cassandra es index
1.0.0
<type>이 문서는 Cassandra에 대한 Elasticsearch 기반 보조 지수 인 "esindex"의 사용 및 구성을 설명합니다.
이 플러그인에는 이미 구성된 엘라스틱 검색 (ES) 클러스터가 필요합니다.
플러그인은 http://cassandra.apache.org/에서 다운로드 한 일반 Cassandra 4.0.x 릴리스로 설치됩니다. 인덱스를 지원하기 위해 Cassandra 구성 파일에서 변경할 것이 없습니다. Cassandra의 행동은 색인을 사용하지 않는 응용 프로그램의 경우 변경되지 않습니다.
Cassandra 테이블에서 생성되면이 색인을 사용하면 CQL을 사용하여 Cassandra에서 "Full 텍스트 검색"Elasticsearch 쿼리를 수행하고 Cassandra 데이터의 매칭 행을 반환 할 수 있습니다. 이 플러그인의 사용은 Cassandra 소스 코드를 변경할 필요가 없으며 다음을 사용하여 Cassandra의 Elasticsearch Index를 구현했습니다.
테스트 된 버전은 Elasticsearch 5.x, 6.x, 7.x 및 Cassandra 4.0.x입니다. 그러나 플러그인은 응용 프로그램이 해당 매핑 및 옵션을 제공하는 경우 다른 Elasticsearch 버전 (1.7, 2.x 5.x, 6.x, 7.x)에서 작동 할 수 있습니다. 플러그인에서 사용하는 보조 인덱스 인터페이스가 다르기 때문에 1.x 2.x, 3.x 또는 4.1과 같은 다른 버전의 Apache Cassandra는 지원되지 않습니다. 다른 Cassandra 공급 업체는 테스트되지 않으며 Scylladb는 지원되지 않습니다.
| 버전 | Elasticsearch 1.x | Elasticsearch 2.x | Elasticsearch 5.x | Elasticsearch 6.x | Elasticsearch 7.x |
|---|---|---|---|---|---|
| 카산드라 1.X | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 |
| 카산드라 2.X | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 |
| 카산드라 3.x | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 |
| Cassandra 4.x | 제한된 | 제한된 | 제한된 | 예 | 예 |
이 프로젝트는 Maven이 필요하고 Java 8을 컴파일해야합니다. Project Execute의 루트에 플러그인을 빌드하려면 다음과 같습니다.
MVN 청소 패키지
이것은 target/distribution/lib4cassandra 에 "하나의 항아리에 모두"를 구축합니다.
<dependency>
<groupId>com.genesyslab</groupId>
<artifactId>es-index</artifactId>
<version>9.2.000.00</version>
</dependency>
Github 패키지를 참조하십시오
Maven 저장소를 참조하십시오
모든 Cassandra 노드에 '/usr/share/cassandra/lib'와 같은 다른 Cassandra Jars와 함께 Cassandra의 lib 폴더에 es-index-9.2.000.xx-jar-with-dependencies.jar 넣으십시오. Cassandra 노드를 시작하거나 다시 시작하십시오.
테스트 부족으로 인해 클러스터링 키가있는 테이블은 지원되지 않습니다. 파티션 키 만 지원되며 복합 파티션 키는 작동하지만 광범위하게 테스트되지 않았습니다.
ESINDEX는 모든 셀이 동시에 만료되는 행 수준 TTL 만 지원하며 해당 ES 문서는 동시에 삭제할 수 있습니다. 행에 다른 시간에 만료되는 셀이있는 경우, 마지막 셀이 만료되면 해당 문서가 삭제됩니다. 다른 셀 TTL을 사용하는 경우 검색에서 반환 된 데이터는 여전히 SSTABLE에서 데이터를 읽을 수 있지만 ES 쿼리를 사용하여 만료 된 데이터를 사용하여 행을 찾을 수 있습니다.
동일한 테이블에 여러 인덱스를 만들 수 있습니다. Esindex는이를 방해하지 않습니다. 그러나 하나 이상의 esindex가 존재하면 동작이 일치하지 않을 수 있으며, 그러한 구성은 지원되지 않습니다. CQLSH 명령 '표 <ks.tablename> 설명을 사용하여 테이블에 생성 된 인덱스를 표시하고 필요한 경우 떨어 뜨릴 수 있습니다.
단순성을 위해 먼저이 키 공간을 만듭니다.
CREATE KEYSPACE genesys WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1}
아래 테이블을 예로 들어 봅시다.
CREATE TABLE genesys.emails (
id UUID PRIMARY KEY,
subject text,
body text,
userid int,
query text
);
인덱스 사용을 위해 더미 텍스트 열을 전용해야합니다. 이 열은 데이터를 수신해서는 안됩니다. 이 예에서 query 열은 더미 열입니다.
예제 테이블의 색인을 작성하고 Eshost를 Eshost를 사용하는 방법은 다음과 같습니다.
CREATE CUSTOM INDEX ON genesys.emails(query)
USING 'com.genesyslab.webme.commons.index.EsSecondaryIndex'
WITH OPTIONS = {'unicast-hosts': 'eshost:9200'};
예를 들어, Elasticsearch 서버가 localhost 에서 듣는 경우 EShost를 LocalHost 로 바꾸십시오.
CQL에 의해 반환 된 오류는 매우 제한적입니다. Elasticsearch 호스트를 사용할 수없는 것처럼 무언가 잘못되면 타임 아웃이나 다른 종류의 예외를 얻을 수 있습니다. 무엇이 잘못되었는지 이해하려면 Cassandra 로그를 확인해야합니다.
우리는 매핑을 제공하지 않았으므로 Elasticsearch Dynamic Mapping에 의존하고 있습니다. 일부 데이터를 삽입합시다.
INSERT INTO genesys.emails (id, subject, body, userid)
VALUES (904b88b2-9c61-4539-952e-c179a3805b22, 'Hello world', 'Cassandra is great, but it''s even better with EsIndex and Elasticsearch', 42);
로그에 액세스 할 수있는 경우 Elasticsearch에서 인덱스가 생성되고 있음을 알 수 있습니다.
[o.e.c.m.MetaDataCreateIndexService] [node-1] [genesys_emails_index@] creating index, cause [api], templates [], shards [5]/[1], mappings []
[INFO ][o.e.c.m.MetaDataMappingService] [node-1] [genesys_emails_index@/waSGrPvkQvyQoUEiwqKN3w] create_mapping [emails]
이제 인덱스를 통해 Elasticsearch를 사용하여 Cassandra를 검색 할 수 있습니다. 여기 Lucene Syntax 검색이 있습니다.
select id, subject, body, userid, query from emails where query='body:cassan*';
id | subject | body | userid | query
--------------------------------------+-------------+-------------------------------------------------------------------------+--------+-------
904b88b2-9c61-4539-952e-c179a3805b22 | Hello world | Cassandra is great, but it's even better with EsIndex and Elasticsearch | 42 |
{
"_index": "genesys_emails_index@",
"_type": "emails",
"_id": "904b88b2-9c61-4539-952e-c179a3805b22",
"_score": 0.24257512,
"_source": {
"id": "904b88b2-9c61-4539-952e-c179a3805b22"
},
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.24257512
}
}
(1 rows)
(JSON은 포맷되었습니다)
모든 행에는 CQL 일관성을 사용하여 sstables에서로드 된 Cassandra의 데이터가 포함됩니다. '쿼리'열의 데이터는 Elasticsearch에서 반환 한 메타 데이터입니다.
