cassandra es index
1.0.0
<type>Cette documentation explique l'utilisation et la configuration de "Esindex" qui est un index secondaire basé sur Elasticsearch pour Cassandra.
Ce plugin nécessite un cluster Elasticsearch (ES) déjà configuré.
Le plugin s'installe dans une version régulière de Cassandra 4.0.x téléchargée à partir de http://cassandra.apache.org/. Il n'y a rien à modifier dans les fichiers de configuration de Cassandra pour prendre en charge l'index. Le comportement de Cassandra reste inchangé pour les applications qui n'utilisent pas l'index.
Une fois créé sur une table Cassandra, cet index permet d'effectuer des requêtes "Recherche de texte intégrale" sur Cassandra à l'aide de CQL et de retour des lignes correspondantes à partir des données de Cassandra. L'utilisation de ce plugin ne nécessite pas de modification du code source Cassandra, nous avons implémenté l'index Elasticsearch pour Cassandra en utilisant:
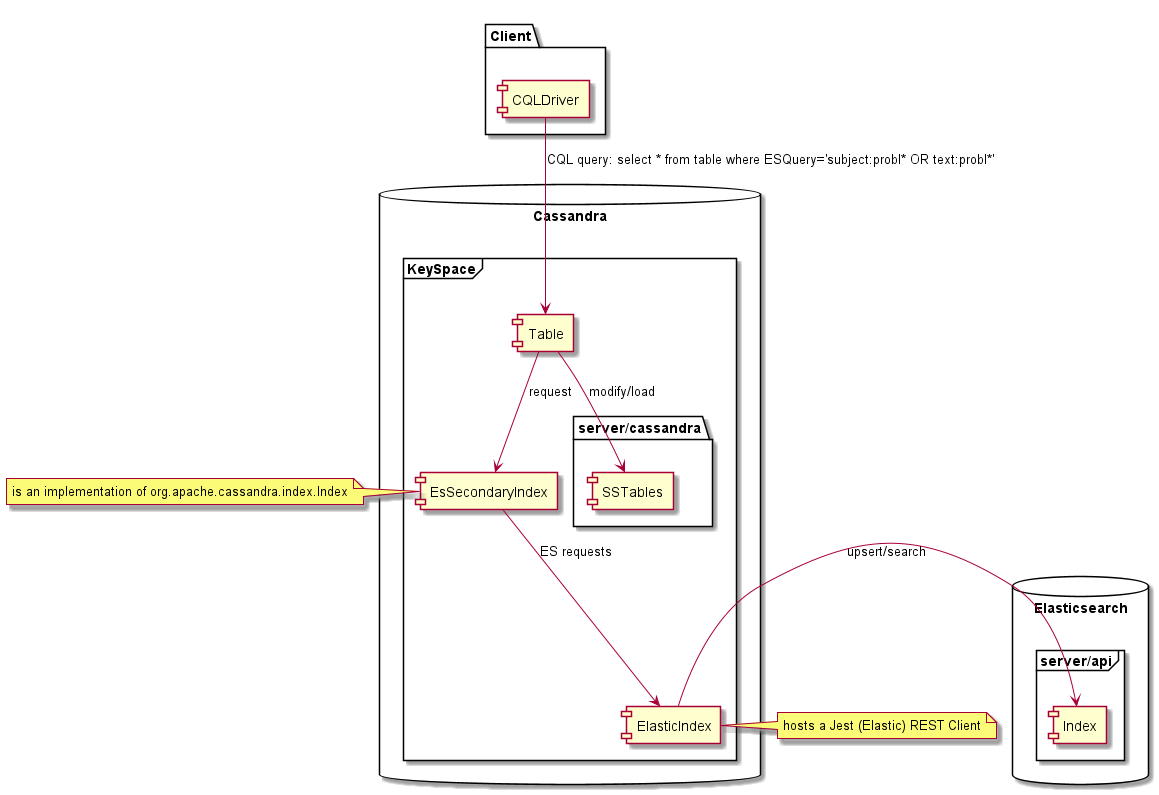
Les versions testées sont Elasticsearch 5.x, 6.x, 7.x et Cassandra 4.0.x. Cependant, le plugin peut également fonctionner avec différentes versions Elasticsearch (1.7, 2.x 5.x, 6.x, 7.x) si l'application fournit les mappages et options correspondants. D'autres versions d'Apache Cassandra comme 1.x 2.x, 3.x ou 4.1 ne sont pas prises en charge car l'interface d'index secondaire utilisé par le plugin est différente. D'autres vendeurs de Cassandra ne sont pas testés, Scylladb n'est pas pris en charge.
| Versions | Elasticsearch 1.x | Elasticsearch 2.x | Elasticsearch 5.x | Elasticsearch 6.x | Elasticsearch 7.x |
|---|---|---|---|---|---|
| Cassandra 1.x | Non | Non | Non | Non | Non |
| Cassandra 2.x | Non | Non | Non | Non | Non |
| Cassandra 3.x | Non | Non | Non | Non | Non |
| Cassandra 4.x | Limité | Limité | Limité | Oui | Oui |
Ce projet nécessite Maven et compile avec Java 8. Pour construire le plugin, à la racine du projet Exécuter:
Package Clean MVN
Cela construira un "tout en un pot" dans target/distribution/lib4cassandra
<dependency>
<groupId>com.genesyslab</groupId>
<artifactId>es-index</artifactId>
<version>9.2.000.00</version>
</dependency>
Voir le package GitHub
Voir le référentiel Maven
Mettez es-index-9.2.000.xx-jar-with-dependencies.jar dans le dossier lib de Cassandra avec d'autres pots Cassandra, par exemple '/ usr / share / Cassandra / lib' sur tous les nœuds Cassandra. Commencez ou redémarrez vos nœuds Cassandra.
En raison du manque de tests, les tables avec des clés de clustering ne sont pas prises en charge. Seule une clé de partition est prise en charge, les clés de partition composite doivent fonctionner mais n'ont pas été testées largement.
ESINDEX ne prend en charge que le niveau de ligne TTL où toutes les cellules expireront en même temps et le document ES correspondant peut être supprimé en même temps. Si une ligne a des cellules qui expirent à différents moments, le document correspondant sera supprimé lorsque la dernière cellule expire. Si vous utilisez différentes cellules TTL, les données renvoyées à partir d'une recherche seront toujours cohérentes car les données sont lues à partir de SSTABLES, mais il sera toujours possible de trouver la ligne à l'aide de données expirées à l'aide d'une requête ES.
