detext
v2.0.8 Release Note
O Detext é uma estrutura de entendimento de texto de EP para tarefas de classificação, classificação e geração de idiomas relacionadas à PNL. Ele aproveita a correspondência semântica usando redes neurais profundas para entender os intenções dos membros nos sistemas de pesquisa e recomendação.
Como uma estrutura geral do NLP, o Detext pode ser aplicado a muitas tarefas, incluindo classificação de pesquisa e recomendação, classificação de várias classes e tarefas de compreensão de consultas.
Mais detalhes podem ser encontrados na postagem do blog de engenharia do LinkedIn.
O Detext suporta uma arquitetura de modelo geral que contém os seguintes componentes:
Camada de incorporação de palavras . Ele converte a sequência de palavras em anúncio por n matriz.
CNN/BERT/LSTM para camada de codificação de texto . Ele leva a palavra Matriz de incorporação como entrada e mapeia os dados de texto em uma incorporação de comprimento fixo.
Camada de interação . Ele gera recursos profundos com base nas incorporações de texto. As opções incluem concatenação, similaridade de cosseno, etc.
Processamento de recursos amplos e profundos . Combinamos os recursos tradicionais com os recursos de interação (recursos profundos) de uma maneira ampla e profunda.
Camada MLP . A camada MLP é combinar recursos amplos e recursos profundos.
Todos os parâmetros são atualizados em conjunto para otimizar o objetivo de treinamento.
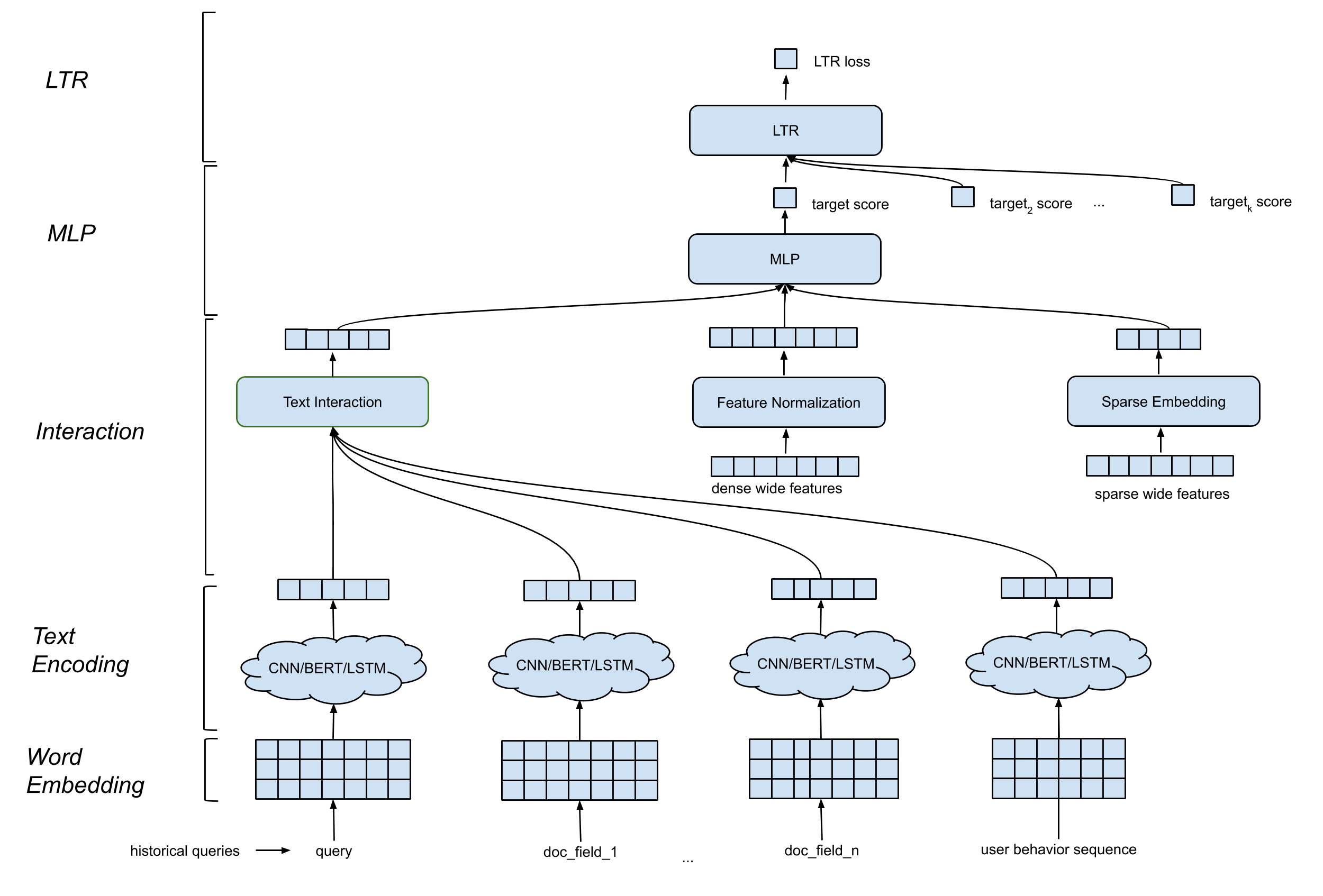
O Detext oferece grande flexibilidade para os clientes criarem redes personalizadas para seus próprios casos de uso:
Camada de LTR/Classificação : Implementação interna de perda de LTR ou perda de LTR de classificação TF, suporte de classificação de várias classes.
Camada MLP : número personalizável de camadas e número de dimensões.
Camada de interação : suporte a similaridade de cosseno, produto hadamard e concatenação.
Camada de incorporação de texto : Suporte CNN, BERT, LSTM com parâmetros personalizados em filtros, camadas, dimensões, etc.
Normalização contínua do recurso : redimensionamento no elemento, normalização do valor.
Processamento de recursos categóricos : modelado como incorporação de entidade.
Tudo isso pode ser personalizado por meio de hiper-parâmetros no modelo Detext. Observe que o ranking de TF é suportado na estrutura do Detext, ou seja, os usuários podem escolher a perda e as métricas LTR definidas no detettx.
VENV_DIR = < your venv dir >
python3 -m venv $VENV_DIR # Make sure your python version >= 3.7
source $VENV_DIR /bin/activate # Enter the virtual environmentpip3 install -U pip
pip3 install -U setuptoolspip install . -epytest Se você quiser uma simples tentativa da biblioteca, pode consultar os seguintes cadernos para o tutorial
text_classification_demo.ipynb
Este notebook mostra como usar o Detext para treinar um modelo de classificação de texto de várias classes em um conjunto de dados de classificação de intenção de consulta pública. Instruções detalhadas sobre preparação de dados, treinamento de modelos, inferência do modelo estão incluídas.
AutoCompletion.ipynb
Este notebook mostra como usar o Detext para treinar um modelo de classificação de texto em um conjunto de dados de conclusão automática de consulta pública. Etapas detalhadas na preparação de dados, treinamento de modelos, exemplos de inferência de modelos estão incluídos.
Cite o Detext em suas publicações se ajudar sua pesquisa:
@manual{guo-liu20,
author = {Weiwei Guo and
Xiaowei Liu and
Sida Wang and
Huiji Gao and
Bo Long},
title = {DeText: A Deep NLP Framework for Intelligent Text Understanding},
url = {https://engineering.linkedin.com/blog/2020/open-sourcing-detext},
year = {2020}
}
@inproceedings{guo-gao19,
author = {Weiwei Guo and
Huiji Gao and
Jun Shi and
Bo Long},
title = {Deep Natural Language Processing for Search Systems},
booktitle = {ACM SIGIR 2019},
year = {2019}
}
@inproceedings{guo-gao19,
author = {Weiwei Guo and
Huiji Gao and
Jun Shi and
Bo Long and
Liang Zhang and
Bee-Chung Chen and
Deepak Agarwal},
title = {Deep Natural Language Processing for Search and Recommender Systems},
booktitle = {ACM SIGKDD 2019},
year = {2019}
}
@inproceedings{guo-liu20,
author = {Weiwei Guo and
Xiaowei Liu and
Sida Wang and
Huiji Gao and
Ananth Sankar and
Zimeng Yang and
Qi Guo and
Liang Zhang and
Bo Long and
Bee-Chung Chen and
Deepak Agarwal},
title = {DeText: A Deep Text Ranking Framework with BERT},
booktitle = {ACM CIKM 2020},
year = {2020}
}
@inproceedings{jia-long20,
author = {Jun Jia and
Bo Long and
Huiji Gao and
Weiwei Guo and
Jun Shi and
Xiaowei Liu and
Mingzhou Zhou and
Zhoutong Fu and
Sida Wang and
Sandeep Kumar Jha},
title = {Deep Learning for Search and Recommender Systems in Practice},
booktitle = {ACM SIGKDD 2020},
year = {2020}
}
@inproceedings{wang-guo20,
author = {Sida Wang and
Weiwei Guo and
Huiji Gao and
Bo Long},
title = {Efficient Neural Query Auto Completion},
booktitle = {ACM CIKM 2020},
year = {2020}
}
@inproceedings{liu-guo20,
author = {Xiaowei Liu and
Weiwei Guo and
Huiji Gao and
Bo Long},
title = {Deep Search Query Intent Understanding},
booktitle = {arXiv:2008.06759},
year = {2020}
}


