Deece
1.0.0

A Deece Search é um mecanismo de pesquisa aberto, colaborativo e descentralizado para IPFs. Qualquer nó executando o cliente é capaz de rastejar o conteúdo no IPFS e adicioná -lo ao índice, que por si só é armazenado de maneira descentralizada no IPFS. Isso permite pesquisas descentralizadas em conteúdo descentralizado.
A implementação atual ainda é altamente experimental. Estamos trabalhando nas versões futuras sem gateway central e estamos explorando mecanismos alternativos de pesquisa. Nosso servidor atual está inativo e o projeto não foi mantido.
ClientGatewayLibraryA pesquisa DEECE permite pesquisas descentralizadas nos dados do IPFS. Isso é conseguido por uma rede de nós IPFS que participam da rastreamento e indexação dos dados na rede. O índice é armazenado no IPFS e dividido em uma hierarquia de duas camadas, sendo o primeiro o índice de nível superior (TLI) e o segundo é o índice específico da palavra-chave (KSI). O TLI contém os identificadores (CID) para o KSI para cada palavra -chave e é constantemente atualizado quando um nó envia um rastreamento. Ao rastejar, os nós adicionam ao KSI atual uma lista dos identificadores de arquivos que contêm essa palavra -chave.
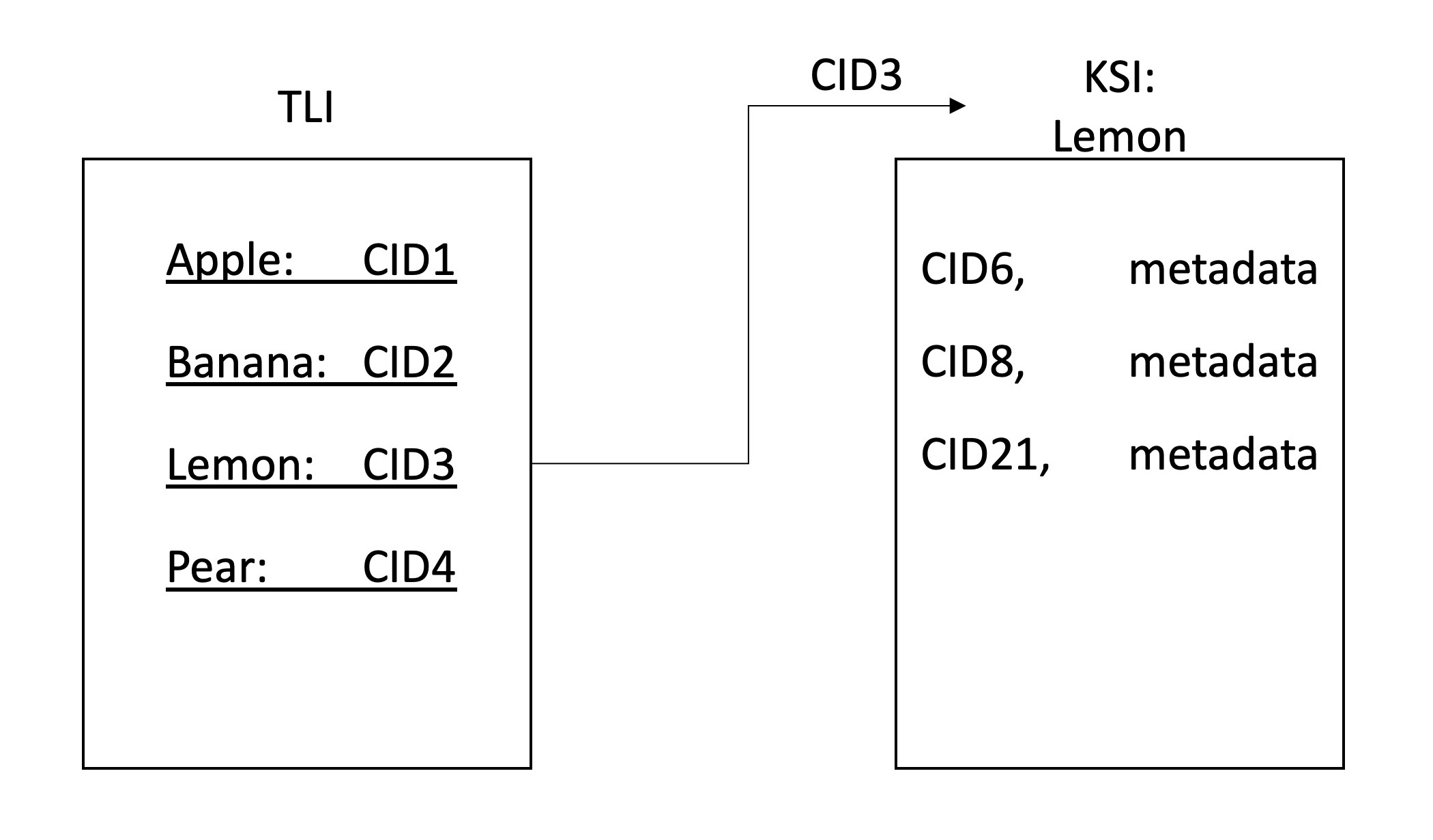
A pesquisa Deece permite duas ações específicas: search e crawl . As consultas de pesquisa o TLI mais recente para encontrar o KSI para cada palavra -chave na consulta do usuário e, em seguida, busca os resultados deles, que são exibidos para o usuário. Atualmente, a classificação dos resultados é ordenada com base no CID, mas mecanismos mais sofisticados devem ser desenvolvidos. Permitimos resultados combinados para até duas palavras -chave, que serão estendidas no futuro.
Atualmente, existem três maneiras de acessar a pesquisa Deece. Primeiro, existe o software cliente que usa uma interface de linha de comando. Segundo, implementamos um serviço de gateway (www.deece.nl/web/), que executa uma instância do nó do cliente e permite que "clientes leves" interajam com a pesquisa sem instalar outro software. Finalmente, lançamos nosso código usado pela CLI e Gateway na forma de uma biblioteca GO.
A versão inicial da Deece Search baseia -se em um nó confiável (o mesmo nó do nosso gateway) para atualizar o registro IPNS apontando para a versão mais recente do TLI. Quando os clientes rastejam, a etapa final envolve eles enviando uma solicitação de atualização para este servidor. No momento, os clientes precisarão especificar uma senha em seu arquivo de configuração, que pode ser obtido dos mantenedores, pois as medidas de segurança serão implementadas posteriormente.
Atualmente, os usuários da Web têm poucas alternativas aos mecanismos de pesquisa centralizados . Esses motores mantêm controle, política e confiança centralizados, o que pode levar a questões de censura, proteção à privacidade e transparência.
Além disso, esses motores geralmente concentram seus esforços no conteúdo da Web tradicional (hospedado em servidores da Web, acessados através do DNS). No entanto, em um paradigma do Web3, onde se espera que o conteúdo seja armazenado em redes de armazenamento descentralizadas (por exemplo, IPFs) e resolução de nomes para ocorrer através de soluções de blockchain (por exemplo, ENS), é necessário um mecanismo de pesquisa alternativo.
Em suma, é necessário um mecanismo de pesquisa que pesquise dados descentralizados e o faça de maneira descentralizada.
Existem vários projetos comparáveis, que tentaram resolver o problema da centralização na pesquisa na web. Primeiro de tudo, existem implementações e propostas de pesquisas para mecanismos de pesquisa distribuídos / descentralizados para os dados da Web atuais. Os primeiros projetos incluem Yacy, Faroo e busca. Mais recentemente, a Presearch tem como objetivo criar um mecanismo de pesquisa colaborativo usando recompensas de blockchain para incentivos.
Da mesma forma, vários trabalhos destinam -se a fornecer pesquisas distribuídas por redes de armazenamento P2P. Mais recentemente, o gráfico criou um protocolo de indexação descentralizado para dados de blockchain usando incentivos de criptomoeda.
No entanto, nenhum dos projetos acima captura inteiramente nosso caso de uso específico de pesquisa descentralizada por dados descentralizados do Web3.
Nossa arquitetura depende de vários nós do cliente, que mantêm e adicionam coletivamente ao índice e são capazes de executar pesquisas. Aproveitamos primeiro a abordagem de terminar um protipo de funcionamento da nossa arquitetura e adicionar recursos de forma incremental. Portanto, nossa versão atual depende de um nó confiável (Gateway) para atualizar o registro do TLI IPNS. Como não há segurança adicional ou incentivação implementada, usamos uma senha simples para permitir que novos nós do cliente adicionassem ao índice. Embora a segurança possa ser insuficiente no futuro, assumimos um modelo altruísta para o nosso lançamento em estágio inicial.
No futuro, imaginamos haver segurança e incentivos adicionais, o que alinha os nós para ser honesto ao atualizar o índice. Estes podem estar na forma de recompensas de criptocurrenia, cortes, reputação etc. Uma maneira de financiar recompensas para nós honestos pode ser incorporando o anúncio no protocolo e permitir que as taxas de anúncio sejam delegadas aos nós que mantêm a rede.
Nossa versão atual suporta apenas arquivos PDF no IPFS a serem adicionados ao índice. No futuro, gostaríamos de expandir isso para mais tipos e diretórios de arquivos e suportar diferentes redes de armazenamento descentralizado. Por fim, pretendemos incorporar dados baseados em blockchain, como contratos inteligentes na pesquisa.
Agora apresentamos uma visão geral das duas operações principais em nosso mecanismo.
A pesquisa começa com uma consulta pelo cliente que contém vários termos de pesquisa. O cliente busca o TLI mais recente, resolvendo o nome do IPNS definido pelo gateway para o CID correspondente. Este TLI é então buscado e atravessado para verificar se as palavras -chave têm KSI. Se for esse o caso, os KSIs relevantes são consultas, para retornar o conteúdo que contém as palavras -chave. O cliente pode recuperar esses arquivos da rede.
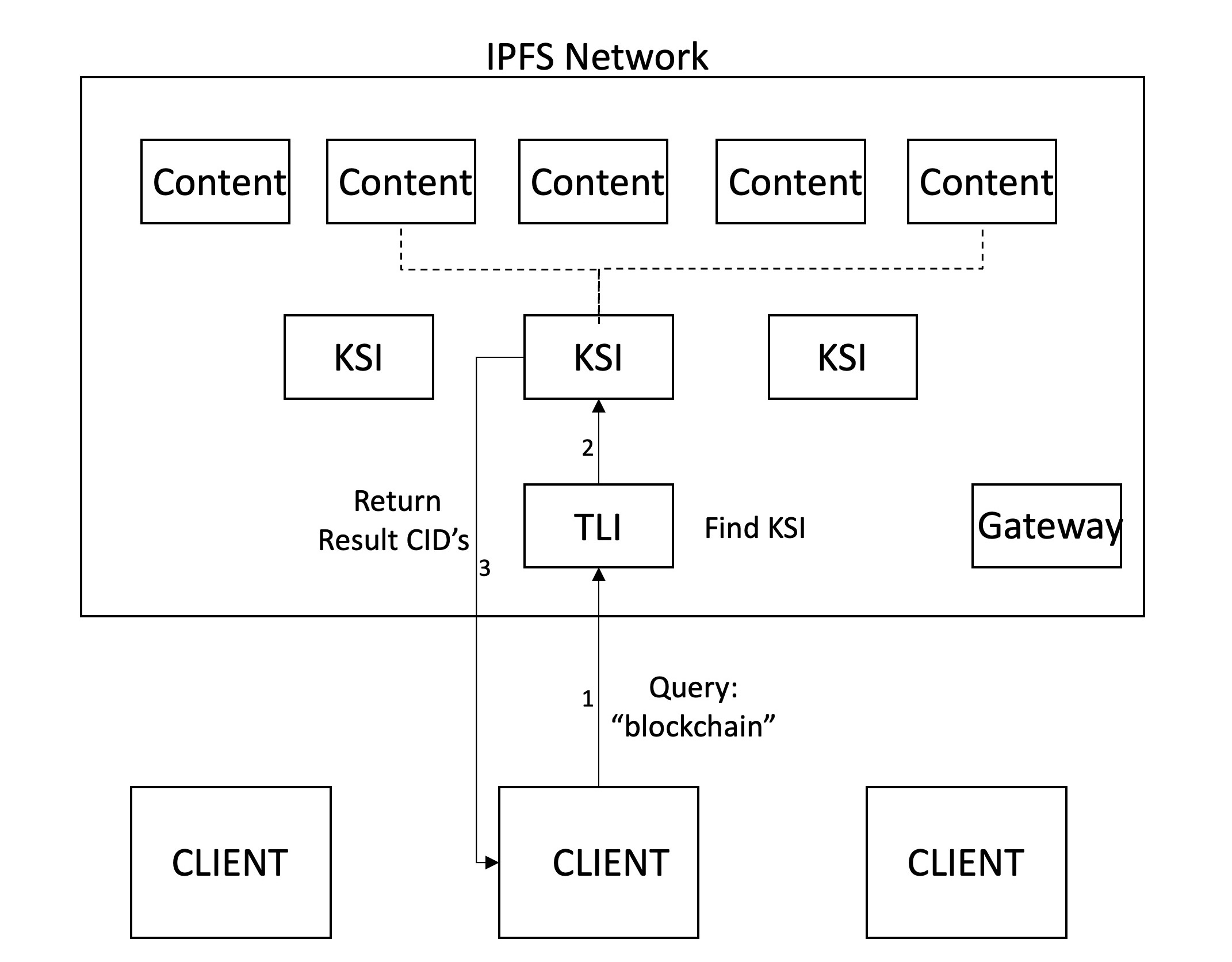
Um aspecto importante nos mecanismos de pesquisa é o mecanismo de classificação. Isso geralmente acontece de maneira centralizada, sem muita influência dos clientes. Embora não tenhamos implementado mecanismos sofisticados de classificação, imaginamos que estivemos ranking nos clientes dos resultados, o que lhes dá maior poder e transparência. Isso permite que os clientes estejam no controle das funções de classificação e personalizem -as com base em necessidades específicas. Atualmente, nosso mecanismo devoluções ordenou resultados com base nos CIDs. Quando dois termos de pesquisa são inseridos, as páginas em que ambas ocorrem são retornadas primeiro, após as quais as páginas são retornadas, que contêm apenas um dos termos.
Um aspecto importante de qualquer mecanismo de pesquisa é a adição de entradas ao índice. Esse processo envolve uma série de etapas, que descrevemos abaixo.
A primeira decisão a ser tomada é qual conteúdo será adicionado ao índice, que chamamos de curadoria . Nos motores tradicionais, isso inclui todo o conteúdo público da Web. Embora isso alcance o alto desempenho, pode adicionar muita sobrecarga quando executado em uma rede descentralizada. Outra abordagem pode ser uma curadoria com base no consenso da rede de conteúdo importante. Para o nosso sistema atual, permitimos que qualquer pessoa que acredite que o conteúdo seja importante para adicionar isso à rede. O conteúdo pode ser abordado por identificadores CID, DNSLINK, ENS ou IPNS.
Em seguida, acontece o rastreamento, o que envolve buscar e analisar arquivos para extrair palavras -chave importantes. Como mencionado acima, nosso sistema rasteja quando alguém decide que o conteúdo deve ser adicionado e, portanto, envia manualmente o CID para ser rastreado. No futuro, imaginamos que isso aconteça automaticamente quando o conteúdo é carregado ou visitado na rede. Além de extrair palavras -chave, outros metadados podem ser adicionados. Atualmente, usamos o tipo de arquivo (PDF) e o registro de data e hora quando rastejados, mas na intenção futura de adicionar título, contagem, tamanho etc.
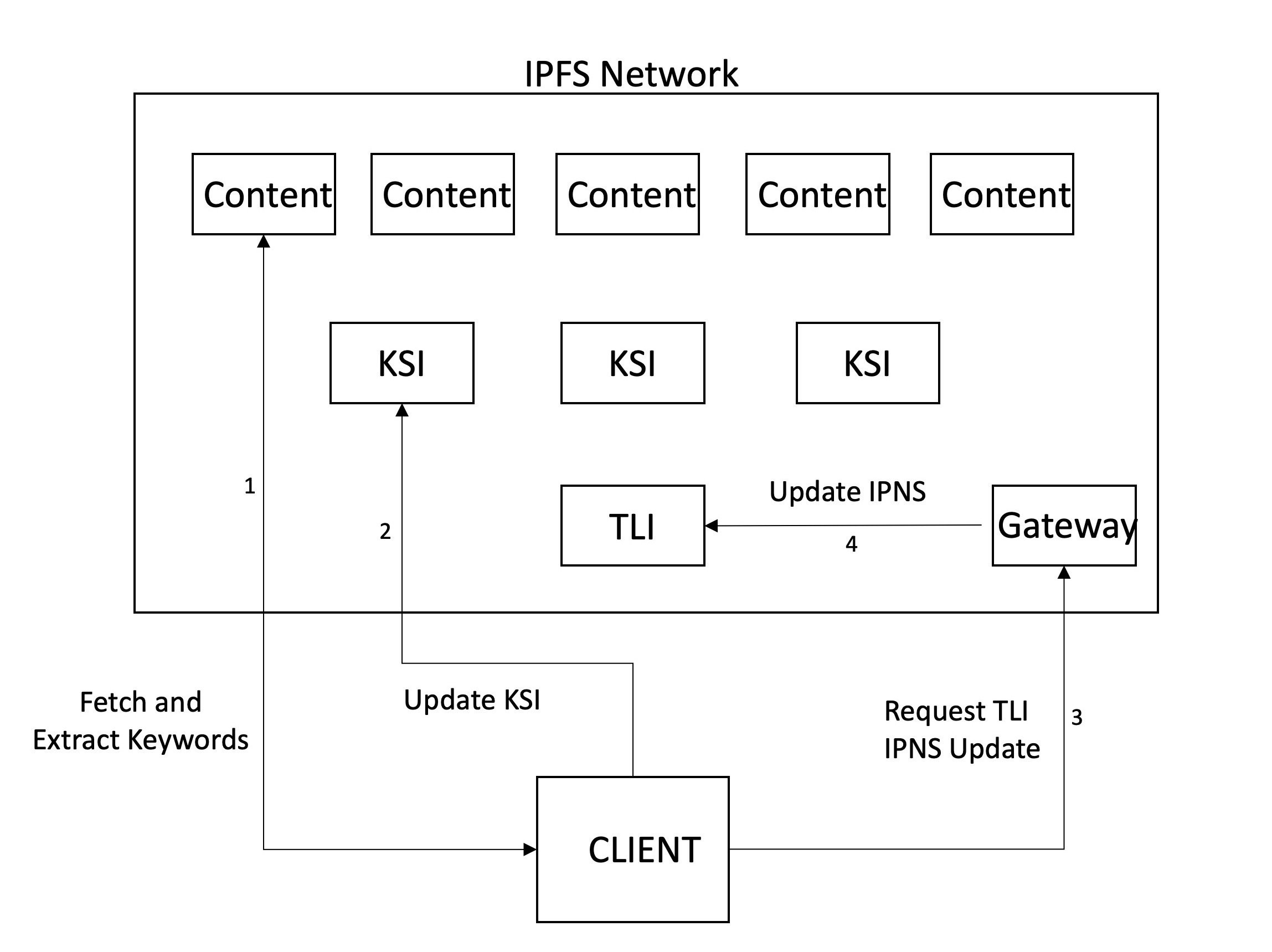
Depois de extrair as palavras -chave (e produzir o RWI), o índice precisa ser armazenado. Para armazenamento, usamos IPFs, pois isso permite o armazenamento colaborativo descentralizado. Decidimos manter uma hierarquia de dois níveis. Cada palavra -chave terá um arquivo de índice associado (KSI), onde os nós podem encontrar qual conteúdo contém essas palavras -chave. Um índice separado é mantido (TLI) para apontar para os identificadores do KSI, e isso é publicado em um nome de IPNS no nosso servidor Gateway. Quando um nó atualiza os KSI depois de rastejar um arquivo, eles atualizam o ponteiro no TLI para esses arquivos e solicita o gateway para atualizar o ponteiro que o registro do IPNS resolve. Dessa forma, o registro do IPNS aponta para a versão mais recente do TLI, que, por sua vez, aponta para as versões mais recentes do KSI.
Atualmente, os nós do cliente podem alterar o TLI se eles possuem uma senha, que pode ser obtida dos mantenedores deste projeto. Dessa forma, possíveis entradas maliciosas são menos propensas. Os nós com as senhas podem ser vistos como 'autoridades' na rede.
Durante o desenvolvimento e teste, fizemos várias observações com relação ao desempenho. Como nossa solução depende muito de IPFs, o mesmo acontece com o nosso desempenho. Descobrimos que atrasos significativos podem ocorrer quando os nós não adicionaram o par de gateway em seu enxame de colegas. Embora tenhamos adicionado isso à nossa CLI, a conexão ainda cai ocasionalmente. Embora isso não quebre o sistema, ele adiciona atrasos.
Além disso, a atualização de nossa entrada de IPNs no gateway pode ser muito lenta e pode se tornar um gargalo de desempenho quando o tráfego de rastreamento aumenta. Começamos a investigar alternativas, mas deixamos a implementação para lançamentos futuros. Uma opção é usar o DNS para armazenar um ponteiro para o mais recente registro do TLI, mas isso traz vários desafios adicionais inerentes ao DNS. Um registro de nomes baseado em blockchain, como o ENS, também pode ser usado, embora atualizações frequentes do contrato de resolver possam se tornar uma grande despesa.
Existem várias maneiras de acessar a Pesquisa Deece:
ClientO software cliente pode ser usado por qualquer nó que execute o IPFS e fornece uma interface simples da linha de comando.
NAME:
Deece - Decentralised search for IPFS
USAGE:
Deece [global options] command [command options] [arguments...]
VERSION:
0.0.1
AUTHORS:
Navin V. Keizer < [email protected] >
Puneet K. Bindlish < [email protected] >
COMMANDS:
search Performs a decentralised search on IPFS
crawl Crawls a page to add to the decentralised index
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--help, -h show help (default: false)
--version, -v print the version (default: false)
GatewayPara acesso fácil e leve, implementamos um gateway para nossos clientes de pesquisa. Isso pode ser encontrado em: www.deece.nl/web/ e permite pesquisas e rastreamentos na rede com base nos identificadores (CIDs).

NOTA: O gateway está atualmente suposto ao atualizar para a versão 2.
LibraryTanto a CLI quanto o Gateway são executados usando nosso pacote de pesquisa Deece para Go. Lançamos isso, pois isso pode ser usado para facilitar integrações e extensões.
Mais instruções de instalação serão adicionadas depois de testadas em diferentes plataformas. Por enquanto, fornecemos instruções com base em nossa instalação no Linux.
Para que a pesquisa Deece funcione, existem vários requisitos e dependências. Para executar como cliente, um daemon local do IPFS precisa estar em execução e, para acelerar os resultados, ajuda a adicionar o gateway que mantém o TLI no enxame de pares. Para enviar alterações ao TLI como cliente, é necessária uma senha. Finalmente, um arquivo de configuração precisa estar presente no mesmo diretório que o executável para carregar resultados. Um arquivo de configuração incompleto pode ser encontrado neste repositório.
Para executar o cliente, o primeiro IPFS, GO (testado para a versão 1.13.7, as versões mais recentes devem funcionar com pequenas modificações), e o Git deve ser instalado.
Em seguida, precisamos instalar da fonte:
git clone github.com/navinkeizer/DeeceEm seguida, o TESSERACT-OCR precisa ser instalado, bem como outras dependências. Para Linux, isso pode ser assim:
sudo apt-get install g++
sudo apt-get install autoconf automake libtool
sudo apt-get install autoconf-archive
sudo apt-get install pkg-config
sudo apt-get install libpng-dev
sudo apt-get install libjpeg8-dev
sudo apt-get install libtiff5-dev
sudo apt-get install zlib1g-dev
wget http://www.leptonica.org/source/leptonica-1.81.1.tar.gz
sudo tar xf leptonica-1.81.1.tar.gz
cd leptonica-1.81.1 &&
sudo ./configure &&
sudo apt install make
sudo make &&
sudo make install
sudo apt-get install tesseract-ocr # or sudo apt install tesseract-ocr
sudo apt install libtesseract-devOutros pacotes GO relevantes podem ser instalados:
$ go get -t github.com/otiai10/gosseract
$ go get github.com/navinkeizer/Deece
$ go get github.com/ipfs/go-ipfs-api
$ go get github.com/wealdtech/go-ens/v3
$ go get github.com/otiai10/gosseract/v2
E a CLI construiu:
$ sudo go build Deece/CLI/.
e correr:
$ ./CLI [command] [arguments]
O pacote também pode ser usado como uma biblioteca.
go get github.com/navinkeizer/Deece
A implementação atual da pesquisa Deece ainda é experimental e, portanto, pode experimentar instabilidades. Conforme descrito neste documento, fizemos suposições simplificadoras (altruísmo) e focamos na funcionalidade limitada (somente PDF). Além disso, o gateway apresenta um aspecto centralizado, que no futuro deve ser substituído por consenso de rede descentralizado, e o protocolo deve ser garantido por incentivos.
Nossa implementação adota uma primeira abordagem de princípio. Nosso objetivo foi construir desde o início, em vez de confiar nas abordagens e soluções existentes para componentes do sistema. Acreditamos que isso é necessário, pois as soluções existentes podem não ser ideais para o conteúdo Web3 descentralizado. Em outras palavras, há muito trabalho a ser feito.
Atualmente, ocasionalmente, experimentamos problemas no processo de rastreamento devido ao tempo de atualização do IPNS. Estamos trabalhando para resolver isso com soluções alternativas.