생성 된 매핑을 확인하기 위해 Elasticsearch를 쿼리하는 방법은 다음과 같습니다. GET http://eshost:9200/genesys_emails_index@/emails/_mapping?pretty
{
"genesys_emails_index@" : {
"mappings" : {
"emails" : {
"properties" : {
"IndexationDate" : {
"type" : " date "
},
"_cassandraTtl" : {
"type" : " long "
},
"body" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"id" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"subject" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"userid" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
}
}
}
}
}
}Esindex 플러그인에는 두 개의 필드가 추가되었습니다.
우리는 매핑이 잘 보이지만 Elasticsearch는 userID가 정수이며 모든 텍스트에 [키워드]를 추가 한 것을 알지 못했습니다.
Elasticsearch에서 데이터의 모습은 다음과 같습니다.
GET http://localhost:9200/genesys_emails_index@/emails/_search?pretty&q=body:cassandra
{
"took" : 2 ,
"timed_out" : false ,
"_shards" : {
"total" : 5 ,
"successful" : 5 ,
"skipped" : 0 ,
"failed" : 0
},
"hits" : {
"total" : 1 ,
"max_score" : 0.2876821 ,
"hits" : [
{
"_index" : " genesys_emails_index@ " ,
"_type" : " emails " ,
"_id" : " 904b88b2-9c61-4539-952e-c179a3805b22 " ,
"_score" : 0.2876821 ,
"_source" : {
"id" : " 904b88b2-9c61-4539-952e-c179a3805b22 " ,
"body" : " Cassandra is great, but it's even better with EsIndex and Elasticsearch " ,
"subject" : " Hello world " ,
"userid" : " 42 " ,
"IndexationDate" : " 2019-01-15T16:53:00.107Z " ,
"_cassandraTtl" : 2147483647
}
}
]
}
} 인덱스를 삭제하여 매핑을 수정합시다 : drop index genesys.emails_query_idx; 이것은 또한 Elasticsearch Index와 데이터를 삭제합니다!
적절한 매핑으로 재현하십시오.
CREATE CUSTOM INDEX ON genesys.emails(query)
USING 'com.genesyslab.webme.commons.index.EsSecondaryIndex'
WITH OPTIONS = {
'unicast-hosts': 'localhost:9200',
'mapping-emails': '
{
"emails":{
"date_detection":false,
"numeric_detection":false,
"properties":{
"id":{
"type":"keyword"
},
"userid":{
"type":"long"
},
"subject":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"body":{
"type":"text"
},
"IndexationDate":{
"type":"date",
"format":"yyyy-MM-dd''T''HH:mm:ss.SSS''Z''"
},
"_cassandraTtl":{
"type":"long"
}
}
}
}
'};
이렇게하면 새로운 색인이 생성됩니다. Cassandra에있는 데이터를 매핑하고 다시 표시합니다.
결과 ES 매핑은 다음과 같습니다.
{
"genesys_emails_index@" : {
"mappings" : {
"emails" : {
"date_detection" : false ,
"numeric_detection" : false ,
"properties" : {
"IndexationDate" : {
"type" : " date " ,
"format" : " yyyy-MM-dd'T'HH:mm:ss.SSS'Z' "
},
"_cassandraTtl" : {
"type" : " long "
},
"body" : {
"type" : " text "
},
"id" : {
"type" : " keyword "
},
"subject" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"userid" : {
"type" : " long "
}
}
}
}
}
}매핑이 올바르게 정의되었으므로 userID를 숫자로 검색 할 수 있습니다. 이 예에서는 Elasticsearch Query DSL을 사용하고 있습니다.
select id, subject, body, userid from genesys.emails
where query='{"query":{"range":{"userid":{"gte":10,"lte":50}}}}';
@ Row 1
---------+-------------------------------------------------------------------------
id | 904b88b2-9c61-4539-952e-c179a3805b22
subject | Hello world
body | Cassandra is great, but it's even better with EsIndex and Elasticsearch
userid | 42
생산을 시작하기 직전에 매핑을 얻는 것이 매우 중요합니다. 큰 테이블을 다시 알게되면 많은 시간이 걸리며 Cassandra와 Elasticsearch에 상당한 부하가 있습니다. ES 매핑의 오류가 Cassandra 로그를 확인해야합니다. Create Index 명령에 제공된 JSON 옵션에서 단일 따옴표 ( ')를 두 배로 늘려서 탈출하십시오.
다음은 Elasticsearch Index 구성과 관련된 모든 옵션입니다. 키 이름은 하이픈 '-'char 또는 도트를 사용할 수 있습니다. 예를 들어 두 이름 모두 작동합니다.
아래의 모든 옵션은 Elasticsearch 자체가 아닌 Genesys 구현에만 해당됩니다.
JEST 클래스를 찾을 수없는 경우 더미 모드가 활성화되어 있으며 다른 경우는 적용되지 않습니다.
멀티 다타 센터가 지원되며 데이터는 Cassandra 가십 복제를 통해서만 복제됩니다. 다른 DC의 ES 클러스터는 동일하지 않으며 함께 결합해서는 안됩니다. 그렇지 않으면 성능이 영향을받지 않아야합니다. 데이터가 테이블 수준에서 복제되므로 ESINDEX는 각 DC에서 업데이트를 받고 로컬 ES 클러스터도 업데이트됩니다.
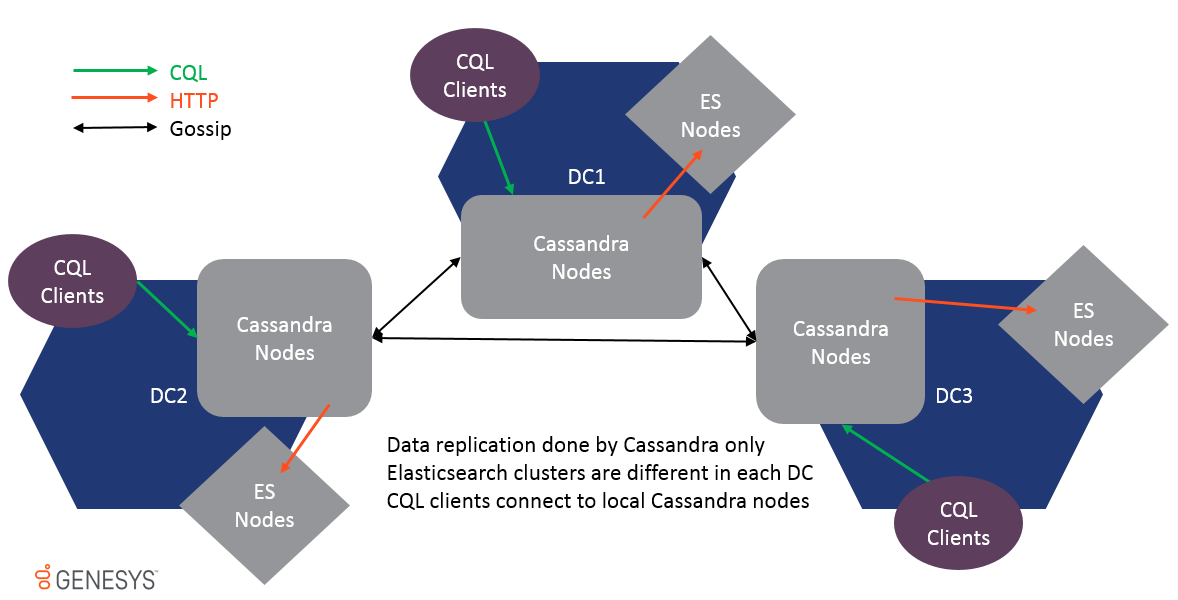
멀티 -DC를 지원하기 위해 모든 옵션은 데이터 센터 및 랙 이름으로 접두사를 접두사로하여 설정 위치를 구체적으로 만들 수 있습니다.
자격 증명이있는 Elasticsearch의 Cassandra 색인을 제공하려면 각 노드에는 시작하기 전에 환경 변수 ESCREDELING이 올바르게 설정되어 있어야합니다. 이것은 모든 Cassandra 호스트에서 설정해야합니다.
아래 예제는 사용자 '탄성'및 비밀번호 'examplaspordword'에 대한 비밀번호를 제공합니다. (콜론) 문자. 시스템에서 환경 변수 또는 Cassandra를 시작하는 바로 가기에서 직접 수행 할 수 있습니다.
escredentials = elastic : examplepassword 인덱스가 성공적으로 초기화되면 Cassandra 로그에 정보 수준의 "Elasticsearch Credentials"를 작성합니다. 이 메시지가 출력되면 환경 변수를 지울 수 있습니다. Cassandra가 다시 시작되면 시작하기 전에 환경 변수를 다시 설정해야합니다. 자격 증명은 메모리에만 유지되며 다른 곳에서는 저장되지 않습니다. 사용자 및/또는 암호가 변경되면 모든 Cassandra 노드는 업데이트 된 환경 변수 값으로 다시 시작해야합니다.
인덱스 옵션 세트에서
Unicast-Hosts = https : //<host name>:9200
현재 기존 색인을 HTTP에서 HTTP로 마이그레이션 할 수는 없으므로 Cassandra 스키마를 생성하기 전에 하나 또는 다른 사용을 결정해야합니다. HTTPS 배포를 용이하게하기 위해 인덱스는 모든 HTTPS 인증서를 자동으로 신뢰합니다.
정의 된 Cassandra TTL보다 Elasticsearch 측에 데이터를 더 긴 기간 동안 유지할 수 있습니다. 이 모드는 es-Analytic-Mode 옵션을 사용하여 전환됩니다. 옵션이 활성화되면 ElasticIndex는 모든 삭제 작업을 건너 뜁니다.
ES 측에서 데이터가 너무 커지지 않도록하기 위해 TTL 시프트 및 힘-지연 설정을 사용하는 것이 좋습니다.
인덱스를 만들 때 '옵션 사용'CQL 명령을 사용하여 인덱스 옵션과 Elasticsearch 색인 옵션을 제공합니다.
인덱스 옵션은 인덱스 생성에서 지정해야합니다. 예는 다음과 같습니다.
CREATE CUSTOM INDEX on genesys.email(query) using 'com.genesyslab.webme.commons.index.EsSecondaryIndex' WITH options =
{
'read-consistency-level':'QUORUM',
'insert-only':'false',
'index-properties': '{
"index.analysis.analyzer.dashless.tokenizer":"dash-ex",
"index.analysis.tokenizer.dash-ex.pattern":"[^\\w\\-]",
"index.analysis.tokenizer.dash-ex.type":"pattern"
}',
'mapping-email': '{
"email": {
"dynamic": "false",
"properties": {
"subject" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}',
'discard-nulls':'false',
'async-search':'true',
'async-write':'false'
};
또한 'Genesys-es-'를 사용하여 옵션을 접두사하여 환경 변수 또는 Java 시스템 속성을 사용하여 옵션을 설정하거나 재정의 할 수 있습니다.
"Create Index"명령에 제공된 옵션이 먼저 사용됩니다. ".", "./conf/", "../conf/"또는 "./bin/"라는 파일을 사용하여 로컬로 재정 의 할 수 있습니다. (-dgenesys-es-esi-file 또는 -dgenesys.es.es.file 시스템 속성으로 변경할 수 있습니다)
다음은 파일의 내용에 대한 예입니다.
