ,
"hits" : [
{
"_index" : " genesys_emails_index@ " ,
"_type" : " emails " ,
"_id" : " 904b88b2-9c61-4539-952e-c179a3805b22 " ,
"_score" : 0.2876821 ,
"_source" : {
"id" : " 904b88b2-9c61-4539-952e-c179a3805b22 " ,
"body" : " Cassandra is great, but it's even better with EsIndex and Elasticsearch " ,
"subject" : " Hello world " ,
"userid" : " 42 " ,
"IndexationDate" : " 2019-01-15T16:53:00.107Z " ,
"_cassandraTtl" : 2147483647
}
}
]
}
} Solucionemos el mapeo soltando el índice: drop index genesys.emails_query_idx; ¡Esto también dejará caer el índice y datos de Elasticsearch!
y recrearlo con un mapeo adecuado:
CREATE CUSTOM INDEX ON genesys.emails(query)
USING 'com.genesyslab.webme.commons.index.EsSecondaryIndex'
WITH OPTIONS = {
'unicast-hosts': 'localhost:9200',
'mapping-emails': '
{
"emails":{
"date_detection":false,
"numeric_detection":false,
"properties":{
"id":{
"type":"keyword"
},
"userid":{
"type":"long"
},
"subject":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"body":{
"type":"text"
},
"IndexationDate":{
"type":"date",
"format":"yyyy-MM-dd''T''HH:mm:ss.SSS''Z''"
},
"_cassandraTtl":{
"type":"long"
}
}
}
}
'};
Esto creará un nuevo índice proporcionará mapeo y reindexa los datos que se encuentran en Cassandra.
Aquí está el mapeo de ES resultante:
{
"genesys_emails_index@" : {
"mappings" : {
"emails" : {
"date_detection" : false ,
"numeric_detection" : false ,
"properties" : {
"IndexationDate" : {
"type" : " date " ,
"format" : " yyyy-MM-dd'T'HH:mm:ss.SSS'Z' "
},
"_cassandraTtl" : {
"type" : " long "
},
"body" : {
"type" : " text "
},
"id" : {
"type" : " keyword "
},
"subject" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"userid" : {
"type" : " long "
}
}
}
}
}
}Ahora que el mapeo se define correctamente, podemos buscar en usuario como un número. En este ejemplo estamos usando Elasticsearch Query DSL:
select id, subject, body, userid from genesys.emails
where query='{"query":{"range":{"userid":{"gte":10,"lte":50}}}}';
@ Row 1
---------+-------------------------------------------------------------------------
id | 904b88b2-9c61-4539-952e-c179a3805b22
subject | Hello world
body | Cassandra is great, but it's even better with EsIndex and Elasticsearch
userid | 42
Es muy importante obtener el mapeo justo antes de comenzar la producción. Reindexar una tabla grande tomará mucho tiempo y pondrá una carga significativa en Cassandra y Elasticsearch. Deberá verificar los registros de Cassandra en busca de errores en su asignación de ES. Asegúrese de escapar de cotizaciones (') duplicándolas en las opciones JSON proporcionadas al comando Crear índice.
A continuación se presentan todas las opciones relacionadas con la configuración del índice Elasticsearch. Los nombres clave pueden usar hyphen '-' char o puntos. Por ejemplo, ambos nombres funcionarán:
Tenga en cuenta que todas las opciones a continuación son específicas para la implementación de Genesys y no en la misma.
Si no se encuentran clases de Jest, el modo ficticio está habilitado y no se aplica otros casos.
Se admite multidatacenter y los datos se replican solo a través de la replicación de chismes de Cassandra. Los grupos de ES en diferentes DC no son los mismos y nunca deben unirse o el rendimiento se verá afectado. Dado que los datos se replican a nivel de tabla, ESIndex obtendrá una actualización en cada DC y el clúster ES local también se actualizará.
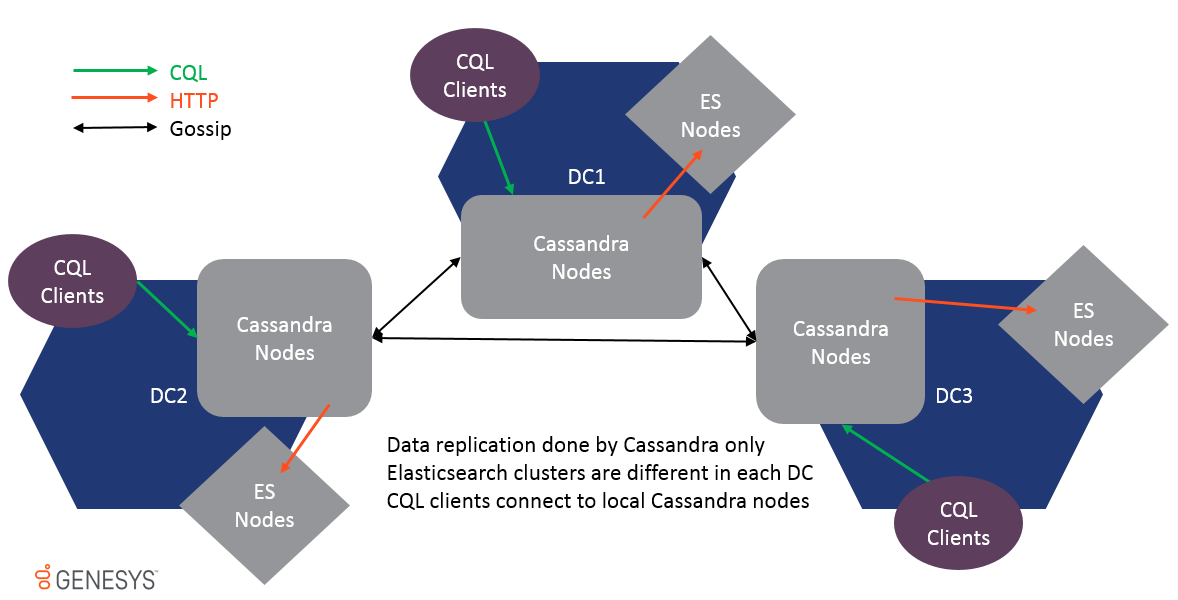
Para admitir múltiples DC, todas las opciones pueden ser prefijadas por Datacenter y Rack Name para hacer que la ubicación de configuración sea específica, por ejemplo:
Para proporcionar el índice de Cassandra para ElasticSearch con credenciales, cada nodo debe tener la variable de entorno de escrutinencialmente establecida correctamente antes de comenzar. Esto debe estar establecido en todos los anfitriones de Cassandra.
El siguiente ejemplo proporciona la contraseña para el usuario 'elástico' y contraseña 'EjemploPassword' separado por: (colon) carácter. Se puede hacer directamente en el sistema como una variable de entorno o en el atajo que lanza Cassandra.
Escredentials = Elastic: EjemploPassword Una vez que el índice se inicialice con éxito, escribirá "Elasticsearch Credentials proporcionadas" en los registros de Cassandra a nivel de información. Una vez que se emite este mensaje, es posible borrar la variable de entorno. Si se reinicia Cassandra, la variable de entorno debe establecerse nuevamente antes de comenzar. Las credenciales se mantienen solo en la memoria y no se guardan en ningún otro lugar. Si se cambia el usuario y/o la contraseña, todos los nodos de Cassandra deben reiniciarse con el valor de la variable de entorno actualizado.
En el conjunto de opciones de índice
unicast-hosts = https : //<host name>:9200
Actualmente no es posible migrar un índice existente de HTTP a HTTPS, el uso de uno u otro debe decidirse antes de crear el esquema Cassandra. Para facilitar la implementación de HTTPS, el índice confiará automáticamente en todos los certificados HTTPS.
Es posible mantener los datos del lado de Elasticsearch durante un período más largo que el Cassandra TTL definido. Este modo se gira utilizando la opción ES-Analytic-Mode. Cuando la opción está habilitada, ElasticIndex omitirá todas las operaciones de eliminación.
Para evitar que los datos crecan demasiado en el lado de ES, se recomienda usar la configuración de cambio TTL y de fortaleza.
Al crear el índice, proporcionará opciones de índice, así como opciones de índice Elasticsearch utilizando el comando CQL 'usando opción'.
Las opciones de índice deben especificarse en la creación del índice, aquí hay un ejemplo
CREATE CUSTOM INDEX on genesys.email(query) using 'com.genesyslab.webme.commons.index.EsSecondaryIndex' WITH options =
{
'read-consistency-level':'QUORUM',
'insert-only':'false',
'index-properties': '{
"index.analysis.analyzer.dashless.tokenizer":"dash-ex",
"index.analysis.tokenizer.dash-ex.pattern":"[^\\w\\-]",
"index.analysis.tokenizer.dash-ex.type":"pattern"
}',
'mapping-email': '{
"email": {
"dynamic": "false",
"properties": {
"subject" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}',
'discard-nulls':'false',
'async-search':'true',
'async-write':'false'
};
También puede establecer o anular opciones utilizando variables de entorno o propiedades del sistema Java mediante el prefijo opciones con 'Genesys-Ees-'.
Primero se utilizan las opciones proporcionadas en el comando "Crear índice personalizado". Se pueden anular localmente utilizando un archivo llamado Es-Index.Properties encontrado en ".", "./Conf/", "../conf/" o "./bin/". (se puede cambiar con -dgenessys-es-esi-file o -dgeness.es.esi.file System Propiedad)
Aquí hay un ejemplo para el contenido del archivo:
insert-solo = true DISCARD-NULLS = false async-write = false
| Nombre | Por defecto | Descripción |
|---|---|---|
| Resultados máximos | 10000 | Número de resultados para leer de ES Búsquedes para cargar filas Cassandra. |
| Leer a nivel de consistencia | UNO | Utilizado para búsquedas, este nivel de consistencia se utiliza para cargar filas de Cassandra. |
| solo inserto | FALSO | Por defecto, ESINDEX utilizará las operaciones UPSERT. En insertar solo los datos del modo siempre se sobrescribirán. |
| escritura asíncrata | verdadero | Envía actualizaciones de índice de forma asincrónica sin verificar la ejecución correcta. Esto proporciona escrituras mucho más rápidas, pero los datos pueden volverse inconsistentes si ES Cluster no está disponible, porque las escrituras no fallarán. El valor predeterminado es verdadero. |
| segmento | APAGADO | Desactivado, hora, día, mes, año, segmentación de índice automático personalizado se controla con esta configuración. Si se establece en el día, todos los días se creará un nuevo índice bajo el alias. Tenga en cuenta que los índices vacíos se eliminan automáticamente cada hora. NOTA: La configuración de la hora se desaconseja, ya que creará muchos índices y puede disminuir el rendimiento. Se recomienda a esta configuración para fines de desarrollo y prueba. |
| nombre de segmento | Si segmento = personalizado este valor se utilizará para la nueva creación de índice. | |
| mapeo- <prote> | {} | Para cada índice secundario, el nombre de la tabla se pasa como un tipo, por ejemplo, mapeo-visit = {json Definent}. |
