cassandra es index
1.0.0
<type>Diese Dokumentation erläutert die Verwendung und Konfiguration von "EsIndex", die ein Elasticsearch -basierter Sekundärindex für Cassandra ist.
Für dieses Plugin ist bereits ein Elasticsarch (ES) -Cluster konfiguriert.
Das Plugin wird in einer regulären Cassandra 4.0.x -Version installiert, die von http://cassandra.apache.org/ heruntergeladen wurde. Die Cassandra -Konfigurationsdateien können den Index nicht ändern. Das Verhalten von Cassandra bleibt für Anwendungen, die den Index nicht verwenden, unverändert.
Nachdem dieser Index in einer Cassandra -Tabelle erstellt wurde, können Elasticsearch -Abfragen "Volltext -Suche" auf Cassandra mithilfe von CQL und der Rückgabe von Matching -Zeilen von Cassandra -Daten zurückgegeben werden. Die Verwendung dieses Plugins erfordert keinen Wechsel von Cassandra -Quellcode. Wir haben den Elasticsearch -Index für Cassandra mithilfe von:
Getestete Versionen sind Elasticsearch 5.x, 6.x, 7.x und Cassandra 4.0.x. Das Plugin kann jedoch auch mit verschiedenen Elasticsearch -Versionen (1.7, 2.x 5.x, 6.x, 7.x) funktionieren, wenn die Anwendung die entsprechenden Zuordnungen und Optionen bereitstellt. Andere Versionen von Apache Cassandra wie 1.x 2.x, 3.x oder 4.1 werden nicht unterstützt, da die vom Plugin verwendete Sekundärindex -Schnittstelle unterschiedlich ist. Andere Cassandra -Anbieter werden nicht getestet, Scylladb wird nicht unterstützt.
| Versionen | Elasticsearch 1.x | Elasticsearch 2.x | Elasticsearch 5.x | Elasticsearch 6.x | Elasticsearch 7.x |
|---|---|---|---|---|---|
| Cassandra 1.x | NEIN | NEIN | NEIN | NEIN | NEIN |
| Cassandra 2.x | NEIN | NEIN | NEIN | NEIN | NEIN |
| Cassandra 3.x | NEIN | NEIN | NEIN | NEIN | NEIN |
| Cassandra 4.x | Beschränkt | Beschränkt | Beschränkt | Ja | Ja |
Dieses Projekt erfordert Maven und kompiliert mit Java 8., um das Plugin auf der Wurzel des Projekts auszuführen, um das Plugin zu erstellen:
MVN Clean Package
Dadurch wird ein "All in One Jar" in target/distribution/lib4cassandra aufgebaut
<dependency>
<groupId>com.genesyslab</groupId>
<artifactId>es-index</artifactId>
<version>9.2.000.00</version>
</dependency>
Siehe Github -Paket
Siehe Maven Repository
Setzen Sie es-index-9.2.000.xx-jar-with-dependencies.jar 000.xx-jar-with-abhängigen.jar. Starten oder starten Sie Ihre Cassandra -Knoten (en) neu.
Aufgrund des Mangels an Tests werden Tabellen mit Clustertasten nicht unterstützt. Es wird nur ein Partitionschlüssel unterstützt, zusammengesetzte Partitionschlüssel sollten funktionieren, wurden jedoch nicht ausgiebig getestet.
ESIndex unterstützt nur die Zeilenpegel -TTL, bei der alle Zellen gleichzeitig ausfallen und das entsprechende ES -Dokument gleichzeitig gelöscht werden kann. Wenn eine Zeile Zellen hat, die zu unterschiedlichen Zeiten ablaufen, wird das entsprechende Dokument beim Ablauf der letzten Zelle gelöscht. Wenn Sie unterschiedliche Zell -TTL verwenden, sind die von einer Suche zurückgegebenen Daten weiterhin konsistent, da Daten aus SSTable gelesen werden. Es ist jedoch weiterhin möglich, die Zeile mithilfe abgelaufener Daten mithilfe einer ES -Abfrage zu finden.
Es ist möglich, mehrere Indizes in derselben Tabelle zu erstellen. EsIndex verhindert dies nicht. Wenn jedoch mehr als ein ESIndex existiert, kann das Verhalten inkonsistent sein, eine solche Konfiguration wird nicht unterstützt. Der CQLSH -Befehl 'Beschreiben Sie Tabelle <ks.tableName>' kann verwendet werden, um in der Tabelle erstellte Indizes anzuzeigen und gegebenenfalls fallen zu lassen.
Erstellen Sie zuerst diesen Schlüsselspace:
CREATE KEYSPACE genesys WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1}
Verwenden wir die folgende Tabelle als Beispiel:
CREATE TABLE genesys.emails (
id UUID PRIMARY KEY,
subject text,
body text,
userid int,
query text
);
Sie müssen eine Dummy -Textspalte für die Indexnutzung widmen. Diese Spalte darf niemals Daten empfangen. In diesem Beispiel ist die query die Dummy -Spalte.
Hier finden Sie, wie Sie den Index für die Beispieltabelle erstellen und Eshost für Elasticsearch verwenden:
CREATE CUSTOM INDEX ON genesys.emails(query)
USING 'com.genesyslab.webme.commons.index.EsSecondaryIndex'
WITH OPTIONS = {'unicast-hosts': 'eshost:9200'};
Wenn Ihr Elasticsearch -Server beispielsweise auf localhost hört, ersetzen Sie Eshost durch Localhost .
Von CQL zurückgegebene Fehler sind sehr begrenzt. Wenn etwas schief geht, wie bei Ihrem Elasticsearch -Host, das nicht verfügbar ist, erhalten Sie eine Zeitüberschreitung oder eine andere Art von Ausnahme. Sie müssen Cassandra -Protokolle überprüfen, um zu verstehen, was schief gelaufen ist.
Wir haben keine Zuordnung bereitgestellt, daher sind wir uns auf die Elasticsearch -dynamische Zuordnung verlassen. Lassen Sie uns einige Daten einfügen:
INSERT INTO genesys.emails (id, subject, body, userid)
VALUES (904b88b2-9c61-4539-952e-c179a3805b22, 'Hello world', 'Cassandra is great, but it''s even better with EsIndex and Elasticsearch', 42);
Sie können sehen, dass der Index in Elasticsearch erstellt wird, wenn Sie den Zugriff auf Protokolle haben:
[o.e.c.m.MetaDataCreateIndexService] [node-1] [genesys_emails_index@] creating index, cause [api], templates [], shards [5]/[1], mappings []
[INFO ][o.e.c.m.MetaDataMappingService] [node-1] [genesys_emails_index@/waSGrPvkQvyQoUEiwqKN3w] create_mapping [emails]
Jetzt können wir Cassandra mit Elasticsearch über den Index durchsuchen. Hier finden Sie eine Lucene -Syntax -Suche:
select id, subject, body, userid, query from emails where query='body:cassan*';
id | subject | body | userid | query
--------------------------------------+-------------+-------------------------------------------------------------------------+--------+-------
904b88b2-9c61-4539-952e-c179a3805b22 | Hello world | Cassandra is great, but it's even better with EsIndex and Elasticsearch | 42 |
{
"_index": "genesys_emails_index@",
"_type": "emails",
"_id": "904b88b2-9c61-4539-952e-c179a3805b22",
"_score": 0.24257512,
"_source": {
"id": "904b88b2-9c61-4539-952e-c179a3805b22"
},
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.24257512
}
}
(1 rows)
(JSON wurde formatiert)
Alle Zeilen enthalten Daten von Cassandra, die unter Verwendung der CQL -Konsistenz aus Sstable geladen wurden. Daten in der Spalte "Abfrage" sind die von Elasticsearch zurückgegebenen Metadaten.