insert-donly = true discard-nulls = false async-write = false
| 이름 | 기본 | 설명 |
|---|---|---|
| 최대-결과 | 10000 | Cassandra 행을로드하기 위해 ES 검색에서 읽을 결과 수. |
| 읽기 일관성 수준 | 하나 | 검색에 사용되는이 일관성 수준은 Cassandra 행을로드하는 데 사용됩니다. |
| 삽입 전용 | 거짓 | 기본적으로 esindex는 업스트 작업을 사용합니다. 삽입에서만 모드 데이터는 항상 덮어 씁니다. |
| 비동기 쓰기 | 진실 | 올바른 실행을 확인하지 않고 인덱스 업데이트를 비동기로 보냅니다. 이것은 훨씬 빠른 쓰기를 제공하지만 ES 클러스터를 사용할 수 없으면 데이터가 일치하지 않을 수 있습니다. 쓰기는 실패하지 않기 때문입니다. 기본값은 사실입니다. |
| 분절 | 끄다 | 꺼짐, 시간, 일, 월, 연도, 사용자 정의 자동 인덱스 세분화는이 설정에 의해 제어됩니다. 매일 설정되면 매일 별명에 따라 새로운 색인이 생성됩니다. 빈 인덱스는 매 시간마다 자동으로 삭제됩니다. 참고 : 시간 설정은 많은 인덱스를 생성하고 성능을 줄일 수 있으므로 낙담합니다. 이 설정은 개발 및 테스트 목적으로 권장됩니다. |
| 세그먼트 이름 | 세그먼트 = 사용자 정의이면이 값은 새로운 인덱스 생성에 사용됩니다. | |
| 매핑-<type> | {} | 각 보조 인덱스에 대해 테이블 이름은 유형으로 전달됩니다 (예 : 매핑-방문 = {json 정의}. |
| 유니 캐스트 호스트 | http : // localhost : 9200 | 쉼표 분리 된 호스트 목록은 호스트 1, host2, host3 또는 http : // host1, http : // host2, http : // http : // host1 : 9200, http : // host2 : 9200, http : // host3 : 9200 일 수 있습니다. 프로토콜이나 포트에 HTTP가없고 9200이 가정 된 경우. HTTPS를 사용할 수 있습니다. |
| 폐기 널 | 진실 | NULL 값을 ES 색인으로 전달하지 않으면 값을 삭제할 수 없음을 의미합니다. 기본값은 사실입니다 . |
| 인덱스 특성 | {} | 새 인덱스를 생성하기 위해 전달 된 JSON 문자열로서의 속성은 예를 들어 토 케이저 정의를 포함 할 수 있습니다. |
| JSON-Serialized 필드 | {} | 문자열 열이 JSON 문자열로 인덱싱되어야한다고 정의하는 혼수 상태에서 분리 된 문자열. JSON이 아닌 구문 분석 문자열은 Cassandra의 삽입물을 방지합니다. |
| JSON-FLAT-SERIALIZIZED 필드 | {} | 문자열 열이 유형-안전 JSON 문서로 인덱싱되어야한다고 정의하는 혼수 상태에서 분리 된 문자열. Elasticsearch JSON 매핑은 시간이 지남에 따라 유형을 변경할 값을 색인화 할 수 없습니다. 예를 들어 { "key": "value"}는 { "key": { "subkey": "value"}}가 될 수 없습니다. 이러한 JSON-FLAT는 문자열 키와 값으로 문자열 배열을 가진 JSON 객체로 변환기가됩니다. |
| 더미 | 거짓 | 2 차 지수를 완전히 비활성화합니다. JEST 클래스를 찾지 못하면 인덱스가 자동으로 더미 모드로 표시됩니다. |
| 검증 된 쿼리 | 거짓 | Cassandra 타임 아웃 대신 의미있는 구문 오류를 제공하기 위해 검색 쿼리를 유효성 검사를 위해 검색 쿼리를 ES로 보냅니다. |
| 동시-잠금 | 진실 | 파티션 ID에서 인덱스 실행을 잠그십시오. 동시에 동일한 파티션에서 여러 업데이트를 처리 할 때 동시성 문제를 방지합니다. |
| 스킵 로그리스 플레이 | 진실 | Cassandra 노드가 시작되면 Commit Log가 재생되면 해당 업데이트는 이미 ES에 적용되었으므로 시작 시간을 개선하기 위해 건너 뜁니다. |
| Skip-non-local-updates | 진실 | 성능을 향상시키기 위해이 설정은 토큰 범위의 마스터 복제본에서 인덱스 업데이트 만 실행됩니다. |
| ES 분석 모드 | 거짓 | ES 문서의 삭제 (TTL 또는 삭제)를 비활성화합니다. |
| 유형 파이프 라인 | 없음 | 설정 파이프 라인 유형 목록. |
| 파이프 라인-<type> | 없음 | 이 유형의 파이프 라인 정의. |
| index.translog.durability | 비동기 | 인덱스를 만들 때 Async Commit 모드를 사용하여 최상의 성능을 보장하면 ES 1.7의 기본 설정이었습니다. 2.X이므로 동기화되어 성능 저하가 심각합니다. |
| 사용 가능합니다 | 진실 | 새 인덱스를 만들 때 부분 색인에서 검색을 실행할 수 있습니다. |
| 잘린 건물 | 거짓 | 재건하기 전에 ES 지수를 잘라냅니다. |
| 퍼지-기간 | 60 | 60 분마다 모든 빈 인덱스가 별칭에서 삭제됩니다. |
| 인덱스 당 유형 | 진실 | 테이블 이름으로 인덱스 이름을 전제하십시오. ES 5.X에서는 더 이상 동일한 인덱스의 다른 유형에서 동일한 필드 이름에 대해 다른 매핑을 가질 수 없습니다. ES 6.X 유형이 제거됩니다. |
| 힘을 지시합니다 | 거짓 | 매 순간 매 순간 "쿼리 삭제"요청은 _cassandRattl이 만료 된 문서를 삭제하기 위해 ES로 전송됩니다. 이것은 ES 5.X에서 제거 된 TTL 기능을 모방하는 것입니다. Cassandra 압축은 실제로 ES에서 문서를 삭제하는 반면 언제 발생할 것인지에 대한 보장은 없습니다. |
| TTL 시프트 | 0 | Cassandra TTL을 이동하는 데 몇 초 만에 시간. Cassandra에서 TTL이 1H이고 Shift가 3600 인 경우 ES의 문서는 Cassandra보다 1 시간 늦게 삭제됩니다. |
| 인덱스 관리자 | com.genesyslab.webme.commons.index.defaultindexmanager | 색인 관리자 클래스 이름. 세분화 및 만료 기능을 관리하는 데 사용됩니다. |
| 세그먼트 크기 | 86400000 | 밀리 초의 세그먼트 시간 프레임. 모든 "세그먼트 크기"milliseconds 새 인덱스는 다음 템플릿을 통해 생성됩니다. |
| 최대 연결-경로 | 2 | ES 노드 당 HTTP 연결 수, 기본값은 Apache HTTP 풀 값이며 Cassandra 지수의 성능을 높이지만 ES의 부하가 증가 할 수 있습니다. (WCC의 신규 9.0.000.15) |
매핑 정의에서 날짜 감지를 해제해야합니다.
다음 JSON :
{
"maps" : {
"key1" : " value " ,
"key2" : 42 ,
"keymap" : {
"sss1" : null ,
"sss2" : 42 ,
"sss0" : " ffff "
},
"plap" : " plop "
},
"string" : " string " ,
"int" : 42 ,
"plplpl" : [ 1 , 2 , 3 , 4 ]
}다음으로 변환됩니다.
{
"maps" : [ " key1=value " , " key2=42 " , " keymap={sss1=null, sss2=42, sss0=ffff} " , " plap=plop " ],
"string" : [ " string " ],
"int" : [ " 42 " ],
"plplpl" : [ " 1 " , " 2 " , " 3 " , " 4 " ]
}가능한 값 :
<type>유형 매핑에 대한 자세한 내용은 Elasticsearch 설명서를 참조하십시오 : http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/mapping.html
모든 Cassandra 열 유형이 지원되며 데이터는 Cassandra 유형에 따라 문자열, 배열 또는 맵으로 전송됩니다. 적절한 매핑을 사용하면 Elasticsearch가 데이터를 관련 유형으로 변환합니다. 이를 통해 훨씬 더 나은 검색 및보고가 가능합니다.
| 카산드라 유형 | Elasticsearch 권장 매핑 | 논평 |
|---|---|---|
| ASCII | 텍스트 또는 키워드 | 텍스트 유형의 다음 섹션을 참조하십시오 |
| 큰 | 긴 | |
| 얼룩 | 장애가 있는 | 이진 컨텐츠를 색인화 할 수 없습니다 |
| 부울 | 부울 | |
| 계수기 | 긴 | |
| 날짜 | 날짜 | |
| 소수 | 더블 | |
| 더블 | 더블 | |
| 뜨다 | 더블 | |
| inet | 예어 | ES IP는 테스트되지 않았습니다 |
| int | int | |
| 목록 <type> | 유형 과 동일합니다 | ES는 유형이 단일 값 또는 배열 일 수 있다고 기대합니다. |
| 지도 < typek , typev > | 물체 | 키가 다양한 값을 가질 수 있다면 폭발을 맵핑하는 것을 조심하십시오. |
| <type> 을 설정하십시오 | 유형과 동일합니다 | ES는 유형이 단일 값 또는 배열 일 수 있다고 기대합니다. |
| smallint | int | |
| 텍스트 | 텍스트 또는 키워드 | 텍스트 유형의 다음 섹션을 참조하십시오 |
| 시간 | 예어 | |
| 타임 스탬프 | "type": "date", "format": "yyyy-mm-dd't'hh : mm : ss.sss'z '" | |
| TimeUuid | 예어 | |
| 작은 | int | |
| 튜플 <type1 type2, ...> | 유형 | |
| uuid | 예어 | |
| 바르 차 | 텍스트 또는 키워드 | 텍스트 유형의 다음 섹션을 참조하십시오 |
| varint | 긴 | |
| 사용자 정의 유형 | 물체 | 각 UDT 필드는 이름과 값을 사용하여 매핑됩니다. |
텍스트 유형의 매핑
텍스트 (ASCII 또는 Varchar) 열이 ES로 전송되면 인덱싱 할 원시 텍스트로 전송됩니다. 그러나 텍스트가 적절한 JSON 인 경우 ES에 대한 JSON 문서로 보낼 수 있습니다. 이를 통해 원시 텍스트 대신 문서를 색인/검색 할 수 있습니다.
이러한 JSON 매핑을 사용하면 "columnname.key : value"를 사용하여 데이터를 검색 할 수 있습니다.
키가 다양한 값을 가질 수 있다면 폭발을 맵핑하는 것을 조심하십시오.
JSON-SERIALIZED 필드 (자세한 내용은 옵션 참조)
텍스트의 내용은 JSON으로 전송됩니다. 매핑에서 각 문서 필드를 별도로 정의 할 수 있습니다. 정적 매핑 또는 동적 매핑에 의해 필드가 유형으로 맵핑되면 호환되지 않는 유형을 제공하면 Cassandra 쓰기 실패가 발생합니다.
JSON-FLAT-SERIALIZED 필드 (자세한 내용 및 전환 예를 참조하십시오)
텍스트의 내용은 JSON으로 전송되지만 모든 값은 평평한 문자열의 배열로 강제됩니다. 이렇게하면 중첩 된 JSON으로 검색하는 기능이 제한되지만 값의 JSON 유형을 제어 할 수 없다면 더 안전합니다.
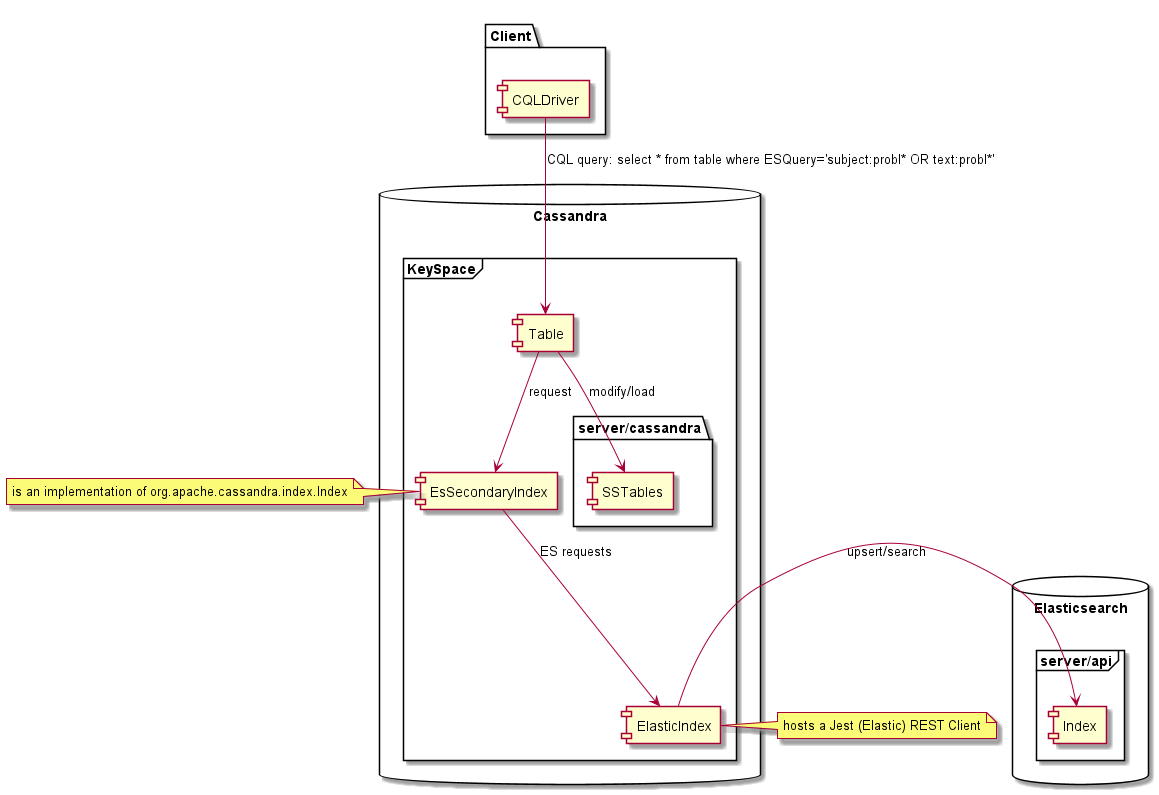
Cassandra 지수의 맞춤형 구현입니다. 이것은 Cassandra 일관성 모델과 관련된 몇 가지 제한 사항을 소개합니다. 주요 제한은 Cassandra 2 차 인덱스의 특성 때문이며, 각 Cassandra 노드에는 Cassandra 링 내에서 책임이있는 데이터 만 포함되어 있으며 2 차 인덱스는 동일하며 각 노드는 로컬 데이터 만 색인화합니다. 이는 색인에서 쿼리를 수행 할 때 쿼리가 모든 노드로 전송 된 다음 쿼리 코디네이터로 결과를 집계하고 클라이언트로 반환 함을 의미합니다.
esindex를 사용하면 인덱스 검색이 Elasticsearch를 기반으로하기 때문에 각 노드는 쿼리에 응답 할 수 있습니다. 즉, 쿼리는 단일 노드로만 전송되어야합니다. 그렇지 않으면 결과에 복제물이 포함되어 있습니다. 이것은 아래와 같이 토큰을 CQL 쿼리로 강요함으로써 달성됩니다.
select * from emails where query='subject:12345' and token(id)=0;
토큰은 노드에 쿼리를 퍼 뜨리려면 임의의 긴 값이어야합니다. 위의 예에서 행의 파티션 키에 구축해야합니다.
위의 예에서 Elasticsearch 쿼리는 '제목 : 12345'입니다. 이것은 루센과 같은 쿼리입니다. 자세한 내용은 DSL 쿼리를 실행할 수도 있습니다.
단일 Elasticsearch 색인에는 주어진 키 공간에 대한 모든 Cassandra 테이블 인덱스가 포함됩니다. 각 지수에 대해 전용 Elasticsearch 유형이 사용됩니다. 교차 테이블 집계를 허용하기 위해 유형은 쿼리에서 시행되지 않습니다. 쿼리가 다른 유형과 일치 할 수 있으면 예상보다 더 많은 ID를 반환합니다. 그것들은 Cassandra 행과 일치하지 않기 때문에 더 많은 결과를 얻지 못하지만 반환 된 결과 수를 제한하면 더 적게 얻을 수 있습니다.
일치하는 행 카운트가 높고 행이 크면 검색이 읽기 시간 초과로 끝날 수 있습니다. ES 메타 데이터로 PK 만 반환 한 다음 CQL 쿼리를 사용하여 코드와 병렬로로드하도록 요청할 수 있습니다.
인덱스에 pks를 반환하도록 지시하려면 아래 쿼리 힌트 #options : load-rows = false #:
select * from emails where query='#options:load-rows=false#id:ab*';
반환 된 행은 가짜이며 Elasicsearch 쿼리의 결과에서 구축된다는 점에 유의해야합니다. 그것은 반환 된 행이 더 이상 존재하지 않을 수 있음을 의미합니다.
검색 요청이 결과를 반환하면 첫 번째 행에는 엘라스틱 검색 메타 데이터가 인덱스 열에 ## a json 문자열로 포함됩니다. 예를 들어 : 참조 :
cqlsh:ucs> select id,query from emails where query='id:00008RD9PrJMMmpr';
id | query
------------------+---------------------------------------------------------------------------------------------------------------------
00008RD9PrJMMmpr | {"took":5,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":1,"max_score":7.89821}}
ESINDEX 세분화 메커니즘은 모 놀리 식 엘라스틱 검색 지수를 시간 기반 인덱스의 순서로 분할합니다. 이를위한 목적은 다음과 같습니다.
Elasticsearch 5.x TTL은 더 이상 지원되지 않기 때문입니다. 그러나 Cassandra의 정상적인 압축 및 수리 프로세스는 묘비 데이터를 자동으로 제거하고 Elasticindex는 Elasticsearch에서 데이터를 제거합니다.
ESINDEX는 CQL 추적을 지원하며 노드에서 활성화하거나 아래 명령과 함께 CQLSH를 사용할 수 있습니다.
추적;
트레이싱 셀렉션 은 전체 쿼리에서 모든 참여 노드에 대한 흔적을 얻을 수 있습니다.
cqlsh:ucs> select * from "Contact" where "ESQuery"='AttributeValues.LastName:ab*' and token("Id")=0 limit 1;
Id | AttributeValues | AttributeValuesDate | Attributes| CreatedDate | ESQuery | ExpirationDate | MergeIds | ModifiedDate| PrimaryAttributes| Segment| TenantId
1001uiP2niJPJGBa | {"LastName":["IdentifyTest-aBEcKPnckHVP"],"EmailAddress":["IdentifyTest-HHzmNornOr"]} |{} | {'EmailAddress_IdentifyTest-HHzmNornOr': {Id: 'EmailAddress_IdentifyTest-HHzmNornOr', Name: 'EmailAddress', StrValue: 'IentifyTest-HHzmNornOr', Description: null, MimeType: null, IsPrimary: False}, 'LastName_IdentifyTest-aBEcKPnckHVP': {Id: 'LastName_IdentifyTest-aBEcKPnckHVP', Name: 'LastName', StrValue: 'IdentifyTest-aBEcKPnckHVP', Description: null, MimeType: null IsPrimary: False}} | 2018-10-30 02:05:06.960000+0000 | {"_index":"ucsperf2_contact_index@","_type":"Contact","_id":"1001uiP2niJPJGBa","_score":1.0,"_source":{"Id":"1001uiP2niJPJGBa"},"took":485,"timed_out":false,"_shards":{"total":5,"successful":5,failed":0},"hits":{"total":18188,"max_score":1.0}} | null | null | 2018-10-30 02:05:06.960000+0000 | {'EmailAddress': 'IdentifyTest-HHzmNornOr', 'LastName': 'IdentifyTest-aBEcKPnckHVP'} | not-applicable |1
(1 rows)
그러면 세션에서 추적 정보를 얻을 수 있습니다.
추적 세션 : 8ED07B60-180D-11E9-B832-33A77983333
activity | timestamp | source | source_elapsed | client
-----------------------------------------------------------------------------------------------------------------------------------------+----------------------------+---------------+----------------+--------------
Execute CQL3 query | 2019-01-14 16:03:32.118000 | xxx.xx.47.82 | 0 | xxx.xx.40.11
RANGE_SLICE message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:02:30.200000 | xxx.xx.47.49 | 34 | xxx.xx.40.11
Executing read on ucsperf2.Contact using index Contact_ESQuery_idx [ReadStage-1] | 2019-01-14 16:02:30.201000 | xxx.xx.47.49 | 411 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 Searching 'AttributeValues.LastName:ab*' [ReadStage-1] | 2019-01-14 16:02:30.201000 | xxx.xx.47.49 | 693 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 Found 10000 matching ES docs in 514ms [ReadStage-1] | 2019-01-14 16:02:30.716000 | xxx.xx.47.49 | 515336 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 StreamingPartitionIterator initialized [ReadStage-1] | 2019-01-14 16:02:30.717000 | xxx.xx.47.49 | 516911 | xxx.xx.40.11
reading data from /xxx.xx.47.100 [ReadStage-1] | 2019-01-14 16:02:30.717000 | xxx.xx.47.49 | 517121 | xxx.xx.40.11
speculating read retry on /xxx.xx.47.82 [ReadStage-1] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517435 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517436 | xxx.xx.40.11
Sending READ message to /xxx.xx.47.100 [MessagingService-Outgoing-/xxx.xx.47.100-Small] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517445 | xxx.xx.40.11
Sending READ message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517558 | xxx.xx.40.11
Acquiring sstable references [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517866 | xxx.xx.40.11
Bloom filter allows skipping sstable 83 [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517965 | xxx.xx.40.11
Partition index with 0 entries found for sstable 400 [ReadStage-2] | 2019-01-14 16:02:30.719000 | xxx.xx.47.49 | 518300 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:02:30.720000 | xxx.xx.47.49 | 519720 | xxx.xx.40.11
Processing response from /xxx.xx.47.82 [RequestResponseStage-4] | 2019-01-14 16:02:30.720000 | xxx.xx.47.49 | 519865 | xxx.xx.40.11
Bloom filter allows skipping sstable 765 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522352 | xxx.xx.40.11
Bloom filter allows skipping sstable 790 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522451 | xxx.xx.40.11
Bloom filter allows skipping sstable 819 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522516 | xxx.xx.40.11
Bloom filter allows skipping sstable 848 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522662 | xxx.xx.40.11
Bloom filter allows skipping sstable 861 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522741 | xxx.xx.40.11
Skipped 0/7 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522855 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-2] | 2019-01-14 16:02:30.723001 | xxx.xx.47.49 | 523075 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-2] | 2019-01-14 16:02:30.723001 | xxx.xx.47.49 | 523164 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524717 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 StreamingPartitionIterator closed [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524805 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524872 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524971 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.100 [MessagingService-Incoming-/xxx.xx.47.100] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528222 | xxx.xx.40.11
Processing response from /xxx.xx.47.100 [RequestResponseStage-1] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528364 | xxx.xx.40.11
Initiating read-repair [RequestResponseStage-1] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528481 | xxx.xx.40.11
Parsing select * from "Contact" where "ESQuery"='AttributeValues.LastName:ab*' and token("Id")=0 limit 1; [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 174 | xxx.xx.40.11
Preparing statement [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 254 | xxx.xx.40.11
Index mean cardinalities are Contact_ESQuery_idx:-2109988917941223823. Scanning with Contact_ESQuery_idx. [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 418 | xxx.xx.40.11
Computing ranges to query [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2480 | xxx.xx.40.11
Submitting range requests on 1 ranges with a concurrency of 1 (-4.6099044E15 rows per range expected) [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2568 | xxx.xx.40.11
Enqueuing request to /xxx.xx.47.49 [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2652 | xxx.xx.40.11
Submitted 1 concurrent range requests [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2708 | xxx.xx.40.11
Sending RANGE_SLICE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2874 | xxx.xx.40.11
READ message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.640000 | xxx.xx.47.100 | 29 | xxx.xx.40.11
READ message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521263 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521468 | xxx.xx.40.11
Acquiring sstable references [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521566 | xxx.xx.40.11
Partition index with 0 entries found for sstable 1187 [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521775 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-1] | 2019-01-14 16:03:32.641000 | xxx.xx.47.100 | 266 | xxx.xx.40.11
Bloom filter allows skipping sstable 1188 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522130 | xxx.xx.40.11
Acquiring sstable references [ReadStage-1] | 2019-01-14 16:03:32.641000 | xxx.xx.47.100 | 361 | xxx.xx.40.11
Bloom filter allows skipping sstable 1189 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522205 | xxx.xx.40.11
Bloom filter allows skipping sstable 1190 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522259 | xxx.xx.40.11
Skipped 0/5 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522303 | xxx.xx.40.11
Bloom filter allows skipping sstable 1186 [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522415 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522540 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522679 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.49 [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522734 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522863 | xxx.xx.40.11
Partition index with 0 entries found for sstable 1208 [ReadStage-1] | 2019-01-14 16:03:32.644000 | xxx.xx.47.100 | 3756 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.647000 | xxx.xx.47.82 | 528443 | xxx.xx.40.11
Processing response from /xxx.xx.47.49 [RequestResponseStage-2] | 2019-01-14 16:03:32.647000 | xxx.xx.47.82 | 528516 | xxx.xx.40.11
Bloom filter allows skipping sstable 1209 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9090 | xxx.xx.40.11
Bloom filter allows skipping sstable 1210 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9162 | xxx.xx.40.11
Bloom filter allows skipping sstable 1211 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9187 | xxx.xx.40.11
Skipped 0/5 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9237 | xxx.xx.40.11
Bloom filter allows skipping sstable 1207 [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9335 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9571 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9734 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.49 [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9842 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 10116 | xxx.xx.40.11
Request complete | 2019-01-14 16:03:32.646708 | xxx.xx.47.82 | 528708 | xxx.xx.40.11
ESI에서 시작하는 모든 활동은 Esindex의 활동입니다.
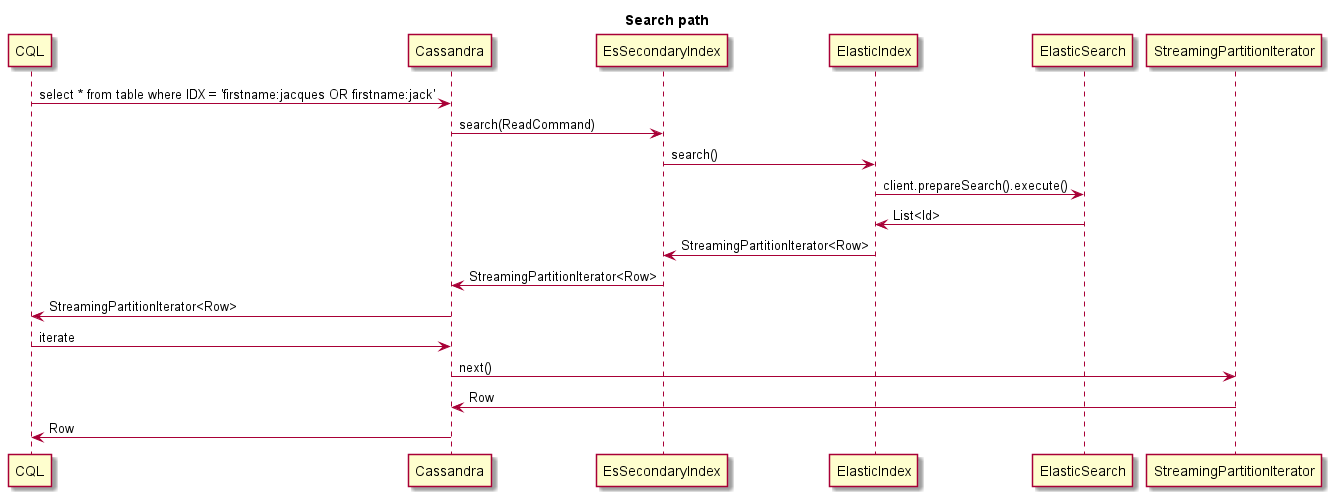
* ESI <id> Searching 'AttributeValues.LastName:ab*': The query have been received and decoded by the ESIndex, it is now sent to ElasticSearch
* ESI <id> Found 10000 matching ES docs in 514ms: The query to ElasticSearch has found 10000 results
* ESI <id> StreamingPartitionIterator initialized: Streaming partition iterator have been provided with all Ids found, and starts reading rows
* ESI <id> StreamingPartitionIterator closed: Client is done reading rows (limit was 1)
업데이트/인서트/삭제 추적
cqlsh:ucs> update "Contact" set "CreatedDate"='2017-04-01T11:21:59.001+0000' where "Id"='1001uiP2niJPJGBa';
추적 세션 : F76E4AC0-180E-11E9-B832-33A77983333
activity | timestamp | source | source_elapsed | client
----------------------------------------------------------------------------------------------------------------------------------------+----------------------------+---------------+----------------+--------------
Execute CQL3 query | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 0 | xxx.xx.40.11
MUTATION message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 22 | xxx.xx.40.11
Appending to commitlog [MutationStage-1] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 354 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-1] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 465 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [MutationStage-1] | 2019-01-14 16:12:35.212000 | xxx.xx.47.49 | 2356 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:12:35.212000 | xxx.xx.47.49 | 2548 | xxx.xx.40.11
Parsing update "Contact" set "CreatedDate"='2017-04-01T11:21:59.001+0000' where "Id"='1001uiP2niJPJGBa'; [Native-Transport-Requests-1] | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 146 | xxx.xx.40.11
Preparing statement [Native-Transport-Requests-1] | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 213 | xxx.xx.40.11
Determining replicas for mutation [Native-Transport-Requests-1] | 2019-01-14 16:13:37.133000 | xxx.xx.47.82 | 1895 | xxx.xx.40.11
Appending to commitlog [MutationStage-2] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2042 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-2] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2149 | xxx.xx.40.11
Sending MUTATION message to /xxx.xx.47.100 [MessagingService-Outgoing-/xxx.xx.47.100-Small] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2186 | xxx.xx.40.11
Sending MUTATION message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2232 | xxx.xx.40.11
MUTATION message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 28 | xxx.xx.40.11
Appending to commitlog [MutationStage-1] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 390 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-1] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 471 | xxx.xx.40.11
ESI decoding row 31303031756950326e694a504a474261 [MutationStage-1] | 2019-01-14 16:13:37.137000 | xxx.xx.47.100 | 579 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:13:37.137000 | xxx.xx.47.82 | 5160 | xxx.xx.40.11
ESI writing 31303031756950326e694a504a474261 to ES index [MutationStage-1] | 2019-01-14 16:13:37.137000 | xxx.xx.47.100 | 664 | xxx.xx.40.11
Processing response from /xxx.xx.47.49 [RequestResponseStage-4] | 2019-01-14 16:13:37.137000 | xxx.xx.47.82 | 5280 | xxx.xx.40.11
ESI index 31303031756950326e694a504a474261 done [MutationStage-1] | 2019-01-14 16:13:37.160000 | xxx.xx.47.100 | 23878 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.100 [MessagingService-Incoming-/xxx.xx.47.100] | 2019-01-14 16:13:37.160000 | xxx.xx.47.82 | 28445 | xxx.xx.40.11
Processing response from /xxx.xx.47.100 [RequestResponseStage-2] | 2019-01-14 16:13:37.160000 | xxx.xx.47.82 | 28549 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [MutationStage-1] | 2019-01-14 16:13:37.162000 | xxx.xx.47.100 | 25614 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:13:37.162000 | xxx.xx.47.100 | 25793 | xxx.xx.40.11
Request complete | 2019-01-14 16:13:37.814048 | xxx.xx.47.82 | 682048 | xxx.xx.40.11
ESI에서 시작하는 모든 활동은 Esindex의 활동입니다.
* ESI decoding row <rowId>: update request have been received by the ESIndex, row is being converted to JSON
* ESI writing <rowId> to ES index: update is being sent to ElasticSearch
* ESI index <rowId> done: ElasticSearch acknowledged the update
이것은 검색 할 때 발생하는 일의 예입니다.
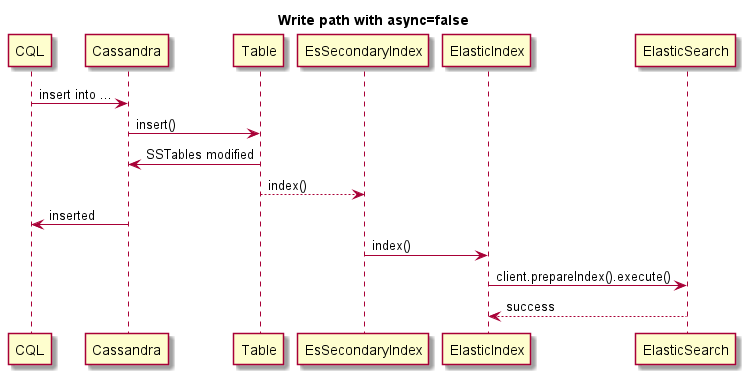
이것은 동기 쓰기의 예입니다 (ES가 실패하면 Cassandra 작동이 실패합니다) :
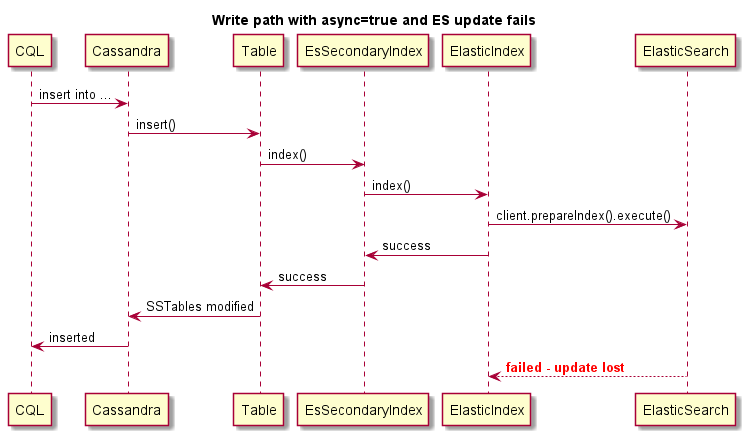
이것은 비동기 쓰기의 예입니다.
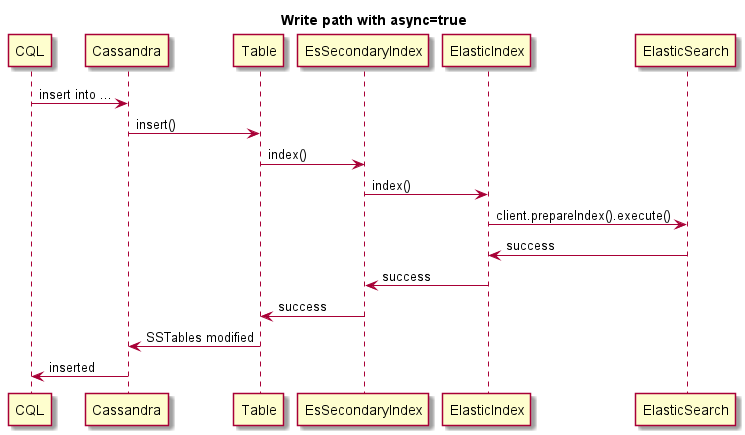
이것은 비동기 쓰기의 예입니다. ES가 실패하면 카산드라 작동이 실패 하지 않습니다 .