| Hosts unidifusión | http: // localhost: 9200 | Una lista de comas separada de host, puede ser host1, host2, host3 o http: // host1, http: // host2, http: // host3 o http: // host1: 9200, http: // host2: 9200, http: // host3: 9200. Si falta el protocolo o el puerto HTTP y se asume 9200. Es posible usar HTTPS. |
| desechar las nulas | verdadero | No pase los valores nulos al índice ES, significa que no podrá eliminar un valor. El valor predeterminado es verdadero . |
| propiedad índice | {} | Las propiedades como una cadena JSON, pasada para crear un nuevo índice, pueden contener definiciones de tokenizador, por ejemplo. |
| JSON-serializados campos | {} | Una cadena separada por coma que define que una columna de cadena debe indexarse como una cadena JSON. Las cadenas de parsables no JSON evitarán insertos en Cassandra. |
| JSON-FLAT-Serialized-Fields | {} | Una cadena separada por coma que define que una columna de cadena debe indexarse como un documento JSON seguro. Elasticsearch JSON Mapping no permite indexar un valor que cambiará el tipo con el tiempo. Por ejemplo, {"clave": "valor"} no puede convertirse en {"clave": {"Subkey": "valor"}} En Elasticsearch obtendrá una excepción de mapeo. Tal JSON-FLAT será convertidor en un objeto JSON que tenga teclas de cadena y matrices de cadena como valores. |
| ficticio | FALSO | Desactiva completamente el índice secundario. Tenga en cuenta que si no se encuentran clases de Jest, el índice se pondrá en modo ficticio automáticamente. |
| Queras de validación | FALSO | Envía consultas de búsqueda a ES para la validación para proporcionar errores de sintaxis significativos en lugar de tiempos de espera de Cassandra. |
| bloqueo simultáneo | verdadero | Bloquea las ejecuciones de índice en ID de partición. Esto evita problemas de concurrencia al tratar con múltiples actualizaciones sobre la misma partición al mismo tiempo. |
| Representación de salto de omisión | verdadero | Cuando comienza los nodos de Cassandra, reproducirá el registro de confirmación, esas actualizaciones se omiten para mejorar el tiempo de inicio, ya que ya se han aplicado a ES. |
| omitir-no-updates | verdadero | Para mejorar el rendimiento, habilitar esta configuración solo ejecutará actualizaciones de índice en la réplica maestra de la gama token. |
| modo analítico | FALSO | Desactiva eliminar (TTL o eliminar de) de los documentos ES. |
| Tipo de pipelines | ninguno | Lista de tipo para configurar tuberías. |
| tubería- <prote> | ninguno | Definición de tubería para este tipo. |
| index.translog.durabilidad | asíncrata | Al crear un índice, utilizamos el modo de confirmación Async para garantizar el mejor rendimiento, fue la configuración predeterminada en ES 1.7. Desde 2.x, es sincronización, lo que resulta en una degradación grave del rendimiento. |
| disponible | verdadero | Al crear un nuevo índice, es posible (o no) ejecutar búsquedas en el índice parcial. |
| truncar-reBuild | FALSO | Truncate ES Index antes de la reconstrucción. |
| período de purga | 60 | Cada 60 minutos, todos los índices vacíos se eliminarán del alias. |
| por índice | verdadero | Prepare el nombre del índice con el nombre de la tabla. En ES 5.x ya no es posible tener una asignación diferente para el mismo nombre de campo en diferentes tipos del mismo índice. En ES 6.x se eliminarán los tipos. |
| fortaleza | FALSO | Cada minuto se envía una solicitud de "Eliminar por consulta" a ES para eliminar documentos que han expirado _Cassandrattl. Esto es para emular la funcionalidad TTL que se eliminó en ES 5.x. Tenga en cuenta que, si bien Cassandra Compacts realmente eliminará el documento de ES, no hay garantía de cuándo ocurrirá. |
| TTL-Shift | 0 | Tiempo en segundos para cambiar a Cassandra ttl. Si TTL era 1H en Cassandra y el cambio es 3600, significa que el documento en ES se eliminará 1H más tarde que Cassandra. |
| gerente de índice | com.genesslab.webme.commons.index.defaultindexmanager | Nombre de clase del administrador del índice. Se utiliza para la funcionalidad de segmentación y vencimiento del gerente. |
| de tamaño de segmento | 86400000 | Marco de tiempo de segmento en milisegundos. Cada nuevo índice de "tamaño de segmento" se creará siguiendo la plantilla: <alias_name> _index@<yyyymmdd't'hhmmss'z '>> |
| Max-Connections por ruta | 2 | Número de conexión HTTP por nodo ES, el valor predeterminado es el valor del grupo HTTP apache, puede aumentar el rendimiento del índice Cassandra pero aumentar la carga en ES. (Nuevo en WCC 9.0.000.15) |
Debe desactivar la detección de fecha en su definición de mapeo.
