detext
v2.0.8 Release Note
Detext es un marco de comprensión de texto de EP para tareas de clasificación, clasificación y generación de idiomas relacionadas con PNL. Aprovecha la coincidencia semántica utilizando redes neuronales profundas para comprender los intentos de los miembros en los sistemas de búsqueda y recomendación.
Como marco general de PNL, el desext se puede aplicar a muchas tareas, incluida la clasificación de búsqueda y recomendación, clasificación de múltiples clases y tareas de comprensión de consultas.
Se pueden encontrar más detalles en la publicación del blog de Ingeniería de LinkedIn.
Detext admite una arquitectura de modelo general que contiene los siguientes componentes:
Plaza de incrustación de palabras . Convierte la secuencia de palabras en AD por N Matrix.
CNN/BERT/LSTM para la capa de codificación de texto . Se necesita en la matriz de incrustación de la palabra como entrada, y mapea los datos de texto en una incrustación de longitud fija.
Capa de interacción . Genera características profundas basadas en los incrustaciones de texto. Las opciones incluyen concatenación, similitud de coseno, etc.
Procesamiento de características amplias y profundas . Combinamos las características tradicionales con las características de interacción (características profundas) de manera amplia y profunda.
Capa MLP . La capa MLP es combinar características amplias y características profundas.
Todos los parámetros se actualizan conjuntamente para optimizar el objetivo de entrenamiento.
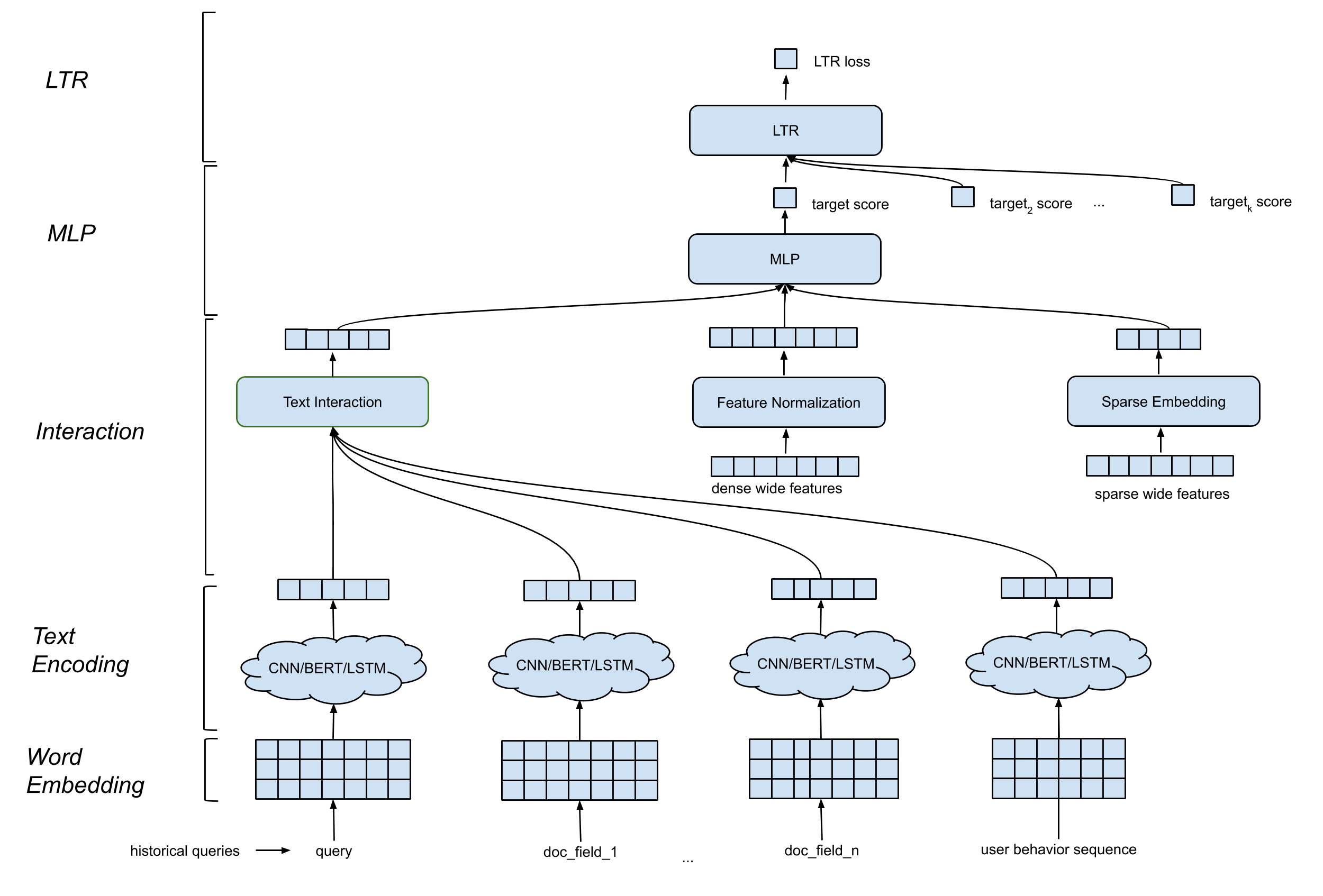
Detext ofrece una gran flexibilidad para que los clientes creen redes personalizadas para sus propios casos de uso:
Capa de LTR/Clasificación : implementación de pérdida de LTR interna o pérdida de LTR de rango de TF, soporte de clasificación de múltiples clases.
Capa MLP : número personalizable de capas y número de dimensiones.
Capa de interacción : soporte de similitud de coseno, producto Hadamard y concatenación.
Capa de incrustación de texto : soporte CNN, Bert, LSTM con parámetros personalizados en filtros, capas, dimensiones, etc.
Normalización de características continuas : reescalado de elementos, normalización del valor.
Procesamiento de características categóricas : modelado como incrustación de entidad.
Todo esto se puede personalizar a través de hiperparámetros en la plantilla de DETEXT. Tenga en cuenta que el rango de TF se admite en el marco Detext, es decir, los usuarios pueden elegir la pérdida y las métricas de LTR definidas en Detext.
VENV_DIR = < your venv dir >
python3 -m venv $VENV_DIR # Make sure your python version >= 3.7
source $VENV_DIR /bin/activate # Enter the virtual environmentpip3 install -U pip
pip3 install -U setuptoolspip install . -epytest Si desea una prueba simple de la biblioteca, puede consultar los siguientes cuadernos para el tutorial
text_classification_demo.ipynb
Este cuaderno muestra cómo usar DETEXT para entrenar un modelo de clasificación de texto de múltiples clases en un conjunto de datos de clasificación de intención de consulta pública. Se incluyen instrucciones detalladas sobre la preparación de datos, la capacitación del modelo, la inferencia del modelo.
autocompletión.ipynb
Este cuaderno muestra cómo usar DETEXT para entrenar un modelo de clasificación de texto en un conjunto de datos de finalización automática de consultas públicas. Se incluyen pasos detallados sobre la preparación de datos, la capacitación del modelo, los ejemplos de inferencia del modelo.
Por favor, cite detexto en sus publicaciones si ayuda a su investigación:
@manual{guo-liu20,
author = {Weiwei Guo and
Xiaowei Liu and
Sida Wang and
Huiji Gao and
Bo Long},
title = {DeText: A Deep NLP Framework for Intelligent Text Understanding},
url = {https://engineering.linkedin.com/blog/2020/open-sourcing-detext},
year = {2020}
}
@inproceedings{guo-gao19,
author = {Weiwei Guo and
Huiji Gao and
Jun Shi and
Bo Long},
title = {Deep Natural Language Processing for Search Systems},
booktitle = {ACM SIGIR 2019},
year = {2019}
}
@inproceedings{guo-gao19,
author = {Weiwei Guo and
Huiji Gao and
Jun Shi and
Bo Long and
Liang Zhang and
Bee-Chung Chen and
Deepak Agarwal},
title = {Deep Natural Language Processing for Search and Recommender Systems},
booktitle = {ACM SIGKDD 2019},
year = {2019}
}
@inproceedings{guo-liu20,
author = {Weiwei Guo and
Xiaowei Liu and
Sida Wang and
Huiji Gao and
Ananth Sankar and
Zimeng Yang and
Qi Guo and
Liang Zhang and
Bo Long and
Bee-Chung Chen and
Deepak Agarwal},
title = {DeText: A Deep Text Ranking Framework with BERT},
booktitle = {ACM CIKM 2020},
year = {2020}
}
@inproceedings{jia-long20,
author = {Jun Jia and
Bo Long and
Huiji Gao and
Weiwei Guo and
Jun Shi and
Xiaowei Liu and
Mingzhou Zhou and
Zhoutong Fu and
Sida Wang and
Sandeep Kumar Jha},
title = {Deep Learning for Search and Recommender Systems in Practice},
booktitle = {ACM SIGKDD 2020},
year = {2020}
}
@inproceedings{wang-guo20,
author = {Sida Wang and
Weiwei Guo and
Huiji Gao and
Bo Long},
title = {Efficient Neural Query Auto Completion},
booktitle = {ACM CIKM 2020},
year = {2020}
}
@inproceedings{liu-guo20,
author = {Xiaowei Liu and
Weiwei Guo and
Huiji Gao and
Bo Long},
title = {Deep Search Query Intent Understanding},
booktitle = {arXiv:2008.06759},
year = {2020}
}


