Deece
1.0.0

Deece Search es un mecanismo de búsqueda abierto, colaborativo y descentralizado para IPF. Cualquier nodo que ejecute el cliente puede rastrear contenido en IPFS y agregarlo al índice, que se almacena de manera descentralizada en IPFS. Esto permite la búsqueda descentralizada en contenido descentralizado.
La implementación actual sigue siendo muy experimental. Estamos trabajando en las versiones futuras sin Gateway Central y estamos explorando mecanismos de búsqueda alternativos. Nuestro servidor actual está inactivo y el proyecto no se ha mantenido.
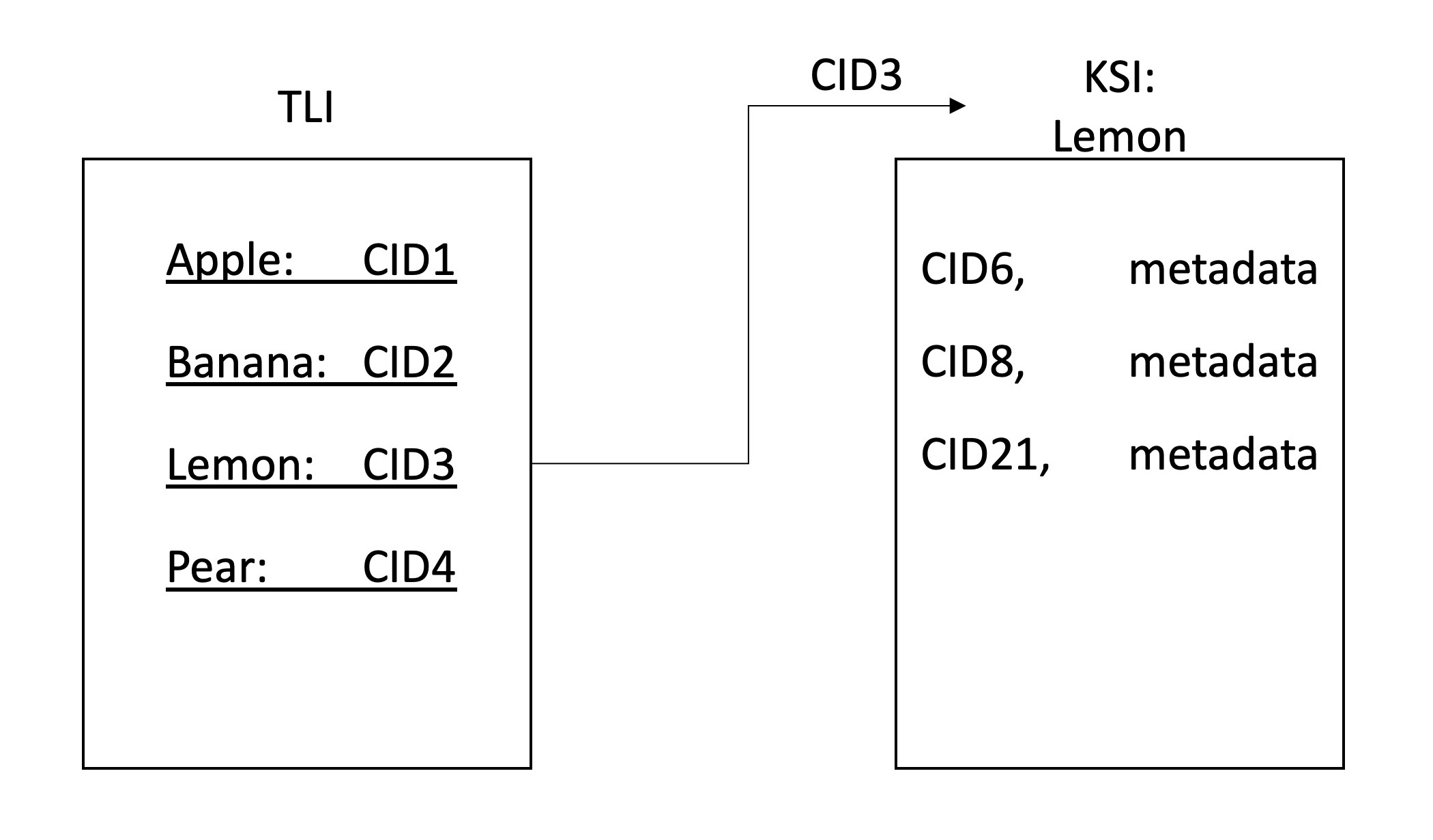
ClientGatewayLibraryLa búsqueda de DEECE permite la búsqueda descentralizada en los datos de IPFS. Esto se logra mediante una red de nodos IPFS que participan en el rastreo e indexación de los datos en la red. El índice se almacena en IPFS y se divide en una jerarquía de dos capas, el primero es el índice de nivel superior (TLI) y el segundo es el índices específicos de la palabra clave (KSI). El TLI contiene los identificadores (CID) para el KSI para cada palabra clave, y se actualiza constantemente cuando un nodo envía un rastreo. Cuando se arrastran, los nodos se suman al KSI actual una lista de los identificadores de archivos que contienen esa palabra clave.
La búsqueda de Deece permite dos acciones específicas: search y crawl . Busque consultas el último TLI para encontrar el KSI para cada palabra clave en la consulta del usuario, y luego obtiene los resultados de estos, que se muestran al usuario. Actualmente, la clasificación de resultados se ordena en función del CID, pero se deben desarrollar mecanismos más sofisticados. Permitimos resultados combinados para hasta dos palabras clave, que se extenderán en el futuro.
Actualmente hay tres formas de acceder a la búsqueda de Deece. Primero, está el software del cliente que utiliza una interfaz de línea de comandos. En segundo lugar, hemos implementado un servicio Gateway (www.deece.nl/web/), que ejecuta una instancia de nuestro nodo de cliente y permite que los "clientes de luz" interactúen con la búsqueda sin instalar otro software. Finalmente, hemos lanzado nuestro código utilizado por la CLI y la puerta de enlace en forma de una biblioteca GO.
La versión inicial de Deece Search se basa en un nodo confiable (el mismo nodo que nuestra puerta de enlace) para actualizar el registro de IPNS que apunta a la última versión del TLI. Cuando los clientes se arrastran, el paso final implica que envíen una solicitud de actualización a este servidor. En este momento, los clientes deberán especificar una contraseña en su archivo de configuración, que se puede obtener de los mantenedores, ya que las medidas de seguridad se implementarán más adelante.
Actualmente, los usuarios web tienen pocas alternativas a los motores de búsqueda centralizados . Estos motores mantienen el control centralizado, la política y la confianza, lo que puede conducir a problemas en la censura, la protección de la privacidad y la transparencia.
Además, estos motores generalmente centran sus esfuerzos en el contenido web tradicional (alojados en los servidores web, a los que se accede a través del DNS). Sin embargo, en un paradigma Web3, donde se espera que el contenido se almacene en redes de almacenamiento descentralizadas (por ejemplo, IPFS) y la resolución de nombres se realice a través de Blockchain Solutions (por ejemplo), se requiere un motor de búsqueda alternativo.
En resumen, se necesita un mecanismo de búsqueda que busque datos descentralizados, y lo hace de manera descentralizada.
Hay una serie de proyectos comparables, que han intentado resolver el problema de la centralización en la búsqueda web. En primer lugar, hay implementaciones y propuestas de la investigación para mecanismos de búsqueda distribuidos / descentralizados para los datos web actuales. Los primeros proyectos incluyen Yacy, Faroo y Buscan. Más recientemente, Presearch tiene como objetivo crear un motor de búsqueda de colaboración utilizando recompensas de blockchain para incentivos.
Del mismo modo, una serie de obras destinadas a proporcionar una búsqueda distribuida de redes de almacenamiento P2P. Más recientemente, el gráfico ha creado un protocolo de indexación descentralizado para datos de blockchain utilizando incentivos de criptomonedas.
Sin embargo, ninguno de los proyectos anteriores captura por completo nuestro caso de uso específico de la búsqueda descentralizada de datos Web3 descentralizados.
Nuestra arquitectura se basa en varios nodos de clientes, que colectivamente mantienen y se suman al índice, y pueden realizar búsquedas. Primero hemos adoptado el enfoque de terminar un protipo que funcione de nuestra arquitectura, y agregando características de forma incremental. Por lo tanto, nuestra versión actual se basa en un nodo confiable (puerta de enlace) para actualizar el registro TLI IPNS. Como no hay seguridad o incentivación adicional implementada, hemos utilizado una contraseña simple para permitir que los nodos de los clientes nuevos se agregen al índice. Si bien la seguridad puede ser insuficiente en el futuro, asumimos un modelo altruista para nuestro lanzamiento en la etapa inicial.
En el futuro, imaginamos que se agregará seguridad e incentivos en su lugar, lo que alinean los nodos para ser honestos al actualizar el índice. Estos pueden ser en forma de recompensas de criptocurrenia, corte, reputación, etc. Una forma de financiar recompensas a nodos honestos podría ser incorporando publicidad en el protocolo y permitir que las tarifas de publicidad se delegen a los nodos que mantienen la red.
Nuestra versión actual solo admite archivos PDF en IPFS que se agregarán al índice. En el futuro, nos gustaría ampliar esto a más tipos de archivos y directorios, y admitir diferentes redes de almacenamiento descentralizadas. Finalmente, nuestro objetivo es incorporar datos basados en blockchain, como contratos inteligentes en la búsqueda.
Ahora presentamos una descripción general de las dos operaciones principales en nuestro mecanismo.
La búsqueda comienza con una consulta del cliente que contiene varios términos de búsqueda. Luego, el cliente obtiene el último TLI resolviendo el nombre de IPNS establecido por la puerta de enlace al CID correspondiente. Este TLI se obtiene y se atraviesa para verificar si las palabras clave tienen KSI. Si este es el caso, los KSI relevantes son consultas para devolver el contenido que contiene las palabras clave. El cliente puede recuperar estos archivos de la red.
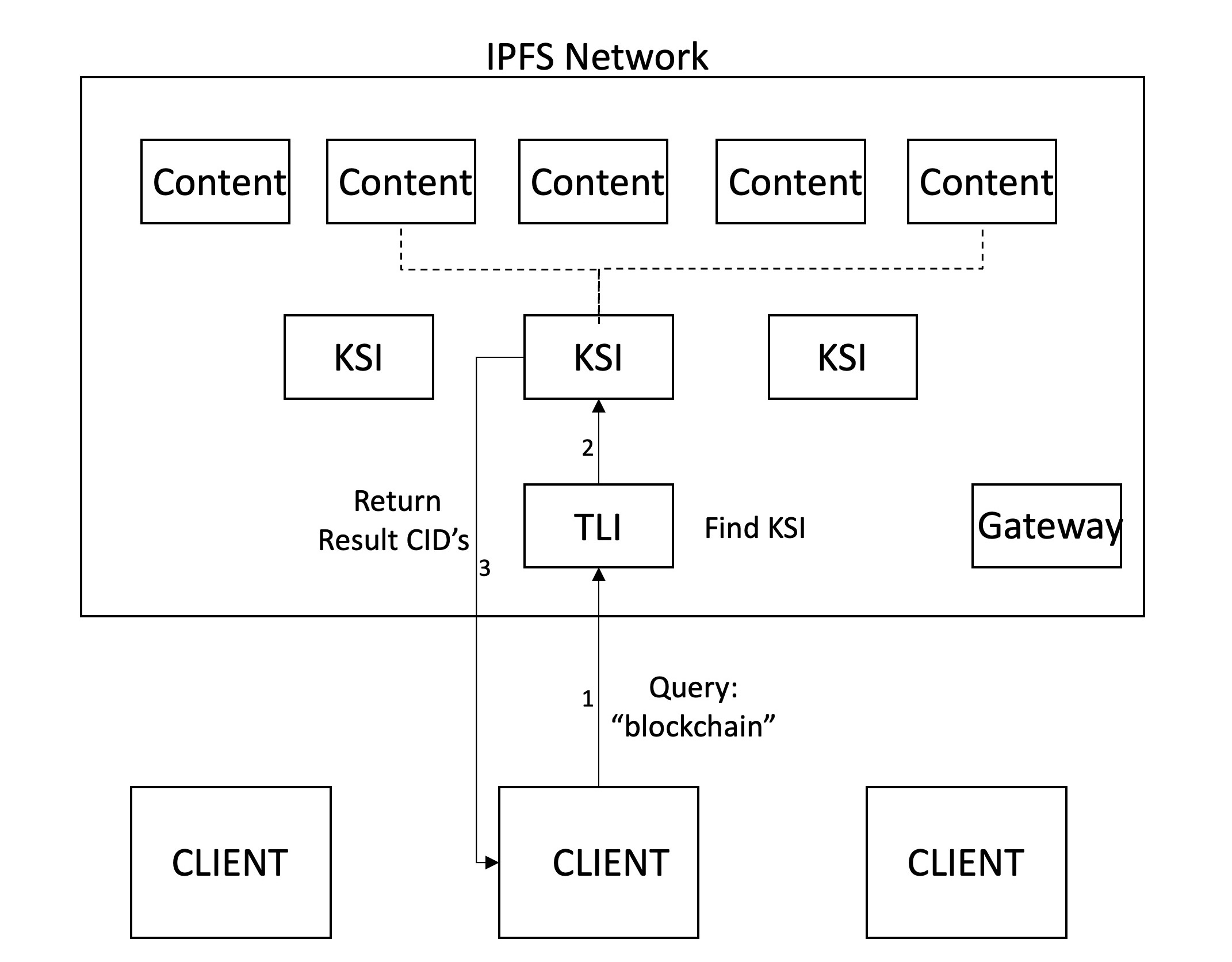
Un aspecto importante en los motores de búsqueda es el mecanismo de clasificación. Esto generalmente sucede de manera centralizada, sin mucha influencia de los clientes. Si bien no hemos implementado mecanismos de clasificación sofisticados, imaginamos que se clasifica en los clientes de los resultados, lo que les da una mayor potencia y transparencia. Esto permite a los clientes controlar las funciones de clasificación y personalizarlos en función de las necesidades específicas. En la actualidad, nuestro mecanismo devuelve los resultados ordenados basados en los CID. Cuando se ingresan dos términos de búsqueda, las páginas donde ambos ocurren se devuelven primero, después de lo cual se devuelven las páginas que contienen solo uno de los términos.
Un aspecto importante de cualquier motor de búsqueda es la adición de entradas al índice. Este proceso implica una serie de pasos, que describimos a continuación.
La primera decisión que se tomará es qué contenido se agregará al índice, que llamamos curación . En los motores tradicionales, esto incluye todo el contenido web público. Aunque esto logra un alto rendimiento, puede agregar demasiada sobrecarga cuando se ejecuta en una red descentralizada. Otro enfoque puede ser la curación basada en el consenso de la red de contenido importante. Para nuestro sistema actual, permitimos que cualquiera que crea que contenga sea importante para agregar esto a la red. El contenido puede ser abordado por identificadores CID, DNSLINK, ENS o IPNS.
A continuación, ocurre el rastreo, lo que implica obtener y analizar archivos para extraer palabras clave importantes. Como se mencionó anteriormente, nuestro sistema se arrastra cuando alguien decide que el contenido debe agregarse y, por lo tanto, envía manualmente el CID para que se rastree. En el futuro, imaginamos que esto sucederá automáticamente cuando el contenido se carga o se visita en la red. Además de extraer palabras clave, se pueden agregar otros metadatos. Actualmente usamos el tipo de archivo (PDF) y la marca de tiempo cuando se arrastramos, pero en la intención del futuro de agregar título, recuento, tamaño, etc.
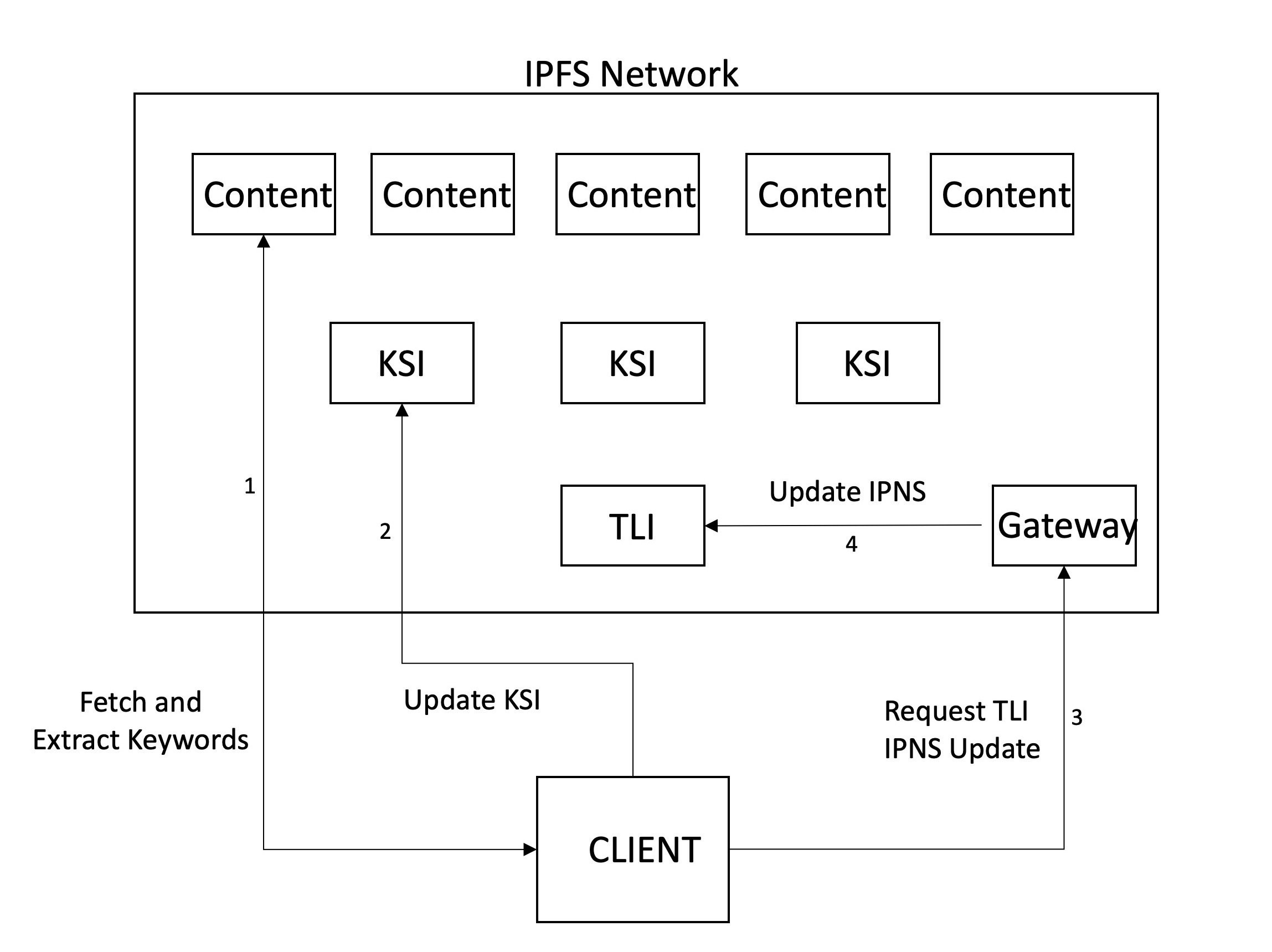
Después de extraer las palabras clave (y producir el RWI), el índice debe almacenarse. Para el almacenamiento usamos IPF, ya que esto permite el almacenamiento colaborativo descentralizado. Hemos decidido mantener una jerarquía de dos niveles. Cada palabra clave tendrá un archivo de índice asociado (KSI) donde los nodos pueden encontrar qué contenido contiene esas palabras clave. Se mantiene un índice separado (TLI) para señalar los identificadores de los KSI, y esto se publica a un nombre de IPNS desde nuestro servidor de puerta de enlace. Cuando un nodo actualiza los KSI después de rastrear un archivo, actualiza el puntero en el TLI a estos archivos y solicita la puerta de enlace para actualizar el puntero que el registro de IPNS resuelve. De esta manera, el registro de IPNS apunta a la última versión del TLI, que a su vez apunta a las últimas versiones de los KSI.
En la actualidad, los nodos del cliente pueden cambiar el TLI si poseen una contraseña, que se puede obtener de los mantenedores de este proyecto. De esta manera, las posibles entradas maliciosas son menos probables. Los nodos con las contraseñas pueden verse como 'autoridades' en la red.
Durante el desarrollo y las pruebas, hemos hecho una serie de observaciones con respecto al rendimiento. Como nuestra solución depende en gran medida de IPFS, también lo hace nuestro rendimiento. Encontramos que pueden ocurrir retrasos significativos cuando los nodos no han agregado el par de la puerta de enlace en su enjambre de pares. Si bien hemos agregado esto a nuestra CLI, la conexión aún cae ocasionalmente. Si bien esto no rompe el sistema, agrega retrasos.
Además, actualizar nuestra entrada IPNS desde la puerta de enlace puede ser muy lenta y puede convertirse en un cuello de botella de rendimiento cuando aumenta el tráfico de rastreo. Hemos comenzado a buscar alternativas, pero dejar la implementación para futuras versiones. Una opción es usar el DNS para almacenar un puntero al último registro de TLI, pero esto trae una serie de desafíos adicionales inherentes al DNS. También se puede utilizar un registro de nombres basado en blockchain como ENS, aunque las actualizaciones frecuentes del contrato de resolución pueden convertirse en un gran gasto.
Hay varias formas de acceder a la búsqueda de Deece:
ClientEl software del cliente puede ser utilizado por cualquier nodo que ejecute IPFS y proporciona una interfaz de línea de comando simple.
NAME:
Deece - Decentralised search for IPFS
USAGE:
Deece [global options] command [command options] [arguments...]
VERSION:
0.0.1
AUTHORS:
Navin V. Keizer < [email protected] >
Puneet K. Bindlish < [email protected] >
COMMANDS:
search Performs a decentralised search on IPFS
crawl Crawls a page to add to the decentralised index
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--help, -h show help (default: false)
--version, -v print the version (default: false)
GatewayPara un acceso fácil y liviano, hemos implementado una puerta de enlace para nuestros clientes de búsqueda. Esto se puede encontrar en: www.deece.nl/web/, y permite buscar y rastrear en la red en función de los identificadores (CID).

NOTA: La puerta de enlace actualmente se inserta mientras se actualiza a la versión 2.
LibraryTanto el CLI como el Gateway se ejecutan usando nuestro paquete de búsqueda Deece para GO. Hemos lanzado esto, ya que esto se puede usar para fáciles de integraciones y extensiones.
Se agregarán más instrucciones de instalación una vez probadas en diferentes plataformas. Por ahora hemos proporcionado instrucciones basadas en nuestra instalación en Linux.
Para la búsqueda de DEECE para trabajar, hay una serie de requisitos y dependencias. Para ejecutarse como cliente, un demonio IPFS local debe estar ejecutándose, y para acelerar los resultados ayuda a agregar la puerta de enlace manteniendo el TLI en el enjambre de pares. Para enviar cambios al TLI como cliente, se requiere una contraseña. Finalmente, un archivo de configuración debe estar presente en el mismo directorio que el ejecutable para cargar resultados. Se puede encontrar un archivo de configuración incompleto en este repositorio.
Para ejecutar el cliente, First IPFS, GO (probado para la versión 1.13.7, las versiones más nuevas deberían funcionar con modificaciones menores), y se debe instalar GIT.
A continuación, debemos instalar desde la fuente:
git clone github.com/navinkeizer/DeeceA continuación, se debe instalar Tesseract-OCR, así como otras dependencias. Para Linux esto puede verse así:
sudo apt-get install g++
sudo apt-get install autoconf automake libtool
sudo apt-get install autoconf-archive
sudo apt-get install pkg-config
sudo apt-get install libpng-dev
sudo apt-get install libjpeg8-dev
sudo apt-get install libtiff5-dev
sudo apt-get install zlib1g-dev
wget http://www.leptonica.org/source/leptonica-1.81.1.tar.gz
sudo tar xf leptonica-1.81.1.tar.gz
cd leptonica-1.81.1 &&
sudo ./configure &&
sudo apt install make
sudo make &&
sudo make install
sudo apt-get install tesseract-ocr # or sudo apt install tesseract-ocr
sudo apt install libtesseract-devSe pueden instalar otros paquetes de GO relevantes:
$ go get -t github.com/otiai10/gosseract
$ go get github.com/navinkeizer/Deece
$ go get github.com/ipfs/go-ipfs-api
$ go get github.com/wealdtech/go-ens/v3
$ go get github.com/otiai10/gosseract/v2
y el CLI construido:
$ sudo go build Deece/CLI/.
y corre:
$ ./CLI [command] [arguments]
El paquete también se puede usar como biblioteca.
go get github.com/navinkeizer/Deece
La implementación actual de la búsqueda de Deece sigue siendo experimental y, por lo tanto, puede experimentar inestabilidades. Como se describe en este documento, hemos hecho suposiciones simplificadoras (altruismo) y nos centramos en la funcionalidad limitada (solo PDF). Además, la puerta de enlace presenta un aspecto centralizado, que en el futuro debe ser reemplazado por un consenso de red descentralizado, y el protocolo debe ser asegurado por incentivos.
Nuestra implementación adopta un enfoque de primer principio. Nuestro objetivo era construir desde cero, en lugar de depender de los enfoques y soluciones existentes para los componentes del sistema. Creemos que esto es necesario ya que las soluciones existentes pueden no ser óptimas para el contenido de Web3 descentralizado. En otras palabras, hay mucho trabajo por hacer.
Actualmente ocasionalmente experimentamos problemas en el proceso de rastreo debido a las actualizaciones de IPNS tiempo de salida. Estamos trabajando para resolver esto con soluciones alternativas.