El siguiente JSON:
{
"maps" : {
"key1" : " value " ,
"key2" : 42 ,
"keymap" : {
"sss1" : null ,
"sss2" : 42 ,
"sss0" : " ffff "
},
"plap" : " plop "
},
"string" : " string " ,
"int" : 42 ,
"plplpl" : [ 1 , 2 , 3 , 4 ]
}Se convertirá en:
{
"maps" : [ " key1=value " , " key2=42 " , " keymap={sss1=null, sss2=42, sss0=ffff} " , " plap=plop " ],
"string" : [ " string " ],
"int" : [ " 42 " ],
"plplpl" : [ " 1 " , " 2 " , " 3 " , " 4 " ]
}Valores posibles:
<type>Consulte la documentación de Elasticsearch para obtener detalles sobre la asignación de tipos: http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/mapping.html
Se admiten todos los tipos de columnas de Cassandra, los datos se enviarán como una cadena, una matriz o un mapa dependiendo del tipo Cassandra. Con la asignación adecuada, Elasticsearch convertirá los datos en el tipo relevante. Esto permitirá búsquedas e informes mucho mejores.
| Tipos de cassandra | Elasticsearch recomendado mapeo | Comentario |
|---|---|---|
| ascii | texto o palabra clave | Consulte la siguiente sección sobre el tipo de texto |
| bigint | largo | |
| gota | desactivado | No es posible indexar contenido binario |
| booleano | booleano | |
| encimera | largo | |
| fecha | fecha | |
| decimal | doble | |
| doble | doble | |
| flotar | doble | |
| inet | palabra clave | ES IP no se prueba |
| intencionalmente | intencionalmente | |
| Lista <Prote> | Igual que el tipo | ES espera que un tipo pueda ser un valor único o una matriz |
| mapa < typek , wypev > | objeto | Si sus claves pueden tener muchos valores diferentes, tenga cuidado con la explosión de mapeo |
| Establecer <Prote> | Igual que el tipo | ES espera que un tipo pueda ser un valor único o una matriz |
| pequeño | intencionalmente | |
| texto | texto o palabra clave | Consulte la siguiente sección sobre el tipo de texto |
| tiempo | palabra clave | |
| marca de tiempo | "tipo": "fecha", "formato": "aaa-mm-dd't'hh: mm: ss.sss'z '" | |
| Timeuuid | palabra clave | |
| pequeño | intencionalmente | |
| Tuple <Type1 Type2, ...> | tipo | |
| uuid | palabra clave | |
| varar | texto o palabra clave | Consulte la siguiente sección sobre el tipo de texto |
| varint | largo | |
| Tipo definido por el usuario | objeto | Cada campo UDT se asignará utilizando sus nombres y valores |
Mapeo del tipo de texto
Cuando se envía una columna de texto (ASCII o VARCHAR) a ES, se envía como texto sin procesar para ser indexado. Sin embargo, si el texto es apropiado JSON, es posible enviarlo como un documento JSON para que ES se indexe. Esto permite indexar/buscar el documento en lugar del texto sin procesar.
El uso de dicha asignación de JSON permite buscar datos usando "columnName.key: value".
Si sus claves pueden tener muchos valores diferentes, tenga cuidado con la explosión de mapeo
JSON-Serialized-Fields (ver opciones para más detalles)
El contenido del texto se envía como JSON. En su mapeo puede definir cada campo de documento por separado. Tenga en cuenta que una vez que un campo se ha asignado como un tipo, ya sea por mapeo estático o mapeo dinámico, proporcionando un tipo incompatible dará como resultado fallas de escritura de Cassandra.
JSON-FLAT-Serialized-Fields (ver opciones para detalles y ejemplo de conversión)
El contenido del texto también se envía como JSON, sin embargo, todos los valores se ven obligados a matrices de cadenas planas. Esto limitará la capacidad de buscar en JSON anidado, pero es más seguro si no puede controlar el tipo JSON de los valores.
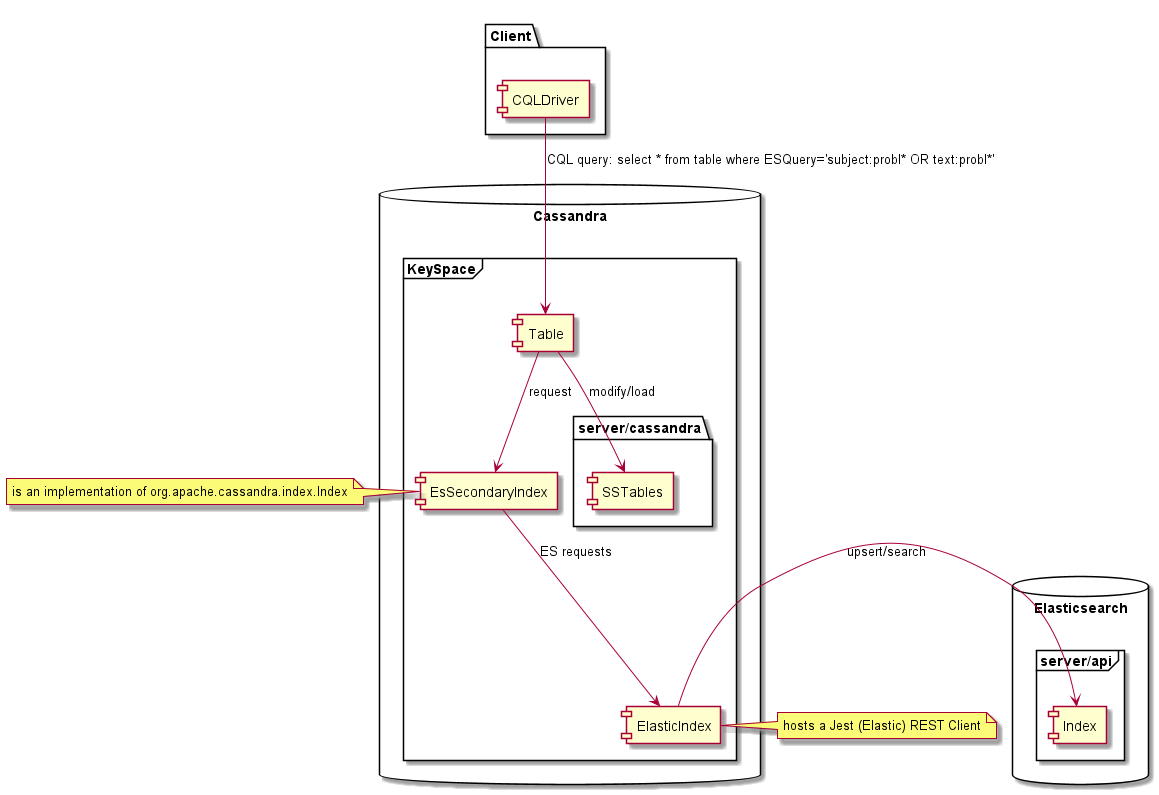
Es una implementación personalizada de un índice Cassandra. Esto introduce algunas limitaciones vinculadas al modelo de consistencia de Cassandra. La limitación principal se debe a la naturaleza de los índices secundarios de Cassandra, cada nodo Cassandra solo contiene datos que es responsable dentro del anillo de Cassandra, con los índices secundarios es lo mismo, cada nodo solo indexa sus datos locales. Significa que al hacer una consulta sobre el índice, la consulta se envía a todos los nodos y luego los resultados se agregan por el coordinador de consultas y se devuelve a los clientes.
Con Esindex es diferente, ya que la búsqueda de índice se basa en Elasticsearch, cada nodo puede responder a la consulta. Significa que la consulta solo debe enviarse a un solo nodo o resultado contendrá duplicados. Esto se logra forzando un token a la consulta CQL como a continuación.
select * from emails where query='subject:12345' and token(id)=0;
El token debe ser cualquier valor largo aleatorio para difundir consultas en los nodos. Debe construirse sobre la clave de partición de la fila, 'ID' en el ejemplo anterior.
En el ejemplo anterior, la consulta Elasticsearch es 'Asunto: 12345'. Esta es una consulta como Lucene. También es posible ejecutar consultas DSL Consulte la página Elasticsearch Query-DSL para obtener más detalles.
Un solo índice de elasticsearch contendrá todos los índices de tabla Cassandra para un espacio de tecla determinado. Para cada índice se utiliza un tipo de ElasticSearch dedicado. Para permitir agregaciones transversales, el tipo no se aplica en las consultas. Significa que si su consulta puede igualar diferentes tipos, devolverá más ID de lo esperado. Dado que esas no coincidirán con las filas de Cassandra, no obtendrá más resultados, pero también podría obtener menos si limita la cantidad de resultados devueltos.
Si el recuento de filas combinados es alto y las filas son grandes, las búsquedas pueden terminar en el tiempo de espera de lectura. Puede solicitar solo PK para devolverse con metadatos ES y luego cargar filas en paralelo desde su código utilizando consultas CQL.
Para decirle al índice que devuelva PKS, solo necesita usar la siguiente consulta de la consulta #options: Load-Rows = False #:
select * from emails where query='#options:load-rows=false#id:ab*';
Es importante tener en cuenta que las filas devueltas son falsas y se construyen a partir de los resultados de la consulta de elasicsearch. Significa que las filas devueltas pueden no existir más:
Cuando una solicitud de búsqueda devuelve un resultado, la primera fila contendrá los metadatos de Elasticsearch como ## una cadena JSON en la columna del índice. Ver por ejemplo:
cqlsh:ucs> select id,query from emails where query='id:00008RD9PrJMMmpr';
id | query
------------------+---------------------------------------------------------------------------------------------------------------------
00008RD9PrJMMmpr | {"took":5,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":1,"max_score":7.89821}}
El mecanismo de segmentación de ESINDEX divide el índice monolítico Elasticsearch a la secuencia de índices basados en el tiempo. Los propósitos para eso son los siguientes:
Dado que ElasticSearch 5.x TTL ya no es compatible. Sin embargo, los procesos normales de compactación y reparación de Cassandra eliminan automáticamente los datos de la lápida, ElasticIndex eliminará los datos de Elasticsearch.
Esindex admite el rastreo CQL, se puede habilitar en un nodo o usar CQLSH con el siguiente comando:
Rastreo;
El rastreo selecciona, luego obtendrá trazas de toda la consulta contra todos los nodos participantes:
cqlsh:ucs> select * from "Contact" where "ESQuery"='AttributeValues.LastName:ab*' and token("Id")=0 limit 1;
Id | AttributeValues | AttributeValuesDate | Attributes| CreatedDate | ESQuery | ExpirationDate | MergeIds | ModifiedDate| PrimaryAttributes| Segment| TenantId
1001uiP2niJPJGBa | {"LastName":["IdentifyTest-aBEcKPnckHVP"],"EmailAddress":["IdentifyTest-HHzmNornOr"]} |{} | {'EmailAddress_IdentifyTest-HHzmNornOr': {Id: 'EmailAddress_IdentifyTest-HHzmNornOr', Name: 'EmailAddress', StrValue: 'IentifyTest-HHzmNornOr', Description: null, MimeType: null, IsPrimary: False}, 'LastName_IdentifyTest-aBEcKPnckHVP': {Id: 'LastName_IdentifyTest-aBEcKPnckHVP', Name: 'LastName', StrValue: 'IdentifyTest-aBEcKPnckHVP', Description: null, MimeType: null IsPrimary: False}} | 2018-10-30 02:05:06.960000+0000 | {"_index":"ucsperf2_contact_index@","_type":"Contact","_id":"1001uiP2niJPJGBa","_score":1.0,"_source":{"Id":"1001uiP2niJPJGBa"},"took":485,"timed_out":false,"_shards":{"total":5,"successful":5,failed":0},"hits":{"total":18188,"max_score":1.0}} | null | null | 2018-10-30 02:05:06.960000+0000 | {'EmailAddress': 'IdentifyTest-HHzmNornOr', 'LastName': 'IdentifyTest-aBEcKPnckHVP'} | not-applicable |1
(1 rows)
Entonces obtendrás información de rastreo de tu sesión:
Sesión de rastreo: 8ED07B60-180D-11E9-B832-33A7779833333
activity | timestamp | source | source_elapsed | client
-----------------------------------------------------------------------------------------------------------------------------------------+----------------------------+---------------+----------------+--------------
Execute CQL3 query | 2019-01-14 16:03:32.118000 | xxx.xx.47.82 | 0 | xxx.xx.40.11
RANGE_SLICE message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:02:30.200000 | xxx.xx.47.49 | 34 | xxx.xx.40.11
Executing read on ucsperf2.Contact using index Contact_ESQuery_idx [ReadStage-1] | 2019-01-14 16:02:30.201000 | xxx.xx.47.49 | 411 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 Searching 'AttributeValues.LastName:ab*' [ReadStage-1] | 2019-01-14 16:02:30.201000 | xxx.xx.47.49 | 693 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 Found 10000 matching ES docs in 514ms [ReadStage-1] | 2019-01-14 16:02:30.716000 | xxx.xx.47.49 | 515336 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 StreamingPartitionIterator initialized [ReadStage-1] | 2019-01-14 16:02:30.717000 | xxx.xx.47.49 | 516911 | xxx.xx.40.11
reading data from /xxx.xx.47.100 [ReadStage-1] | 2019-01-14 16:02:30.717000 | xxx.xx.47.49 | 517121 | xxx.xx.40.11
speculating read retry on /xxx.xx.47.82 [ReadStage-1] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517435 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517436 | xxx.xx.40.11
Sending READ message to /xxx.xx.47.100 [MessagingService-Outgoing-/xxx.xx.47.100-Small] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517445 | xxx.xx.40.11
Sending READ message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517558 | xxx.xx.40.11
Acquiring sstable references [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517866 | xxx.xx.40.11
Bloom filter allows skipping sstable 83 [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517965 | xxx.xx.40.11
Partition index with 0 entries found for sstable 400 [ReadStage-2] | 2019-01-14 16:02:30.719000 | xxx.xx.47.49 | 518300 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:02:30.720000 | xxx.xx.47.49 | 519720 | xxx.xx.40.11
Processing response from /xxx.xx.47.82 [RequestResponseStage-4] | 2019-01-14 16:02:30.720000 | xxx.xx.47.49 | 519865 | xxx.xx.40.11
Bloom filter allows skipping sstable 765 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522352 | xxx.xx.40.11
Bloom filter allows skipping sstable 790 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522451 | xxx.xx.40.11
Bloom filter allows skipping sstable 819 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522516 | xxx.xx.40.11
Bloom filter allows skipping sstable 848 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522662 | xxx.xx.40.11
Bloom filter allows skipping sstable 861 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522741 | xxx.xx.40.11
Skipped 0/7 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522855 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-2] | 2019-01-14 16:02:30.723001 | xxx.xx.47.49 | 523075 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-2] | 2019-01-14 16:02:30.723001 | xxx.xx.47.49 | 523164 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524717 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 StreamingPartitionIterator closed [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524805 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524872 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524971 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.100 [MessagingService-Incoming-/xxx.xx.47.100] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528222 | xxx.xx.40.11
Processing response from /xxx.xx.47.100 [RequestResponseStage-1] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528364 | xxx.xx.40.11
Initiating read-repair [RequestResponseStage-1] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528481 | xxx.xx.40.11
Parsing select * from "Contact" where "ESQuery"='AttributeValues.LastName:ab*' and token("Id")=0 limit 1; [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 174 | xxx.xx.40.11
Preparing statement [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 254 | xxx.xx.40.11
Index mean cardinalities are Contact_ESQuery_idx:-2109988917941223823. Scanning with Contact_ESQuery_idx. [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 418 | xxx.xx.40.11
Computing ranges to query [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2480 | xxx.xx.40.11
Submitting range requests on 1 ranges with a concurrency of 1 (-4.6099044E15 rows per range expected) [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2568 | xxx.xx.40.11
Enqueuing request to /xxx.xx.47.49 [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2652 | xxx.xx.40.11
Submitted 1 concurrent range requests [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2708 | xxx.xx.40.11
Sending RANGE_SLICE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2874 | xxx.xx.40.11
READ message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.640000 | xxx.xx.47.100 | 29 | xxx.xx.40.11
READ message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521263 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521468 | xxx.xx.40.11
Acquiring sstable references [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521566 | xxx.xx.40.11
Partition index with 0 entries found for sstable 1187 [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521775 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-1] | 2019-01-14 16:03:32.641000 | xxx.xx.47.100 | 266 | xxx.xx.40.11
Bloom filter allows skipping sstable 1188 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522130 | xxx.xx.40.11
Acquiring sstable references [ReadStage-1] | 2019-01-14 16:03:32.641000 | xxx.xx.47.100 | 361 | xxx.xx.40.11
Bloom filter allows skipping sstable 1189 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522205 | xxx.xx.40.11
Bloom filter allows skipping sstable 1190 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522259 | xxx.xx.40.11
Skipped 0/5 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522303 | xxx.xx.40.11
Bloom filter allows skipping sstable 1186 [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522415 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522540 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522679 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.49 [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522734 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522863 | xxx.xx.40.11
Partition index with 0 entries found for sstable 1208 [ReadStage-1] | 2019-01-14 16:03:32.644000 | xxx.xx.47.100 | 3756 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.647000 | xxx.xx.47.82 | 528443 | xxx.xx.40.11
Processing response from /xxx.xx.47.49 [RequestResponseStage-2] | 2019-01-14 16:03:32.647000 | xxx.xx.47.82 | 528516 | xxx.xx.40.11
Bloom filter allows skipping sstable 1209 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9090 | xxx.xx.40.11
Bloom filter allows skipping sstable 1210 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9162 | xxx.xx.40.11
Bloom filter allows skipping sstable 1211 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9187 | xxx.xx.40.11
Skipped 0/5 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9237 | xxx.xx.40.11
Bloom filter allows skipping sstable 1207 [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9335 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9571 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9734 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.49 [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9842 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 10116 | xxx.xx.40.11
Request complete | 2019-01-14 16:03:32.646708 | xxx.xx.47.82 | 528708 | xxx.xx.40.11
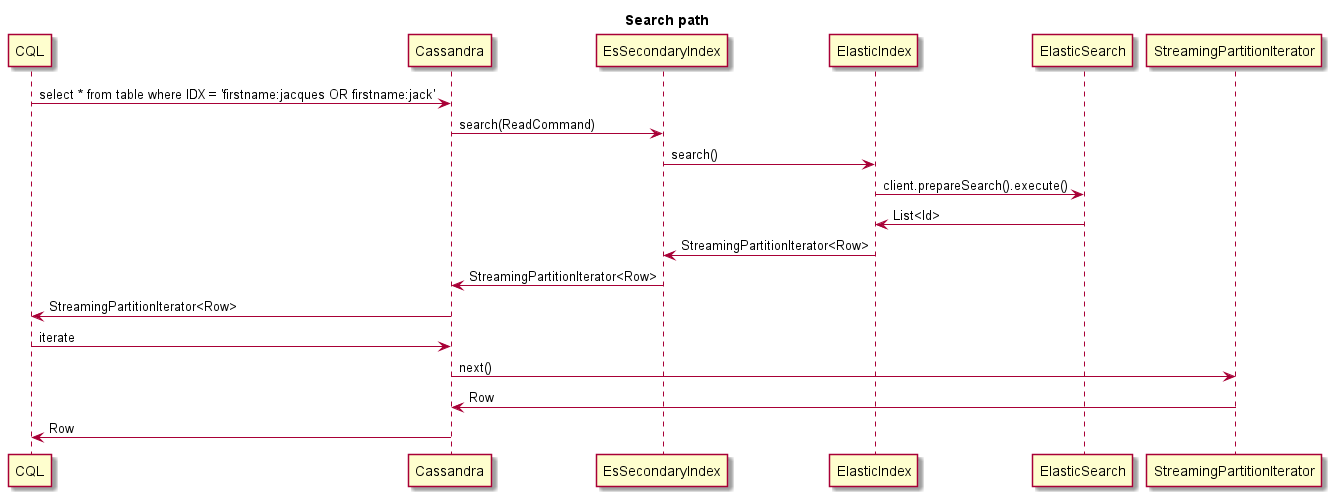
Todas las actividades que comienzan por ESI son actividades de ESINDEX:
* ESI <id> Searching 'AttributeValues.LastName:ab*': The query have been received and decoded by the ESIndex, it is now sent to ElasticSearch
* ESI <id> Found 10000 matching ES docs in 514ms: The query to ElasticSearch has found 10000 results
* ESI <id> StreamingPartitionIterator initialized: Streaming partition iterator have been provided with all Ids found, and starts reading rows
* ESI <id> StreamingPartitionIterator closed: Client is done reading rows (limit was 1)
Rastreo de actualizaciones/insertos/eliminar
cqlsh:ucs> update "Contact" set "CreatedDate"='2017-04-01T11:21:59.001+0000' where "Id"='1001uiP2niJPJGBa';
Sesión de rastreo: F76E4AC0-180E-11E9-B832-33A7779833333
activity | timestamp | source | source_elapsed | client
----------------------------------------------------------------------------------------------------------------------------------------+----------------------------+---------------+----------------+--------------
Execute CQL3 query | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 0 | xxx.xx.40.11
MUTATION message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 22 | xxx.xx.40.11
Appending to commitlog [MutationStage-1] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 354 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-1] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 465 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [MutationStage-1] | 2019-01-14 16:12:35.212000 | xxx.xx.47.49 | 2356 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:12:35.212000 | xxx.xx.47.49 | 2548 | xxx.xx.40.11
Parsing update "Contact" set "CreatedDate"='2017-04-01T11:21:59.001+0000' where "Id"='1001uiP2niJPJGBa'; [Native-Transport-Requests-1] | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 146 | xxx.xx.40.11
Preparing statement [Native-Transport-Requests-1] | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 213 | xxx.xx.40.11
Determining replicas for mutation [Native-Transport-Requests-1] | 2019-01-14 16:13:37.133000 | xxx.xx.47.82 | 1895 | xxx.xx.40.11
Appending to commitlog [MutationStage-2] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2042 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-2] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2149 | xxx.xx.40.11
Sending MUTATION message to /xxx.xx.47.100 [MessagingService-Outgoing-/xxx.xx.47.100-Small] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2186 | xxx.xx.40.11
Sending MUTATION message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2232 | xxx.xx.40.11
MUTATION message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 28 | xxx.xx.40.11
Appending to commitlog [MutationStage-1] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 390 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-1] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 471 | xxx.xx.40.11
ESI decoding row 31303031756950326e694a504a474261 [MutationStage-1] | 2019-01-14 16:13:37.137000 | xxx.xx.47.100 | 579 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:13:37.137000 | xxx.xx.47.82 | 5160 | xxx.xx.40.11
ESI writing 31303031756950326e694a504a474261 to ES index [MutationStage-1] | 2019-01-14 16:13:37.137000 | xxx.xx.47.100 | 664 | xxx.xx.40.11
Processing response from /xxx.xx.47.49 [RequestResponseStage-4] | 2019-01-14 16:13:37.137000 | xxx.xx.47.82 | 5280 | xxx.xx.40.11
ESI index 31303031756950326e694a504a474261 done [MutationStage-1] | 2019-01-14 16:13:37.160000 | xxx.xx.47.100 | 23878 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.100 [MessagingService-Incoming-/xxx.xx.47.100] | 2019-01-14 16:13:37.160000 | xxx.xx.47.82 | 28445 | xxx.xx.40.11
Processing response from /xxx.xx.47.100 [RequestResponseStage-2] | 2019-01-14 16:13:37.160000 | xxx.xx.47.82 | 28549 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [MutationStage-1] | 2019-01-14 16:13:37.162000 | xxx.xx.47.100 | 25614 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:13:37.162000 | xxx.xx.47.100 | 25793 | xxx.xx.40.11
Request complete | 2019-01-14 16:13:37.814048 | xxx.xx.47.82 | 682048 | xxx.xx.40.11
Todas las actividades que comienzan por ESI son actividades de ESINDEX:
* ESI decoding row <rowId>: update request have been received by the ESIndex, row is being converted to JSON
* ESI writing <rowId> to ES index: update is being sent to ElasticSearch
* ESI index <rowId> done: ElasticSearch acknowledged the update
Este es un ejemplo de lo que sucede al buscar:
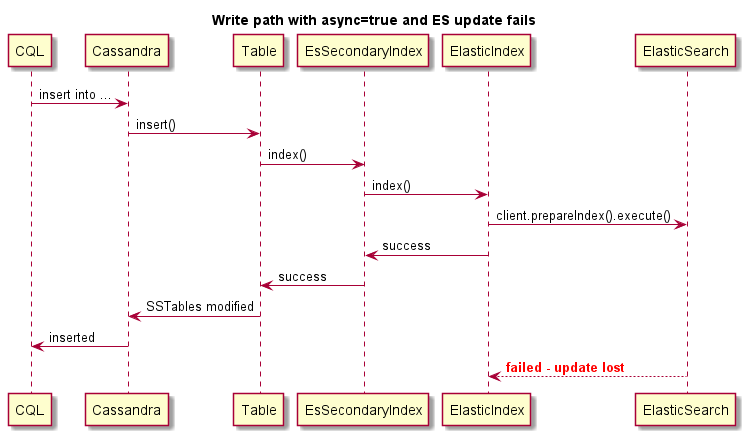
Este es un ejemplo de escritura sincrónica (la operación de Cassandra fallará si ES falla):
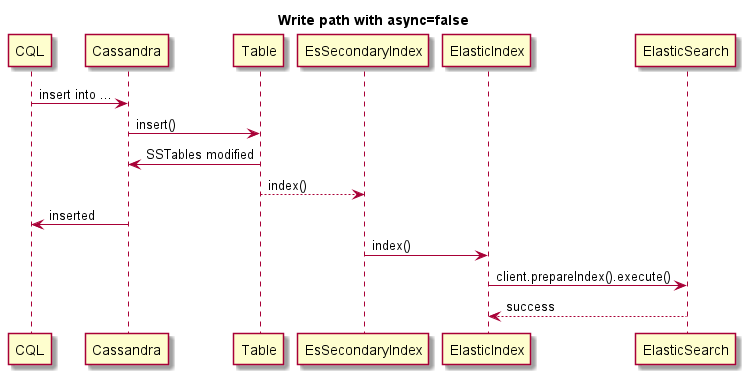
Este es un ejemplo de escritura asincrónica:
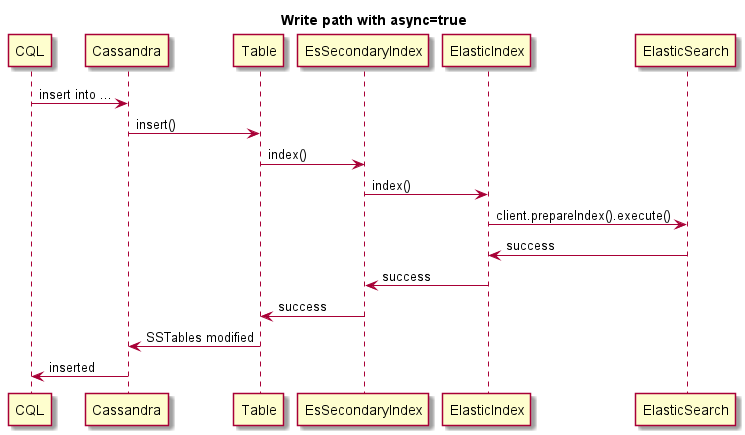
Este es un ejemplo de escritura asíncrona, la operación de Cassandra no fallará si FUSLE ES: