Deece
1.0.0

DEECE検索は、IPFのオープンで共同で分散型の検索メカニズムです。クライアントを実行しているノードは、IPFのコンテンツをクロールし、これをインデックスに追加することができます。これは、それ自体がIPFに分散型の方法で保存されます。これにより、分散コンテンツの分散検索が可能になります。
現在の実装は依然として非常に実験的です。私たちは、Central Gatewayのない将来のバージョンに取り組んでおり、代替の検索メカニズムを調査しています。現在のサーバーはダウンしており、プロジェクトは維持されていません。
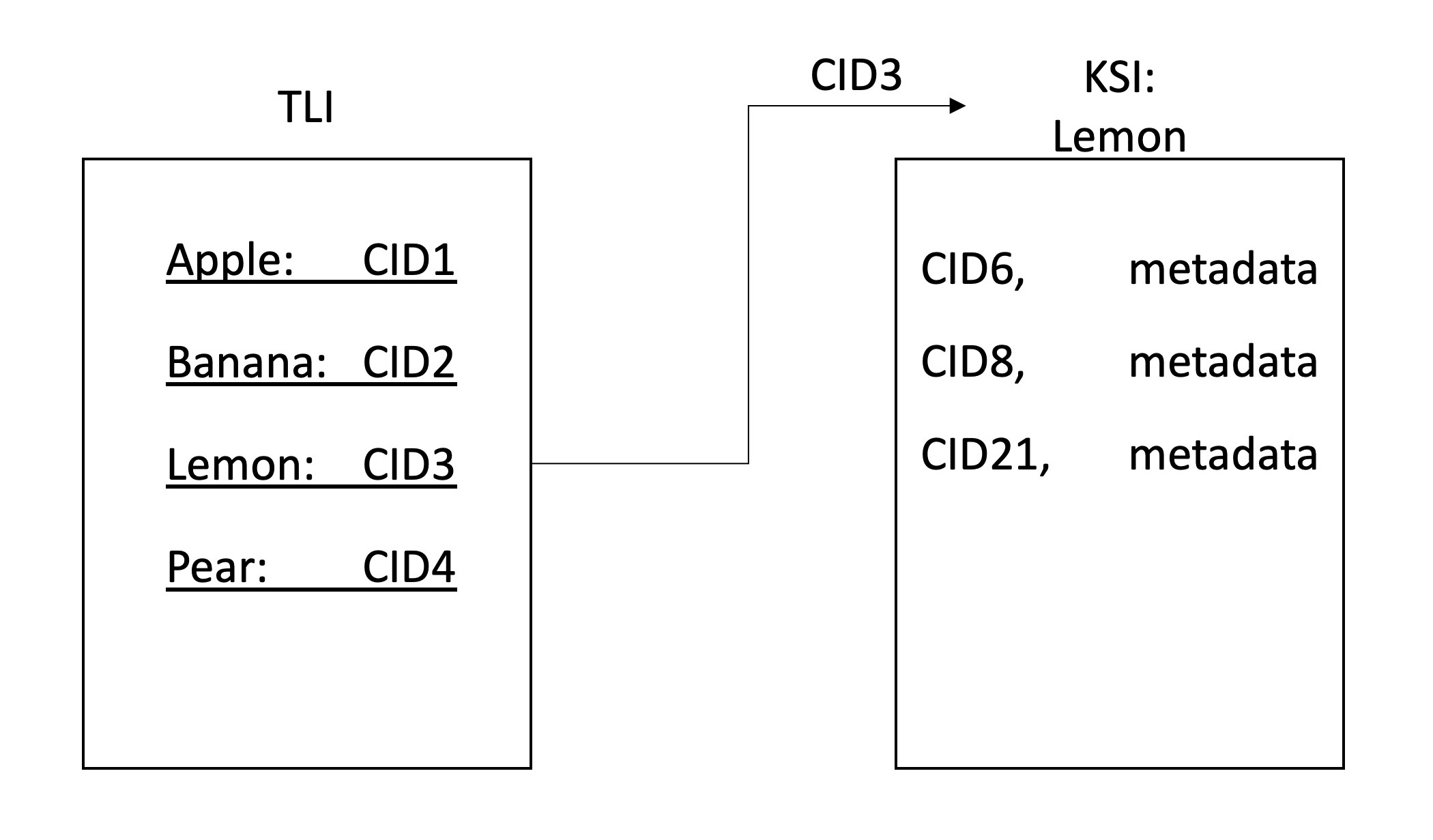
ClientGatewayLibraryDEECE検索では、IPFSデータの分散検索が可能になります。これは、ネットワーク上のデータのクロールとインデックス作成に参加するIPFSノードのネットワークによって達成されます。インデックスはIPFに保存され、2層階層に分割されます。1つ目はトップレベルのインデックス(TLI)で、2番目はキーワード固有のインデックス(KSI)です。 TLIには、各キーワードのKSIの識別子(CID)が含まれており、ノードがクロールを送信すると絶えず更新されます。クロールするとき、ノードは現在のKSIに、そのキーワードを含むファイルの識別子のリストを追加します。
DEECE検索では、 searchとcrawl 2つの特定のアクションが可能になります。検索最新のTLIをクエリして、ユーザークエリの各キーワードのKSIを見つけ、これらの結果をユーザーに表示します。現在、結果のランキングはCIDに基づいて注文されていますが、より洗練されたメカニズムを開発する必要があります。将来拡張される最大2つのキーワードの合計結果を可能にします。
現在、DeeCe検索にアクセスするには3つの方法があります。まず、コマンドラインインターフェイスを使用するクライアントソフトウェアがあります。第二に、クライアントノードのインスタンスを実行し、他のソフトウェアをインストールせずに「ライトクライアント」が検索と対話できるようにするゲートウェイサービス(www.deece.nl/web/)を実装しました。最後に、CLIとGatewayで使用されたコードをGOライブラリの形でリリースしました。
DEECE検索の初期バージョンは、TLIの最新バージョンを指すIPNSレコードを更新するために、信頼できるノード(ゲートウェイと同じノード)に依存しています。クライアントがクロールするとき、最後のステップでは、このサーバーに更新要求を送信することが含まれます。現時点では、セキュリティ対策が後で実装されるため、メンテナーから取得できる構成ファイルにパスワードを指定する必要があります。
現在、Webユーザーは集中化された検索エンジンに代わるものがほとんどありません。これらのエンジンは、集中制御、政策、信頼を維持しており、検閲、プライバシー保護、透明性の問題につながる可能性があります。
さらに、これらのエンジンは一般に、従来のWebコンテンツ(DNSを介してアクセスされるWebサーバーでホストされている)に努力を集中しています。ただし、コンテンツが分散型ストレージネットワークに保存されると予想されるWeb3パラダイム(IPFなど)およびブロックチェーンソリューション(ENSなど)を介して行われる名前の解像度は、代替検索エンジンが必要です。
要するに、分散型データを検索する検索メカニズムが必要であり、分散型の方法でそれを行います。
Web検索の集中化の問題を解決しようとした多くの同等のプロジェクトがあります。まず、現在のWebデータの分散 /分散型検索メカニズムの研究からの実装と提案があります。初期のプロジェクトには、Yacy、Faroo、Seeksが含まれます。最近では、Presearchは、インセンティブのためのブロックチェーンの報酬を使用して、共同検索エンジンを作成することを目指しています。
同様に、多くの作品がP2Pストレージネットワークの分散検索を提供することを目的としています。最近では、グラフは暗号通貨インセンティブを使用して、ブロックチェーンデータの分散型インデックス作成プロトコルを構築しました。
ただし、上記のプロジェクトのいずれも、分散型Web3データの分散型検索の特定のユースケースを完全に把握するものではありません。
当社のアーキテクチャは、インデックスを集合的に維持および追加し、検索を実行できる多くのクライアントノードに依存しています。最初に、アーキテクチャの実用的なプロタイプを完成させ、機能を段階的に追加するアプローチを採用しました。したがって、現在のバージョンは、TLI IPNSレコードを更新するために、信頼できるノード(ゲートウェイ)に依存しています。追加のセキュリティまたはインセンティブ化が実装されていないため、シンプルなパスワードを使用して、新しいクライアントノードがインデックスに追加できるようにしました。セキュリティは将来的には不十分かもしれませんが、初期段階のリリースのための利他的なモデルを想定しています。
将来的には、セキュリティとインセンティブが追加されることを想定しています。これは、インデックスを更新するときに正直にノードを調整することです。これらは、暗号化の報酬、斬新、評判などの形である場合があります。正直なノードへの報酬に資金を提供する1つの方法は、広告をプロトコルに組み込み、ネットワークを維持するノードに広告料金を委任できるようにすることができます。
現在のバージョンは、IPFのPDFファイルのみをサポートし、インデックスに追加されます。将来、これをより多くのファイルタイプとディレクトリに拡張し、さまざまな分散型ストレージネットワークをサポートしたいと考えています。最後に、スマート契約などのブロックチェーンベースのデータを検索に組み込むことを目指しています。
次に、メカニズムにおける2つの主要な操作の概要を示します。
検索は、多くの検索用語を含むクライアントによるクエリから始まります。次に、クライアントは、対応するCIDへのゲートウェイで設定されたIPN名を解決することにより、最新のTLIを取得します。次に、このTLIをフェッチして横断して、キーワードにKSIがあるかどうかを確認します。この場合、関連するKSIはクエリであり、キーワードを含むコンテンツを返します。クライアントは、ネットワークからこれらのファイルを取得できます。
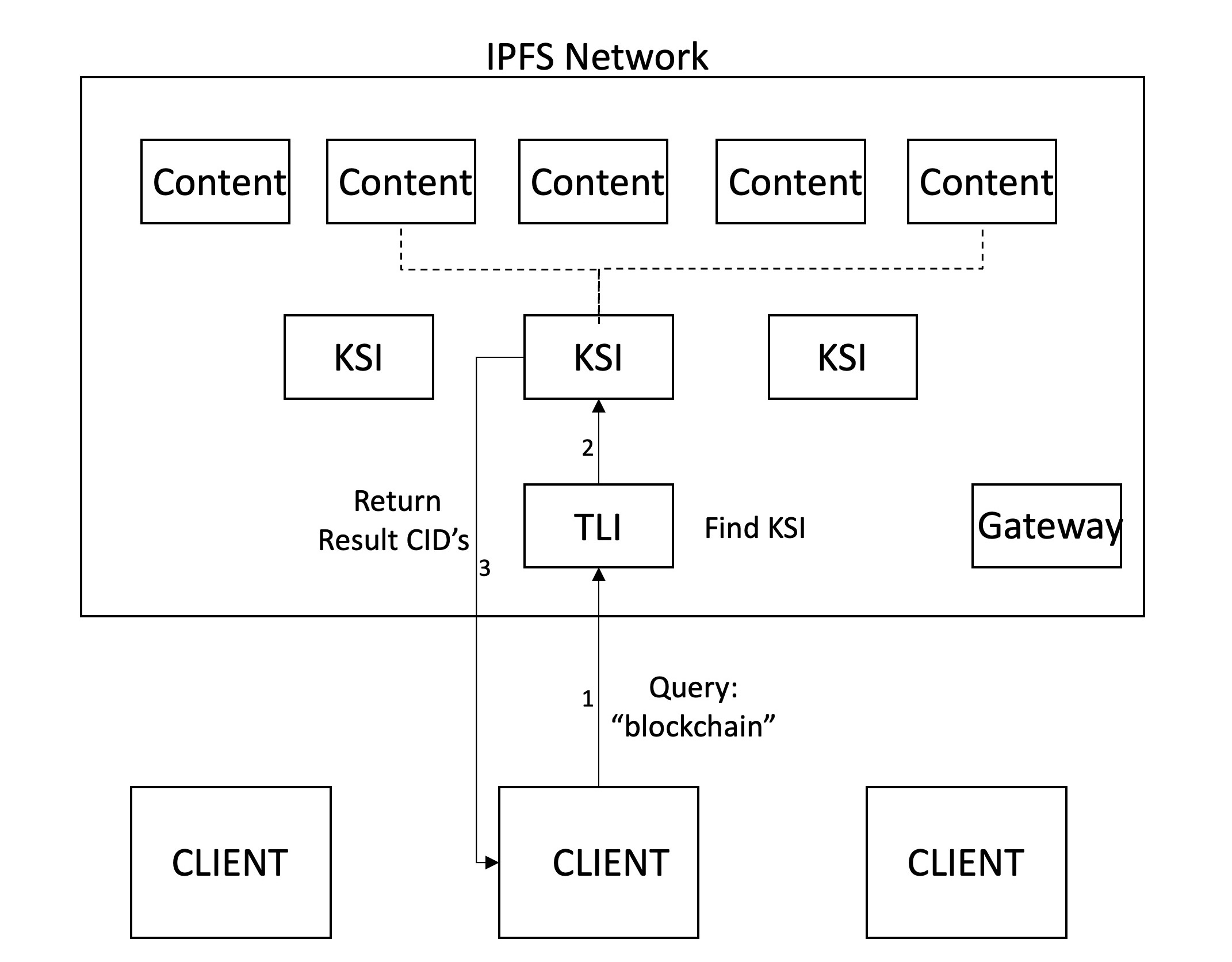
検索エンジンの重要な側面の1つは、ランキングメカニズムです。これは一般に、クライアントからの大きな影響なしに、集中的な方法で起こります。洗練されたランキングメカニズムを実装していませんが、結果のクライアントにランキングが行われることを想像しています。これにより、より大きなパワーと透明性が得られます。これにより、クライアントはランキング機能を制御し、特定のニーズに基づいてこれらをパーソナライズすることができます。現在、私たちのメカニズムは、CIDに基づいて順序付けられた結果を返します。 2つの検索用語が入力されると、これらの両方が発生するページが最初に返され、その後、用語の1つのみを含むページが返されます。
検索エンジンの重要な側面は、インデックスへのエントリを追加することです。このプロセスには、以下で説明するいくつかの手順が含まれます。
行われる最初の決定は、キュレーションと呼ばれるインデックスにコンテンツが追加されるものです。従来のエンジンでは、これにはすべてのパブリックWebコンテンツが含まれます。これは高性能を達成しますが、分散型ネットワークで実行されるとオーバーヘッドが大きすぎる可能性があります。別のアプローチは、重要なコンテンツのネットワークコンセンサスに基づくキュレーションです。現在のシステムでは、コンテンツが重要であると考えている人なら誰でも、これをネットワークに追加することを許可します。コンテンツは、CID、DNSLINK、ENS、またはIPNの識別子によって対処できます。
次に、クロールリングが発生します。これには、ファイルを取得して分析して重要なキーワードを抽出します。上記のように、誰かがコンテンツを追加する必要があると判断したときにシステムがクロールし、したがってCIDを手動で提出してrawいます。将来、コンテンツがネットワーク上にアップロードまたは訪問されたときに、これが自動的に行われることを想定しています。キーワードの抽出に加えて、他のメタデータを追加することができます。現在、クロールされたときにファイルタイプ(PDF)とタイムスタンプを使用していますが、将来的にはタイトル、カウント、サイズなどを追加することを目的としています。
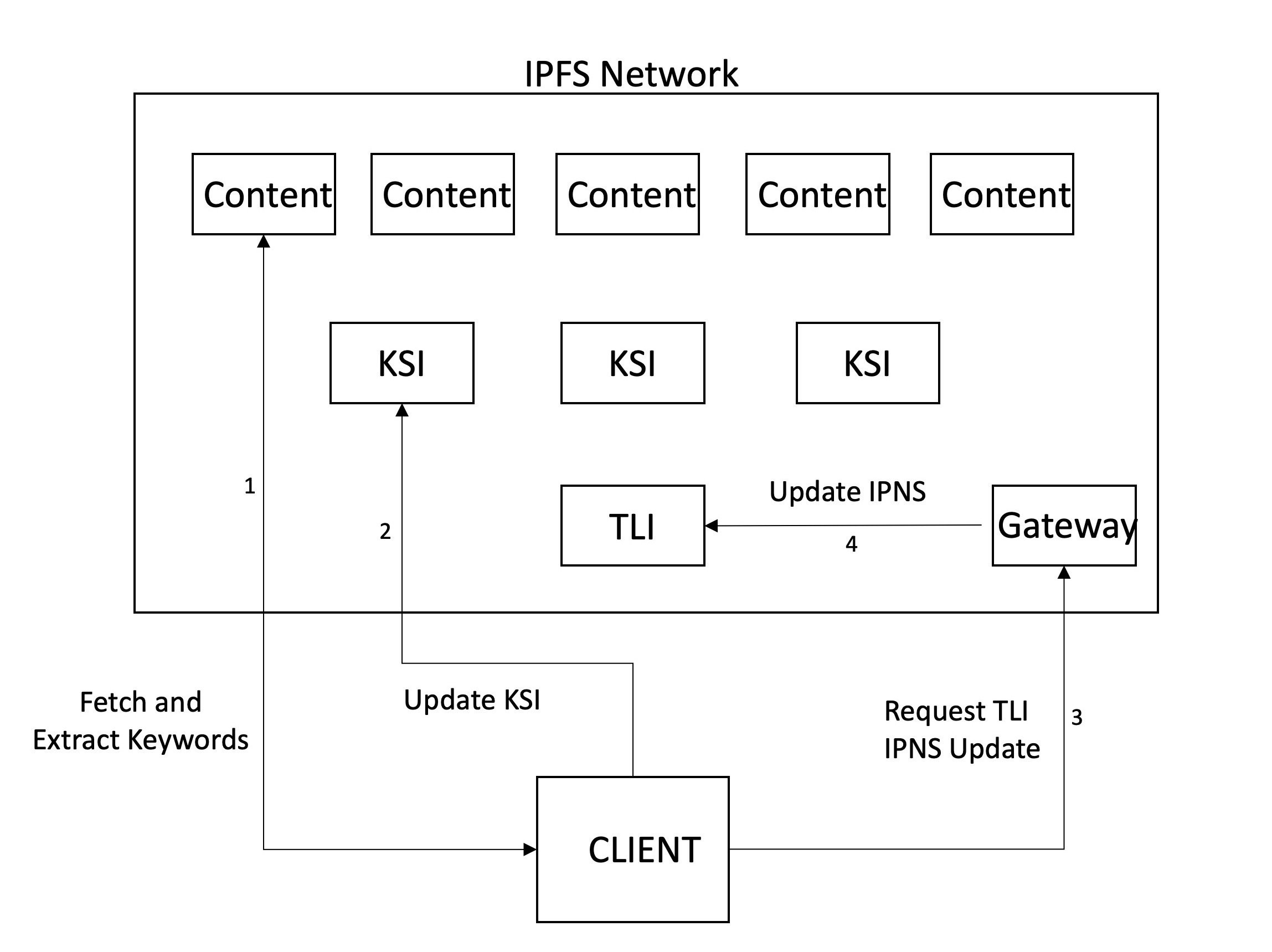
キーワードを抽出した後(およびRWIの生成)、インデックスを保存する必要があります。ストレージには、IPFを使用します。これにより、分散型共同ストレージが可能になります。 2レベルの階層を維持することにしました。各キーワードには、関連するインデックスファイル(KSI)があり、ノードはそれらのキーワードを含むコンテンツを見つけることができます。 KSIの識別子を指すように別のインデックス(TLI)が保持されます。これは、GatewayサーバーのIPN名に公開されます。ノードがファイルをクロールした後にKSIを更新すると、TLIのポインターをこれらのファイルに更新し、IPNSレコードが解決するポインターを更新するゲートウェイを要求します。このようにして、IPNSレコードはTLIの最新バージョンを指しており、これはKSIの最新バージョンを指します。
現在、クライアントノードは、このプロジェクトのメンテナーから取得できるパスワードを所有している場合、TLIを変更できます。これにより、潜在的な悪意のあるエントリの可能性は低くなります。パスワードを含むノードは、ネットワーク内の「当局」と見なすことができます。
開発とテスト中に、パフォーマンスに関して多くの観察を行いました。私たちのソリューションはIPFに大きく依存しているため、パフォーマンスも同様です。ノードがピアの群れにゲートウェイピアを追加していない場合、大幅な遅延が発生する可能性があることがわかりました。これをCLIに追加しましたが、接続は時々落ちます。これはシステムを壊しませんが、遅延を追加します。
さらに、ゲートウェイからIPNのエントリを更新するのは非常に遅く、クロールトラフィックが増加するとパフォーマンスボトルネックになる可能性があります。私たちは代替案を検討し始めましたが、将来のリリースに実装を残しています。 1つのオプションは、DNSを使用して最新のTLIレコードへのポインターを保存することですが、これにより、DNSに固有の多くの追加の課題がもたらされます。 ENSなどのブロックチェーンベースの名前レジストリも使用できますが、リゾルバー契約の頻繁な更新は大きな費用になる可能性があります。
DeeCe検索にアクセスする方法はいくつかあります。
Clientクライアントソフトウェアは、IPFを実行している任意のノードで使用でき、単純なコマンドラインインターフェイスを提供します。
NAME:
Deece - Decentralised search for IPFS
USAGE:
Deece [global options] command [command options] [arguments...]
VERSION:
0.0.1
AUTHORS:
Navin V. Keizer < [email protected] >
Puneet K. Bindlish < [email protected] >
COMMANDS:
search Performs a decentralised search on IPFS
crawl Crawls a page to add to the decentralised index
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--help, -h show help (default: false)
--version, -v print the version (default: false)
Gateway簡単で軽量なアクセスのために、検索クライアントにゲートウェイを実装しました。これは、www.deece.nl/web/で見つけることができ、識別子(CID)に基づいてネットワーク上の検索とクロールを可能にします。

注:現在、ゲートウェイはバージョン2にアップグレードしながら攻撃されています。
LibraryDEECE検索パッケージを使用してCLIとゲートウェイの両方が実行されます。これは、簡単な統合と拡張機能に使用できるため、これをリリースしました。
さまざまなプラットフォームでテストされると、さらにインストール手順が追加されます。今のところ、Linuxへのインストールに基づいて指示を提供しています。
DEECE検索には、多くの要件と依存関係があります。クライアントとして実行するには、ローカルIPFSデーモンが実行されている必要があり、結果をスピードアップするには、ピアスウォームのTLIを維持するゲートウェイを追加するのに役立ちます。クライアントとしてTLIに変更を送信するには、パスワードが必要です。最後に、結果をロードするために実行可能ファイルと同じディレクトリに構成ファイルが存在する必要があります。このリポジトリには、不完全な構成ファイルがあります。
クライアントを実行するには、最初のIPFSを実行して(バージョン1.13.7でテストされ、新しいバージョンはマイナーな変更で動作するはずです)、Gitをインストールする必要があります。
次に、ソースからインストールする必要があります。
git clone github.com/navinkeizer/Deece次のTesseract-ocrは、その他の依存関係と同様にインストールする必要があります。 Linuxの場合、これは次のようになります。
sudo apt-get install g++
sudo apt-get install autoconf automake libtool
sudo apt-get install autoconf-archive
sudo apt-get install pkg-config
sudo apt-get install libpng-dev
sudo apt-get install libjpeg8-dev
sudo apt-get install libtiff5-dev
sudo apt-get install zlib1g-dev
wget http://www.leptonica.org/source/leptonica-1.81.1.tar.gz
sudo tar xf leptonica-1.81.1.tar.gz
cd leptonica-1.81.1 &&
sudo ./configure &&
sudo apt install make
sudo make &&
sudo make install
sudo apt-get install tesseract-ocr # or sudo apt install tesseract-ocr
sudo apt install libtesseract-devその後、他の関連するGOパッケージをインストールできます。
$ go get -t github.com/otiai10/gosseract
$ go get github.com/navinkeizer/Deece
$ go get github.com/ipfs/go-ipfs-api
$ go get github.com/wealdtech/go-ens/v3
$ go get github.com/otiai10/gosseract/v2
そしてCLIが構築されました:
$ sudo go build Deece/CLI/.
と実行:
$ ./CLI [command] [arguments]
パッケージはライブラリとしても使用できます。
go get github.com/navinkeizer/Deece
DEECE検索の現在の実装は依然として実験的であるため、不安定性が発生する可能性があります。このドキュメントで説明されているように、単純化された仮定(利他主義)を作成し、限られた機能(PDFのみ)に焦点を当てました。さらに、ゲートウェイには集中的な側面が提示され、将来的には分散型ネットワークコンセンサスに置き換えられるはずであり、プロトコルはインセンティブによって保護されるべきです。
私たちの実装には、第一の原則的なアプローチが必要です。システムコンポーネントの既存のアプローチやソリューションに依存するのではなく、ゼロから構築することを目指しました。既存のソリューションは分散型Web3コンテンツに最適ではない可能性があるため、これは必要だと考えています。言い換えれば、やるべきことがたくさんあります。
現在、IPNの更新によりタイミングが出るため、クロールプロセスで問題が発生することがあります。これを代替ソリューションで解決することに取り組んでいます。