Il est possible de créer plusieurs index sur le même tableau, Esindex ne l'empêchera pas. Cependant, si plus d'un Esindex existe, le comportement peut être incohérent, une telle configuration n'est pas prise en charge. La commande CQLSH 'décrire la table <ks.tableName>' peut être utilisée pour afficher des index créés sur la table et les déposer si nécessaire.
Par souci de simplicité, créez d'abord cet espace de touche:
CREATE KEYSPACE genesys WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1}
Utilisons le tableau ci-dessous comme exemple:
CREATE TABLE genesys.emails (
id UUID PRIMARY KEY,
subject text,
body text,
userid int,
query text
);
Vous devez consacrer une colonne de texte factice pour l'utilisation d'index. Cette colonne ne doit jamais recevoir de données. Dans cet exemple, la colonne query est la colonne factice.
Voici comment créer l'index pour la table d'exemple et utiliser EShost pour Elasticsearch:
CREATE CUSTOM INDEX ON genesys.emails(query)
USING 'com.genesyslab.webme.commons.index.EsSecondaryIndex'
WITH OPTIONS = {'unicast-hosts': 'eshost:9200'};
Par exemple, si votre serveur Elasticsearch écoute sur localhost , remplacez Eshost par localhost .
Les erreurs renvoyées par CQL sont très limitées, si quelque chose ne va pas, comme votre hôte elasticsearch indisponible, vous obtiendrez un délai ou un autre type d'exception. Vous devrez vérifier les journaux Cassandra pour comprendre ce qui a mal tourné.
Nous n'avons fourni aucun mappage, nous comptons donc sur la cartographie dynamique Elasticsearch, insérons certaines données:
INSERT INTO genesys.emails (id, subject, body, userid)
VALUES (904b88b2-9c61-4539-952e-c179a3805b22, 'Hello world', 'Cassandra is great, but it''s even better with EsIndex and Elasticsearch', 42);
Vous pouvez voir que l'index est créé dans Elasticsearch si vous avez l'accès aux journaux:
[o.e.c.m.MetaDataCreateIndexService] [node-1] [genesys_emails_index@] creating index, cause [api], templates [], shards [5]/[1], mappings []
[INFO ][o.e.c.m.MetaDataMappingService] [node-1] [genesys_emails_index@/waSGrPvkQvyQoUEiwqKN3w] create_mapping [emails]
Maintenant, nous pouvons rechercher Cassandra en utilisant Elasticsearch via l'index, voici une recherche de syntaxe Lucene:
select id, subject, body, userid, query from emails where query='body:cassan*';
id | subject | body | userid | query
--------------------------------------+-------------+-------------------------------------------------------------------------+--------+-------
904b88b2-9c61-4539-952e-c179a3805b22 | Hello world | Cassandra is great, but it's even better with EsIndex and Elasticsearch | 42 |
{
"_index": "genesys_emails_index@",
"_type": "emails",
"_id": "904b88b2-9c61-4539-952e-c179a3805b22",
"_score": 0.24257512,
"_source": {
"id": "904b88b2-9c61-4539-952e-c179a3805b22"
},
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.24257512
}
}
(1 rows)
(JSON a été formaté)
Toutes les lignes contiendront des données de Cassandra chargées à partir de SSTABLES en utilisant la cohérence CQL. Les données de la colonne «Query» sont les métadonnées renvoyées par Elasticsearch.
Voici comment interroger ElasticSearch pour vérifier le mappage généré: GET http://eshost:9200/genesys_emails_index@/emails/_mapping?pretty
{
"genesys_emails_index@" : {
"mappings" : {
"emails" : {
"properties" : {
"IndexationDate" : {
"type" : " date "
},
"_cassandraTtl" : {
"type" : " long "
},
"body" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"id" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"subject" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"userid" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
}
}
}
}
}
}Le plugin ESINDEX a ajouté deux champs:
Nous pouvons voir que le mappage semble bien, mais Elasticsearch n'a pas remarqué que l'utilisateur est un entier et les champs ajoutés [mot-clé] à tous les texte.
Voici à quoi ressemblent les données dans Elasticsearch:
GET http://localhost:9200/genesys_emails_index@/emails/_search?pretty&q=body:cassandra
{
"took" : 2 ,
"timed_out" : false ,
"_shards" : {
"total" : 5 ,
"successful" : 5 ,
"skipped" : 0 ,
"failed" : 0
},
"hits" : {
"total" : 1 ,
"max_score" : 0.2876821 ,
"hits" : [
{
"_index" : " genesys_emails_index@ " ,
"_type" : " emails " ,
"_id" : " 904b88b2-9c61-4539-952e-c179a3805b22 " ,
"_score" : 0.2876821 ,
"_source" : {
"id" : " 904b88b2-9c61-4539-952e-c179a3805b22 " ,
"body" : " Cassandra is great, but it's even better with EsIndex and Elasticsearch " ,
"subject" : " Hello world " ,
"userid" : " 42 " ,
"IndexationDate" : " 2019-01-15T16:53:00.107Z " ,
"_cassandraTtl" : 2147483647
}
}
]
}
} Corrigeons le mappage en supprimant l'index: drop index genesys.emails_query_idx; Cela supprimera également l'index et les données Elasticsearch!
et recréez-le avec une cartographie appropriée:
CREATE CUSTOM INDEX ON genesys.emails(query)
USING 'com.genesyslab.webme.commons.index.EsSecondaryIndex'
WITH OPTIONS = {
'unicast-hosts': 'localhost:9200',
'mapping-emails': '
{
"emails":{
"date_detection":false,
"numeric_detection":false,
"properties":{
"id":{
"type":"keyword"
},
"userid":{
"type":"long"
},
"subject":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"body":{
"type":"text"
},
"IndexationDate":{
"type":"date",
"format":"yyyy-MM-dd''T''HH:mm:ss.SSS''Z''"
},
"_cassandraTtl":{
"type":"long"
}
}
}
}
'};
Cela créera un nouvel index à condition de mappage et de réindexer les données qui se trouvent dans Cassandra.
