Deece
1.0.0

Die Deece -Suche ist ein offener, kollaborativer und dezentraler Suchmechanismus für IPFs. Jeder Knoten, der den Client ausführt, kann Inhalte auf IPFs kriechen und diesen dem Index hinzufügen, der selbst auf IPFs dezentral gespeichert wird. Dies ermöglicht eine dezentrale Suche nach dezentralen Inhalten.
Die aktuelle Implementierung ist immer noch sehr experimentell. Wir arbeiten an zukünftigen Versionen ohne zentrales Gateway und untersuchen alternative Suchmechanismen. Unser aktueller Server ist ausgefallen und das Projekt wurde nicht gewartet.
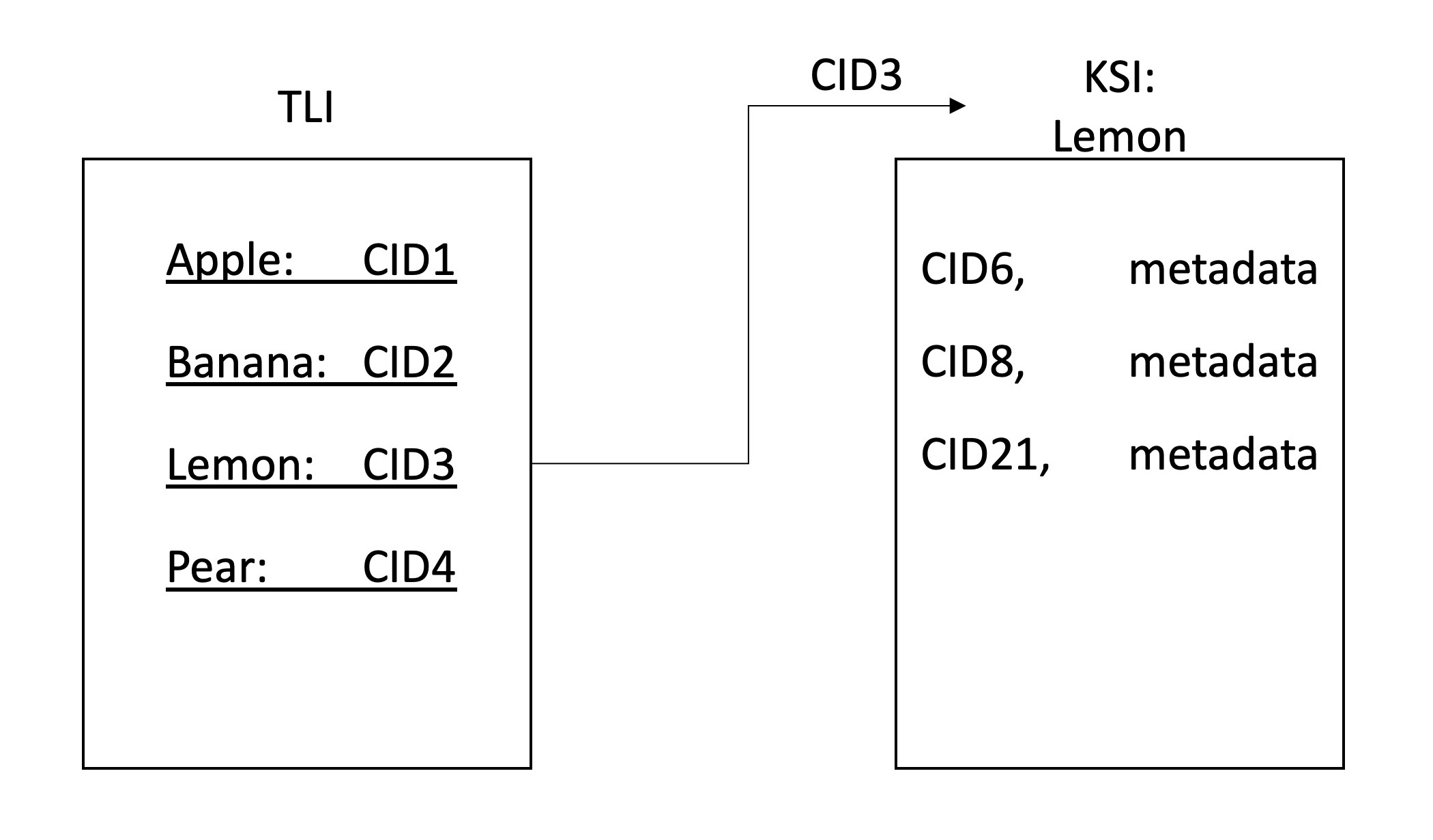
ClientGatewayLibraryDie DEECE -Suche ermöglicht eine dezentrale Suche nach IPFS -Daten. Dies wird durch ein Netzwerk von IPFS -Knoten erreicht, die am Kriechen und Indizieren der Daten im Netzwerk teilnehmen. Der Index ist auf IPFS gespeichert und in eine zweischichtige Hierarchie aufgeteilt, wobei der erste der oberste Index (TLI) und der zweite der Schlüsselwortspezifische Indizes (KSI) sind. Das TLI enthält die Kennungen (CID) für das KSI für jedes Schlüsselwort und wird ständig aktualisiert, wenn ein Knoten einen Crawl einreicht. Beim Kriechen fügen die Knoten dem aktuellen KSI eine Liste der Kennungen von Dateien hinzu, die dieses Schlüsselwort enthalten.
Die DEECE -Suche ermöglicht zwei spezifische Aktionen: search und crawl . Suchen Sie die neuesten TLI, die das KSI für jedes Schlüsselwort in der Benutzerabfrage finden, und holt dann die Ergebnisse aus diesen, die dem Benutzer angezeigt werden. Derzeit wird die Ergebnisse auf der Grundlage von CID bestellt, aber es sollten ausgefeiltere Mechanismen entwickelt werden. Wir ermöglichen kombinierte Ergebnisse für bis zu zwei Schlüsselwörter, die in Zukunft erweitert werden.
Derzeit gibt es drei Möglichkeiten, auf die Seece -Suche zugreifen zu können. Erstens gibt es die Client -Software, die eine Befehlszeilenschnittstelle verwendet. Zweitens haben wir einen Gateway -Dienst (www.deece.nl/web/) implementiert, der eine Instanz unseres Client -Knotens ausführt und es "leichte Clients" ermöglicht, mit der Suche zu interagieren, ohne andere Software zu installieren. Schließlich haben wir unseren Code veröffentlicht, der von der CLI und dem Gateway in Form einer Go -Bibliothek verwendet wird.
Die anfängliche Version der Deece Search basiert auf einem vertrauenswürdigen Knoten (demselben Knoten wie unser Gateway), um den IPNS -Datensatz zu aktualisieren, der auf die neueste Version des TLI zeigt. Wenn Clients kriechen, besteht der letzte Schritt darin, dass sie eine Aktualisierungsanforderung an diesen Server senden. Derzeit müssen die Clients ein Kennwort in ihrer Konfigurationsdatei angeben, das von den Wartenden erhalten werden kann, da Sicherheitsmaßnahmen später implementiert werden.
Derzeit haben Webbenutzer nur wenige Alternativen zu zentralisierten Suchmaschinen. Diese Motoren halten zentralisierte Kontrolle, Politik und Vertrauen beibehalten, was zu Fragen in Bezug auf Zensur, Datenschutzschutz und Transparenz führen kann.
Darüber hinaus konzentrieren diese Motoren ihre Bemühungen im Allgemeinen auf traditionelle Webinhalte (gehostet auf Webservern, auf die über die DNS zugegriffen wird). In einem Web3 -Paradigma, in dem Inhalte voraussichtlich in dezentralen Speichernetzwerken (z. B. IPFS) und Namensauflösung über Blockchain -Lösungen (z. B. ENS) stattfinden, ist eine alternative Suchmaschine erforderlich.
Kurz gesagt, ein Suchmechanismus ist erforderlich, der dezentrale Daten durchsucht und dies auf dezentrale Weise tut.
Es gibt eine Reihe vergleichbarer Projekte, die versucht haben, das Problem der Zentralisierung bei der Websuche zu lösen. Erstens gibt es Implementierungen und Vorschläge aus der Forschung für verteilte / dezentrale Suchmechanismen für die aktuellen Webdaten. Frühe Projekte umfassen Yacy, Faroo und Suche. In jüngerer Zeit zielt Pressearch darauf ab, eine kollaborative Suchmaschine mithilfe von Blockchain -Belohnungen für Anreize zu erstellen.
In ähnlicher Weise zielten eine Reihe von Arbeiten darauf ab, verteilte Suche nach P2P -Speichernetzwerken bereitzustellen. In jüngerer Zeit hat das Diagramm ein dezentrales Indexierungsprotokoll für Blockchain -Daten unter Verwendung von Kryptowährungsanreizen erstellt.
Keines der oben genannten Projekte erfasst jedoch unseren spezifischen Anwendungsfall einer dezentralen Suche nach dezentralen Web3 -Daten.
Unsere Architektur beruht auf einer Reihe von Client -Knoten, die gemeinsam den Index pflegen und hinzufügen und Suchvorgänge durchführen können. Wir haben den Ansatz, zuerst einen funktionierenden Protypen unserer Architektur zu beenden und inkrementell Funktionen hinzuzufügen. Daher stützt sich unsere aktuelle Version auf einen vertrauenswürdigen Knoten (Gateway), um den TLI -IPNS -Datensatz zu aktualisieren. Da keine zusätzliche Sicherheit oder Anreize implementiert sind, haben wir ein einfaches Kennwort verwendet, damit neue Client -Knoten dem Index hinzugefügt werden können. Während die Sicherheit in Zukunft möglicherweise nicht ausreicht, nehmen wir ein altruistisches Modell für unsere Frühstadienveröffentlichung an.
In Zukunft stellen wir uns vor, dass es zusätzliche Sicherheit und Anreize gibt, die Knoten ausrichten, um bei der Aktualisierung des Index ehrlich zu sein. Diese können in Form von Kryptocurreny Rewards, Slashing, Reputation usw. erfolgen. Eine Möglichkeit, Belohnungen an ehrliche Knoten zu finanzieren, können darin bestehen, dass Werbung in das Protokoll einbezieht und die Werbegebühren an die Knoten delegiert werden können, die das Netzwerk unterhalten.
Unsere aktuelle Version unterstützt nur PDF -Dateien auf IPFs, die dem Index hinzugefügt werden. In Zukunft möchten wir dies auf mehr Dateitypen und Verzeichnisse erweitern und verschiedene dezentrale Speichernetzwerke unterstützen. Schließlich wollen wir Blockchain -basierte Daten wie intelligente Verträge in die Suche einbeziehen.
Wir geben nun einen Überblick über die beiden Hauptoperationen in unserem Mechanismus.
Die Suche beginnt mit einer Abfrage durch den Client, der eine Reihe von Suchbegriffen enthält. Der Client holt dann den neuesten TLI, indem er den vom Gateway festgelegten IPNS -Namen zum entsprechenden CID auflöst. Dieser TLI wird dann abgerufen und durchquert, um zu überprüfen, ob die Schlüsselwörter KSI haben. Wenn dies der Fall ist, sind die relevanten KSI -Abfragen, um den Inhalt zurückzugeben, der die Schlüsselwörter enthält. Der Client kann diese Dateien dann aus dem Netzwerk abrufen.
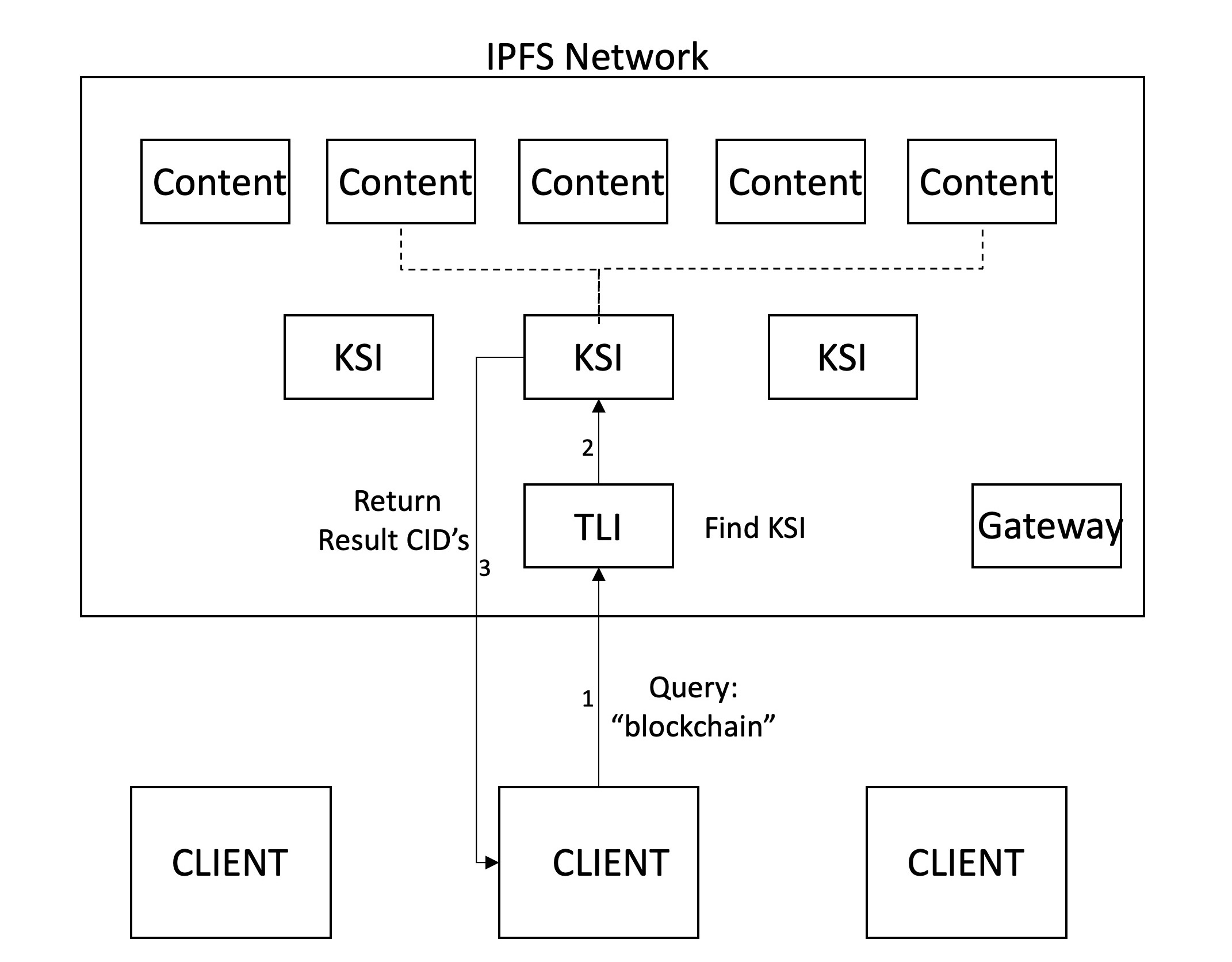
Ein wichtiger Aspekt in Suchmaschinen ist der Ranking -Mechanismus. Dies geschieht im Allgemeinen zentral, ohne dass die Kunden viel Einfluss haben. Obwohl wir keine ausgefeilten Ranking -Mechanismen implementiert haben, stellen wir uns vor, dass die Kunden der Ergebnisse rangieren, was ihnen mehr Leistung und Transparenz verleiht. Auf diese Weise können Kunden die Kontrolle über Ranking -Funktionen haben und diese basierend auf bestimmten Bedürfnissen personalisieren. Gegenwärtig rendite unser Mechanismus geordnete Ergebnisse auf der Grundlage von CIDs zurück. Wenn zwei Suchbegriffe eingegeben werden, werden die Seiten, auf denen beide stattfinden, zuerst zurückgegeben. Danach werden die Seiten zurückgegeben, die nur einen der Begriffe enthalten.
Ein wichtiger Aspekt einer Suchmaschine ist die Hinzufügung von Einträgen zum Index. Dieser Prozess umfasst eine Reihe von Schritten, die wir unten beschreiben.
Die erste Entscheidung ist, welche Inhalte dem Index hinzugefügt werden, den wir Curation bezeichnen. In traditionellen Motoren umfasst dies alle öffentlichen Webinhalte. Obwohl dies eine hohe Leistung erzielt, kann es zu viel Overhead hinzufügen, wenn es in einem dezentralen Netzwerk ausgeführt wird. Ein anderer Ansatz kann eine Kuration sein, die auf dem Netzwerkkonsens wichtiger Inhalte basiert. Für unser aktuelles System erlauben wir jedem, der den Inhalt für wichtig ist, dies dem Netzwerk hinzuzufügen. Der Inhalt kann durch CID-, DNSLINK-, ENS- oder IPNS -Kennungen behandelt werden.
Als nächstes kommt es zu einem Krabbeln, bei dem Dateien abgerufen und analysiert werden, um wichtige Schlüsselwörter zu extrahieren. Wie oben erwähnt, kriecht unser System, wenn jemand entscheidet, dass Inhalte hinzugefügt werden sollten, und setzt somit die CID manuell ein, um es zu krochet. In Zukunft stellen wir uns vor, dass dies automatisch geschieht, wenn der Inhalt im Netzwerk hochgeladen oder besucht wird. Neben dem Extrahieren von Schlüsselwörtern können andere Metadaten hinzugefügt werden. Wir verwenden derzeit den Dateityp (PDF) und den Zeitstempel, wenn wir krabbeln, aber in zukünftiger Absicht, Titel, Zählung, Größe usw. hinzuzufügen, usw.
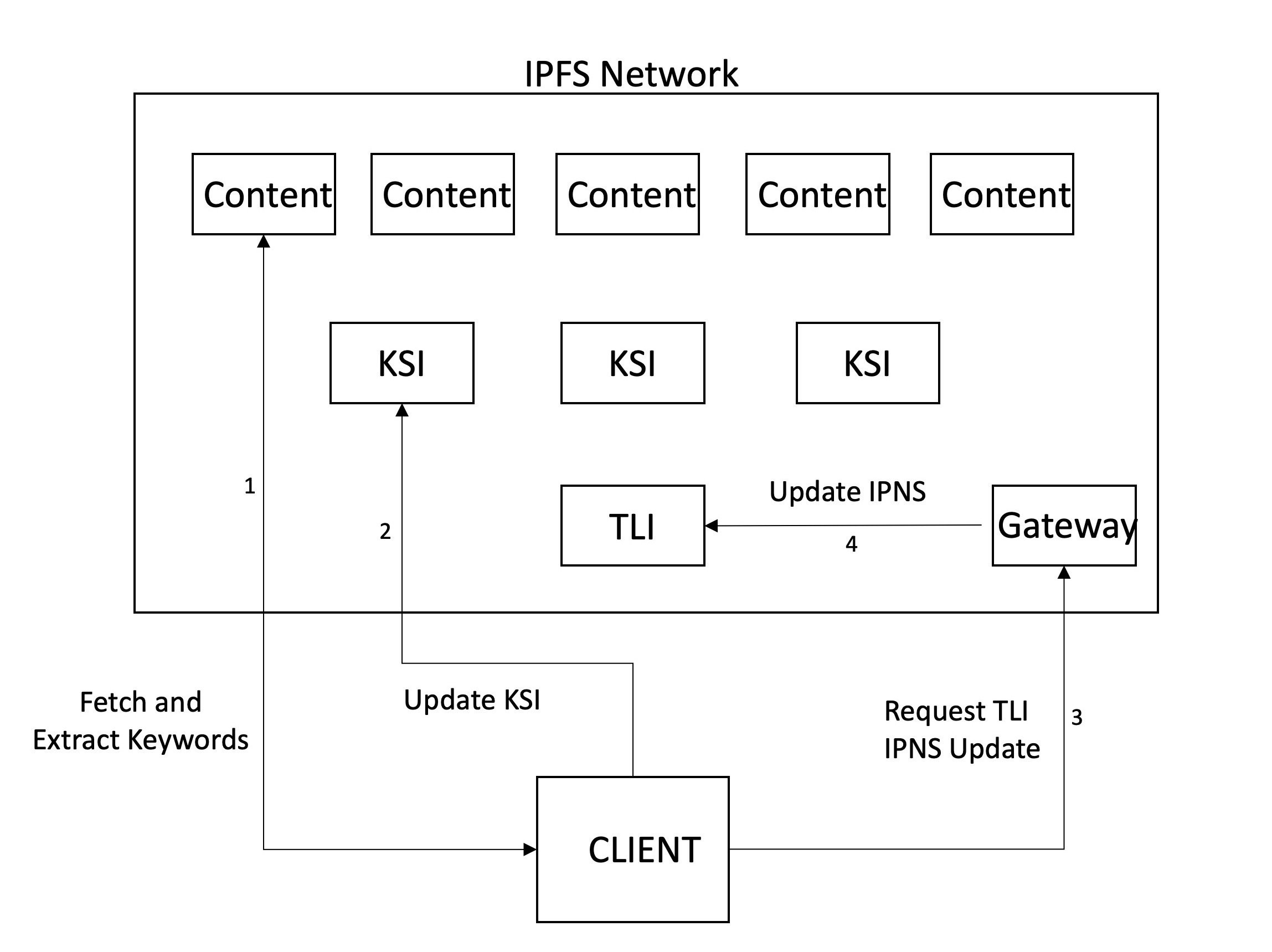
Nach dem Extrahieren der Schlüsselwörter (und der Erzeugung des RWI) muss der Index gespeichert werden. Für die Speicherung verwenden wir IPFs, da dies eine dezentrale kollaborative Speicherung ermöglicht. Wir haben beschlossen, eine zweistufige Hierarchie aufrechtzuerhalten. Jedes Schlüsselwort verfügt über eine zugehörige Indexdatei (KSI), in der Knoten herausfinden können, welcher Inhalt diese Schlüsselwörter enthält. Ein separater Index wird (TLI) aufbewahrt, um auf die Kennungen der KSI zu verweisen, und dies wird von unserem Gateway -Server in einem IPNS -Namen veröffentlicht. Wenn ein Knoten die KSI nach dem Krabbeln einer Datei aktualisiert, aktualisiert er den Zeiger in den TLI auf diese Dateien und fordert das Gateway an, den Zeiger zu aktualisieren, auf den der IPNS -Datensatz beherrscht. Auf diese Weise verweist der IPNS -Rekord auf die neueste Version des TLI, was wiederum auf die neuesten Versionen der KSI zeigt.
Gegenwärtig können Clientknoten die TLI ändern, wenn sie ein Passwort besitzen, das von den Betreuern dieses Projekts erhalten werden kann. Auf diese Weise sind potenzielle böswillige Einträge weniger wahrscheinlich. Knoten mit den Passwörtern können als "Behörden" im Netzwerk angesehen werden.
Während der Entwicklung und Tests haben wir eine Reihe von Beobachtungen in Bezug auf die Leistung gemacht. Da unsere Lösung stark auf IPFs abhängt, ist dies auch unsere Leistung. Wir fanden heraus, dass erhebliche Verzögerungen auftreten können, wenn Knoten den Peer -Peer in ihrem Peers nicht hinzugefügt haben. Während wir dies zu unserer CLI hinzugefügt haben, fällt die Verbindung gelegentlich immer noch ab. Während dies das System nicht durchbricht, fügt es Verzögerungen hinzu.
Darüber hinaus kann die Aktualisierung unseres IPNS -Eintrags aus dem Gateway sehr langsam sein und kann zu einem Leistungs Engpass werden, wenn der Kriechverkehr zunimmt. Wir haben mit Alternativen begonnen, aber die Implementierung zukünftigen Veröffentlichungen überlassen. Eine Möglichkeit besteht darin, den DNS zu verwenden, um einen Zeiger auf den neuesten TLI -Datensatz zu speichern. Dies bringt jedoch eine Reihe zusätzlicher Herausforderungen, die dem DNS innewohnt. Eine Blockchain -basierte Namensregistrierung wie ENS kann auch verwendet werden, obwohl häufige Aktualisierungen des Resolver -Vertrags zu einem großen Aufwand werden können.
Es gibt eine Reihe von Möglichkeiten, um auf DECE -Suche zugreifen zu können:
ClientDie Client -Software kann von jedem Knoten verwendet werden, der IPFS ausführt, und bietet eine einfache Befehlszeilenschnittstelle.
NAME:
Deece - Decentralised search for IPFS
USAGE:
Deece [global options] command [command options] [arguments...]
VERSION:
0.0.1
AUTHORS:
Navin V. Keizer < [email protected] >
Puneet K. Bindlish < [email protected] >
COMMANDS:
search Performs a decentralised search on IPFS
crawl Crawls a page to add to the decentralised index
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--help, -h show help (default: false)
--version, -v print the version (default: false)
GatewayFür einen einfachen und leichten Zugriff haben wir ein Gateway für unsere Suchkunden implementiert. Dies finden Sie unter: www.deece.nl/web/ und ermöglicht Such- und Kriechen im Netzwerk basierend auf Kennungen (CIDs).

HINWEIS: Das Gateway ist derzeit suspendiert, während er auf Version 2 aktualisiert wird.
LibrarySowohl das CLI als auch das Gateway laufen mit unserem Deec -Suchpaket für GO. Wir haben dies veröffentlicht, da dies für einfache Integrationen und Erweiterungen verwendet werden kann.
Weitere Installationsanweisungen werden hinzugefügt, sobald auf verschiedenen Plattformen getestet wurde. Derzeit haben wir Anweisungen anhand unserer Installation unter Linux gegeben.
Damit die DEACE -Suche zur Arbeit zur Arbeit ist, gibt es eine Reihe von Anforderungen und Abhängigkeiten. Um als Kunde zu laufen, muss ein lokaler IPFS -Daemon ausgeführt werden. Um die Ergebnisse zu beschleunigen, können Sie das Gateway hinzufügen, wodurch die TLI im Peer -Schwarm aufrechterhalten wird. Um Änderungen an der TLI als Client einzureichen, ist ein Passwort erforderlich. Schließlich muss eine Konfigurationsdatei im selben Verzeichnis wie die ausführbare Datei zum Laden von Ergebnissen vorhanden sein. Eine unvollständige Konfigurationsdatei finden Sie in diesem Repository.
Um den Client auszuführen, werden erste IPFS, GO (getestet für Version 1.13.7, neuere Versionen sollten mit geringfügigen Änderungen funktionieren) und Git muss installiert werden.
Als nächstes müssen wir aus Quelle installieren:
git clone github.com/navinkeizer/DeeceDer nächste Tesseract-OCR muss sowohl installiert werden als auch andere Abhängigkeiten. Für Linux kann dies so aussehen:
sudo apt-get install g++
sudo apt-get install autoconf automake libtool
sudo apt-get install autoconf-archive
sudo apt-get install pkg-config
sudo apt-get install libpng-dev
sudo apt-get install libjpeg8-dev
sudo apt-get install libtiff5-dev
sudo apt-get install zlib1g-dev
wget http://www.leptonica.org/source/leptonica-1.81.1.tar.gz
sudo tar xf leptonica-1.81.1.tar.gz
cd leptonica-1.81.1 &&
sudo ./configure &&
sudo apt install make
sudo make &&
sudo make install
sudo apt-get install tesseract-ocr # or sudo apt install tesseract-ocr
sudo apt install libtesseract-devAndere relevante GO -Pakete können dann installiert werden:
$ go get -t github.com/otiai10/gosseract
$ go get github.com/navinkeizer/Deece
$ go get github.com/ipfs/go-ipfs-api
$ go get github.com/wealdtech/go-ens/v3
$ go get github.com/otiai10/gosseract/v2
und die CLI gebaut:
$ sudo go build Deece/CLI/.
und rennen:
$ ./CLI [command] [arguments]
Das Paket kann auch als Bibliothek verwendet werden.
go get github.com/navinkeizer/Deece
Die aktuelle Implementierung der DEECE -Suche ist immer noch experimentell und kann daher Instabilitäten erleben. Wie in diesem Dokument beschrieben, haben wir vereinfachende Annahmen (Altruismus) vereinfacht und uns auf begrenzte Funktionen (nur PDF) konzentriert. Darüber hinaus präsentiert das Gateway einen zentralisierten Aspekt, der in Zukunft durch den dezentralen Netzwerkkonsens ersetzt werden sollte, und das Protokoll sollte durch Anreize gesichert werden.
Unsere Implementierung verfolgt einen ersten Prinzip -Ansatz. Wir wollten uns von Grund auf aufbauen, anstatt uns auf vorhandene Ansätze und Lösungen für Systemkomponenten zu verlassen. Wir glauben, dass dies notwendig ist, da vorhandene Lösungen für dezentrale Web3 -Inhalte möglicherweise nicht optimal sind. Mit anderen Worten, es gibt viel zu tun.
Derzeit haben wir gelegentlich Probleme im Crawling -Prozess, da das Timing von IPNS -Updates ausgeführt wird. Wir arbeiten daran, dies mit alternativen Lösungen zu lösen.