Hier erfahren Sie, wie Sie Elasticsearch abfragen, um die generierte Zuordnung zu überprüfen: GET http://eshost:9200/genesys_emails_index@/emails/_mapping?pretty
{
"genesys_emails_index@" : {
"mappings" : {
"emails" : {
"properties" : {
"IndexationDate" : {
"type" : " date "
},
"_cassandraTtl" : {
"type" : " long "
},
"body" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"id" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"subject" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"userid" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
}
}
}
}
}
}Das ESIndex -Plugin fügte zwei Felder hinzu:
Wir können sehen, dass die Zuordnung gut aussieht, aber Elasticsearch bemerkte nicht, dass UserID alle Texte Felder [Schlüsselwort] hinzugefügt hat.
So sieht die Daten in Elasticsearch aus:
GET http://localhost:9200/genesys_emails_index@/emails/_search?pretty&q=body:cassandra
{
"took" : 2 ,
"timed_out" : false ,
"_shards" : {
"total" : 5 ,
"successful" : 5 ,
"skipped" : 0 ,
"failed" : 0
},
"hits" : {
"total" : 1 ,
"max_score" : 0.2876821 ,
"hits" : [
{
"_index" : " genesys_emails_index@ " ,
"_type" : " emails " ,
"_id" : " 904b88b2-9c61-4539-952e-c179a3805b22 " ,
"_score" : 0.2876821 ,
"_source" : {
"id" : " 904b88b2-9c61-4539-952e-c179a3805b22 " ,
"body" : " Cassandra is great, but it's even better with EsIndex and Elasticsearch " ,
"subject" : " Hello world " ,
"userid" : " 42 " ,
"IndexationDate" : " 2019-01-15T16:53:00.107Z " ,
"_cassandraTtl" : 2147483647
}
}
]
}
} Lassen Sie uns die Zuordnung beheben, indem Sie den Index fallen lassen: drop index genesys.emails_query_idx; Dies wird auch den Elasticsearch -Index und die Daten fallen lassen!
und neu erstellen Sie es mit einer ordnungsgemäßen Zuordnung:
CREATE CUSTOM INDEX ON genesys.emails(query)
USING 'com.genesyslab.webme.commons.index.EsSecondaryIndex'
WITH OPTIONS = {
'unicast-hosts': 'localhost:9200',
'mapping-emails': '
{
"emails":{
"date_detection":false,
"numeric_detection":false,
"properties":{
"id":{
"type":"keyword"
},
"userid":{
"type":"long"
},
"subject":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"body":{
"type":"text"
},
"IndexationDate":{
"type":"date",
"format":"yyyy-MM-dd''T''HH:mm:ss.SSS''Z''"
},
"_cassandraTtl":{
"type":"long"
}
}
}
}
'};
Dadurch wird ein neuer Index erstellt, der die Zuordnungen bereitstellt und die Daten in Cassandra wiederherstellt.
Hier ist die resultierende ES -Zuordnung:
{
"genesys_emails_index@" : {
"mappings" : {
"emails" : {
"date_detection" : false ,
"numeric_detection" : false ,
"properties" : {
"IndexationDate" : {
"type" : " date " ,
"format" : " yyyy-MM-dd'T'HH:mm:ss.SSS'Z' "
},
"_cassandraTtl" : {
"type" : " long "
},
"body" : {
"type" : " text "
},
"id" : {
"type" : " keyword "
},
"subject" : {
"type" : " text " ,
"fields" : {
"keyword" : {
"type" : " keyword " ,
"ignore_above" : 256
}
}
},
"userid" : {
"type" : " long "
}
}
}
}
}
}Jetzt, da die Zuordnung ordnungsgemäß definiert ist, können wir UserID als Nummer durchsuchen. In diesem Beispiel verwenden wir Elasticsearch Query DSL:
select id, subject, body, userid from genesys.emails
where query='{"query":{"range":{"userid":{"gte":10,"lte":50}}}}';
@ Row 1
---------+-------------------------------------------------------------------------
id | 904b88b2-9c61-4539-952e-c179a3805b22
subject | Hello world
body | Cassandra is great, but it's even better with EsIndex and Elasticsearch
userid | 42
Es ist sehr wichtig, die Zuordnung kurz vor dem Start der Produktion zu erhalten. Die Rebedexing eines großen Tisches dauert viel Zeit und lädt Cassandra und Elasticsearch erheblich belastet. Sie müssen Cassandra -Protokolle auf Fehler in Ihrer ES -Zuordnung überprüfen. Stellen Sie sicher, dass Sie einzelne Zitate (') entkommen, indem Sie sie in den JSON -Optionen verdoppeln, die dem Befehl create Index erstellt wurden.
Im Folgenden finden Sie alle Optionen, die sich auf die Konfiguration des Elasticsearch -Index beziehen. Schlüsselnamen können Bindestriche verwenden, 'char oder Punkte. Zum Beispiel funktionieren beide Namen:
Beachten Sie, dass alle folgenden Optionen spezifisch für die Implementierung von Genesys und nicht für Elasticsearch selbst sind.
Wenn keine Scherzklassen gefunden werden, ist der Dummy -Modus aktiviert und es gilt keine anderen Fälle.
Multi-DataCenter wird unterstützt und die Daten werden nur über Cassandra-Klatschreplikation repliziert. ES -Cluster auf verschiedenen DCs sind nicht gleich und sollten niemals miteinander verbunden werden, da die Leistung beeinträchtigt wird. Da Daten auf der Tabellenebene repliziert werden, wird ESIndex in jedem DC ein Update erhält und der lokale ES -Cluster wird ebenfalls aktualisiert.
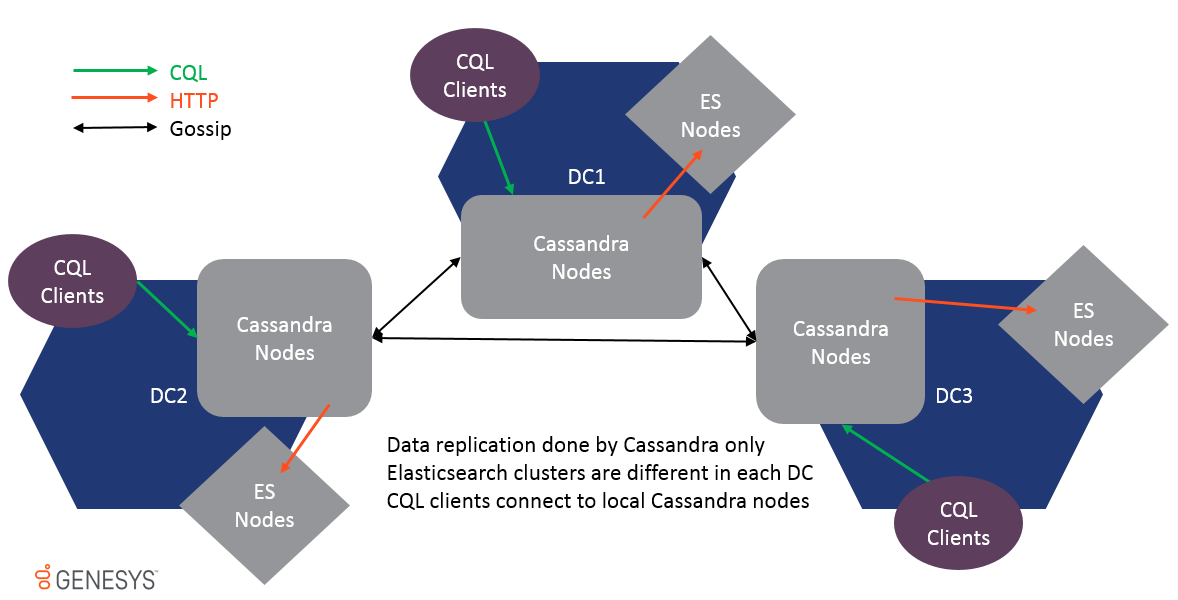
Um Multi-DC zu unterstützen, können alle Optionen nach Datencenter- und Rack-Namen vorangestellt werden, um die Einstellungen auf Ort zu stellten, beispielsweise:
Um den Cassandra -Index für Elasticsearch mit Anmeldeinformationen bereitzustellen, muss jeder Knoten die Umgebungsvariablen -Escredentials vor dem Start korrekt eingestellt haben. Dies muss auf alle Cassandra -Hosts eingestellt werden.
Das folgende Beispiel bietet das Kennwort für den Benutzer 'elastischer' und Kennwort 'Beispielpasswort' getrennt durch: (Colon) Zeichen. Es kann entweder direkt im System als Umgebungsvariable oder in der Verknüpfung erfolgen, die Cassandra startet.
Escredentials = Elastic: BeispielPassword Wenn der Index erfolgreich initialisiert wurde, schreibt er "Elasticsearch -Anmeldeinformationen" in Cassandra -Protokollen auf Info -Ebene. Sobald diese Nachricht ausgegeben ist, ist es möglich, die Umgebungsvariable zu löschen. Wenn Cassandra neu gestartet wird, muss die Umgebungsvariable vor dem Start erneut festgelegt werden. Die Anmeldeinformationen werden nur im Speicher gehalten und nirgendwo anders gespeichert. Wenn Benutzer und/oder Kennwort geändert werden, müssen alle Cassandra -Knoten mit dem variablen Umgebungswert neu gestartet werden.
Im Indexoptionen gesetzt
Unicast-Hosts = https : //<host name>:9200
Derzeit ist es nicht möglich, einen vorhandenen Index von HTTP auf HTTPS zu migrieren. Die Verwendung eines oder anderen muss entschieden werden, bevor Sie das Cassandra -Schema erstellen. Um die HTTPS -Bereitstellung zu erleichtern, vertraut der Index automatisch allen HTTPS -Zertifikaten.
Es ist möglich, Daten über einen längeren Zeitraum auf der Seite von Elasticsearch zu halten als definierte Cassandra TTL. Dieser Modus wird mithilfe der ES-Analytic-Modus-Option gedreht. Wenn die Option aktiviert ist, überspringt ElasticIndex alle Löschvorgänge.
Um zu verhindern, dass die Daten zu sehr auf der ES-Seite wachsen, wird empfohlen, TTL-Shift- und Force-Delete-Einstellungen zu verwenden.
Beim Erstellen des Index werden Sie Indexoptionen sowie Elasticsearch -Indexoptionen angeben, indem Sie den Befehl "Option" verwenden.
Indexoptionen sollten bei der Indexerstellung angegeben werden, hier ist ein Beispiel
CREATE CUSTOM INDEX on genesys.email(query) using 'com.genesyslab.webme.commons.index.EsSecondaryIndex' WITH options =
{
'read-consistency-level':'QUORUM',
'insert-only':'false',
'index-properties': '{
"index.analysis.analyzer.dashless.tokenizer":"dash-ex",
"index.analysis.tokenizer.dash-ex.pattern":"[^\\w\\-]",
"index.analysis.tokenizer.dash-ex.type":"pattern"
}',
'mapping-email': '{
"email": {
"dynamic": "false",
"properties": {
"subject" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}',
'discard-nulls':'false',
'async-search':'true',
'async-write':'false'
};
Sie können Optionen auch mithilfe von Umgebungsvariablen oder Java-Systemeigenschaften einstellen oder überschreiben, indem Sie Optionen mit "GeneSys-ES-" Präfixen einstellen.
Optionen im Befehl "Custom Custom Index Create Index erstellen" werden zuerst verwendet. Sie können lokal unter Verwendung einer Datei namens es-Index.properties in ".", "./Conf/", "../conf/" oder "./Bin/" überschrieben werden. (Kann mit -DGenesys-E-ESI-File oder -dgenesys.es.essi.file System-Eigenschaft geändert werden)
Hier ist ein Beispiel für den Inhalt der Datei:
Nur einfügen = true entschaltungsnulls = false async-write = false
| Name | Standard | Beschreibung |
|---|---|---|
| Max-Results | 10000 | Anzahl der Ergebnisse, die aus ES -Suchvorgängen gelesen werden sollen, um Cassandra -Zeilen zu laden. |
| Lesekonsistenz-Ebene | EINS | Mit dieser Konsistenzebene werden Cassandra-Reihen verwendet. |
| Nur einfügen | FALSCH | Standardmäßig wird ESIndex Upsert -Vorgänge einsetzen. In Einfügen werden nur Daten überschrieben. |
| asynchrones Schreiben | WAHR | Sendet Indexaktualisierungen asynchron, ohne die korrekte Ausführung zu überprüfen. Dies liefert viel schnellere Schreibvorgänge, aber Daten können inkonsistent werden, wenn ES -Cluster nicht verfügbar ist, da Schreibvorgänge nicht fehlschlagen. Standard ist wahr. |
| Segment | AUS | Off, Stunde, Tag, Monat, Jahr, benutzerdefinierte automatische Indexsegmentierung wird durch diese Einstellung gesteuert. Wenn es auf den Tag festgelegt ist, wird jeden Tag ein neuer Index unter dem Alias erstellt. Beachten Sie, dass leere Indizes jede Stunde automatisch gelöscht werden. HINWEIS: Die Einstellung der Stunden ist entmutigt, da viele Indizes erzeugt werden und die Leistung verringern können. Diese Einstellung wird für Entwicklung und Testzwecke empfohlen. |
| Segmentname | Wenn Segment = Custom dieser Wert für die neue Indexerstellung verwendet wird. | |
| Mapping- <Typ> | {} | Für jeden Sekundärindex wird der Tabellenname als Typ übergeben, z. B. Mapping-vist = {JSON-Definition}. |
| Unicast-Hosts | http: // localhost: 9200 | Eine von Comma getrennte Liste von Host, kann Host1, Host2, Host3 oder http: // host1, http: // host2, http: // host3 oder http: // host1: 9200, http: // host2: 9200, http: // host3: 9200 sein. Wenn Protokoll oder Port an angenommen werden, fehlen HTTP und 9200. Es ist möglich, HTTPS zu verwenden. |
| Nulls wegwerfen | WAHR | Übergeben Sie keine Nullwerte an den ES -Index, sondern bedeutet, dass Sie keinen Wert löschen können. Standard ist wahr . |
| Index-Propertien | {} | Eigenschaften als JSON -Zeichenfolge, die zum Erstellen eines neuen Index bestanden wurden, können beispielsweise Tokenizer -Definitionen enthalten. |
| JSON-serialisierte Felder | {} | Eine coma getrennte Zeichenfolge, die definiert, dass eine Stringspalte als JSON -Zeichenfolge indiziert werden muss. Nicht-JSON-Parsersable-Saiten verhindern Einsätze in Cassandra. |
| JSON-Flat-serialisierte Felder | {} | Eine von Coma getrennte Zeichenfolge, die definiert, dass eine Stringspalte als Typ-Safe-JSON-Dokument indiziert werden muss. Elasticsearch JSON Mapping erlaubt es nicht, einen Wert zu indizieren, der den Typ im Laufe der Zeit ändert. Zum Beispiel {"Key": "value"} kann nicht {"Key" werden: {"subKey": "value"}} In Elasticsearch erhalten Sie eine Zuordnungsausnahme. Ein solcher JSON-Flat wird in ein JSON-Objekt mit String-Tasten und -Arrays von String als Werte umgewandelt. |