Voici la cartographie ES résultante:
{
"genesys_emails_index@" : {
"mappings" : {
"emails" : {
"date_detection" : false ,
"numeric_detection" : false ,
"properties" : {
"IndexationDate" : {
"type" : " date " ,
"format" : " yyyy-MM-dd'T'HH:mm:ss.SSS'Z' "
},
"_cassandraTtl" : {
"type" : " long "
},
"body" : {
"type" : " text "
},
"id" : {
"type" : " keyword "
},
"subject" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"userid" : {
"type" : " long "
}
}
}
}
}
}Maintenant que le mappage est correctement défini, nous pouvons rechercher UserId comme un nombre. Dans cet exemple, nous utilisons Elasticsearch Query DSL:
select id, subject, body, userid from genesys.emails
where query='{"query":{"range":{"userid":{"gte":10,"lte":50}}}}';
@ Row 1
---------+-------------------------------------------------------------------------
id | 904b88b2-9c61-4539-952e-c179a3805b22
subject | Hello world
body | Cassandra is great, but it's even better with EsIndex and Elasticsearch
userid | 42
Il est très important d'obtenir la cartographie juste avant de commencer la production. La réindexation d'une grande table prendra beaucoup de temps et mettra une charge importante sur Cassandra et Elasticsearch. Vous devrez vérifier les journaux Cassandra pour les erreurs dans votre mappage ES. Assurez-vous d'échapper aux citations simples (') en les doubler dans les options JSON fournies à la commande Create Index.
Vous trouverez ci-dessous toutes les options liées à la configuration de l'index Elasticsearch. Les noms de clés peuvent utiliser le trait d'union '-' char ou des points. Par exemple, les deux noms fonctionneront:
Notez que toutes les options ci-dessous sont spécifiques à la mise en œuvre de Genesys et non à Elasticsearch elle-même.
Si les classes de plaisanterie ne sont pas trouvées, le mode factice est activé et aucun autre cas ne s'applique.
Multi-Datacenter est pris en charge et les données sont reproduites via la réplication des potins de Cassandra uniquement. Les clusters ES sur différents CD ne sont pas les mêmes et ne devraient jamais être réunis ou les performances seront affectées. Étant donné que les données sont reproduites au niveau du tableau, Esindex recevra une mise à jour dans chaque cluster DC et local ES sera également mis à jour.
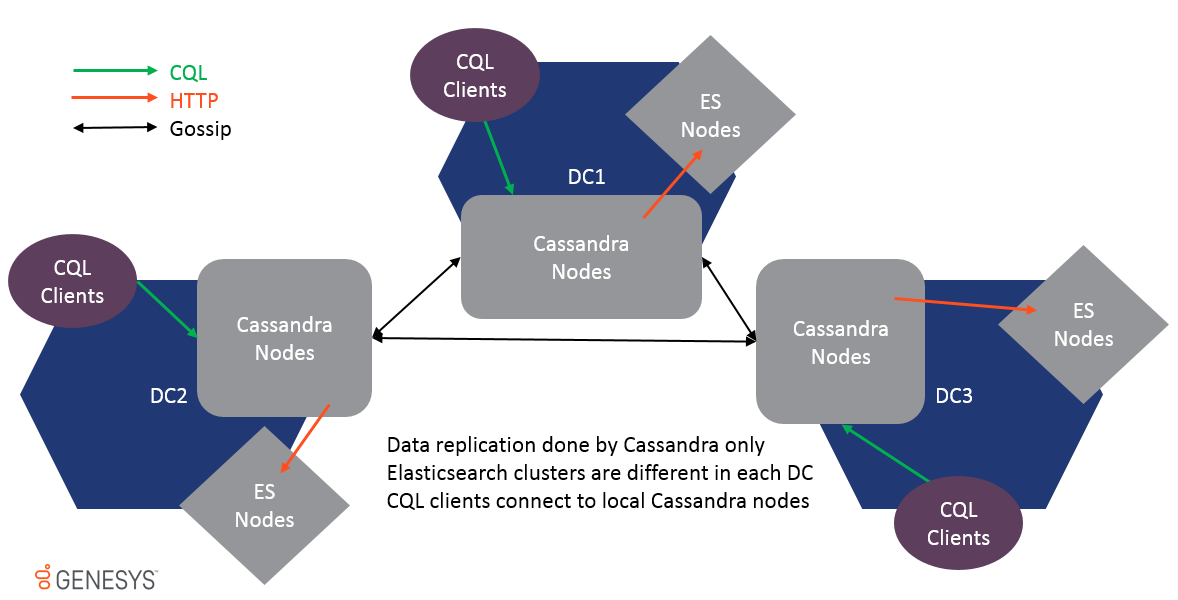
Pour prendre en charge le multi-DC, toutes les options peuvent être préfixées par le nom de centre de données et le nom du rack pour rendre les paramètres spécifiques à l'emplacement, par exemple:
Pour fournir l'indice Cassandra pour Elasticsearch avec des informations d'identification, chaque nœud doit avoir la variable d'environnement Escredentials correctement défini avant de commencer. Cela doit être réglé sur tous les hôtes de Cassandra.
L'exemple ci-dessous fournit le mot de passe pour l'utilisateur «élastique» et le mot de passe »ExemplePassword 'séparé par: (colon) Caractère. Cela peut être fait directement dans le système en tant que variable d'environnement ou dans le raccourci qui lance Cassandra.
ESCREDENTIELS = ELASTIC: ExemplePassword Une fois que l'index est initialisé avec succès, il rédigera "Elasticsearch Indementiels fourni" dans les journaux Cassandra au niveau de l'information. Une fois ce message de sortie, il est possible d'effacer la variable d'environnement. Si Cassandra est redémarré, la variable d'environnement doit être rejetée avant de commencer. Les informations d'identification sont conservées en mémoire uniquement et ne sont enregistrées nulle part ailleurs. Si l'utilisateur et / ou le mot de passe est modifié, tous les nœuds Cassandra doivent être redémarrés avec la valeur de variable d'environnement mise à jour.
Dans l'ensemble d'options d'index
Unicast-hôtes = https : //<host name>:9200
Il n'est actuellement pas possible de migrer un indice existant de HTTP à HTTPS, l'utilisation de l'une ou l'autre doit être décidée avant de créer le schéma Cassandra. Afin de faciliter le déploiement HTTPS, l'index fera automatiquement confiance à tous les certificats HTTPS.
Il est possible de conserver les données du côté d'Elasticsearch pendant une période plus longue que Cassandra TTL définie. Ce mode est tourné à l'aide de l'option ES-Analytique en mode. Lorsque l'option est activée, ElasticIndex sautera toutes les opérations de suppression.
Pour empêcher les données de croître trop du côté ES, il est conseillé d'utiliser des paramètres TTL-Shift et Force-Delete.
Lors de la création de l'index, vous offrez des options d'index, ainsi que des options d'index Elasticsearch à l'aide de la commande CQL «Utilisation de l'option».
Les options d'index doivent être spécifiées à la création d'index, voici un exemple
CREATE CUSTOM INDEX on genesys.email(query) using 'com.genesyslab.webme.commons.index.EsSecondaryIndex' WITH options =
{
'read-consistency-level':'QUORUM',
'insert-only':'false',
'index-properties': '{
"index.analysis.analyzer.dashless.tokenizer":"dash-ex",
"index.analysis.tokenizer.dash-ex.pattern":"[^\\w\\-]",
"index.analysis.tokenizer.dash-ex.type":"pattern"
}',
'mapping-email': '{
"email": {
"dynamic": "false",
"properties": {
"subject" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}',
'discard-nulls':'false',
'async-search':'true',
'async-write':'false'
};
Vous pouvez également définir ou remplacer les options en utilisant des variables d'environnement ou des propriétés du système Java en préfixant les options avec «Genesys-ES-».
Les options fournies dans la commande "Create Custom Index" sont utilisées en premier. Ils peuvent être remplacés localement à l'aide d'un fichier nommé es-index.properties trouvé dans ".", "./Conf/", "../conf/" ou "./bin/". (Peut être modifié avec -DGENESYS-ES-ESI-FILE ou -DGENESYS.es.esi.File Système Propriété)
Voici un exemple pour le contenu du fichier:
insert-only = true Discard-nulls = false async-write = false
| Nom | Défaut | Description |
|---|---|---|
| Résultes max | 10000 | Nombre de résultats à lire à partir de recherches ES pour charger les lignes Cassandra. |
| au niveau de la lecture | UN | Utilisé pour les recherches, ce niveau de cohérence est utilisé pour charger les lignes Cassandra. |
| insert uniquement | FAUX | Par défaut, Esindex utilisera les opérations Upsert. En mode insérer uniquement, les données seront toujours écrasées. |
| asynchronisme | vrai | Envoie des mises à jour d'indexes de manière asynchrone sans vérifier l'exécution correcte. Cela fournit des écritures beaucoup plus rapides, mais les données peuvent devenir incohérentes si le cluster ES n'est pas disponible, car les écritures n'échoueront pas. La valeur par défaut est vraie. |
| segment | DÉSACTIVÉ | OFF, HEUR, JOUR, MOIS, ANNÉE, La segmentation automatique de l'index personnalisée est contrôlée par ce paramètre. S'il est mis à jour, chaque jour, un nouvel index sera créé sous l'alias. Notez que les index vides sont supprimés automatiquement toutes les heures. Remarque: le réglage de l'heure est découragé car il créera de nombreux index et peut réduire les performances. Ce paramètre est conseillé à des fins de développement et de test. |
| nom de segment | Si segment = personnalisé, cette valeur sera utilisée pour la nouvelle création d'index. | |
| mappage- <pype> | {} | Pour chaque index secondaire, le nom du tableau est passé sous forme de type, par exemple mapping-visit = {JSON Definition}. |
| hôtes unicast | http: // localhost: 9200 | Une liste d'hôte séparée par des virgules peut être HOST1, HOST2, HOST3 ou http: // host1, http: // host2, http: // host3 ou http: // host1: 9200, http: // host2: 9200, http: // host3: 9200. Si le protocole ou le port manque HTTP et 9200 supposé. Il est possible d'utiliser HTTPS. |
| écarter | vrai | Ne transmettez pas les valeurs NULL à l'indice ES, cela signifie que vous ne pourrez pas supprimer une valeur. La valeur par défaut est vraie . |
| index-propriétés | {} | Les propriétés en tant que chaîne JSON, passées pour créer un nouvel index, peuvent contenir des définitions de tokenzer par exemple. |
| champs réalisés en JSON | {} | Une chaîne séparée par coma définissant qu'une colonne de chaîne doit être indexée en tant que chaîne JSON. Les cordes non analyséables non JSON empêcheront les inserts à Cassandra. |
| champs de série JSON-FLAT | {} | Une chaîne séparée par le coma définissant qu'une colonne de chaîne doit être indexée en tant que document JSON de type type. Elasticsearch JSON Mapping ne permet pas d'indexer une valeur qui changera le type au fil du temps. Par exemple {"Key": "Value"} ne peut pas devenir {"Key": {"Subkey": "Value"}} Dans Elasticsearch, vous obtiendrez une exception de mappage. Un tel JSON-FLAT sera convertisseur en un objet JSON qui a des touches de chaîne et des tableaux de chaîne comme valeurs. |
| factice | FAUX | Désactive complètement l'index secondaire. Notez que si les classes de plaisanterie ne sont pas trouvées, l'index sera automatiquement mis en mode factice. |
| valider les quelles | FAUX | Envoie des requêtes de recherche à ES pour la validation afin de fournir des erreurs de syntaxe significatives au lieu des délais d'attente de Cassandra. |
| verrouillage concurrent | vrai | Verrouille les exécutions de l'index sur l'ID de partition. Cela empêche les problèmes de concurrence lorsqu'il s'agit de plusieurs mises à jour sur la même partition en même temps. |
| skip-log-replay | vrai | Lorsqu'un nœud Cassandra démarre, il rejouera le journal de validation, ces mises à jour sont ignorées pour améliorer le temps de démarrage car elles ont déjà été appliquées à ES. |
| sauter-non-local-updates | vrai | Pour améliorer les performances, l'activation de ce paramètre exécutera uniquement les mises à jour d'index sur la réplique maître de la plage de jetons. |
| en mode analytique ES | FAUX | Désactive les suppressions (TTL ou Supprimer) des documents ES. |
| type-pipelines | aucun | Liste de type pour configurer les pipelines. |
| pipeline- <type> | aucun | Définition du pipeline pour ce type. |
| index.translog.durabilité | asynchrone | Lors de la création d'un index, nous utilisons le mode de validation asynchrone pour garantir les meilleures performances, c'était le paramètre par défaut dans ES 1.7. Depuis 2.x, c'est une synchronisation entraînant une grave dégradation des performances. |
| Disponible - reconstruire | vrai | Lors de la création d'un nouvel index, il est possible (ou non) d'exécuter des recherches sur l'index partiel. |
| retransmis | FAUX | Tronquer l'indice ES avant la reconstruction. |
| période de purge | 60 | Toutes les 60 minutes, tous les index vides seront supprimés de l'alias. |
| de type par index | vrai | Présentez le nom d'index avec le nom de la table. Dans ES 5.x, il n'est plus possible d'avoir un mappage différent pour le même nom de champ dans différents types du même index. Dans ES 6.x, les types seront supprimés. |
| se débarrasser de la force | FAUX | Chaque minute, une demande "Supprimer par requête" est envoyée à ES pour supprimer des documents qui ont expiré _cassandrattl. Il s'agit d'imiter la fonctionnalité TTL qui a été supprimée dans ES 5.x. Notez que bien que le compactage de Cassandra supprime réellement le document de l'ES, il n'y a aucune garantie sur le moment où cela se produira. |
| ttl shift | 0 | Temps en quelques secondes pour déplacer Cassandra TTL. Si TTL était 1H à Cassandra et que Shift est de 3600, cela signifie que le document dans ES sera supprimé 1H plus tard que Cassandra. |
| manager indexé | com.genesyslab.webme.commons.index.defaultIndexManager | Index Manager Nom de la classe. Est utilisé pour la fonctionnalité de segmentation et d'expiration du gestionnaire. |
| taille de la taille d'un segment | 86400000 | Cale de temps du segment en millisecondes. Chaque nouvel index de «taille de segment», un nouvel index sera créé en suivant le modèle: <lias_name> _index @ <yyymmmdT'hhmmss'z '> |
| max-connections-per-route | 2 | Nombre de connexions HTTP par nœud ES, par défaut est la valeur du pool HTTP Apache, peut augmenter les performances de l'indice Cassandra mais augmenter la charge sur ES. (Nouveau dans le COE 9.0.000.15) |
Vous devez désactiver la détection des dates dans votre définition de cartographie.
Le JSON suivant:
{
"maps" : {
"key1" : " value " ,
"key2" : 42 ,
"keymap" : {
"sss1" : null ,
"sss2" : 42 ,
"sss0" : " ffff "
},
"plap" : " plop "
},
"string" : " string " ,
"int" : 42 ,
"plplpl" : [ 1 , 2 , 3 , 4 ]
}Sera converti en:
{
"maps" : [ " key1=value " , " key2=42 " , " keymap={sss1=null, sss2=42, sss0=ffff} " , " plap=plop " ],
"string" : [ " string " ],
"int" : [ " 42 " ],
"plplpl" : [ " 1 " , " 2 " , " 3 " , " 4 " ]
}Valeurs possibles:
<type>Voir la documentation Elasticsearch pour plus de détails sur la mappage de type: http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/mapping.html
Tous les types de colonnes Cassandra sont pris en charge, les données seront envoyées sous forme de chaîne, de tableau ou de carte en fonction du type Cassandra. Avec le mappage approprié, Elasticsearch convertira ensuite les données en type pertinent. Cela permettra de bien meilleures recherches et rapports.
| Types de Cassandra | Mappage recommandé par Elasticsearch | Commentaire |
|---|---|---|
| ascii | texte ou mot-clé | Voir la section suivante sur le type de texte |
| grand | long | |
| goutte | désactivé | Il n'est pas possible d'indexer le contenu binaire |
| booléen | booléen | |
| comptoir | long | |
| date | date | |
| décimal | double | |
| double | double | |
| flotter | double | |
| inédire | mot-clé | ES IP n'est pas testé |
| int | int | |
| Liste <type> | Idem que le type | ES s'attend à ce qu'un type puisse être une seule valeur ou un tableau |
| map < typek , typv > | objet | Si vos clés peuvent avoir beaucoup de valeurs différentes, méfiez-vous de la cartographie de l'explosion |
| set <pype> | Idem que le type | ES s'attend à ce qu'un type puisse être une seule valeur ou un tableau |
| petit | int | |
| texte | texte ou mot-clé | Voir la section suivante sur le type de texte |
| temps | mot-clé | |
| horodatage | "Type": "Date", "Format": "Yyyy-mm-d't'hh: mm: SS.SSS'Z '" | |
| timeuuid | mot-clé | |
| minuscule | int | |
| Tuple <type1 Type2, ...> | taper | |
| uuid | mot-clé | |
| varchar | texte ou mot-clé | Voir la section suivante sur le type de texte |
| variante | long | |
| Type défini par l'utilisateur | objet | Chaque champ UDT sera mappé à l'aide de ses noms et valeurs |
Cartographie du type de texte
Lorsqu'une colonne de texte (ASCII ou VARCHAR) est envoyée à ES, il est envoyé comme texte brut à indexer. Cependant, si le texte est un JSON approprié, il est possible de l'envoyer en tant que document JSON à indexer. Cela permet d'indexer / rechercher le document au lieu du texte brut.
L'utilisation d'un tel mappage JSON permet de rechercher des données à l'aide de "Columnname.Key: Value".
Si vos clés peuvent avoir beaucoup de valeurs différentes, méfiez-vous de la cartographie de l'explosion
champs réalisés par JSON (voir les options pour plus de détails)
Le contenu du texte est envoyé comme JSON. Dans votre cartographie, vous pouvez définir chaque champ de document séparément. Notez qu'une fois qu'un champ a été cartographié en tant que type, soit par cartographie statique, soit par mappage dynamique, fournir un type incompatible entraînera des échecs d'écriture de Cassandra.
Champs réalisés par JSON-FLAT (Voir Options pour les détails et l'exemple de conversion)
Le contenu du texte est également envoyé sous forme de JSON, mais toutes les valeurs sont obligées de tableaux de chaînes plates. Cela limitera la possibilité de rechercher dans JSON imbriqué mais est plus sûr si vous ne pouvez pas contrôler le type JSON des valeurs.
Il s'agit d'une implémentation personnalisée d'un indice Cassandra. Cela introduit certaines limites liées au modèle de cohérence de Cassandra. La principale limitation est due à la nature des indices secondaires de Cassandra, chaque nœud Cassandra ne contient que des données qu'il est responsable dans le ring de Cassandra, avec des index secondaires c'est la même chose, chaque nœud index uniquement ses données locales. Cela signifie que lorsque vous effectuez une requête sur l'index, la requête est envoyée à tous les nœuds, puis les résultats sont agrégés par le coordinateur de la requête et retournés aux clients.
Avec Esindex, il est différent, car la recherche d'index est basée sur Elasticsearch, chaque nœud est capable de répondre à la requête. Cela signifie que la requête ne doit être envoyée qu'à un seul nœud ou que le résultat contiendra des doublons. Ceci est réalisé en forçant un jeton à la requête CQL comme ci-dessous.
select * from emails where query='subject:12345' and token(id)=0;
Le jeton doit être une valeur longue aléatoire pour répandre les requêtes à travers les nœuds. Il doit être construit sur la clé de partition de la ligne, «id» dans l'exemple ci-dessus.
Dans l'exemple ci-dessus, la requête Elasticsearch est «Sujet: 12345». Ceci est une requête de Lucene. Il est également possible d'exécuter les requêtes DSL Voir la page Elasticsearch Query-DSL pour plus de détails.
Un seul indice Elasticsearch contiendra tous les index de table Cassandra pour un espace de clé donné. Pour chaque index, un type dédié Elasticsearch est utilisé. Afin de permettre des agrégations à table croisée, le type n'est pas appliqué dans les requêtes. Cela signifie que si votre requête peut correspondre à différents types, il renverra plus d'ID que prévu. Étant donné que ceux-ci ne correspondent pas aux lignes de Cassandra, vous n'obtiendrez pas plus de résultats, mais vous pourriez également obtenir moins si vous limitez le nombre de résultats retournés.
Si le nombre de lignes apparié est élevé et que les lignes sont grandes, les recherches peuvent se terminer par un délai de lecture. Vous ne pouvez demander que PK à retourner avec les métadonnées ES, puis charger les lignes en parallèle à partir de votre code à l'aide de requêtes CQL.
Afin de dire à l'index pour retourner PK
select * from emails where query='#options:load-rows=false#id:ab*';
Il est important de noter que les lignes renvoyées sont fausses et construites à partir des résultats de la requête ELASICSEARCH. Cela signifie que les lignes retournées peuvent ne plus exister:
poule une demande de recherche renvoie un résultat, la première ligne contiendra les métadonnées Elasticsearch en tant que ## une chaîne JSON dans la colonne de l'index. Voir par exemple:
cqlsh:ucs> select id,query from emails where query='id:00008RD9PrJMMmpr';
id | query
------------------+---------------------------------------------------------------------------------------------------------------------
00008RD9PrJMMmpr | {"took":5,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":1,"max_score":7.89821}}
Le mécanisme de segmentation d'Esindex divise l'indice monolithique Elasticsearch à la séquence des index basés sur le temps. Les objectifs qui suit:
Puisque Elasticsearch 5.x TTL n'est plus pris en charge. Cependant, les processus normaux de compactage et de réparation normaux de Cassandra suppriment automatiquement les données de pierre tombale, ElasticIndex supprimera les données d'Elasticsearch.
ESINDEX prend en charge le traçage CQL, il peut être activé sur un nœud ou à l'aide de CQLSH avec la commande ci-dessous:
Traçage sur;
Sélectionne le traçage , vous obtiendrez des traces à partir de toute la requête contre tous les nœuds participants:
cqlsh:ucs> select * from "Contact" where "ESQuery"='AttributeValues.LastName:ab*' and token("Id")=0 limit 1;
Id | AttributeValues | AttributeValuesDate | Attributes| CreatedDate | ESQuery | ExpirationDate | MergeIds | ModifiedDate| PrimaryAttributes| Segment| TenantId
1001uiP2niJPJGBa | {"LastName":["IdentifyTest-aBEcKPnckHVP"],"EmailAddress":["IdentifyTest-HHzmNornOr"]} |{} | {'EmailAddress_IdentifyTest-HHzmNornOr': {Id: 'EmailAddress_IdentifyTest-HHzmNornOr', Name: 'EmailAddress', StrValue: 'IentifyTest-HHzmNornOr', Description: null, MimeType: null, IsPrimary: False}, 'LastName_IdentifyTest-aBEcKPnckHVP': {Id: 'LastName_IdentifyTest-aBEcKPnckHVP', Name: 'LastName', StrValue: 'IdentifyTest-aBEcKPnckHVP', Description: null, MimeType: null IsPrimary: False}} | 2018-10-30 02:05:06.960000+0000 | {"_index":"ucsperf2_contact_index@","_type":"Contact","_id":"1001uiP2niJPJGBa","_score":1.0,"_source":{"Id":"1001uiP2niJPJGBa"},"took":485,"timed_out":false,"_shards":{"total":5,"successful":5,failed":0},"hits":{"total":18188,"max_score":1.0}} | null | null | 2018-10-30 02:05:06.960000+0000 | {'EmailAddress': 'IdentifyTest-HHzmNornOr', 'LastName': 'IdentifyTest-aBEcKPnckHVP'} | not-applicable |1
(1 rows)
Ensuite, vous obtiendrez des informations sur votre session:
Session de traçage: 8ED07B60-180D-11E9-B832-33A77983333
activity | timestamp | source | source_elapsed | client
-----------------------------------------------------------------------------------------------------------------------------------------+----------------------------+---------------+----------------+--------------
Execute CQL3 query | 2019-01-14 16:03:32.118000 | xxx.xx.47.82 | 0 | xxx.xx.40.11
RANGE_SLICE message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:02:30.200000 | xxx.xx.47.49 | 34 | xxx.xx.40.11
Executing read on ucsperf2.Contact using index Contact_ESQuery_idx [ReadStage-1] | 2019-01-14 16:02:30.201000 | xxx.xx.47.49 | 411 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 Searching 'AttributeValues.LastName:ab*' [ReadStage-1] | 2019-01-14 16:02:30.201000 | xxx.xx.47.49 | 693 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 Found 10000 matching ES docs in 514ms [ReadStage-1] | 2019-01-14 16:02:30.716000 | xxx.xx.47.49 | 515336 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 StreamingPartitionIterator initialized [ReadStage-1] | 2019-01-14 16:02:30.717000 | xxx.xx.47.49 | 516911 | xxx.xx.40.11
reading data from /xxx.xx.47.100 [ReadStage-1] | 2019-01-14 16:02:30.717000 | xxx.xx.47.49 | 517121 | xxx.xx.40.11
speculating read retry on /xxx.xx.47.82 [ReadStage-1] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517435 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517436 | xxx.xx.40.11
Sending READ message to /xxx.xx.47.100 [MessagingService-Outgoing-/xxx.xx.47.100-Small] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517445 | xxx.xx.40.11
Sending READ message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517558 | xxx.xx.40.11
Acquiring sstable references [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517866 | xxx.xx.40.11
Bloom filter allows skipping sstable 83 [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517965 | xxx.xx.40.11
Partition index with 0 entries found for sstable 400 [ReadStage-2] | 2019-01-14 16:02:30.719000 | xxx.xx.47.49 | 518300 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:02:30.720000 | xxx.xx.47.49 | 519720 | xxx.xx.40.11
Processing response from /xxx.xx.47.82 [RequestResponseStage-4] | 2019-01-14 16:02:30.720000 | xxx.xx.47.49 | 519865 | xxx.xx.40.11
Bloom filter allows skipping sstable 765 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522352 | xxx.xx.40.11
Bloom filter allows skipping sstable 790 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522451 | xxx.xx.40.11
Bloom filter allows skipping sstable 819 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522516 | xxx.xx.40.11
Bloom filter allows skipping sstable 848 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522662 | xxx.xx.40.11
Bloom filter allows skipping sstable 861 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522741 | xxx.xx.40.11
Skipped 0/7 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522855 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-2] | 2019-01-14 16:02:30.723001 | xxx.xx.47.49 | 523075 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-2] | 2019-01-14 16:02:30.723001 | xxx.xx.47.49 | 523164 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524717 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 StreamingPartitionIterator closed [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524805 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524872 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524971 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.100 [MessagingService-Incoming-/xxx.xx.47.100] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528222 | xxx.xx.40.11
Processing response from /xxx.xx.47.100 [RequestResponseStage-1] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528364 | xxx.xx.40.11
Initiating read-repair [RequestResponseStage-1] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528481 | xxx.xx.40.11
Parsing select * from "Contact" where "ESQuery"='AttributeValues.LastName:ab*' and token("Id")=0 limit 1; [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 174 | xxx.xx.40.11
Preparing statement [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 254 | xxx.xx.40.11
Index mean cardinalities are Contact_ESQuery_idx:-2109988917941223823. Scanning with Contact_ESQuery_idx. [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 418 | xxx.xx.40.11
Computing ranges to query [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2480 | xxx.xx.40.11
Submitting range requests on 1 ranges with a concurrency of 1 (-4.6099044E15 rows per range expected) [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2568 | xxx.xx.40.11
Enqueuing request to /xxx.xx.47.49 [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2652 | xxx.xx.40.11
Submitted 1 concurrent range requests [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2708 | xxx.xx.40.11
Sending RANGE_SLICE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2874 | xxx.xx.40.11
READ message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.640000 | xxx.xx.47.100 | 29 | xxx.xx.40.11
READ message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521263 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521468 | xxx.xx.40.11
Acquiring sstable references [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521566 | xxx.xx.40.11
Partition index with 0 entries found for sstable 1187 [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521775 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-1] | 2019-01-14 16:03:32.641000 | xxx.xx.47.100 | 266 | xxx.xx.40.11
Bloom filter allows skipping sstable 1188 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522130 | xxx.xx.40.11
Acquiring sstable references [ReadStage-1] | 2019-01-14 16:03:32.641000 | xxx.xx.47.100 | 361 | xxx.xx.40.11
Bloom filter allows skipping sstable 1189 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522205 | xxx.xx.40.11
Bloom filter allows skipping sstable 1190 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522259 | xxx.xx.40.11
Skipped 0/5 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522303 | xxx.xx.40.11
Bloom filter allows skipping sstable 1186 [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522415 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522540 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522679 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.49 [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522734 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522863 | xxx.xx.40.11
Partition index with 0 entries found for sstable 1208 [ReadStage-1] | 2019-01-14 16:03:32.644000 | xxx.xx.47.100 | 3756 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.647000 | xxx.xx.47.82 | 528443 | xxx.xx.40.11
Processing response from /xxx.xx.47.49 [RequestResponseStage-2] | 2019-01-14 16:03:32.647000 | xxx.xx.47.82 | 528516 | xxx.xx.40.11
Bloom filter allows skipping sstable 1209 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9090 | xxx.xx.40.11
Bloom filter allows skipping sstable 1210 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9162 | xxx.xx.40.11
Bloom filter allows skipping sstable 1211 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9187 | xxx.xx.40.11
Skipped 0/5 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9237 | xxx.xx.40.11
Bloom filter allows skipping sstable 1207 [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9335 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9571 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9734 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.49 [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9842 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 10116 | xxx.xx.40.11
Request complete | 2019-01-14 16:03:32.646708 | xxx.xx.47.82 | 528708 | xxx.xx.40.11
Toutes les activités commençant par ESI sont des activités d'Esindex:
* ESI <id> Searching 'AttributeValues.LastName:ab*': The query have been received and decoded by the ESIndex, it is now sent to ElasticSearch
* ESI <id> Found 10000 matching ES docs in 514ms: The query to ElasticSearch has found 10000 results
* ESI <id> StreamingPartitionIterator initialized: Streaming partition iterator have been provided with all Ids found, and starts reading rows
* ESI <id> StreamingPartitionIterator closed: Client is done reading rows (limit was 1)
Traçage des mises à jour / inserts / supprimer
cqlsh:ucs> update "Contact" set "CreatedDate"='2017-04-01T11:21:59.001+0000' where "Id"='1001uiP2niJPJGBa';
Session de traçage: F76E4AC0-180E-11E9-B832-33A77983333
activity | timestamp | source | source_elapsed | client
----------------------------------------------------------------------------------------------------------------------------------------+----------------------------+---------------+----------------+--------------
Execute CQL3 query | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 0 | xxx.xx.40.11
MUTATION message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 22 | xxx.xx.40.11
Appending to commitlog [MutationStage-1] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 354 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-1] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 465 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [MutationStage-1] | 2019-01-14 16:12:35.212000 | xxx.xx.47.49 | 2356 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:12:35.212000 | xxx.xx.47.49 | 2548 | xxx.xx.40.11
Parsing update "Contact" set "CreatedDate"='2017-04-01T11:21:59.001+0000' where "Id"='1001uiP2niJPJGBa'; [Native-Transport-Requests-1] | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 146 | xxx.xx.40.11
Preparing statement [Native-Transport-Requests-1] | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 213 | xxx.xx.40.11
Determining replicas for mutation [Native-Transport-Requests-1] | 2019-01-14 16:13:37.133000 | xxx.xx.47.82 | 1895 | xxx.xx.40.11
Appending to commitlog [MutationStage-2] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2042 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-2] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2149 | xxx.xx.40.11
Sending MUTATION message to /xxx.xx.47.100 [MessagingService-Outgoing-/xxx.xx.47.100-Small] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2186 | xxx.xx.40.11
Sending MUTATION message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2232 | xxx.xx.40.11
MUTATION message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 28 | xxx.xx.40.11
Appending to commitlog [MutationStage-1] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 390 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-1] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 471 | xxx.xx.40.11
ESI decoding row 31303031756950326e694a504a474261 [MutationStage-1] | 2019-01-14 16:13:37.137000 | xxx.xx.47.100 | 579 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:13:37.137000 | xxx.xx.47.82 | 5160 | xxx.xx.40.11
ESI writing 31303031756950326e694a504a474261 to ES index [MutationStage-1] | 2019-01-14 16:13:37.137000 | xxx.xx.47.100 | 664 | xxx.xx.40.11
Processing response from /xxx.xx.47.49 [RequestResponseStage-4] | 2019-01-14 16:13:37.137000 | xxx.xx.47.82 | 5280 | xxx.xx.40.11
ESI index 31303031756950326e694a504a474261 done [MutationStage-1] | 2019-01-14 16:13:37.160000 | xxx.xx.47.100 | 23878 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.100 [MessagingService-Incoming-/xxx.xx.47.100] | 2019-01-14 16:13:37.160000 | xxx.xx.47.82 | 28445 | xxx.xx.40.11
Processing response from /xxx.xx.47.100 [RequestResponseStage-2] | 2019-01-14 16:13:37.160000 | xxx.xx.47.82 | 28549 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [MutationStage-1] | 2019-01-14 16:13:37.162000 | xxx.xx.47.100 | 25614 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:13:37.162000 | xxx.xx.47.100 | 25793 | xxx.xx.40.11
Request complete | 2019-01-14 16:13:37.814048 | xxx.xx.47.82 | 682048 | xxx.xx.40.11
Toutes les activités commençant par ESI sont des activités d'Esindex:
* ESI decoding row <rowId>: update request have been received by the ESIndex, row is being converted to JSON
* ESI writing <rowId> to ES index: update is being sent to ElasticSearch
* ESI index <rowId> done: ElasticSearch acknowledged the update
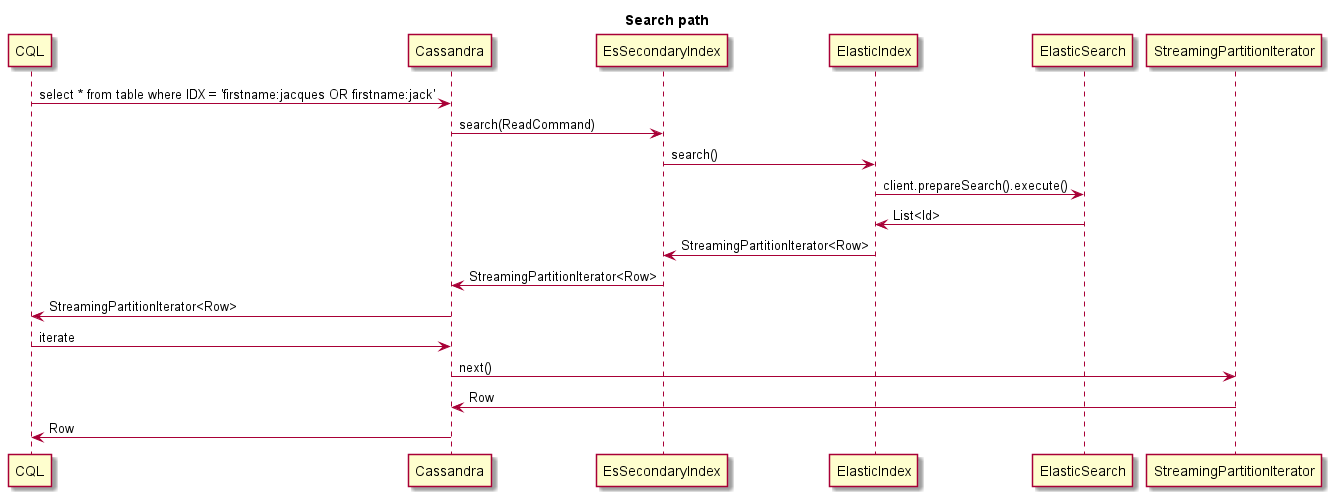
Ceci est un exemple de ce qui se passe lors de la recherche:
Ceci est un exemple d'écriture synchrone (l'opération Cassandra échouera si Es échoue):
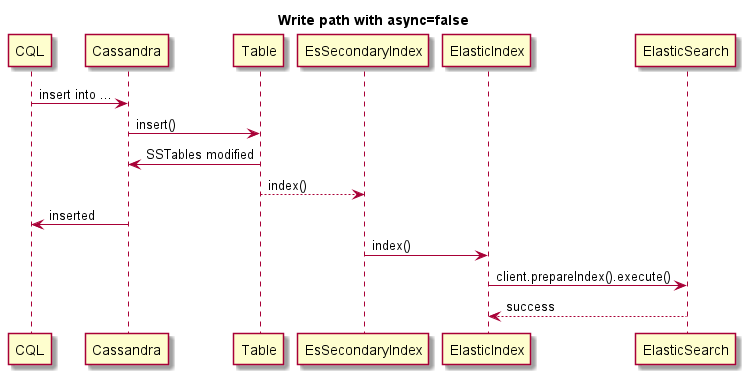
Ceci est un exemple d'écriture asynchrone:
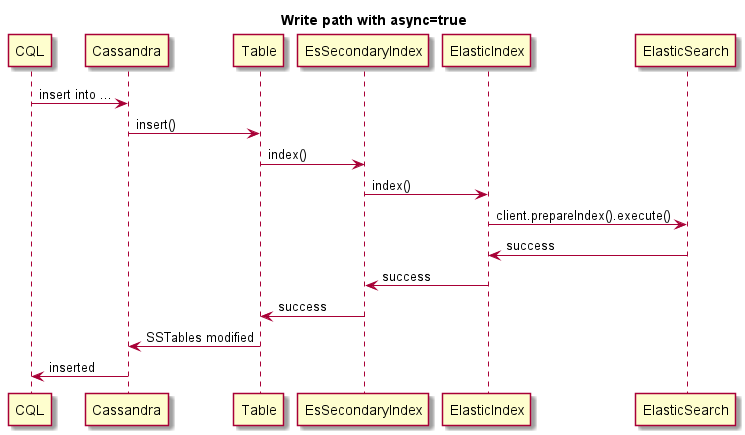
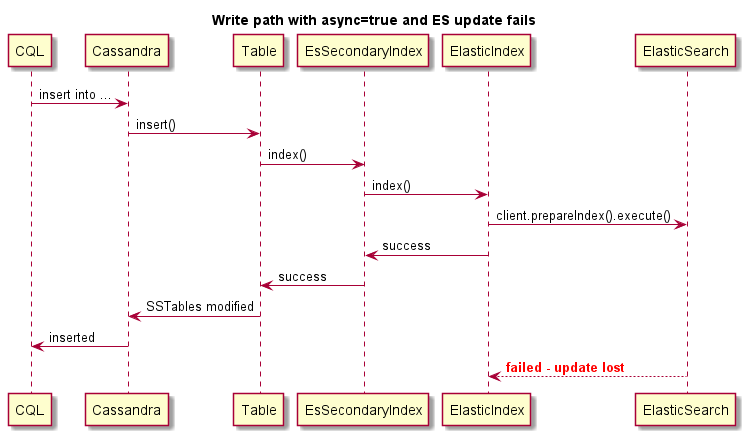
Ceci est un exemple d'écriture asynchrone, l'opération Cassandra n'échouera pas si ES échoue: