detext
v2.0.8 Release Note
Detext est un cadre de compréhension du texte EP pour les tâches de classement, de classification et de génération de langues liées aux NLP. Il exploite la correspondance sémantique à l'aide de réseaux de neurones profonds pour comprendre les intentions des membres dans les systèmes de recherche et de recommandation.
En tant que cadre Général NLP, le DETEXT peut être appliqué à de nombreuses tâches, notamment le classement de la recherche et des recommandations, des tâches de classification multi-classes et de compréhension des requêtes.
Plus de détails peuvent être trouvés dans le blog de LinkedIn Engineering.
Detext prend en charge une architecture de modèle générale qui contient des composants suivants:
Mot d'intégration de couche . Il convertit la séquence des mots en MA par n matrice.
CNN / Bert / LSTM pour la couche de codage de texte . Il entre dans le mot incorporation de la matrice comme entrée et mappe les données de texte dans une longueur fixe incorpore.
Couche d'interaction . Il génère des fonctionnalités profondes basées sur les intérêts du texte. Les options incluent la concaténation, la similitude des cosinus, etc.
Traitement des fonctionnalités larges et profondes . Nous combinons les fonctionnalités traditionnelles avec les caractéristiques d'interaction (caractéristiques profondes) de manière large et profonde.
Couche MLP . La couche MLP consiste à combiner des caractéristiques larges et des caractéristiques profondes.
Tous les paramètres sont mis à jour conjointement pour optimiser l'objectif de formation.
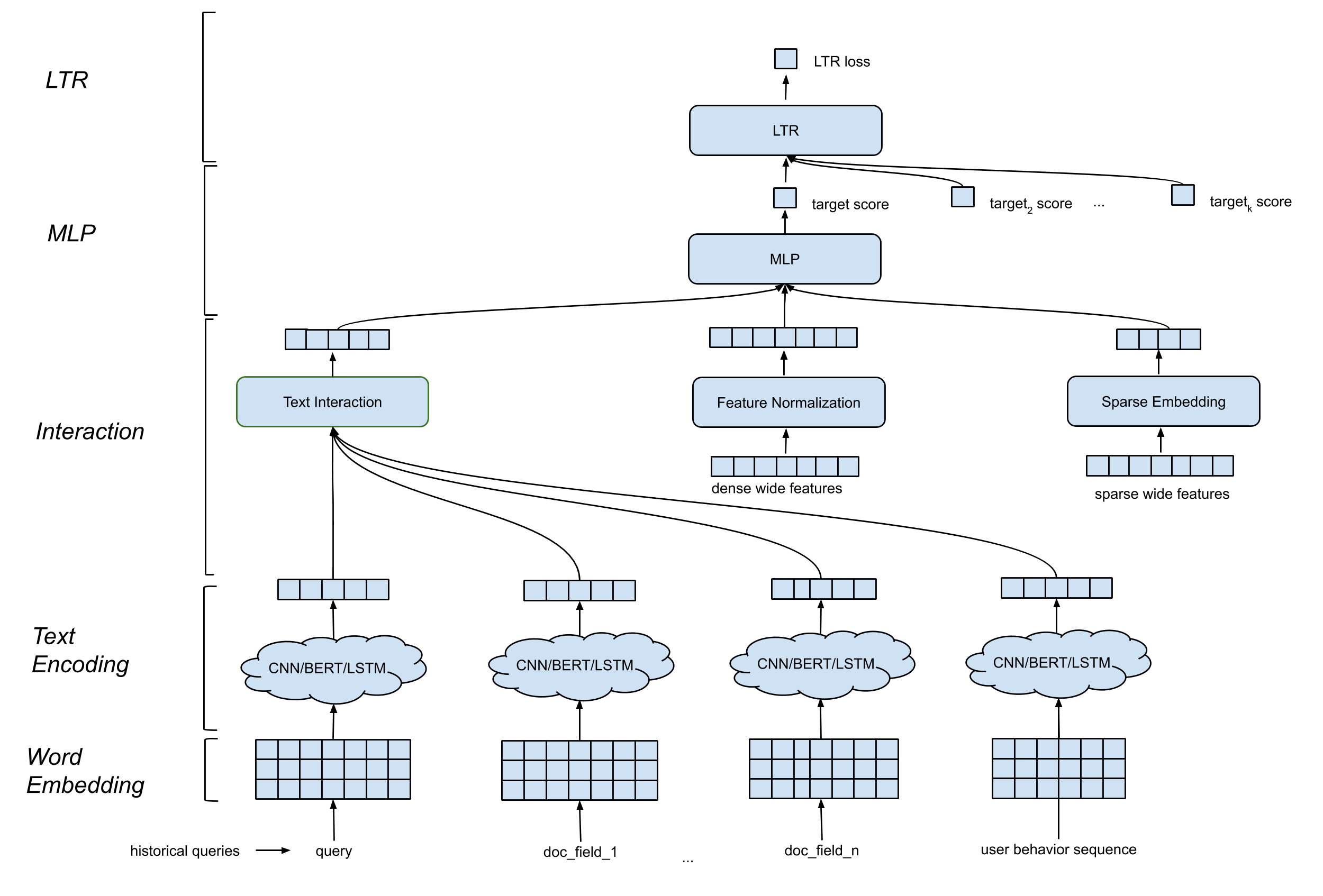
Detext offre une grande flexibilité aux clients de créer des réseaux personnalisés pour leurs propres cas d'utilisation:
Couche LTR / Classification : implémentation interne LTR LTR ou perte LTR RANKing TF, support de classification multi-classes.
Couche MLP : nombre personnalisable de couches et nombre de dimensions.
Couche d'interaction : soutenir la similitude du cosinus, le produit Hadamard et la concaténation.
Couche d'intégration de texte : Prise en charge CNN, Bert, LSTM avec paramètres personnalisés sur les filtres, les couches, les dimensions, etc.
Normalisation des caractéristiques continues : rediffusion sur les éléments, normalisation de la valeur.
Traitement des fonctionnalités catégorielles : modélisé en tant qu'entité intégrée.
Tous ces éléments peuvent être personnalisés via des hyper-paramètres dans le modèle detext. Notez que le rantin TF est pris en charge dans le cadre detext, c'est-à-dire que les utilisateurs peuvent choisir la perte et les métriques LTR définies dans le DETEXT.
VENV_DIR = < your venv dir >
python3 -m venv $VENV_DIR # Make sure your python version >= 3.7
source $VENV_DIR /bin/activate # Enter the virtual environmentpip3 install -U pip
pip3 install -U setuptoolspip install . -epytest Si vous souhaitez un simple essai de la bibliothèque, vous pouvez vous référer aux cahiers suivants pour le tutoriel
text_classification_demo.ipynb
Ce carnet montre comment utiliser DESText pour former un modèle de classification de texte multi-classes sur un ensemble de données de classification d'intention de requête publique. Des instructions détaillées sur la préparation des données, la formation du modèle, l'inférence du modèle sont incluses.
AutoC-completion.ipynb
Ce carnet montre comment utiliser DESText pour former un modèle de classement de texte sur un ensemble de données d'achèvement de la requête publique. Des étapes détaillées sur la préparation des données, la formation du modèle, les exemples d'inférence du modèle sont inclus.
Veuillez citer Detext dans vos publications si cela aide vos recherches:
@manual{guo-liu20,
author = {Weiwei Guo and
Xiaowei Liu and
Sida Wang and
Huiji Gao and
Bo Long},
title = {DeText: A Deep NLP Framework for Intelligent Text Understanding},
url = {https://engineering.linkedin.com/blog/2020/open-sourcing-detext},
year = {2020}
}
@inproceedings{guo-gao19,
author = {Weiwei Guo and
Huiji Gao and
Jun Shi and
Bo Long},
title = {Deep Natural Language Processing for Search Systems},
booktitle = {ACM SIGIR 2019},
year = {2019}
}
@inproceedings{guo-gao19,
author = {Weiwei Guo and
Huiji Gao and
Jun Shi and
Bo Long and
Liang Zhang and
Bee-Chung Chen and
Deepak Agarwal},
title = {Deep Natural Language Processing for Search and Recommender Systems},
booktitle = {ACM SIGKDD 2019},
year = {2019}
}
@inproceedings{guo-liu20,
author = {Weiwei Guo and
Xiaowei Liu and
Sida Wang and
Huiji Gao and
Ananth Sankar and
Zimeng Yang and
Qi Guo and
Liang Zhang and
Bo Long and
Bee-Chung Chen and
Deepak Agarwal},
title = {DeText: A Deep Text Ranking Framework with BERT},
booktitle = {ACM CIKM 2020},
year = {2020}
}
@inproceedings{jia-long20,
author = {Jun Jia and
Bo Long and
Huiji Gao and
Weiwei Guo and
Jun Shi and
Xiaowei Liu and
Mingzhou Zhou and
Zhoutong Fu and
Sida Wang and
Sandeep Kumar Jha},
title = {Deep Learning for Search and Recommender Systems in Practice},
booktitle = {ACM SIGKDD 2020},
year = {2020}
}
@inproceedings{wang-guo20,
author = {Sida Wang and
Weiwei Guo and
Huiji Gao and
Bo Long},
title = {Efficient Neural Query Auto Completion},
booktitle = {ACM CIKM 2020},
year = {2020}
}
@inproceedings{liu-guo20,
author = {Xiaowei Liu and
Weiwei Guo and
Huiji Gao and
Bo Long},
title = {Deep Search Query Intent Understanding},
booktitle = {arXiv:2008.06759},
year = {2020}
}


