Deece
1.0.0

Deece Search는 IPF에 대한 개방적이고 협력 적이며 분산 된 검색 메커니즘입니다. 클라이언트를 실행하는 모든 노드는 IPF에서 컨텐츠를 크롤링하고 IPF에 분산 된 방식으로 저장됩니다. 이를 통해 분산 된 콘텐츠에 대한 분산 된 검색이 가능합니다.
현재 구현은 여전히 실험적입니다. 우리는 Central Gateway가없는 미래 버전에서 작업하고 있으며 대체 검색 메커니즘을 탐색하고 있습니다. 현재 서버가 다운되었고 프로젝트는 유지되지 않았습니다.
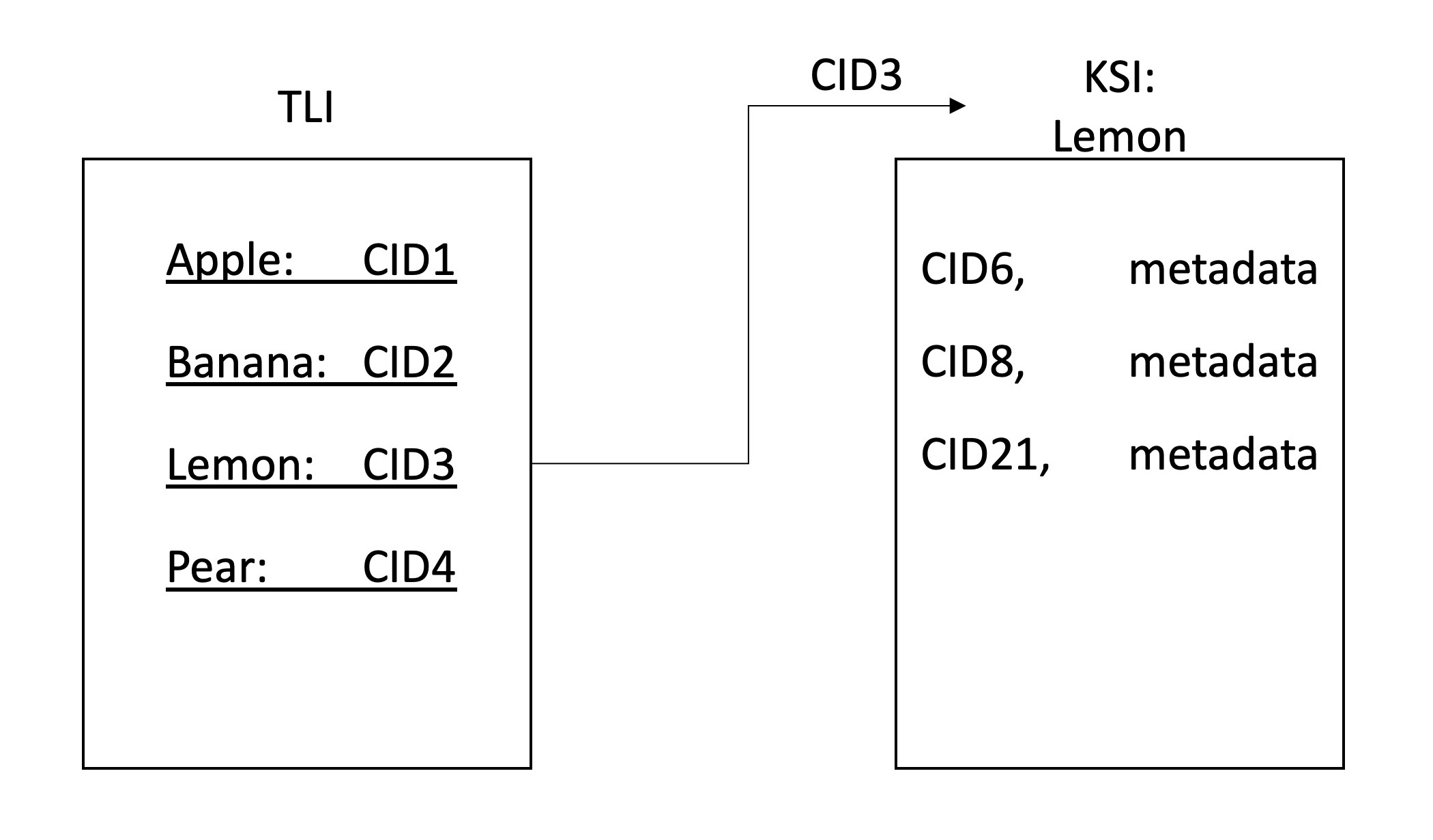
ClientGatewayLibraryDEECE 검색을 통해 IPFS 데이터에서 분산 된 검색을 허용합니다. 이는 네트워크에서 데이터의 크롤링 및 인덱싱에 참여하는 IPFS 노드 네트워크에 의해 달성됩니다. 인덱스는 IPF에 저장되고 2 층 계층으로 나뉘며, 첫 번째는 최상위 인덱스 (TLI)이고 두 번째는 키워드 별 인덱스 (KSI)입니다. TLI에는 각 키워드에 대한 KSI의 식별자 (CID)가 포함되어 있으며 노드가 크롤링을 제출할 때 지속적으로 업데이트됩니다. 크롤링 할 때 노드는 현재 KSI에 해당 키워드를 포함하는 파일 식별자 목록을 추가합니다.
Deece Search는 search 과 crawl 의 두 가지 특정 작업을 허용합니다. 검색은 최신 TLI를 쿼리하여 사용자 쿼리에서 각 키워드의 KSI를 찾은 다음 사용자에게 표시되는 결과를 가져옵니다. 현재 결과 순위는 CID에 따라 주문되지만보다 정교한 메커니즘을 개발해야합니다. 우리는 최대 두 개의 키워드에 대한 결합 된 결과를 허용하며, 향후에는 확장 될 것입니다.
현재 Deece 검색에 액세스하는 세 가지 방법이 있습니다. 먼저 명령 줄 인터페이스를 사용하는 클라이언트 소프트웨어가 있습니다. 둘째, 우리는 Gateway Service (www.deece.nl/web/)를 구현하여 클라이언트 노드의 인스턴스를 실행하고 "Light Clients"가 다른 소프트웨어를 설치하지 않고 검색과 상호 작용할 수 있도록합니다. 마지막으로 CLI 및 게이트웨이에서 사용한 코드를 GO 라이브러리 형태로 공개했습니다.
Deece Search의 초기 버전은 신뢰할 수있는 노드 (게이트웨이와 동일한 노드)에 의존하여 최신 버전의 TLI를 가리키는 IPNS 레코드를 업데이트합니다. 클라이언트가 크롤링하면 최종 단계는이 서버에 업데이트 요청을 보내는 것입니다. 현재 클라이언트는 보안 측정이 나중에 구현되므로 관리자로부터 얻을 수있는 구성 파일에 암호를 지정해야합니다.
현재 웹 사용자는 중앙 검색 엔진에 대한 대안이 거의 없습니다. 이 엔진은 중앙 집중식 제어, 정책 및 신뢰를 유지하여 검열, 개인 정보 보호 및 투명성 문제로 이어질 수 있습니다.
또한이 엔진은 일반적으로 기존 웹 컨텐츠 (웹 서버에서 호스팅, DNS를 통해 액세스)에 대한 노력에 중점을 둡니다. 그러나 컨텐츠가 분산 된 스토리지 네트워크 (예 : IPF)에 저장 될 것으로 예상되는 Web3 패러다임에서 블록 체인 솔루션 (예 : ENS)을 통해 이루어질 수있는 이름 해상도에 저장 될 것으로 예상됩니다. 대체 검색 엔진이 필요합니다.
요컨대, 분산 된 데이터를 검색하고 분산 된 방식으로 검색 메커니즘이 필요합니다.
웹 검색에서 중앙 집중화 문제를 해결하려고 시도한 많은 비슷한 프로젝트가 있습니다. 우선, 현재 웹 데이터에 대한 분산 / 분산 검색 메커니즘에 대한 연구의 구현 및 제안이 있습니다. 초기 프로젝트에는 Yacy, Faroo 및 Semks가 포함됩니다. 보다 최근에 Presearch는 인센티브에 대한 블록 체인 보상을 사용하여 협업 검색 엔진을 만드는 것을 목표로합니다.
마찬가지로, 다수의 작품은 P2P 스토리지 네트워크에 대한 분산 검색을 제공하는 것을 목표로했습니다. 보다 최근 에이 그래프는 cryptocurrency 인센티브를 사용하여 블록 체인 데이터에 대한 분산 된 인덱싱 프로토콜을 구축했습니다.
그러나 위의 프로젝트 중 어느 것도 분산 된 Web3 데이터에 대한 분산 된 분산 된 검색의 특정 사용 사례를 완전히 포착하지 않습니다.
우리의 아키텍처는 여러 클라이언트 노드에 의존하여 집합 적으로 인덱스를 유지하고 추가하며 검색을 수행 할 수 있습니다. 우리는 먼저 아키텍처의 작업 양성자를 마무리하고 기능을 점진적으로 추가하는 방법을 접근했습니다. 따라서 현재 버전은 TLI IPNS 레코드를 업데이트하기 위해 신뢰할 수있는 노드 (게이트웨이)에 의존합니다. 보안 또는 인센티브가 추가되지 않으므로 구현 된 간단한 암호를 사용하여 새 클라이언트 노드가 인덱스에 추가 할 수 있습니다. 앞으로 보안이 불충분하지만 초기 단계 릴리스에 대한 이타적인 모델을 가정합니다.
앞으로 우리는 보안과 인센티브가 추가 될 것으로 예상되는데, 이는 인덱스를 업데이트 할 때 노드를 정직하게 조정합니다. 이들은 Cryptocurreny 보상, 슬래시, 평판 등의 형태 일 수 있습니다. 정직한 노드에 보상을 제공하는 한 가지 방법은 광고를 프로토콜에 통합하고 광고 수수료를 네트워크를 유지하는 노드에 위임 할 수 있습니다.
현재 버전은 IPF의 PDF 파일 만 지원하여 인덱스에 추가 할 수 있습니다. 앞으로 더 많은 파일 유형 및 디렉토리로이를 확장하고 다른 분산 스토리지 네트워크를 지원하고자합니다. 마지막으로, 우리는 스마트 계약과 같은 블록 체인 기반 데이터를 검색에 통합하는 것을 목표로합니다.
우리는 이제 우리의 메커니즘에서 두 가지 주요 작업에 대한 개요를 제시합니다.
검색은 여러 검색어가 포함 된 클라이언트의 쿼리로 시작됩니다. 그런 다음 클라이언트는 게이트웨이에서 해당 CID로 설정된 IPNS 이름을 해결하여 최신 TLI를 가져옵니다. 이 TLI는 키워드에 KSI가 있는지 확인하기 위해 가져 와서 가로 지르고 있습니다. 이 경우 관련 KSI는 쿼리이며 키워드가 포함 된 컨텐츠를 반환합니다. 그런 다음 클라이언트는 네트워크에서 이러한 파일을 검색 할 수 있습니다.
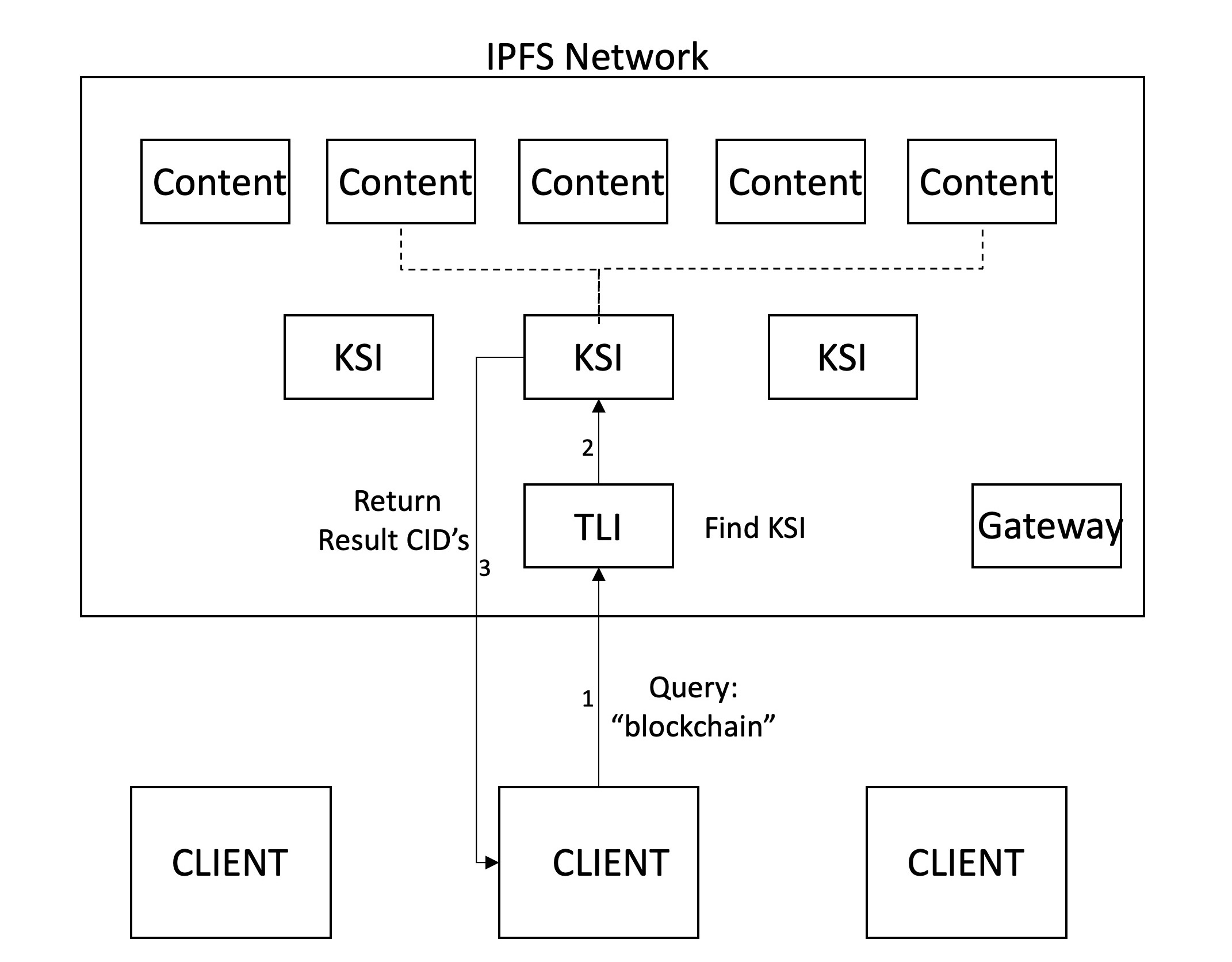
검색 엔진의 중요한 측면 중 하나는 순위 메커니즘입니다. 이것은 일반적으로 고객의 많은 영향을 미치지 않고 중앙 집중식 방식으로 발생합니다. 우리는 정교한 순위 메커니즘을 구현하지는 않았지만 결과의 클라이언트에 순위가있을 것으로 예상하여 더 큰 힘과 투명성을 제공합니다. 이를 통해 고객은 순위 기능을 제어하고 특정 요구에 따라이를 개인화 할 수 있습니다. 현재, 우리의 메커니즘은 CID를 기반으로 순서 결과를 반환합니다. 두 개의 검색어가 입력되면이 둘 다 발생하는 페이지가 먼저 반환되며, 그 후에는 용어 중 하나만 포함 된 페이지가 반환됩니다.
모든 검색 엔진의 중요한 측면은 인덱스에 항목을 추가하는 것입니다. 이 프로세스에는 여러 단계가 포함되며 아래에 설명합니다.
첫 번째 결정은 큐 레이션 이라고 부르는 인덱스에 컨텐츠가 추가 될 것입니다. 전통적인 엔진에서는 여기에는 모든 공개 웹 컨텐츠가 포함됩니다. 이것은 고성능을 달성하지만 분산 된 네트워크에서 실행될 때 너무 많은 오버 헤드를 추가 할 수 있습니다. 또 다른 접근법은 중요한 컨텐츠의 네트워크 합의를 기반으로 한 큐 레이션 일 수 있습니다. 현재 시스템의 경우 콘텐츠를 네트워크에 추가하는 것이 중요하다고 생각하는 사람이라면 누구나 허용합니다. CID, DNSLINK, ENS 또는 IPNS 식별자가 컨텐츠를 해결할 수 있습니다.
다음으로 크롤링이 발생하여 중요한 키워드를 추출하기 위해 파일을 가져오고 분석합니다. 위에서 언급했듯이, 누군가가 컨텐츠를 추가해야 할 때 우리 시스템은 크롤링되므로 CID를 수동으로 제출합니다. 앞으로는 콘텐츠가 네트워크에서 업로드되거나 방문 될 때 자동으로 이런 일이 발생한다고 생각합니다. 키워드 추출 외에 다른 메타 데이터가 추가 될 수 있습니다. 우리는 현재 크롤링시 파일 유형 (PDF)과 타임 스탬프를 사용하지만 앞으로 제목, 카운트, 크기 등을 추가하려는 의도입니다.
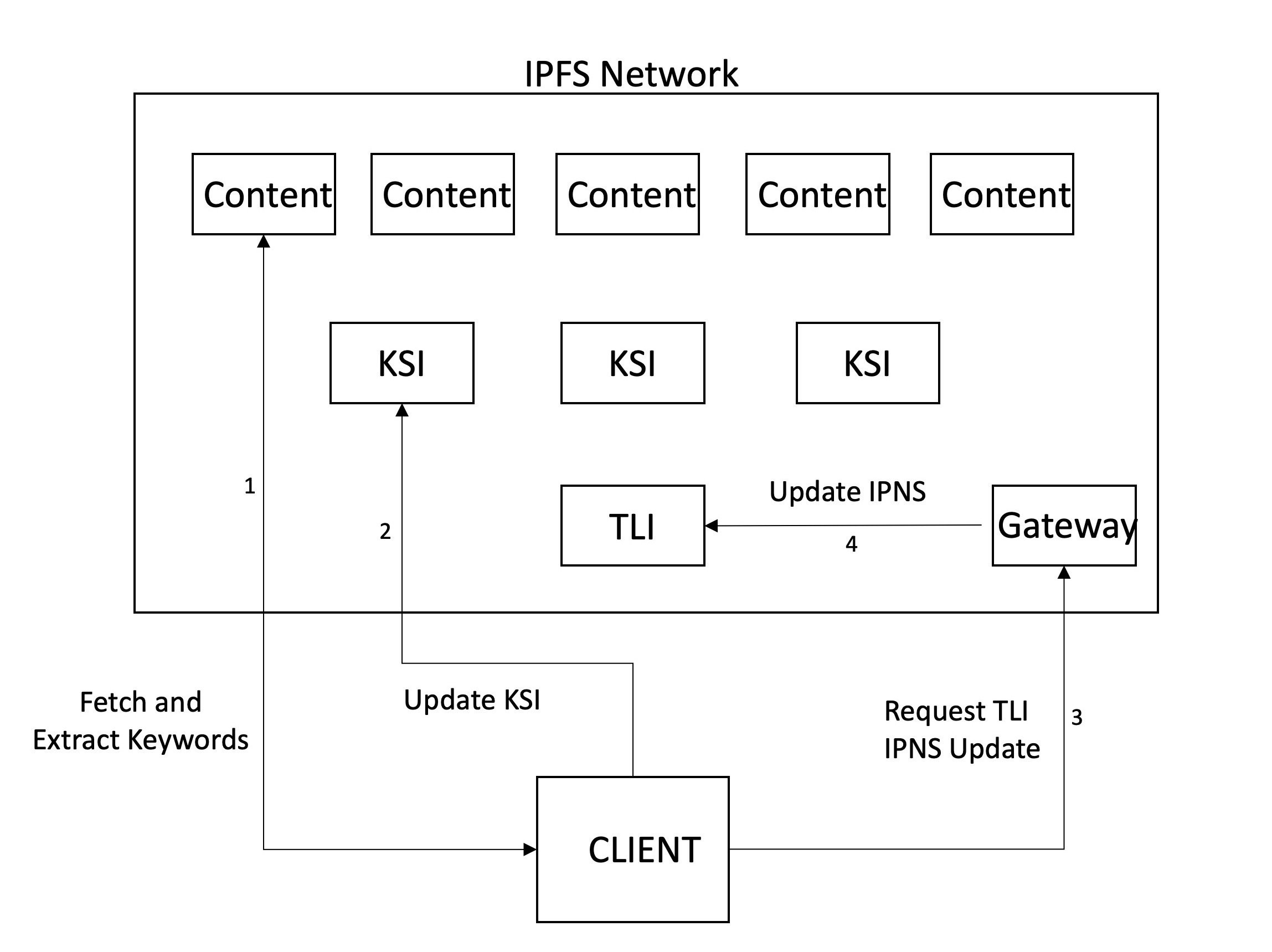
키워드를 추출하고 (및 RWI를 생성 한 후) 인덱스를 저장해야합니다. 스토리지의 경우 IPF를 사용하여 분산 된 공동 작업 저장소가 가능하므로 IPF를 사용합니다. 우리는 2 단계 계층을 유지하기로 결정했습니다. 각 키워드에는 노드가 해당 키워드가 포함 된 컨텐츠를 찾을 수있는 관련 인덱스 파일 (KSI)이 있습니다. KSI의 식별자를 가리키기 위해 별도의 인덱스 (TLI)가 유지되며 이는 게이트웨이 서버의 IPNS 이름에 게시됩니다. 노드가 파일을 크롤링 한 후 KSI를 업데이트하면 TLI의 포인터를 이러한 파일로 업데이트하고 게이트웨이에 IPNS 레코드가 해결하는 포인터를 업데이트하도록 요청합니다. 이런 식으로 IPNS 레코드는 최신 버전의 TLI를 가리 킵니다.
현재 클라이언트 노드는 비밀번호가있는 경우 TLI를 변경할 수 있으며,이 프로젝트의 관리자로부터 얻을 수 있습니다. 이런 식으로, 잠재적 인 악의적 인 항목은 덜 가능합니다. 비밀번호가있는 노드는 네트워크에서 '당국'으로 볼 수 있습니다.
개발 및 테스트 중에 우리는 성능과 관련하여 여러 가지 관찰을했습니다. 솔루션은 IPF에 크게 의존하기 때문에 성능도 크게 의존합니다. 우리는 노드가 동료 떼에 게이트웨이 피어를 추가하지 않았을 때 상당한 지연이 발생할 수 있음을 발견했습니다. CLI에 이것을 추가했지만 연결은 여전히 삭제됩니다. 이것은 시스템을 깨뜨리지 않지만 지연이 추가됩니다.
또한 게이트웨이에서 IPN 항목을 업데이트하는 것은 매우 느릴 수 있으며 크롤링 트래픽이 증가 할 때 성능 병목 현상이 될 수 있습니다. 우리는 대안을 조사하기 시작했지만 향후 릴리스에 구현을 떠납니다. 한 가지 옵션은 DNS를 사용하여 최신 TLI 레코드에 대한 포인터를 저장하는 것이지만 DNS에 내재 된 여러 가지 추가 문제가 발생합니다. Resolver 계약에 대한 빈번한 업데이트가 큰 비용이 될 수 있지만 ENS와 같은 블록 체인 기반 이름 레지스트리도 사용될 수 있습니다.
Deece 검색에 액세스하는 방법에는 여러 가지가 있습니다.
Client클라이언트 소프트웨어는 IPF를 실행하는 노드에서 사용할 수 있으며 간단한 명령 줄 인터페이스를 제공합니다.
NAME:
Deece - Decentralised search for IPFS
USAGE:
Deece [global options] command [command options] [arguments...]
VERSION:
0.0.1
AUTHORS:
Navin V. Keizer < [email protected] >
Puneet K. Bindlish < [email protected] >
COMMANDS:
search Performs a decentralised search on IPFS
crawl Crawls a page to add to the decentralised index
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--help, -h show help (default: false)
--version, -v print the version (default: false)
Gateway쉽고 가벼운 액세스를 위해 검색 클라이언트를위한 게이트웨이를 구현했습니다. 이것은 www.deece.nl/web/에서 찾을 수 있으며 식별자 (CID)를 기반으로 네트워크에서 검색 및 크롤링을 허용합니다.

참고 : 게이트웨이는 현재 버전 2로 업그레이드하는 동안 징계 중입니다.
LibraryCLI와 게이트웨이는 모두 Deece 검색 패키지를 사용하여 실행됩니다. 우리는 쉽게 통합 및 확장에 사용될 수 있으므로 이것을 릴리스했습니다.
다른 플랫폼에서 테스트 한 후 추가 설치 지침이 추가됩니다. 현재 우리는 Linux에 설치를 기반으로 지침을 제공했습니다.
Deece 검색이 작동하려면 여러 가지 요구 사항과 종속성이 있습니다. 클라이언트로 실행하려면 로컬 IPFS 데몬이 실행되어야하며 결과 속도를 높이려면 게이트웨이를 추가하는 데 도움이됩니다. 클라이언트로서 TLI에 변경 사항을 제출하려면 비밀번호가 필요합니다. 마지막으로, 구성 파일은 실행 파일과 동일한 디렉토리에 실행 가능 결과를로드하기 위해 존재해야합니다. 이 저장소에서 불완전한 구성 파일을 찾을 수 있습니다.
클라이언트, 첫 번째 IPFS를 실행하려면 GO (버전 1.13.7에 대한 테스트, 최신 버전은 사소한 수정으로 작동해야 함)를 설치해야합니다.
다음으로 소스에서 설치해야합니다.
git clone github.com/navinkeizer/Deece다음 TesserAct-ARC는 다른 종속성뿐만 아니라 설치해야합니다. Linux의 경우 이것은 다음과 같습니다.
sudo apt-get install g++
sudo apt-get install autoconf automake libtool
sudo apt-get install autoconf-archive
sudo apt-get install pkg-config
sudo apt-get install libpng-dev
sudo apt-get install libjpeg8-dev
sudo apt-get install libtiff5-dev
sudo apt-get install zlib1g-dev
wget http://www.leptonica.org/source/leptonica-1.81.1.tar.gz
sudo tar xf leptonica-1.81.1.tar.gz
cd leptonica-1.81.1 &&
sudo ./configure &&
sudo apt install make
sudo make &&
sudo make install
sudo apt-get install tesseract-ocr # or sudo apt install tesseract-ocr
sudo apt install libtesseract-dev그런 다음 다른 관련 GO 패키지를 설치할 수 있습니다.
$ go get -t github.com/otiai10/gosseract
$ go get github.com/navinkeizer/Deece
$ go get github.com/ipfs/go-ipfs-api
$ go get github.com/wealdtech/go-ens/v3
$ go get github.com/otiai10/gosseract/v2
그리고 CLI는 다음과 같습니다.
$ sudo go build Deece/CLI/.
그리고 달리기 :
$ ./CLI [command] [arguments]
패키지는 라이브러리로도 사용할 수 있습니다.
go get github.com/navinkeizer/Deece
현재 Deece 검색의 구현은 여전히 실험적이므로 불안정성을 경험할 수 있습니다. 이 문서에 설명 된 바와 같이, 우리는 단순화 가정 (이타주의)을 만들고 제한된 기능 (PDF 만 해당)에 중점을 두었습니다. 또한 게이트웨이는 중앙 집중식 측면을 제시하며, 향후에 분산 된 네트워크 합의로 대체되어야하며, 프로토콜은 인센티브에 의해 확보되어야합니다.
우리의 구현은 첫 번째 원칙 접근법을 취합니다. 우리는 시스템 구성 요소를위한 기존 접근법과 솔루션에 의존하기보다는 처음부터 구축하는 것을 목표로했습니다. 우리는 기존 솔루션이 분산 된 Web3 컨텐츠에 최적이 아닐 수 있으므로 이것이 필요하다고 생각합니다. 다시 말해,해야 할 일이 많이 있습니다.
현재 우리는 때때로 IPNS 업데이트 타이밍으로 인해 크롤링 프로세스에서 문제를 경험합니다. 우리는 대체 솔루션으로 이것을 해결하기 위해 노력하고 있습니다.