| Dummy | FALSCH | Deaktiviert den Sekundärindex vollständig. Beachten Sie, dass der Index automatisch in den Dummy -Modus in den Dummy -Modus eingefügt wird, wenn Scherzklassen nicht gefunden werden. |
| Validierungsfragen validieren | FALSCH | Sendet Suchanfragen zur Validierung an ES, um aussagekräftige Syntaxfehler anstelle von Cassandra Timeouts bereitzustellen. |
| gleichzeitige Lock | WAHR | Sperrt Indexausführungen auf Partitions -ID. Dies verhindert Parallelitätsprobleme, wenn sie gleichzeitig mit mehreren Aktualisierungen derselben Partition behandelt werden. |
| Replay überspringen | WAHR | Wenn ein Cassandra -Knoten beginnt, wird das Commit -Protokoll wiederholt, diese Updates werden übersprungen, um die Startzeit zu verbessern, da sie bereits auf ES angewendet wurden. |
| Skip-Non-Local-Updates | WAHR | Um die Leistung zu verbessern, die diese Einstellung aktiviert, werden nur Indexaktualisierungen für die Master -Replik des Token -Bereichs ausgeführt. |
| Es-Analytikmodus | FALSCH | Deaktiviert Deletten (TTL oder Löschen aus) der ES -Dokumente. |
| Typ-Pipelines | keiner | Liste des Typs zum Einrichten von Pipelines. |
| Pipeline- <Typ> | keiner | Pipeline -Definition für diesen Typ. |
| index.translog.durability | asynchron | Beim Erstellen eines Index verwenden wir den asynchronisierten Ausschussesmodus, um die beste Leistung zu gewährleisten, die Standardeinstellung in ES 1.7. Da 2.x Synchronisation ist, führt es zu einer schwerwiegenden Leistungsverschlechterung. |
| Erhältlich, während der Rebuilding | WAHR | Beim Erstellen eines neuen Index ist es möglich (oder nicht), die Suche im Teilindex auszuführen. |
| Truncate-Rebuild | FALSCH | Schnitt -ES -Index vor dem Wiederaufbau. |
| Säuberung | 60 | Alle 60 Minuten werden alle leeren Indizes aus dem Alias gelöscht. |
| pro-Index-Typ | WAHR | Bereiten Sie den Indexnamen mit dem Tabellennamen vor. In ES 5.x ist es nicht mehr möglich, eine andere Zuordnung für denselben Feldnamen in verschiedenen Arten desselben Index zu haben. In ES 6.x werden Typen entfernt. |
| Kraftdelete | FALSCH | Jede Minute wird eine Anforderung "per Abfrage löschen" an ES gesendet, um Dokumente zu löschen, die _cassandrattl abgelaufen sind. Dies soll die TTL -Funktionalität emulieren, die in ES 5.x entfernt wurde. Beachten Sie, dass die Cassandra -Verdichtung zwar tatsächlich ein Dokument von ES löscht, es gibt keine Garantie darüber, wann es auftritt. |
| TTL-Shift | 0 | Zeit in Sekunden zur Verschiebung von Cassandra TTL. Wenn TTL in Cassandra 1 Stunde war und die Verschiebung 3600 beträgt, bedeutet dies, dass Dokument in ES 1 Stunde später als Cassandra gelöscht werden. |
| Indexmanager | com.genesysslab.webme.commons.index.defaultIndexManager | Index Manager -Klasse -Name. Wird zur Manager -Segmentierung und zur Ablauffunktionalität verwendet. |
| Segmentgröße | 86400000 | Segment -Zeitrahmen in Millisekunden. Jeder "Segment-Size" -Millisekunden neue Index wird erstellt, indem die folgende Vorlage folgt: <alias_name> _index@<yyyymmdd'hhmmss'z '> |
| Max-Verknüpfungen-pro-Route | 2 | Anzahl der HTTP -Verbindung pro ES -Knoten, Standardeinstellung ist Apache HTTP -Poolwert, kann die Leistung des Cassandra -Index erhöhen, aber die Last auf ES erhöhen. (Neu im WCC 9.0.000.15) |
Sie sollten die Erkennung der Datum in Ihrer Zuordnungsdefinition deaktivieren.
Der folgende JSON:
{
"maps" : {
"key1" : " value " ,
"key2" : 42 ,
"keymap" : {
"sss1" : null ,
"sss2" : 42 ,
"sss0" : " ffff "
},
"plap" : " plop "
},
"string" : " string " ,
"int" : 42 ,
"plplpl" : [ 1 , 2 , 3 , 4 ]
}Wird konvertiert in:
{
"maps" : [ " key1=value " , " key2=42 " , " keymap={sss1=null, sss2=42, sss0=ffff} " , " plap=plop " ],
"string" : [ " string " ],
"int" : [ " 42 " ],
"plplpl" : [ " 1 " , " 2 " , " 3 " , " 4 " ]
}Mögliche Werte:
<type>Weitere Informationen zum Typ -Mapping finden Sie unter Elasticsearch -Dokumentation: http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/mapping.html
Alle Cassandra -Spalten -Typen werden unterstützt, Daten werden als Zeichenfolge, ein Array oder eine Karte gesendet, abhängig vom Typ Cassandra. Mit der richtigen Zuordnung wandelt Elasticsearch die Daten in den entsprechenden Typ um. Dies ermöglicht viel bessere Suchanfragen und Berichterstattung.
| Cassandra -Typen | Elasticsearch empfohlen Mapping | Kommentar |
|---|---|---|
| ASCII | Text oder Schlüsselwort | Siehe nächsten Abschnitt zum Texttyp |
| Bigint | lang | |
| Klecks | deaktiviert | Es ist nicht möglich, binäre Inhalte zu indizieren |
| boolean | boolean | |
| Schalter | lang | |
| Datum | Datum | |
| dezimal | doppelt | |
| doppelt | doppelt | |
| schweben | doppelt | |
| inet | Stichwort | Es wird nicht getestet |
| int | int | |
| Liste <Typs> | Gleich wie Typ | ES erwartet, dass ein Typ entweder ein einzelner Wert oder ein Array sein kann |
| Karte < typek , typev > | Objekt | Wenn Ihre Schlüssel viele verschiedene Werte haben können, achten Sie darauf, Explosion zuzuordnen |
| Setzen Sie <Typ> | Gleich wie Typ | ES erwartet, dass ein Typ entweder ein einzelner Wert oder ein Array sein kann |
| Smallint | int | |
| Text | Text oder Schlüsselwort | Siehe nächsten Abschnitt zum Texttyp |
| Zeit | Stichwort | |
| Zeitstempel | "Typ": "Date", "Format": "Yyyy-mm-dd't'hh: mm: ss.sss'z '" | |
| Zeituuid | Stichwort | |
| Tinyint | int | |
| Tuple <type1 Typ2, ...> | Typ | |
| Uuid | Stichwort | |
| varchar | Text oder Schlüsselwort | Siehe nächsten Abschnitt zum Texttyp |
| Varint | lang | |
| Benutzerdefinierter Typ | Objekt | Jedes UDT -Feld wird mit ihren Namen und Werten zugeordnet |
Zuordnung des Texttyps
Wenn eine Spalte von Text (ASCII oder VARCHAR) an ES gesendet wird, wird sie als Rohtext gesendet, der indexiert werden soll. Wenn der Text jedoch ordnungsgemäß ist, ist es möglich, ihn als JSON -Dokument für die Index zu senden. Dadurch können Sie das Dokument anstelle eines Rohtextes indexieren/durchsuchen.
Durch die Verwendung eines solchen JSON -Mapping können Daten mit "ColumnName.Key: Value" durchsucht.
Wenn Ihre Schlüssel viele verschiedene Werte haben können, achten Sie darauf, Explosion zuzuordnen
JSON-serialisierte Felder (siehe Optionen für Details)
Der Inhalt des Textes wird als JSON gesendet. In Ihrer Zuordnung können Sie jedes Dokumentfeld separat definieren. Beachten Sie, dass nach statischer Zuordnung oder dynamischer Mapping ein Feld als Typ abgebildet wurde, sodass ein inkompatibler Typ zu Cassandra -Schreibfehlern führt.
JSON-Flat-serialisierte Felder (Beispiele für Details und Konvertierungsbeispiel)
Der Inhalt des Textes wird ebenfalls als JSON gesendet, alle Werte sind jedoch gezwungen, Flat -Saiten zu verhindern. Dies begrenzt die Fähigkeit, nach verschachtelten JSON zu suchen, ist jedoch sicherer, wenn Sie den JSON -Typ der Werte nicht kontrollieren können.
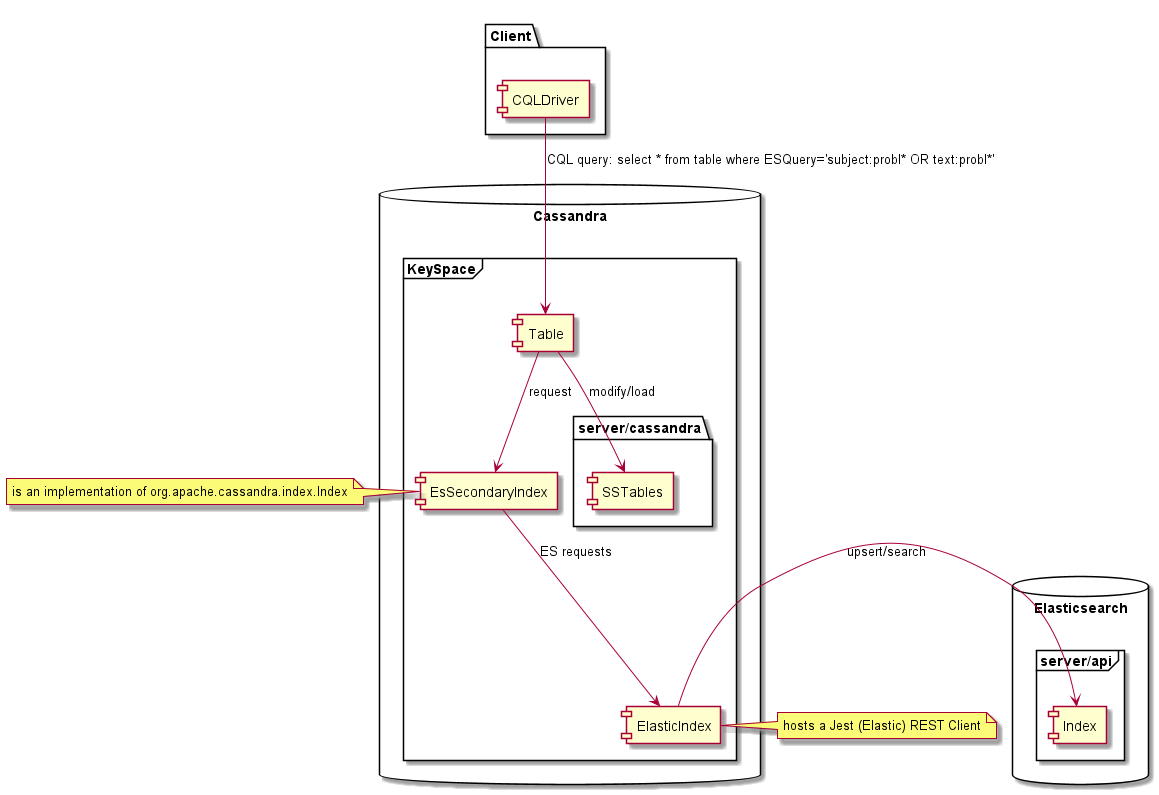
Es handelt sich um eine benutzerdefinierte Implementierung eines Cassandra -Index. Dies führt zu einigen Einschränkungen, die mit dem Cassandra -Konsistenzmodell verbunden sind. Die Hauptbeschränkung ist auf die Art der Sekundärindizes von Cassandra zurückzuführen. Jeder Cassandra -Knoten enthält nur Daten, die im Cassandra -Ring verantwortlich sind. Mit sekundären Indizes ist es dasselbe. Jeder Knoten indiziert nur seine lokalen Daten. Dies bedeutet, dass bei einer Abfrage im Index die Abfrage an alle Knoten gesendet wird und die Ergebnisse vom Abfragekoordinator aggregiert und an die Kunden zurückgegeben werden.
Bei ESIndex ist es anders, da die Indexsuche auf Elasticsearch basiert, kann jeder Knoten auf die Abfrage reagieren. Dies bedeutet, dass die Abfrage nur an einen einzelnen Knoten gesendet werden darf, oder Ergebnis enthält Duplikate. Dies wird erreicht, indem ein Token wie unten in die CQL -Abfrage gezwungen wird.
select * from emails where query='subject:12345' and token(id)=0;
Das Token sollte einen zufälligen langen Wert sein, um Abfragen über Knoten hinweg zu verbreiten. Es muss auf dem Partitionschlüssel der Reihe "ID" im obigen Beispiel aufgebaut werden.
Im obigen Beispiel lautet die Elasticsearch -Abfrage 'Subjekt: 12345'. Dies ist eine Lucene -ähnliche Frage. Es ist auch möglich, DSL-Abfragen auszuführen. Weitere Informationen finden Sie in Elasticsearch Query-DSL-Seite.
Ein einzelner Elasticsearch -Index enthält alle Cassandra -Tabellenindizes für einen bestimmten Schlüsselraum. Für jeden Index wird ein dedizierter Elasticsearch -Typ verwendet. Um Cross-Table-Aggregationen zu ermöglichen, wird der Typ in den Abfragen nicht durchgesetzt. Wenn Ihre Abfrage mit unterschiedlichen Typen übereinstimmen kann, wird mehr IDs als erwartet zurückgegeben. Da diese nicht mit Cassandra -Zeilen übereinstimmen, werden Sie nicht mehr Ergebnisse erzielen, aber Sie können auch weniger bekommen, wenn Sie die Anzahl der zurückgegebenen Ergebnisse begrenzen.
Wenn die angepasste Zeilenzahl hoch ist und die Zeilen groß sind, können die Suchvorgänge in der Lesen von Timeout enden. Sie können nur anfordern, dass PK mit ES -Metadaten zurückgegeben und anschließend Zeilen parallel von Ihrem Code mit CQL -Abfragen laden.
Um dem Index zu sagen, dass Pks nur zurückgegeben werden soll, müssen Sie die folgende Abfrage-Hinweis #Options: load-rows = false #:
select * from emails where query='#options:load-rows=false#id:ab*';
Es ist wichtig zu beachten, dass die zurückgegebenen Zeilen gefälscht und aus den Ergebnissen der Elasicsearch -Abfrage erstellt werden. Es bedeutet, dass zurückgegebene Zeilen möglicherweise nicht mehr existieren:
Wenn eine Suchanforderung ein Ergebnis zurückgibt, enthält die erste Zeile die Elasticsearch -Metadaten als ## eine JSON -Zeichenfolge in der Spalte des Index. Siehe zum Beispiel:
cqlsh:ucs> select id,query from emails where query='id:00008RD9PrJMMmpr';
id | query
------------------+---------------------------------------------------------------------------------------------------------------------
00008RD9PrJMMmpr | {"took":5,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":1,"max_score":7.89821}}
Der Segmentierungsmechanismus von ESIndex spaltet den monolithischen Elasticsearch-Index in die Abfolge zeitbasierter Indizes. Die Zwecke dafür folgen:
Da Elasticsearch 5.x TTL nicht mehr unterstützt wird. Die normalen Verdichtungs- und Reparaturprozesse von Cassandra entfernen jedoch automatisch eine Tombstone -Daten. ElasticIndex entfernen die Daten aus Elasticsarch.
ESIndex unterstützt die CQL -Verfolgung. Sie kann auf einem Knoten aktiviert werden oder mit CQLSH mit dem folgenden Befehl:
Verfolgung auf;
Die Auswahl ausgewählt, dann erhalten Sie Spuren von der gesamten Abfrage gegen alle teilnehmenden Knoten:
cqlsh:ucs> select * from "Contact" where "ESQuery"='AttributeValues.LastName:ab*' and token("Id")=0 limit 1;
Id | AttributeValues | AttributeValuesDate | Attributes| CreatedDate | ESQuery | ExpirationDate | MergeIds | ModifiedDate| PrimaryAttributes| Segment| TenantId
1001uiP2niJPJGBa | {"LastName":["IdentifyTest-aBEcKPnckHVP"],"EmailAddress":["IdentifyTest-HHzmNornOr"]} |{} | {'EmailAddress_IdentifyTest-HHzmNornOr': {Id: 'EmailAddress_IdentifyTest-HHzmNornOr', Name: 'EmailAddress', StrValue: 'IentifyTest-HHzmNornOr', Description: null, MimeType: null, IsPrimary: False}, 'LastName_IdentifyTest-aBEcKPnckHVP': {Id: 'LastName_IdentifyTest-aBEcKPnckHVP', Name: 'LastName', StrValue: 'IdentifyTest-aBEcKPnckHVP', Description: null, MimeType: null IsPrimary: False}} | 2018-10-30 02:05:06.960000+0000 | {"_index":"ucsperf2_contact_index@","_type":"Contact","_id":"1001uiP2niJPJGBa","_score":1.0,"_source":{"Id":"1001uiP2niJPJGBa"},"took":485,"timed_out":false,"_shards":{"total":5,"successful":5,failed":0},"hits":{"total":18188,"max_score":1.0}} | null | null | 2018-10-30 02:05:06.960000+0000 | {'EmailAddress': 'IdentifyTest-HHzmNornOr', 'LastName': 'IdentifyTest-aBEcKPnckHVP'} | not-applicable |1
(1 rows)
Dann erhalten Sie Verfolgungsinformationen aus Ihrer Sitzung:
Tracing Session: 8ed07b60-180d-11e9-B832-33A777983333
activity | timestamp | source | source_elapsed | client
-----------------------------------------------------------------------------------------------------------------------------------------+----------------------------+---------------+----------------+--------------
Execute CQL3 query | 2019-01-14 16:03:32.118000 | xxx.xx.47.82 | 0 | xxx.xx.40.11
RANGE_SLICE message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:02:30.200000 | xxx.xx.47.49 | 34 | xxx.xx.40.11
Executing read on ucsperf2.Contact using index Contact_ESQuery_idx [ReadStage-1] | 2019-01-14 16:02:30.201000 | xxx.xx.47.49 | 411 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 Searching 'AttributeValues.LastName:ab*' [ReadStage-1] | 2019-01-14 16:02:30.201000 | xxx.xx.47.49 | 693 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 Found 10000 matching ES docs in 514ms [ReadStage-1] | 2019-01-14 16:02:30.716000 | xxx.xx.47.49 | 515336 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 StreamingPartitionIterator initialized [ReadStage-1] | 2019-01-14 16:02:30.717000 | xxx.xx.47.49 | 516911 | xxx.xx.40.11
reading data from /xxx.xx.47.100 [ReadStage-1] | 2019-01-14 16:02:30.717000 | xxx.xx.47.49 | 517121 | xxx.xx.40.11
speculating read retry on /xxx.xx.47.82 [ReadStage-1] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517435 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517436 | xxx.xx.40.11
Sending READ message to /xxx.xx.47.100 [MessagingService-Outgoing-/xxx.xx.47.100-Small] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517445 | xxx.xx.40.11
Sending READ message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517558 | xxx.xx.40.11
Acquiring sstable references [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517866 | xxx.xx.40.11
Bloom filter allows skipping sstable 83 [ReadStage-2] | 2019-01-14 16:02:30.718000 | xxx.xx.47.49 | 517965 | xxx.xx.40.11
Partition index with 0 entries found for sstable 400 [ReadStage-2] | 2019-01-14 16:02:30.719000 | xxx.xx.47.49 | 518300 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:02:30.720000 | xxx.xx.47.49 | 519720 | xxx.xx.40.11
Processing response from /xxx.xx.47.82 [RequestResponseStage-4] | 2019-01-14 16:02:30.720000 | xxx.xx.47.49 | 519865 | xxx.xx.40.11
Bloom filter allows skipping sstable 765 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522352 | xxx.xx.40.11
Bloom filter allows skipping sstable 790 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522451 | xxx.xx.40.11
Bloom filter allows skipping sstable 819 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522516 | xxx.xx.40.11
Bloom filter allows skipping sstable 848 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522662 | xxx.xx.40.11
Bloom filter allows skipping sstable 861 [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522741 | xxx.xx.40.11
Skipped 0/7 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-2] | 2019-01-14 16:02:30.723000 | xxx.xx.47.49 | 522855 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-2] | 2019-01-14 16:02:30.723001 | xxx.xx.47.49 | 523075 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-2] | 2019-01-14 16:02:30.723001 | xxx.xx.47.49 | 523164 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524717 | xxx.xx.40.11
ESI 00ebf964-b958-4e74-ab89-e0093a8ec188 StreamingPartitionIterator closed [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524805 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [ReadStage-1] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524872 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:02:30.725000 | xxx.xx.47.49 | 524971 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.100 [MessagingService-Incoming-/xxx.xx.47.100] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528222 | xxx.xx.40.11
Processing response from /xxx.xx.47.100 [RequestResponseStage-1] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528364 | xxx.xx.40.11
Initiating read-repair [RequestResponseStage-1] | 2019-01-14 16:02:30.729000 | xxx.xx.47.49 | 528481 | xxx.xx.40.11
Parsing select * from "Contact" where "ESQuery"='AttributeValues.LastName:ab*' and token("Id")=0 limit 1; [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 174 | xxx.xx.40.11
Preparing statement [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 254 | xxx.xx.40.11
Index mean cardinalities are Contact_ESQuery_idx:-2109988917941223823. Scanning with Contact_ESQuery_idx. [Native-Transport-Requests-1] | 2019-01-14 16:03:32.119000 | xxx.xx.47.82 | 418 | xxx.xx.40.11
Computing ranges to query [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2480 | xxx.xx.40.11
Submitting range requests on 1 ranges with a concurrency of 1 (-4.6099044E15 rows per range expected) [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2568 | xxx.xx.40.11
Enqueuing request to /xxx.xx.47.49 [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2652 | xxx.xx.40.11
Submitted 1 concurrent range requests [Native-Transport-Requests-1] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2708 | xxx.xx.40.11
Sending RANGE_SLICE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.121000 | xxx.xx.47.82 | 2874 | xxx.xx.40.11
READ message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.640000 | xxx.xx.47.100 | 29 | xxx.xx.40.11
READ message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521263 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521468 | xxx.xx.40.11
Acquiring sstable references [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521566 | xxx.xx.40.11
Partition index with 0 entries found for sstable 1187 [ReadStage-2] | 2019-01-14 16:03:32.640000 | xxx.xx.47.82 | 521775 | xxx.xx.40.11
Executing single-partition query on Contact [ReadStage-1] | 2019-01-14 16:03:32.641000 | xxx.xx.47.100 | 266 | xxx.xx.40.11
Bloom filter allows skipping sstable 1188 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522130 | xxx.xx.40.11
Acquiring sstable references [ReadStage-1] | 2019-01-14 16:03:32.641000 | xxx.xx.47.100 | 361 | xxx.xx.40.11
Bloom filter allows skipping sstable 1189 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522205 | xxx.xx.40.11
Bloom filter allows skipping sstable 1190 [ReadStage-2] | 2019-01-14 16:03:32.641000 | xxx.xx.47.82 | 522259 | xxx.xx.40.11
Skipped 0/5 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522303 | xxx.xx.40.11
Bloom filter allows skipping sstable 1186 [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522415 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522540 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522679 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.49 [ReadStage-2] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522734 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.641001 | xxx.xx.47.82 | 522863 | xxx.xx.40.11
Partition index with 0 entries found for sstable 1208 [ReadStage-1] | 2019-01-14 16:03:32.644000 | xxx.xx.47.100 | 3756 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:03:32.647000 | xxx.xx.47.82 | 528443 | xxx.xx.40.11
Processing response from /xxx.xx.47.49 [RequestResponseStage-2] | 2019-01-14 16:03:32.647000 | xxx.xx.47.82 | 528516 | xxx.xx.40.11
Bloom filter allows skipping sstable 1209 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9090 | xxx.xx.40.11
Bloom filter allows skipping sstable 1210 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9162 | xxx.xx.40.11
Bloom filter allows skipping sstable 1211 [ReadStage-1] | 2019-01-14 16:03:32.649000 | xxx.xx.47.100 | 9187 | xxx.xx.40.11
Skipped 0/5 non-slice-intersecting sstables, included 0 due to tombstones [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9237 | xxx.xx.40.11
Bloom filter allows skipping sstable 1207 [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9335 | xxx.xx.40.11
Merged data from memtables and 1 sstables [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9571 | xxx.xx.40.11
Read 1 live and 0 tombstone cells [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9734 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.49 [ReadStage-1] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 9842 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:03:32.650000 | xxx.xx.47.100 | 10116 | xxx.xx.40.11
Request complete | 2019-01-14 16:03:32.646708 | xxx.xx.47.82 | 528708 | xxx.xx.40.11
Alle Aktivitäten ab ESI sind Aktivitäten von EsIndex:
* ESI <id> Searching 'AttributeValues.LastName:ab*': The query have been received and decoded by the ESIndex, it is now sent to ElasticSearch
* ESI <id> Found 10000 matching ES docs in 514ms: The query to ElasticSearch has found 10000 results
* ESI <id> StreamingPartitionIterator initialized: Streaming partition iterator have been provided with all Ids found, and starts reading rows
* ESI <id> StreamingPartitionIterator closed: Client is done reading rows (limit was 1)
Verfolgung von Updates/Einfügen/Löschungen
cqlsh:ucs> update "Contact" set "CreatedDate"='2017-04-01T11:21:59.001+0000' where "Id"='1001uiP2niJPJGBa';
Tracing Session: F76E4AC0-180E-11E9-B832-33A777983333
activity | timestamp | source | source_elapsed | client
----------------------------------------------------------------------------------------------------------------------------------------+----------------------------+---------------+----------------+--------------
Execute CQL3 query | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 0 | xxx.xx.40.11
MUTATION message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 22 | xxx.xx.40.11
Appending to commitlog [MutationStage-1] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 354 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-1] | 2019-01-14 16:12:35.210000 | xxx.xx.47.49 | 465 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [MutationStage-1] | 2019-01-14 16:12:35.212000 | xxx.xx.47.49 | 2356 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:12:35.212000 | xxx.xx.47.49 | 2548 | xxx.xx.40.11
Parsing update "Contact" set "CreatedDate"='2017-04-01T11:21:59.001+0000' where "Id"='1001uiP2niJPJGBa'; [Native-Transport-Requests-1] | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 146 | xxx.xx.40.11
Preparing statement [Native-Transport-Requests-1] | 2019-01-14 16:13:37.132000 | xxx.xx.47.82 | 213 | xxx.xx.40.11
Determining replicas for mutation [Native-Transport-Requests-1] | 2019-01-14 16:13:37.133000 | xxx.xx.47.82 | 1895 | xxx.xx.40.11
Appending to commitlog [MutationStage-2] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2042 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-2] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2149 | xxx.xx.40.11
Sending MUTATION message to /xxx.xx.47.100 [MessagingService-Outgoing-/xxx.xx.47.100-Small] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2186 | xxx.xx.40.11
Sending MUTATION message to /xxx.xx.47.49 [MessagingService-Outgoing-/xxx.xx.47.49-Small] | 2019-01-14 16:13:37.134000 | xxx.xx.47.82 | 2232 | xxx.xx.40.11
MUTATION message received from /xxx.xx.47.82 [MessagingService-Incoming-/xxx.xx.47.82] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 28 | xxx.xx.40.11
Appending to commitlog [MutationStage-1] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 390 | xxx.xx.40.11
Adding to Contact memtable [MutationStage-1] | 2019-01-14 16:13:37.136000 | xxx.xx.47.100 | 471 | xxx.xx.40.11
ESI decoding row 31303031756950326e694a504a474261 [MutationStage-1] | 2019-01-14 16:13:37.137000 | xxx.xx.47.100 | 579 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.49 [MessagingService-Incoming-/xxx.xx.47.49] | 2019-01-14 16:13:37.137000 | xxx.xx.47.82 | 5160 | xxx.xx.40.11
ESI writing 31303031756950326e694a504a474261 to ES index [MutationStage-1] | 2019-01-14 16:13:37.137000 | xxx.xx.47.100 | 664 | xxx.xx.40.11
Processing response from /xxx.xx.47.49 [RequestResponseStage-4] | 2019-01-14 16:13:37.137000 | xxx.xx.47.82 | 5280 | xxx.xx.40.11
ESI index 31303031756950326e694a504a474261 done [MutationStage-1] | 2019-01-14 16:13:37.160000 | xxx.xx.47.100 | 23878 | xxx.xx.40.11
REQUEST_RESPONSE message received from /xxx.xx.47.100 [MessagingService-Incoming-/xxx.xx.47.100] | 2019-01-14 16:13:37.160000 | xxx.xx.47.82 | 28445 | xxx.xx.40.11
Processing response from /xxx.xx.47.100 [RequestResponseStage-2] | 2019-01-14 16:13:37.160000 | xxx.xx.47.82 | 28549 | xxx.xx.40.11
Enqueuing response to /xxx.xx.47.82 [MutationStage-1] | 2019-01-14 16:13:37.162000 | xxx.xx.47.100 | 25614 | xxx.xx.40.11
Sending REQUEST_RESPONSE message to /xxx.xx.47.82 [MessagingService-Outgoing-/xxx.xx.47.82-Small] | 2019-01-14 16:13:37.162000 | xxx.xx.47.100 | 25793 | xxx.xx.40.11
Request complete | 2019-01-14 16:13:37.814048 | xxx.xx.47.82 | 682048 | xxx.xx.40.11
Alle Aktivitäten ab ESI sind Aktivitäten von EsIndex:
* ESI decoding row <rowId>: update request have been received by the ESIndex, row is being converted to JSON
* ESI writing <rowId> to ES index: update is being sent to ElasticSearch
* ESI index <rowId> done: ElasticSearch acknowledged the update
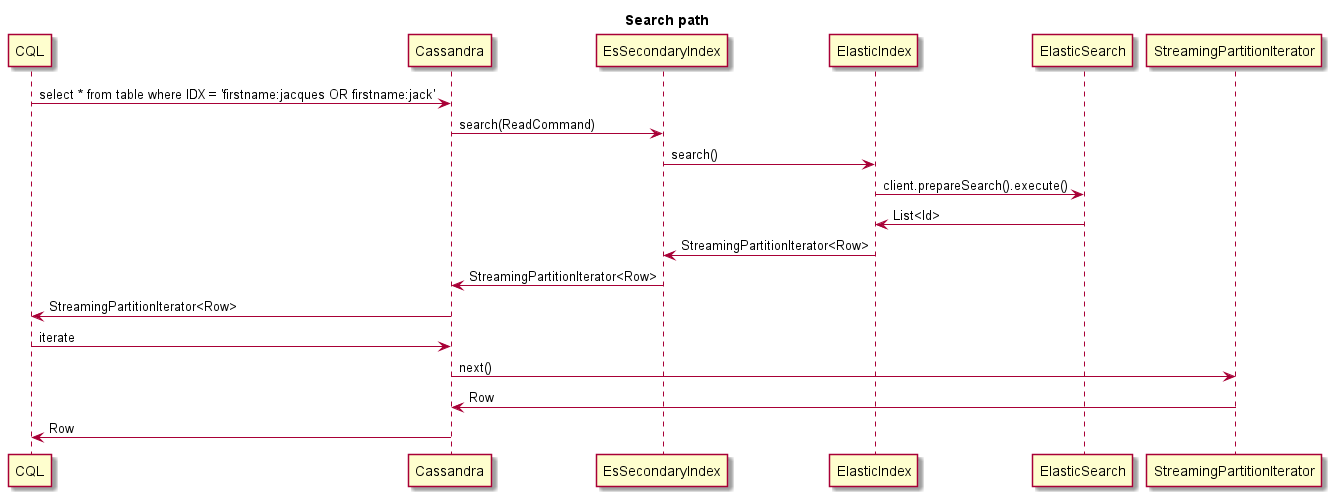
Dies ist ein Beispiel dafür, was bei der Suche passiert:
Dies ist ein Beispiel für synchrones Schreiben (Cassandra -Operation schlägt fehl, wenn ES fehlschlägt):
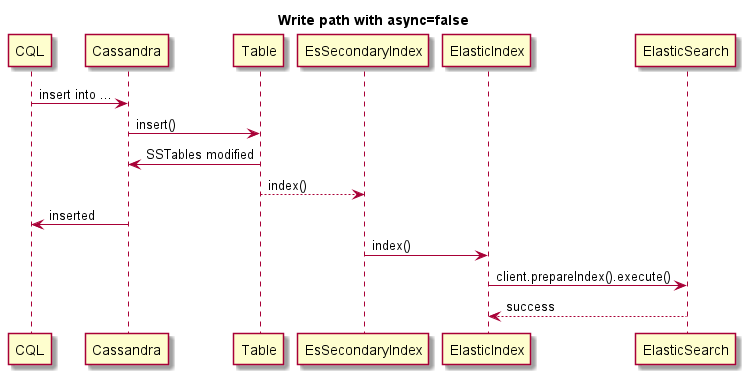
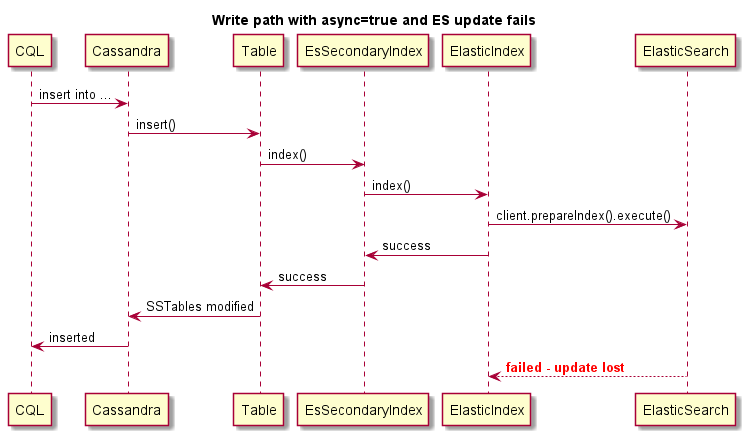
Dies ist ein Beispiel für asynchrones Schreiben:
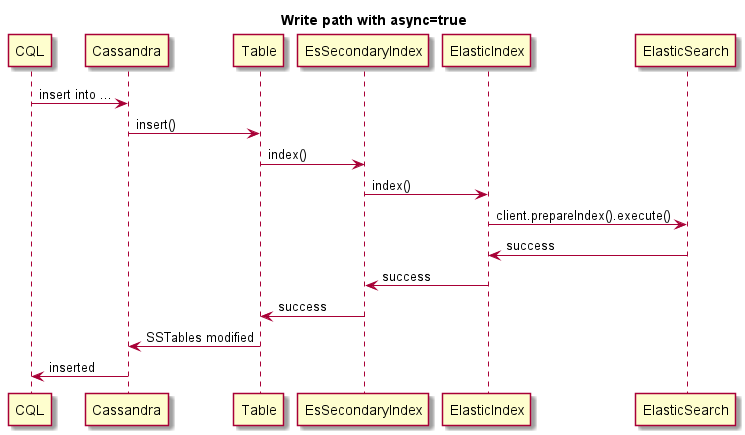
Dies ist ein Beispiel für asynchrones Schreiben. Die Cassandra -Operation schlägt nicht aus, wenn ES ausfällt: