Deece
1.0.0

Deece Search est un mécanisme de recherche ouvert, collaboratif et décentralisé pour les IPF. Tout nœud exécutant le client est capable de ramper du contenu sur IPFS et de l'ajouter à l'index, qui lui-même est stocké de manière décentralisée sur IPFS. Cela permet une recherche décentralisée sur un contenu décentralisé.
L'implémentation actuelle est toujours très expérimentale. Nous travaillons sur les futures versions sans passerelle centrale et explorons des mécanismes de recherche alternatifs. Notre serveur actuel est en panne et le projet n'a pas été maintenu.
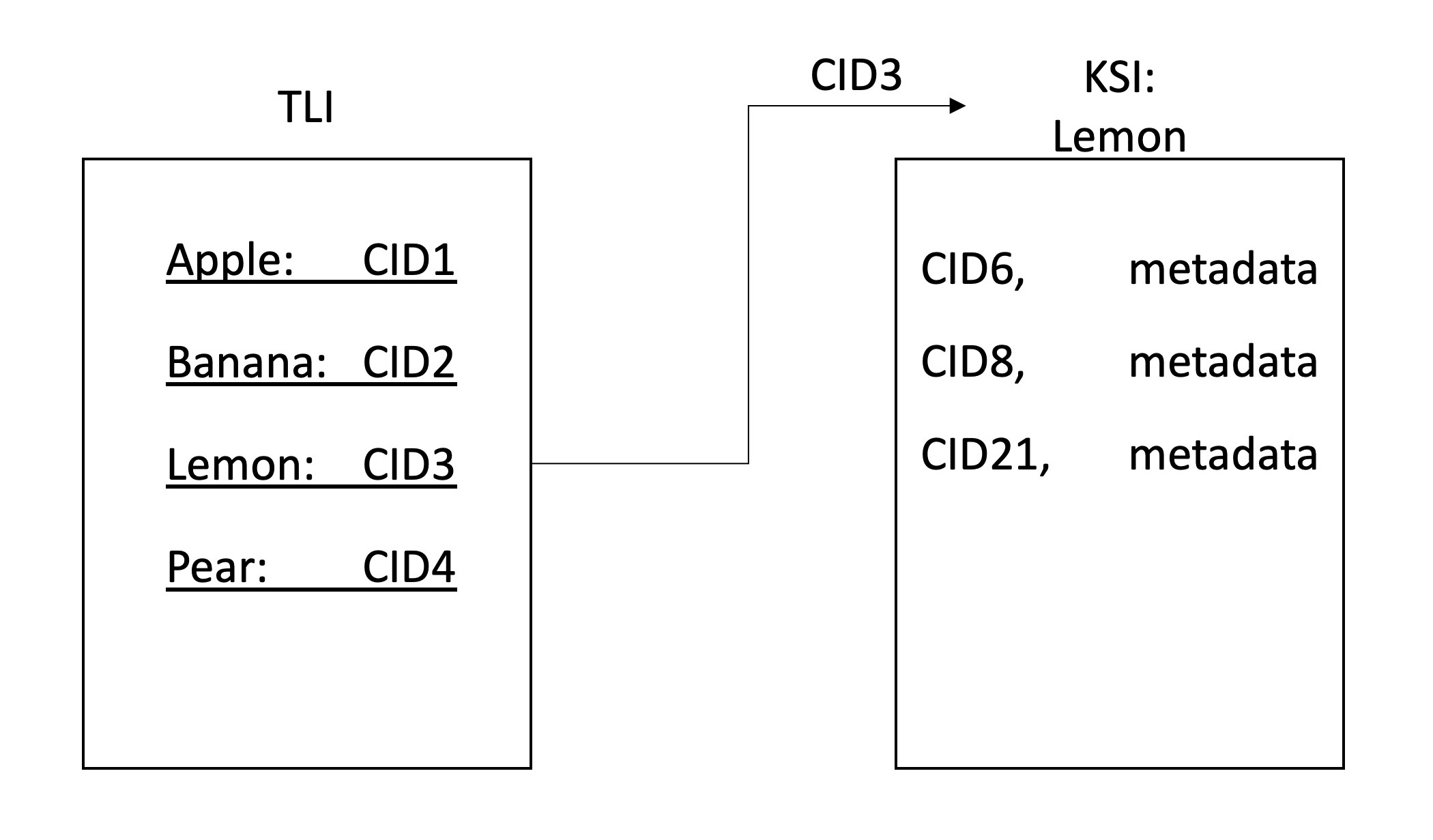
ClientGatewayLibraryLa recherche Deece permet une recherche décentralisée sur les données IPFS. Ceci est réalisé par un réseau de nœuds IPFS qui participent à la rampe et à l'indexation des données sur le réseau. L'index est stocké sur IPFS et divisé en une hiérarchie à deux couches, le premier étant l' index de niveau supérieur (TLI) et le second étant les index spécifiques au mot clé (KSI). Le TLI contient les identifiants (CID) pour le KSI pour chaque mot-clé et est constamment mis à jour lorsqu'un nœud soumet une rampe. Lorsque vous rampez, les nœuds ajoutent au KSI actuel une liste des identifiants des fichiers contenant ce mot-clé.
La recherche Deece permet deux actions spécifiques: search et crawl . Recherchez les requêtes le dernier TLI pour trouver le KSI pour chaque mot-clé de la requête utilisateur, puis récupère les résultats de ceux-ci, qui sont affichés à l'utilisateur. Actuellement, le classement des résultats est ordonné en fonction du CID, mais des mécanismes plus sophistiqués doivent être développés. Nous permettons des résultats combinés pour jusqu'à deux mots clés, qui seront étendus à l'avenir.
Il existe actuellement trois façons d'accéder à la recherche Deece. Tout d'abord, il existe le logiciel client qui utilise une interface de ligne de commande. Deuxièmement, nous avons implémenté un service Gateway (www.deece.nl/web/), qui exécute une instance de notre nœud client et permet aux "clients légers" d'interagir avec la recherche sans installer d'autres logiciels. Enfin, nous avons publié notre code utilisé par la CLI et la passerelle sous la forme d'une bibliothèque Go.
La version initiale de Deece Search repose sur un nœud de confiance (le même nœud que notre passerelle) pour mettre à jour l'enregistrement IPNS pointant vers la dernière version du TLI. Lorsque les clients rampent, la dernière étape les implique d'envoyer une demande de mise à jour à ce serveur. À l'heure actuelle, les clients devront spécifier un mot de passe dans leur fichier de configuration, qui peut être obtenu auprès des responsables, car les mesures de sécurité seront implémentées ultérieurement.
Actuellement, les utilisateurs Web ont peu d'alternatives aux moteurs de recherche centralisés . Ces moteurs maintiennent le contrôle, la politique et la confiance centralisés, ce qui peut entraîner des problèmes de censure, de protection de la vie privée et de transparence.
En outre, ces moteurs concentrent généralement leurs efforts sur le contenu Web traditionnel (hébergé sur des serveurs Web, accessible via le DNS). Cependant, dans un paradigme Web3, où le contenu devrait être stocké dans des réseaux de stockage décentralisés (par exemple IPF) et la résolution de noms qui se déroule via Blockchain Solutions (par exemple ENS), un autre moteur de recherche est requis.
En bref, un mécanisme de recherche est nécessaire qui recherche des données décentralisées et le fait de manière décentralisée.
Il existe un certain nombre de projets comparables, qui ont tenté de résoudre le problème de la centralisation dans la recherche Web. Tout d'abord, il existe des implémentations et des propositions de recherches pour les mécanismes de recherche distribués / décentralisés pour les données Web actuelles. Les premiers projets incluent Yacy, Faroo et Seeks. Plus récemment, Presearch vise à créer un moteur de recherche collaboratif utilisant des récompenses de blockchain pour les incitations.
De même, un certain nombre d'œuvres visaient à fournir la recherche distribuée pour les réseaux de stockage P2P. Plus récemment, le graphique a construit un protocole d'indexation décentralisé pour les données de blockchain à l'aide d'incitations à la crypto-monnaie.
Cependant, aucun des projets ci-dessus ne capture entièrement notre cas d'utilisation spécifique de recherche décentralisée de données Web3 décentralisées.
Notre architecture repose sur un certain nombre de nœuds clients, qui maintiennent et s'ajoutent collectivement à l'index, et sont capables d'effectuer des recherches. Nous avons d'abord adopté l'approche de la finition d'un protype de travail de notre architecture et de l'ajout de caractéristiques progressivement. Par conséquent, notre version actuelle repose sur un nœud de confiance (Gateway) pour mettre à jour l'enregistrement TLI IPNS. Comme il n'y a pas de sécurité ou d'incitation supplémentaire implémentée, nous avons utilisé un mot de passe simple pour permettre à de nouveaux nœuds clients d'ajouter à l'index. Bien que la sécurité puisse être insuffisante à l'avenir, nous supposons un modèle altruiste pour notre version précoce.
À l'avenir, nous envisageons qu'il y ait une sécurité et des incitations en place, ce qui aligne les nœuds pour être honnête lors de la mise à jour de l'index. Ceux-ci peuvent être sous la forme de récompenses, de récompense, de réputation, etc., etc. Une façon de financer les récompenses aux nœuds honnêtes pourrait être en incorporant la publicité dans le protocole et permettre la délégué des frais de publicité aux nœuds qui entretiennent le réseau.
Notre version actuelle ne prend en charge que les fichiers PDF sur IPF à ajouter à l'index. À l'avenir, nous tenons à étendre cela à plus de types de fichiers et de répertoires, et de prendre en charge différents réseaux de stockage décentralisés. Enfin, nous visons à intégrer des données basées sur la blockchain telles que les contrats intelligents dans la recherche.
Nous présentons maintenant un aperçu des deux principales opérations de notre mécanisme.
La recherche commence par une requête par le client contenant un certain nombre de termes de recherche. Le client récupère ensuite le dernier TLI en résolvant le nom IPNS défini par la passerelle vers le CID correspondant. Ce TLI est ensuite récupéré et traversé pour vérifier si les mots clés ont KSI. Si tel est le cas, les KSI pertinents sont des requêtes, pour renvoyer le contenu qui contient les mots clés. Le client peut ensuite récupérer ces fichiers à partir du réseau.
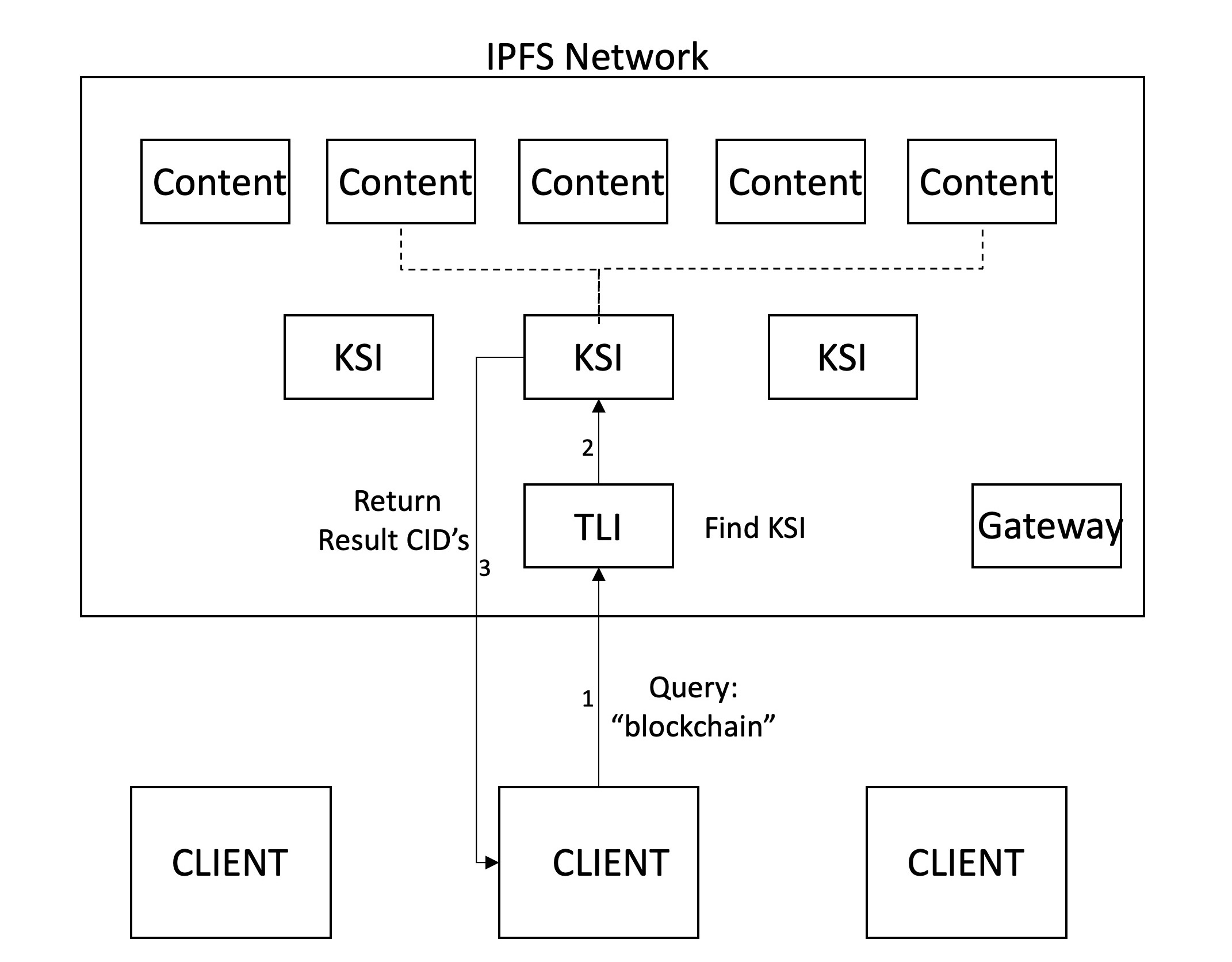
Un aspect important dans les moteurs de recherche est le mécanisme de classement. Cela se produit généralement de manière centralisée, sans beaucoup d'influence des clients. Bien que nous n'ayons pas mis en œuvre des mécanismes de classement sophistiqués, nous envisageons qu'il y ait un classement aux clients des résultats, ce qui leur donne plus de puissance et de transparence. Cela permet aux clients de contrôler les fonctions de classement et de les personnaliser en fonction des besoins spécifiques. À l'heure actuelle, notre mécanisme renvoie les résultats ordonnés sur la base des CID. Lorsque deux termes de recherche sont entrés, les pages où ces deux se produisent sont renvoyées en premier, après quoi les pages sont retournées qui ne contiennent qu'un seul des termes.
Un aspect important de tout moteur de recherche est l'ajout d'entrées à l'index. Ce processus implique un certain nombre d'étapes que nous décrivons ci-dessous.
La première décision à prendre est le contenu ajouté à l'index, que nous appelons la conservation . Dans les moteurs traditionnels, cela comprend tout le contenu Web public. Bien que cela atteigne des performances élevées, elle peut ajouter trop de frais généraux lorsqu'il est exécuté dans un réseau décentralisé. Une autre approche peut être une conservation basée sur le consensus du réseau sur un contenu important. Pour notre système actuel, nous permettons à toute personne qui croit que le contenu soit important pour l'ajouter au réseau. Le contenu peut être traité par les identificateurs CID, DNSLink, ENS ou IPNS.
Ensuite, ramper se produit, ce qui implique de récupérer et d'analyser des fichiers pour extraire des mots clés importants. Comme mentionné ci-dessus, notre système rampe lorsque quelqu'un décide de contenu doit être ajouté, et soumet donc manuellement le CID à ramper. À l'avenir, nous envisageons que cela se produise automatiquement lorsque le contenu est téléchargé ou visité sur le réseau. En plus d'extraire des mots clés, d'autres métadonnées peuvent être ajoutées. Nous utilisons actuellement le type de fichier (PDF) et l'horodatage lorsqu'il est rampé, mais dans l'intention future d'ajouter le titre, le compte, la taille, etc.
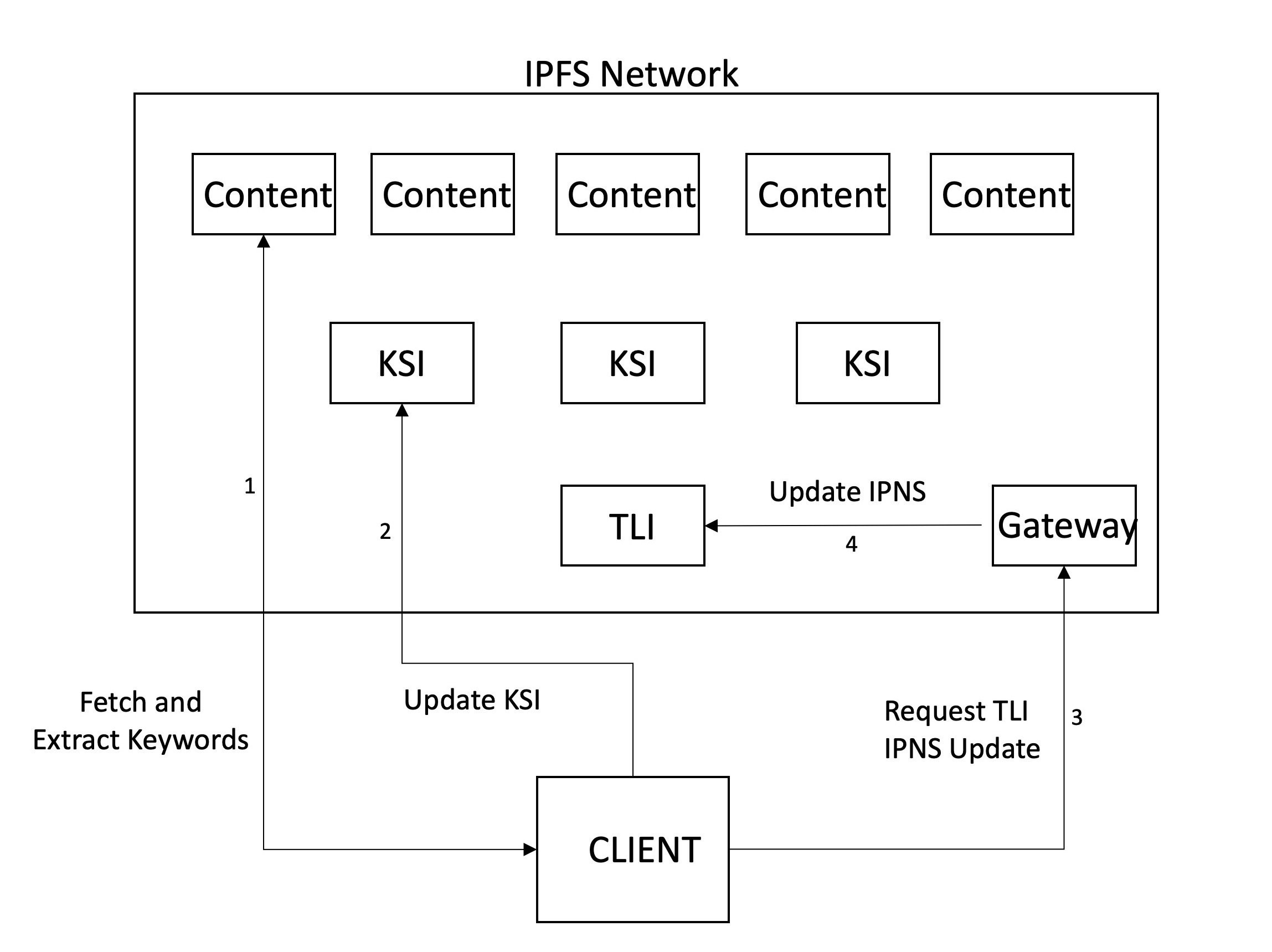
Après avoir extrait les mots clés (et produire le RWI), l'index doit être stocké. Pour le stockage, nous utilisons des IPF, car cela permet un stockage collaboratif décentralisé. Nous avons décidé de maintenir une hiérarchie à deux niveaux. Chaque mot-clé aura un fichier d'index associé (KSI) où les nœuds peuvent trouver le contenu contient ces mots clés. Un index séparé est conservé (TLI) pour pointer les identificateurs des KSI, et cela est publié sur un nom IPNS à partir de notre serveur Gateway. Lorsqu'un nœud met à jour les KSI après avoir rampé un fichier, ils mettent à jour le pointeur dans le TLI vers ces fichiers et demande la passerelle pour mettre à jour le pointeur que l'enregistrement IPNS résout. De cette façon, l'enregistrement IPNS pointe vers la dernière version du TLI, qui à son tour pointe vers les dernières versions des KSI.
À l'heure actuelle, les nœuds clients peuvent modifier le TLI s'ils possèdent un mot de passe, qui peut être obtenu auprès des responsables de ce projet. De cette façon, les entrées malveillantes potentielles sont moins probables. Les nœuds avec les mots de passe peuvent être considérés comme des «autorités» dans le réseau.
Au cours du développement et des tests, nous avons fait un certain nombre d'observations en ce qui concerne les performances. Comme notre solution repose fortement sur les IPF, nos performances aussi. Nous avons constaté que des retards importants peuvent se produire lorsque les nœuds n'ont pas ajouté le pair de la passerelle dans leur essaim de pairs. Bien que nous ayons ajouté cela à notre CLI, la connexion tombe encore de temps en temps. Bien que cela ne casse pas le système, il ajoute des retards.
De plus, la mise à jour de notre entrée IPNS à partir de la passerelle peut être très lente et peut devenir un goulot d'étranglement des performances lorsque le trafic de rampe augmente. Nous avons commencé à examiner les alternatives, mais nous laissons la mise en œuvre des versions futures. Une option consiste à utiliser le DNS pour stocker un pointeur vers le dernier enregistrement TLI, mais cela apporte un certain nombre de défis supplémentaires inhérents au DNS. Un registre de noms basé sur la blockchain tel que ENS peut également être utilisé, bien que des mises à jour fréquentes du contrat de résolveur puissent devenir une dépense importante.
Il existe plusieurs façons d'accéder à la recherche de Deece:
ClientLe logiciel client peut être utilisé par n'importe quel nœud exécutant des IPF et fournit une interface de ligne de commande simple.
NAME:
Deece - Decentralised search for IPFS
USAGE:
Deece [global options] command [command options] [arguments...]
VERSION:
0.0.1
AUTHORS:
Navin V. Keizer < [email protected] >
Puneet K. Bindlish < [email protected] >
COMMANDS:
search Performs a decentralised search on IPFS
crawl Crawls a page to add to the decentralised index
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--help, -h show help (default: false)
--version, -v print the version (default: false)
GatewayPour un accès facile et léger, nous avons implémenté une passerelle pour nos clients de recherche. Cela peut être trouvé sur: www.deece.nl/web/, et permet la recherche et les rampes sur le réseau en fonction des identifiants (CID).

Remarque: La passerelle est actuellement dépassée lors de la mise à niveau vers la version 2.
LibraryLa CLI et la passerelle s'exécutent à l'aide de notre package de recherche Deece pour Go. Nous l'avons publié, car cela peut être utilisé pour des intégrations et des extensions faciles.
D'autres instructions d'installation seront ajoutées une fois testées sur différentes plates-formes. Pour l'instant, nous avons fourni des instructions basées sur notre installation sur Linux.
Pour que la recherche Deece fonctionne, il existe un certain nombre d'exigences et de dépendances. Pour fonctionner en tant que client, un démon d'IPFS local doit être exécuté et pour accélérer les résultats, il aide à ajouter la passerelle en maintenant le TLI dans l'essaim de pairs. Pour soumettre des modifications au TLI en tant que client, un mot de passe est requis. Enfin, un fichier de configuration doit être présent dans le même répertoire que l'exécutable pour charger les résultats. Un fichier de configuration incomplet se trouve dans ce référentiel.
Pour exécuter le client, First IPFS, GO (testé pour la version 1.13.7, les versions plus récentes devraient fonctionner avec des modifications mineures) et GIT doit être installé.
Ensuite, nous devons installer à partir de la source:
git clone github.com/navinkeizer/DeeceLe prochain Tesseract-OCR doit être installé, ainsi que d'autres dépendances. Pour Linux, cela peut ressembler à ceci:
sudo apt-get install g++
sudo apt-get install autoconf automake libtool
sudo apt-get install autoconf-archive
sudo apt-get install pkg-config
sudo apt-get install libpng-dev
sudo apt-get install libjpeg8-dev
sudo apt-get install libtiff5-dev
sudo apt-get install zlib1g-dev
wget http://www.leptonica.org/source/leptonica-1.81.1.tar.gz
sudo tar xf leptonica-1.81.1.tar.gz
cd leptonica-1.81.1 &&
sudo ./configure &&
sudo apt install make
sudo make &&
sudo make install
sudo apt-get install tesseract-ocr # or sudo apt install tesseract-ocr
sudo apt install libtesseract-devD'autres packages GO pertinents peuvent alors être installés:
$ go get -t github.com/otiai10/gosseract
$ go get github.com/navinkeizer/Deece
$ go get github.com/ipfs/go-ipfs-api
$ go get github.com/wealdtech/go-ens/v3
$ go get github.com/otiai10/gosseract/v2
et la CLI construite:
$ sudo go build Deece/CLI/.
Et courir:
$ ./CLI [command] [arguments]
Le package peut également être utilisé comme bibliothèque.
go get github.com/navinkeizer/Deece
L'implémentation actuelle de la recherche Deece est toujours expérimentale et peut donc subir des instabilités. Comme décrit dans ce document, nous avons fait des hypothèses de simplification (altruisme) et axée sur les fonctionnalités limitées (PDF uniquement). En outre, la passerelle présente un aspect centralisé, qui à l'avenir devrait être remplacé par un consensus de réseau décentralisé, et le protocole devrait être garanti par des incitations.
Notre mise en œuvre adopte une première approche principale. Nous avons cherché à construire à partir de zéro, plutôt que de compter sur les approches et les solutions existantes pour les composants du système. Nous pensons que cela est nécessaire car les solutions existantes peuvent ne pas être optimales pour le contenu Web3 décentralisé. En d'autres termes, il y a beaucoup de travail à faire.
Actuellement, nous rencontrons occasionnellement des problèmes dans le processus rampant en raison de la mise à jour des mises à jour IPNS. Nous travaillons à résoudre ce problème avec des solutions alternatives.


