rag experiment accelerator
1.0.0
O Accelerator de Experiência de RAG é uma ferramenta versátil que ajuda a realizar experimentos e avaliações usando o padrão de pesquisa e pano de IA do Azure. Este documento fornece um guia abrangente que abrange tudo o que você precisa saber sobre essa ferramenta, como seu objetivo, recursos, instalação, uso e muito mais.
O principal objetivo do acelerador do experimento com trapos é tornar mais fácil e mais rápido executar experimentos e avaliações de consultas de pesquisa e qualidade da resposta do OpenAI. Esta ferramenta é útil para pesquisadores, cientistas de dados e desenvolvedores que desejam:
18 de março de 2024: a amostragem de conteúdo foi adicionada. Essa funcionalidade permitirá que o conjunto de dados seja amostrado por uma porcentagem especificada. Os dados são agrupados pelo conteúdo e, em seguida, a porcentagem de amostra é obtida em cada cluster para tentar a distribuição uniforme dos dados amostrados.
Isso é feito para garantir resultados representativos na amostra que se passaria pelo conjunto de dados inteiro.
Nota : Recomenda -se reconstruir seu ambiente se você já usou essa ferramenta antes devido a novas dependências.
O Accelerator de Experiência do RAG é orientado a Config e oferece um rico conjunto de recursos para apoiar seu objetivo:
Configuração do experimento : você pode definir e configurar experimentos especificando uma variedade de parâmetros do mecanismo de pesquisa, tipos de pesquisa, conjuntos de consultas e métricas de avaliação.
Integração : integra -se perfeitamente à pesquisa do Azure AI, Azure Machine Learning, MLFlow e Azure OpenAI.
Índice de Pesquisa Rica : Cria vários índices de pesquisa com base nas configurações de hiperparameter disponíveis no arquivo de configuração.
Múltiplas carregadores de documentos : a ferramenta suporta vários carregadores de documentos, incluindo o carregamento via inteligência de documentos do Azure e carregadores básicos de Langchain. Isso oferece a flexibilidade de experimentar diferentes métodos de extração e avaliar sua eficácia.
Carregador de inteligência de documentos personalizados : Ao selecionar o modelo de API 'pré-construído' para inteligência de documentos, a ferramenta utiliza um carregador de inteligência de documentos personalizado para carregar os dados. Esse carregador personalizado suporta formatação de tabelas com cabeçalhos de coluna em pares de valor-chave (para melhorar a legibilidade para o LLM), exclui partes irrelevantes do arquivo para o LLM (como números de página e rodapés), remove padrões recorrentes no arquivo usando regex e mais. Como cada linha da tabela é transformada em uma linha de texto, para evitar quebrar uma linha no meio, o Chunking é feito recursivamente por parágrafo e linha. O carregador personalizado recorda ao modelo de API 'pré-construído' mais simples como um fallback quando o 'layout pré-construído' falha. Qualquer outro modelo de API utilizará a implementação de Langchain, que retornará a resposta bruta da API da Document Intelligence.
Geração de consultas : A ferramenta pode gerar uma variedade de conjuntos de consultas diversas e personalizáveis, que podem ser adaptadas para necessidades específicas de experimentação.
Vários tipos de pesquisa : ele suporta vários tipos de pesquisa, incluindo texto puro, vetor puro, vetor cruzado, multi-vetor, híbrido e muito mais. Isso oferece a capacidade de realizar análises abrangentes sobre recursos e resultados de pesquisa.
Sub-inquilino : o padrão avalia a consulta do usuário e, se achar complexa o suficiente, ele o divide em sub-inter-questões menores para gerar contexto relevante.
Reanking : as respostas de consulta da pesquisa do Azure AI são reavaliadas usando o LLM e classificadas de acordo com a relevância entre a consulta e o contexto.
Métricas e avaliação : suporta métricas de ponta a ponta comparando as respostas geradas (reais) com as respostas da verdadeira-verdade (esperada), incluindo métricas de distância baseada em distância, cosseno e similaridade semântica. Ele também inclui métricas baseadas em componentes para avaliar o desempenho da recuperação e da geração usando o LLMS como juízes, como recall de contexto ou relevância de resposta, bem como métricas de recuperação para avaliar os resultados da pesquisa (por exemplo, mapa@k).
Geração de relatórios : O Accelerador de Experiência de RAG automatiza o processo de geração de relatórios, completa com visualizações que facilitam a análise e a compartilhamento de descobertas do experimento.
Multi-Linguual : a ferramenta suporta analisadores de idiomas para suporte linguístico em idiomas individuais e analisadores especializados (idiomas-agnóticos) para padrões definidos pelo usuário nos índices de pesquisa. Para mais informações, consulte Tipos de analisadores.
Amostragem : se você tiver um conjunto de dados grande e/ou deseja acelerar a experimentação, um processo de amostragem estará disponível para criar uma amostra pequena, mas representativa, dos dados para a porcentagem especificada. Os dados serão agrupados pelo conteúdo e uma porcentagem de cada cluster será selecionada como parte da amostra. Os resultados obtidos devem ser aproximadamente indicativos do conjunto de dados completo dentro de uma margem de ~ 10%. Depois que uma abordagem é identificada, a execução do conjunto de dados completa é recomendada para obter resultados precisos.
No momento, o acelerador do experimento com trapos pode ser executado localmente alavancando um dos seguintes:
O uso de um contêiner de desenvolvimento significa que todo o software necessário está instalado para você. Isso exigirá WSL. Para mais informações sobre os contêineres de desenvolvimento, visite contêineres.dev
Instale o seguinte software na máquina host, você executará a implantação de:
- Para Windows - Windows Store Ubuntu 22.04.3 LTS
- Docker Desktop
- Código do Visual Studio
- VS Extensão de Código: Contos de Remoto
Mais orientações para a criação de WSL podem ser encontradas aqui. Agora você tem os pré -requisitos, você pode:
git clone https://github.com/microsoft/rag-experiment-accelerator.git
code .Uma vez que o projeto seja aberto no vscode, ele deve perguntar se você deseja "reabrir isso em um contêiner de desenvolvimento". Diga sim.
É claro que você pode executar o Accelerador de Experiência RAG em uma máquina Windows/Mac, se quiser; Você é responsável por instalar as ferramentas corretas. Siga estas etapas de instalação:
git clone https://github.com/microsoft/rag-experiment-accelerator.gitconda create -n rag-experiment python=3.11
conda init bashFeche seu terminal, abra um novo e corra:
conda activate rag-experiment
pip install .az login
az account set --subscription= " <your_subscription_guid> "
az account showExistem 3 opções para instalar todos os serviços do Azure necessários:
Este projeto suporta o desenvolvedor do Azure CLI.
azd provisionazd up se preferir, pois isso chama azd provision de qualquer maneira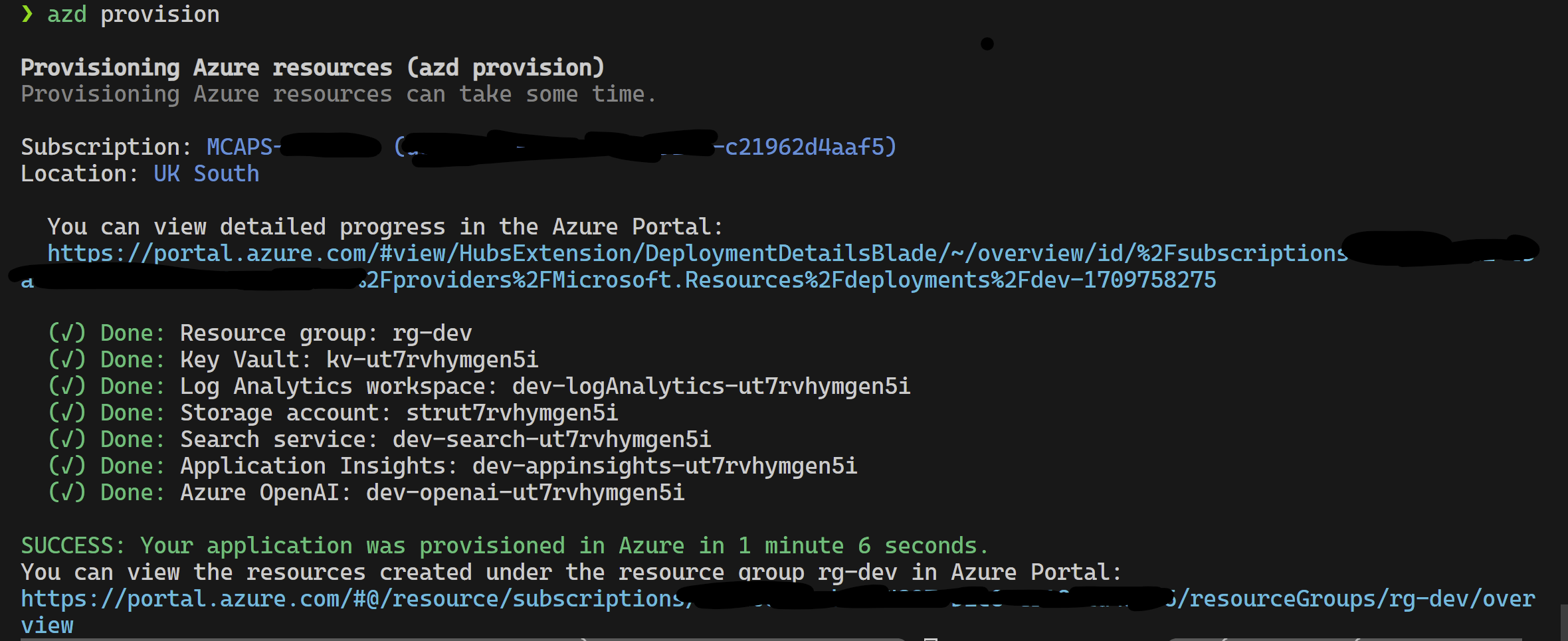
Depois que isso estiver concluído, você poderá usar a configuração de lançamento para ser executada ou depurar as 4 etapas e o ambiente atual provisionado pelo azd será carregado com os valores corretos.
Se você deseja implantar a infraestrutura do modelo, também pode clicar aqui:
Se você não quiser usar azd também pode usar a az CLI normal.
Use o seguinte comando para implantar.
az login
az deployment sub create --subscription < subscription-id > --location < location > --template-file infra/main.bicepOu
Para implantar com o uso de rede isolado seguindo o comando. Substitua os valores dos parâmetros pelas especificidades da sua rede isolada. Você deve fornecer todos os três parâmetros (ou seja, vnetAddressSpace , proxySubnetAddressSpace e subnetAddressSpace ) se desejar implantar para uma rede isolada.
az login
az deployment sub create --location < location > --template-file infra/main.bicep
--parameters vnetAddressSpace= < vnet-address-space >
--parameters proxySubnetAddressSpace= < proxy-subnet-address-space >
--parameters subnetAddressSpace= < azure-subnet-address-space >Aqui está um exemplo com valores de parâmetros:
az deployment sub create --location uksouth --template-file infra/main.bicep
--parameters vnetAddressSpace= ' 10.0.0.0/16 '
--parameters proxySubnetAddressSpace= ' 10.0.1.0/24 '
--parameters subnetAddressSpace= ' 10.0.2.0/24 ' Para usar o Accelerador de Experiência RAG localmente, siga estas etapas:
Copie o arquivo .env.template fornecido para um arquivo chamado .env e atualize todos os valores necessários. Muitos dos valores necessários para o arquivo .env virão de recursos que foram configurados anteriormente e/ou podem ser coletados a partir de recursos provisionados na seção de infraestrutura de provisão. Observe também, por padrão, LOGGING_LEVEL está definido como INFO , mas pode ser alterado para qualquer um dos seguintes níveis: NOTSET , DEBUG , INFO , WARN , ERROR , CRITICAL .
cp .env.template .env
# change parameters manually Copie o arquivo config.sample.json fornecido para um arquivo chamado config.json e altere qualquer hiperparâmetro para adaptar ao seu experimento.
cp config.sample.json config.json
# change parameters manually Copie todos os arquivos para ingestão (PDF, HTML, Markdown, Text, JSON ou DOCX Format) na pasta data .
Execute 01_index.py (python 01_index.py) para criar índices de pesquisa de IA do Azure e carregar dados neles.
python 01_index.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " Execute 02_qa_generation.py (python 02_qa_generation.py) para gerar pares de perguntas-respostas usando o Azure OpenAI.
python 02_qa_generation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " Execute 03_querying.py (Python 03_Querying.py) para consultar a pesquisa do Azure AI para gerar contexto, re-classificar itens no contexto e obter resposta do Azure OpenAI usando o novo contexto.
python 03_querying.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " Execute 04_evaluation.py (python 04_evaluation.py) para calcular métricas usando vários métodos e gerar gráficos e relatórios no Azure Machine Learning usando a integração do MLFlow.
python 04_evaluation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " Como alternativa, você pode executar as etapas acima (além de 02_qa_generation.py ) usando um pipeline do Azure ML. Para fazer isso, siga o guia aqui.
A amostragem será executada localmente para criar uma fatia pequena, mas representativa, dos dados. Isso ajuda na rápida experimentação e mantém os custos baixos. Os resultados obtidos devem ser aproximadamente indicativos do conjunto de dados completo dentro de uma margem de ~ 10%. Depois que uma abordagem é identificada, a execução do conjunto de dados completa é recomendada para obter resultados precisos.
NOTA : A amostragem só pode ser executada localmente, nesta fase, não é suportada em um cluster de computação AML distribuído. Portanto, o processo seria executar a amostragem localmente e usar o conjunto de dados de amostra gerado para ser executado na AML.
Se você possui um conjunto de dados muito grande e deseja executar uma abordagem semelhante para amostrar os dados, pode usar a implementação distribuída na memória do Pyspark no kit de ferramentas Data Discovery para Microsoft Fabric ou Azure Synapse Analytics.
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"only_run_sampling" : " If set to true, this will only run the sampling step and will not create an index or any subsequent steps, use this if you want to build a small sampled dataset to run in AML " ,
"sample_percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 " ,
},O processo de amostragem produzirá os seguintes artefatos no diretório de amostragem:
job_name que contém o subconjunto de arquivos amostrados, eles podem ser especificados como --data_dir argumento ao executar todo o processo na AML.
"optimum_k": auto Config estiver definido como automático, o processo de amostragem tentará definir o número ideal de clusters automaticamente. Isso pode ser substituído se você souber aproximadamente quantos baldes amplos de conteúdo existem em seus dados. Um gráfico de cotovelo será gerado na pasta de amostragem. 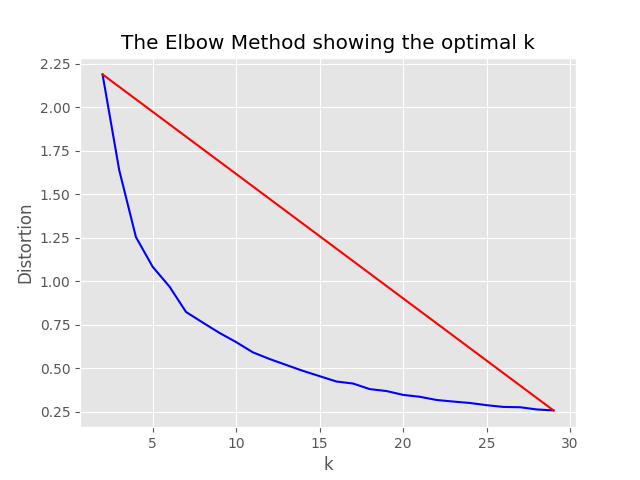
Existem duas opções para a amostragem em execução, a saber:
Defina os seguintes valores para executar o processo de indexação localmente:
"sampling" : {
"sample_data" : true ,
"only_run_sampling" : false ,
"sample_percentage" : 10 ,
"optimum_k" : auto,
"min_cluster" : 2 ,
"max_cluster" : 30
}, Se only_run_sampling o valor de configuração de configuração for definido como true, isso executará apenas a etapa de amostragem, nenhum índice será criado e quaisquer outras etapas subsequentes não serão executadas. Defina o argumento --data_dir como diretório criado pelo processo de amostragem que será:
artifacts/sampling/config.[job_name] e execute a etapa do pipeline da AML.
Todos os valores podem ser listas de elementos. Incluindo as configurações aninhadas. Cada matriz produzirá as combinações de configurações planas quando o método flatten() é chamado em um nó específico, para selecionar 1 combinação aleatória - chame a sample() .
{
"experiment_name" : " If provided, this will be the experiment name in Azure ML and it will group all job run under the same experiment, otherwise (if left empty) index_name_prefix will be used and there may be more than one experiment " ,
"job_name" : " If provided, all jobs runs in Azure ML will be named with this property value plus timestamp, otherwise (if left empty) each job with be named only with timestamp " ,
"job_description" : " You may provide a description for the current job run which describes in words what you are about to experiment with " ,
"data_formats" : " Specifies the supported data formats for the application. You can choose from a variety of formats such as JSON, CSV, PDF, and more. [*] - means all formats included " ,
"main_instruction" : " Defines the main instruction prompt coming with queries to LLM " ,
"use_checkpoints" : " A boolean. If true, enables use of checkpoints to load data and skip processing that was already done in previous executions. " ,
"index" : {
"index_name_prefix" : " Search index name prefix " ,
"ef_construction" : " ef_construction value determines the value of Azure AI Search vector configuration. " ,
"ef_search" : " ef_search value determines the value of Azure AI Search vector configuration. " ,
"chunking" : {
"preprocess" : " A boolean. If true, preprocess documents, split into smaller chunks, embed and enrich them, and finally upload documents chunks for retrieval into Azure Search Index. " ,
"chunk_size" : " Size of each chunk e.g. [500, 1000, 2000] " ,
"overlap_size" : " Overlap Size for each chunk e.g. [100, 200, 300] " ,
"generate_title" : " A boolean. If true, a title is generated for the chunk of content and an embedding is created for it " ,
"generate_summary" : " A boolean. If true, a summary is generated for the chunk of content and an embedding is created for it " ,
"override_content_with_summary" : " A boolean. If true, The chunk content is replaced with its summary " ,
"chunking_strategy" : " determines the chunking strategy. Valid values are 'azure-document-intelligence' or 'basic' " ,
"azure_document_intelligence_model" : " represents the Azure Document Intelligence Model. Used when chunking strategy is 'azure-document-intelligence'. When set to 'prebuilt-layout', provides additional features (see above) "
},
"embedding_model" : " see 'Description of embedding models config' below " ,
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 "
}
},
"language" : {
"analyzer" : {
"analyzer_name" : " name of the analyzer to use for the field. This option can be used only with searchable fields and it can't be set together with either searchAnalyzer or indexAnalyzer. " ,
"index_analyzer_name" : " name of the analyzer used at indexing time for the field. This option can be used only with searchable fields. It must be set together with searchAnalyzer and it cannot be set together with the analyzer option. " ,
"search_analyzer_name" : " name of the analyzer used at search time for the field. This option can be used only with searchable fields. It must be set together with indexAnalyzer and it cannot be set together with the analyzer option. This property cannot be set to the name of a language analyzer; use the analyzer property instead if you need a language analyzer. " ,
"char_filters" : " The character filters for the index " ,
"tokenizers" : " The tokenizers for the index " ,
"token_filters" : " The token filters for the index "
},
"query_language" : " The language of the query. Possible values: en-us, en-gb, fr-fr etc. "
},
"rerank" : {
"enabled" : " determines if search results should be re-ranked. Value values are TRUE or FALSE " ,
"type" : " determines the type of re-ranking. Value values are llm or cross_encoder " ,
"llm_rerank_threshold" : " determines the threshold when using llm re-ranking. Chunks with rank above this number are selected in range from 1 - 10. " ,
"cross_encoder_at_k" : " determines the threshold when using cross-encoding re-ranking. Chunks with given rank value are selected. " ,
"cross_encoder_model" : " determines the model used for cross-encoding re-ranking step. Valid value is cross-encoder/stsb-roberta-base "
},
"search" : {
"retrieve_num_of_documents" : " determines the number of chunks to retrieve from the search index " ,
"search_type" : " determines the search types used for experimentation. Valid value are search_for_match_semantic, search_for_match_Hybrid_multi, search_for_match_Hybrid_cross, search_for_match_text, search_for_match_pure_vector, search_for_match_pure_vector_multi, search_for_match_pure_vector_cross, search_for_manual_hybrid. e.g. ['search_for_manual_hybrid', 'search_for_match_Hybrid_multi','search_for_match_semantic'] " ,
"search_relevancy_threshold" : " the similarity threshold to determine if a doc is relevant. Valid ranges are from 0.0 to 1.0 "
},
"query_expansion" : {
"expand_to_multiple_questions" : " whether the system should expand a single question into multiple related questions. By enabling this feature, you can generate a set of alternative related questions that may improve the retrieval process and provide more accurate results " .,
"query_expansion" : " determines if query expansion feature is on. Value values are TRUE or FALSE " ,
"hyde" : " this feature allows you to experiment with various query expansion approaches which may improve the retrieval metrics. The possible values are 'disabled' (default), 'generated_hypothetical_answer', 'generated_hypothetical_document_to_answer' reference article - Precise Zero-Shot Dense Retrieval without Relevance Labels (HyDE - Hypothetical Document Embeddings) - https://arxiv.org/abs/2212.10496 " ,
"min_query_expansion_related_question_similarity_score" : " minimum similarity score in percentage between LLM generated related queries to the original query using cosine similarly score. default 90% "
},
"openai" : {
"azure_oai_chat_deployment_name" : " determines the Azure OpenAI deployment name " ,
"azure_oai_eval_deployment_name" : " determines the Azure OpenAI deployment name used for evaluation " ,
"temperature" : " determines the OpenAI temperature. Valid value ranges from 0 to 1. "
},
"eval" : {
"metric_types" : " determines the metrics used for evaluation (end-to-end or component-wise metrics using LLMs). Valid values for end-to-end metrics are lcsstr, lcsseq, cosine, jaro_winkler, hamming, jaccard, levenshtein, fuzzy_score, cosine_ochiai, bert_all_MiniLM_L6_v2, bert_base_nli_mean_tokens, bert_large_nli_mean_tokens, bert_large_nli_stsb_mean_tokens, bert_distilbert_base_nli_stsb_mean_tokens, bert_paraphrase_multilingual_MiniLM_L12_v2. Valid values for component-wise LLM-based metrics are llm_answer_relevance, llm_context_precision and llm_context_recall. e.g ['fuzzy_score','bert_all_MiniLM_L6_v2','cosine_ochiai','bert_distilbert_base_nli_stsb_mean_tokens', 'llm_answer_relevance'] " ,
}
}Nota: Ao alterar a configuração, lembre -se de mudar:
config.sample.json (a configuração de exemplo a ser copiada por outros) embedding_model é uma matriz que contém a configuração para os modelos de incorporação usarem. A incorporação type de modelo deve ser azure para modelos do Azure OpenAi e sentence-transformer para os modelos de transformadores de sentenças Huggingface.
{
"type" : " azure " ,
"model_name" : " the name of the Azure OpenAI model " ,
"dimension" : " the dimension of the embedding model. For example, 1536 which is the dimension of text-embedding-ada-002 "
} Se você estiver usando um modelo que não seja text-embedding-ada-002 , deve especificar a dimensão correspondente para o modelo no campo dimension ; por exemplo:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 3072
}As dimensões para os diferentes modelos de incorporação do Azure Openai podem ser encontradas na documentação dos modelos de serviço do Azure Openai.
Ao usar os modelos de incorporação mais recentes (V3), você também pode aproveitar o suporte para encurtar as incorporações. Nesse caso, especifique o número de dimensões que você precisa e adicione o sinalizador shorten_dimensions para indicar que deseja reduzir as incorporações. Por exemplo:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 256 ,
"shorten_dimensions" : true
}{
"type" : " sentence-transformer " ,
"model_name" : " the name of the sentence transformer model " ,
"dimension" : " the dimension of the model. This field is not required if model name is one of ['all-MiniLM-L6-v2', 'all-mpnet-base-v2', 'bert-large-nli-mean-tokens] "
}Dando um exemplo de uma resposta hipotética para a pergunta em consulta, uma passagem hipotética que mantém uma resposta à consulta ou gera poucas perguntas relacionadas alternativas pode melhorar a recuperação e, assim, obter pedaços mais precisos dos documentos para passar no contexto do LLM. Com base no artigo de referência - recuperação precisa de densa tiro zero sem rótulos de relevância (incorporação de documentos hipotéticos).
As seguintes opções de configuração ativam essas abordagens de experimentação:
{
"hyde" : " generated_hypothetical_answer "
}{
"hyde" : " generated_hypothetical_document_to_answer "
} Esse recurso gerará boas perguntas relacionadas, filtrará aquelas que são menos que min_query_expansion_related_question_similarity_score por cento da consulta original (usando a pontuação de similaridade de cosseno) e pesquisar documentos para cada um deles, juntamente com a consulta original, deduzir os resultados e devolvê -los ao reproduzir e render a K Steps.
Valor padrão para min_query_expansion_related_question_similarity_score está definido para 90%, você pode alterar isso no config.json
{
"query_expansion" : true ,
"min_query_expansion_related_question_similarity_score" : 90
}A solução se integra ao Azure Machine Learning e usa o MLFlow para gerenciar experimentos, trabalhos e artefatos. Você pode visualizar os seguintes relatórios como parte do processo de avaliação:
all_metrics_current_run.html mostra pontuações médias entre perguntas e tipos de pesquisa para cada métrica selecionada:
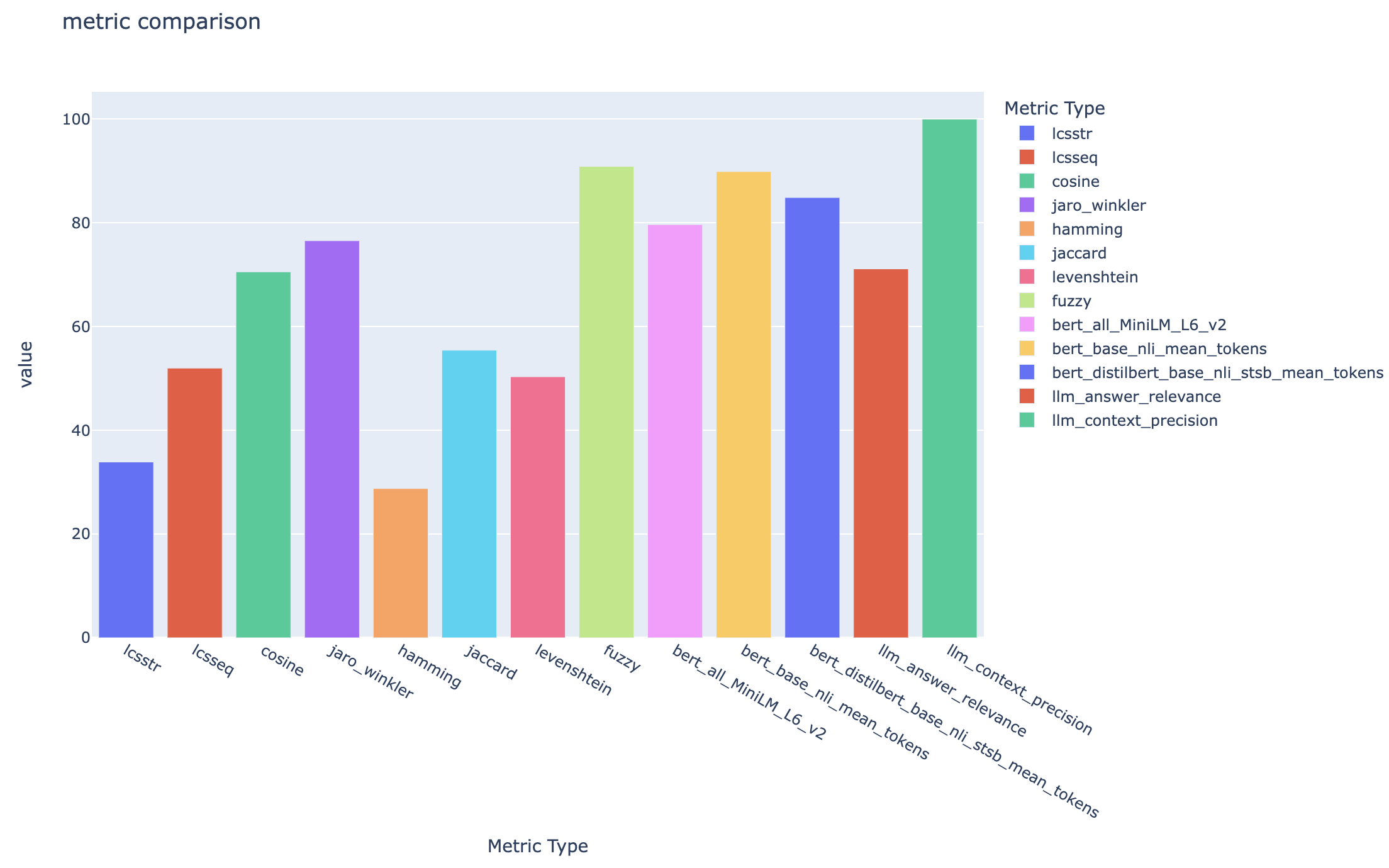
O cálculo de cada métrica e campos utilizados para avaliação são rastreados para cada pergunta e tipo de pesquisa no arquivo CSV de saída:
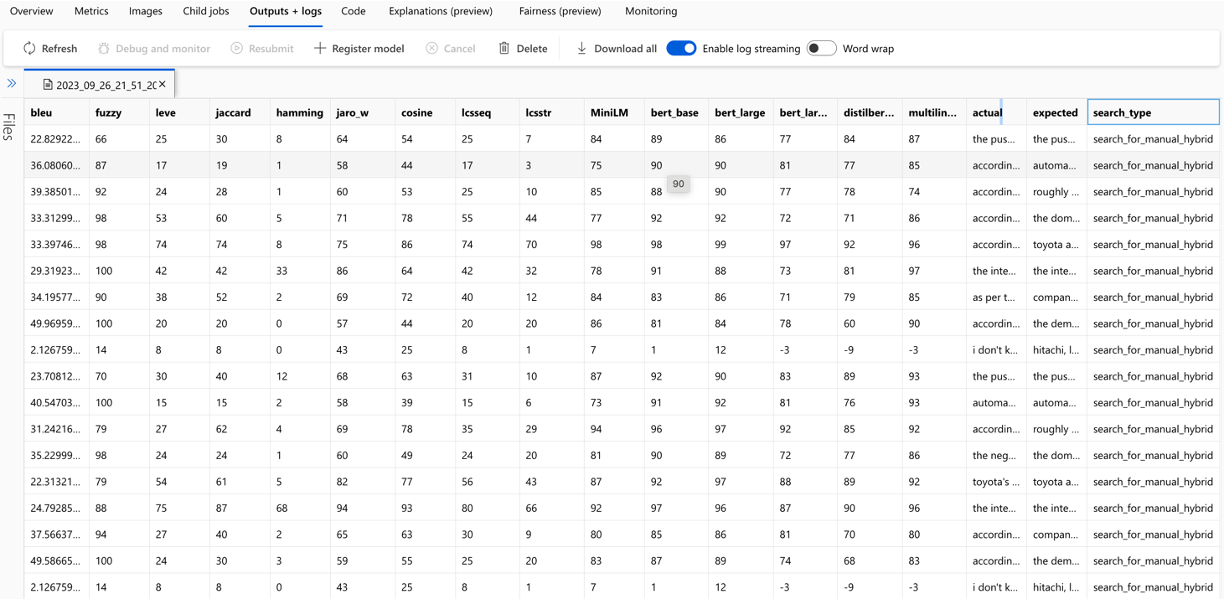
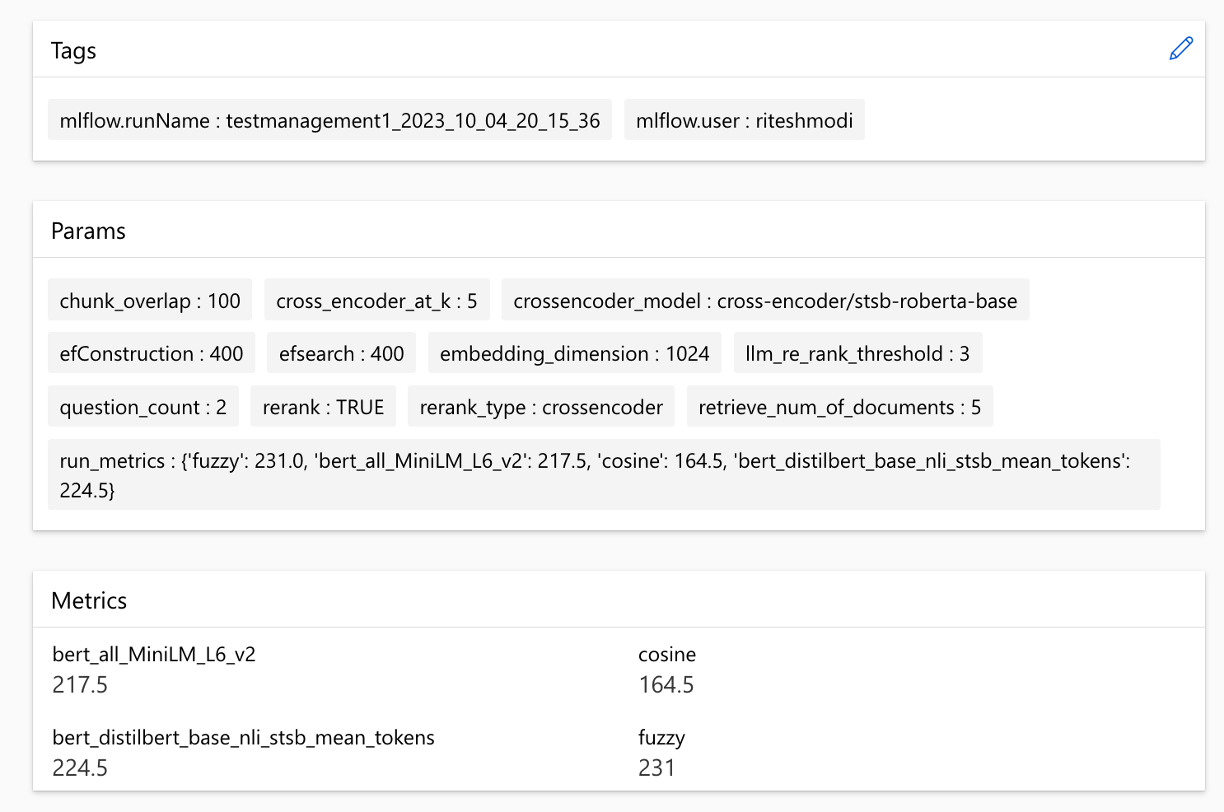
As métricas podem ser comparadas entre as execuções:
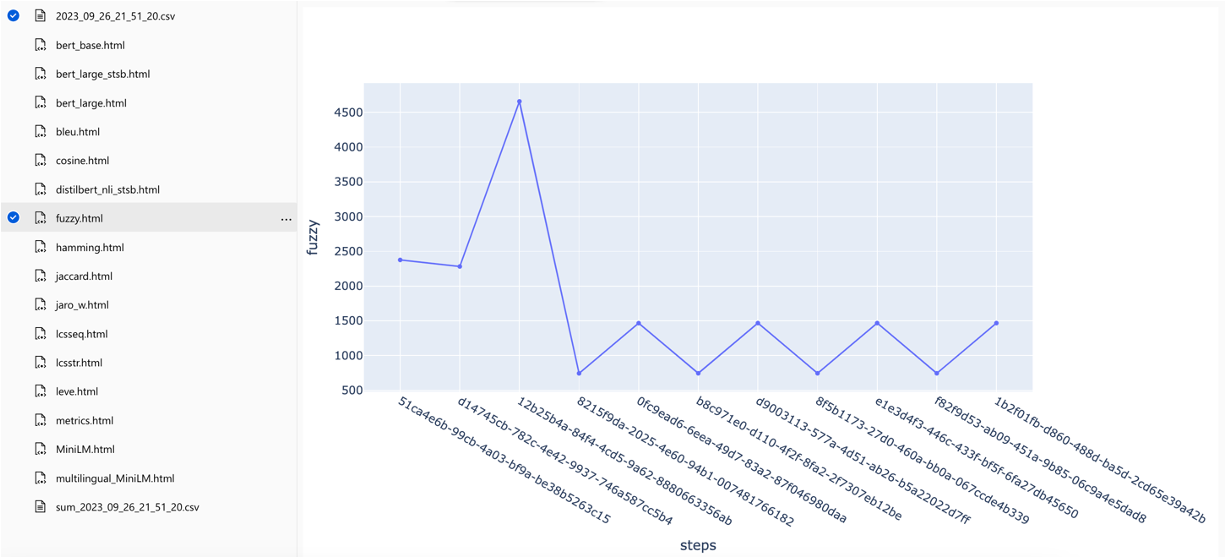
As métricas podem ser comparadas em diferentes estratégias de pesquisa:
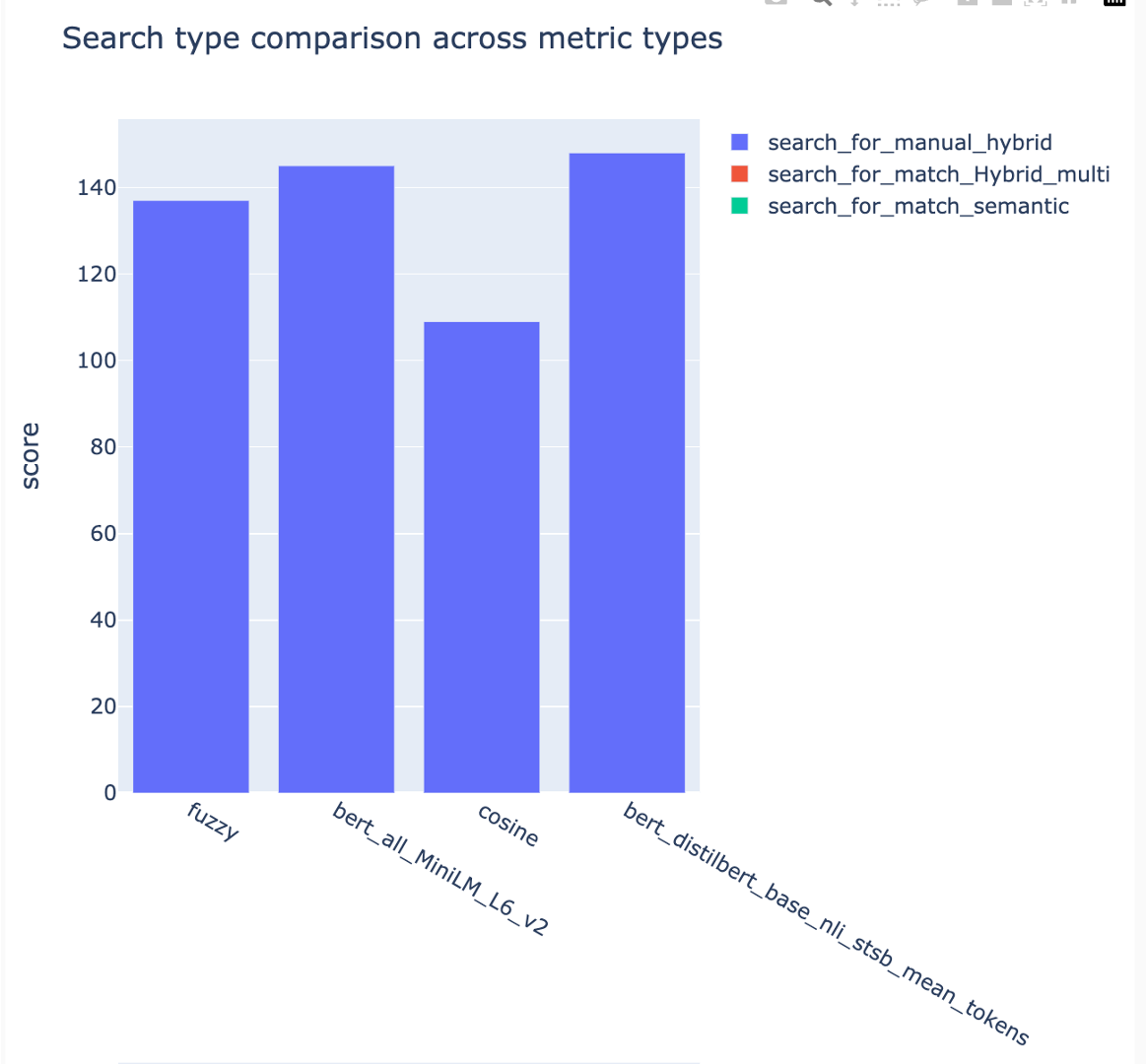
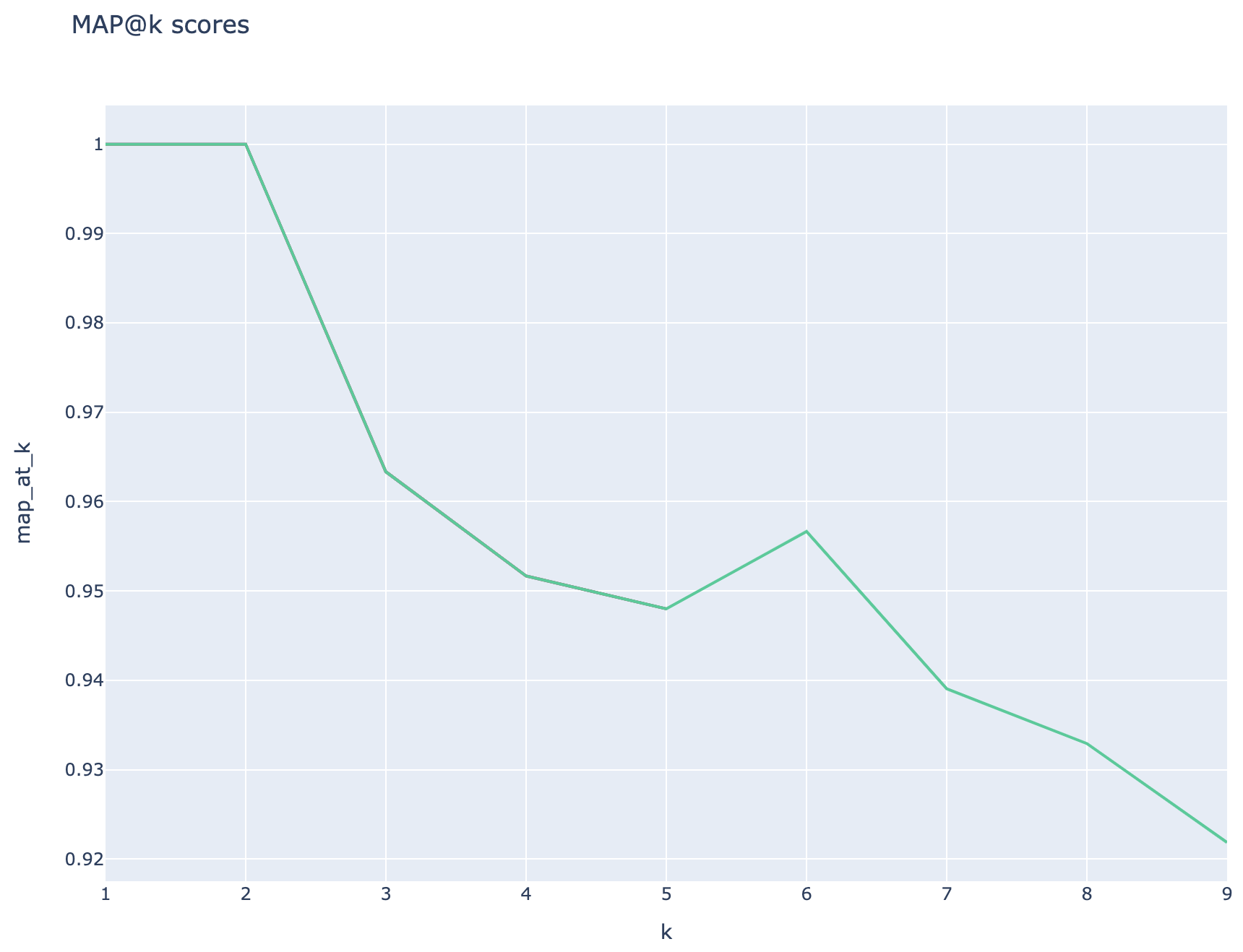
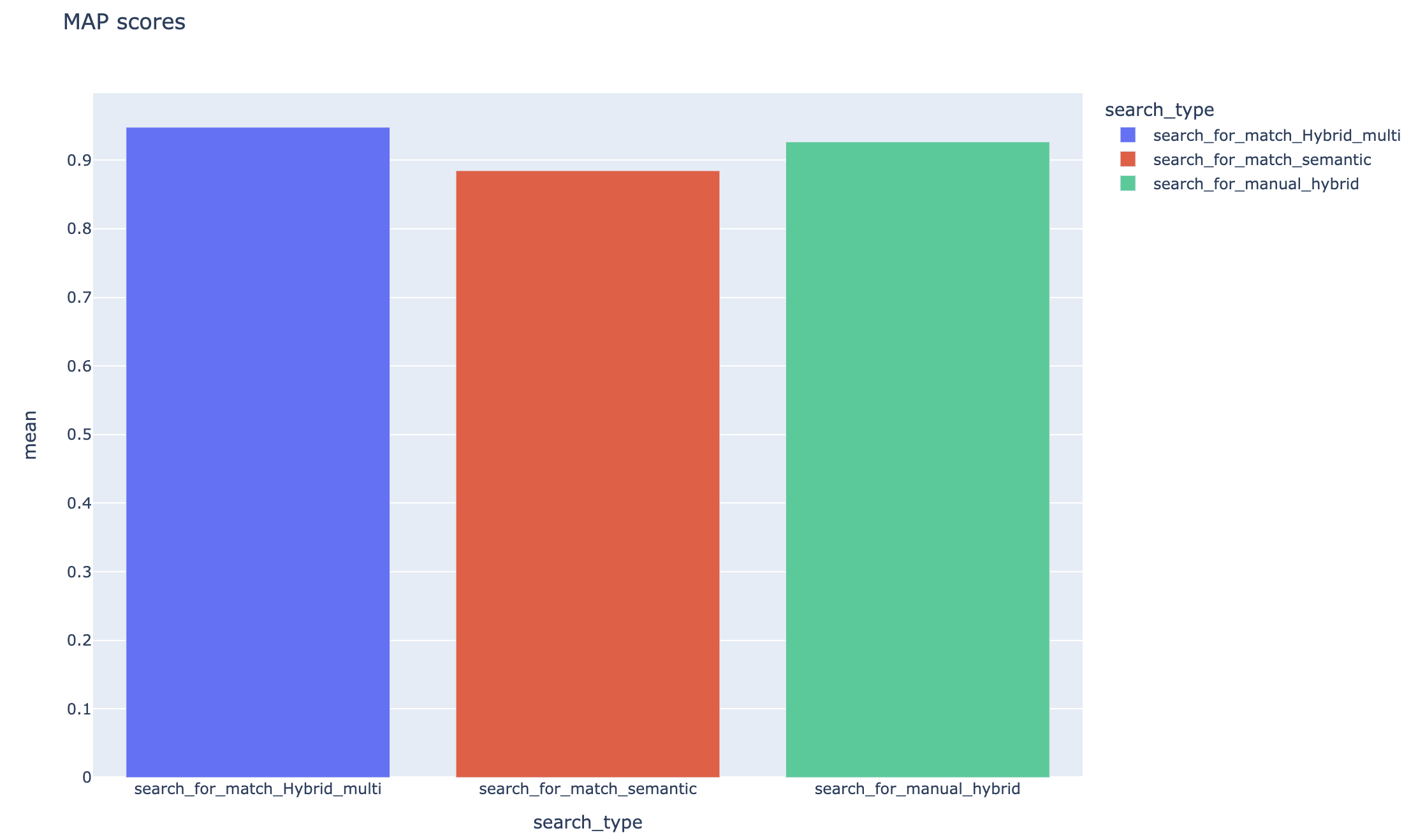
As pontuações médias de precisão média são rastreadas e as pontuações médias dos mapas podem ser comparadas entre o tipo de pesquisa:
Esta seção descreve as gotas ou armadilhas comuns que os engenheiros/desenvolvedores/cientistas de dados podem encontrar enquanto trabalham com o RAG Experiment Accelerator.
Para utilizar com êxito esta solução, você deve primeiro se autenticar, fazendo login na sua conta do Azure. Esta etapa essencial garante que você tenha as permissões necessárias para acessar e gerenciar os recursos do Azure usados por ela. Você pode erros relacionados ao armazenamento de dados do QNA nos ativos de dados de aprendizado de máquina do Azure, executando a etapa de consulta e avaliação como resultado de autorização e autenticação inadequadas ao Azure. Consulte o ponto 4 neste documento para autenticação e autorização.
Pode haver situações em que a solução ainda geraria erros, apesar de autenticação e autorização válidas. Nesses casos, inicie uma nova sessão com uma nova instância de terminal, faça login no Azure usando as etapas mencionadas na Etapa 4 e também verifique se o usuário contribuiu com o acesso aos recursos do Azure relacionados à solução.
Esta solução utiliza vários parâmetros de configuração no config.json que afetam diretamente sua funcionalidade e desempenho. Por favor, preste muita atenção a estas configurações:
Retrieve_Num_Of_Documents: Esta configuração controla o número inicial de documentos recuperados para análise. Valores excessivamente altos ou baixos podem levar a erros de "índice fora do alcance" devido ao processamento de classificação dos resultados da IA da pesquisa.
Cross_Encoder_AT_K: Esta configuração influencia o processo de classificação. Um valor alto pode resultar em documentos irrelevantes sendo incluídos nos resultados finais.
LLM_RERANK_THREHOLD: Esta configuração determina quais documentos são passados para o Modelo de Idioma (LLM) para processamento adicional. Definir esse valor muito alto pode criar um contexto excessivamente grande para o LLM lidar, potencialmente levando a erros de processamento ou resultados degradados. Isso também pode resultar em exceção do terminal do Azure Openai.
Antes de executar esta solução, certifique -se de configurar corretamente o nome da implantação do Azure OpenAI no arquivo config.json e adicione segredos relevantes às variáveis de ambiente (arquivo .env). Essas informações são cruciais para que o aplicativo se conecte aos recursos apropriados do Azure OpenAi e da função, conforme projetado. Se você não tiver certeza sobre os dados de configuração, consulte o arquivo .env.template e config.json. A solução foi testada com o modelo GPT 3.5 Turbo e precisa de mais testes para qualquer outro modelo.
Durante a etapa de geração QNA, você pode ocasionalmente encontrar erros relacionados à saída JSON recebida do Azure OpenAI. Esses erros podem impedir a geração bem -sucedida de poucas perguntas e respostas. Aqui está o que você precisa saber:
Formatação incorreta: a saída JSON do Azure OpenAI pode não aderir ao formato esperado, causando problemas com o processo de geração QNA. Filtragem de conteúdo: o Azure OpenAI possui filtros de conteúdo em vigor. Se o texto de entrada ou as respostas geradas forem consideradas inadequadas, poderá levar a erros. Limitações da API: o serviço Azure OpenAI tem limitações de token e taxa que afetam a saída.
Métricas de avaliação de ponta a ponta: Nem todas as métricas comparando as respostas geradas e de verdade no solo são capazes de capturar diferenças na semântica. Por exemplo, métricas como levenshtein ou jaro_winkler medem apenas distâncias de edição. A métrica cosine também não permite a comparação da semântica: ele usa a implementação baseada em token de texto de texto com base em vetores de frequência de termo. Para calcular a similaridade semântica entre as respostas geradas e as respostas esperadas, considere o uso de métricas baseadas em incorporação, como as pontuações do BERT ( bert_ ).
As métricas de avaliação componentes: as métricas de avaliação usando o LLM-AS-Judges não são determinísticas. As métricas llm_ incluídas no acelerador usam o modelo indicado no campo Config azure_oai_eval_deployment_name . Os avisos usados para a instrução de avaliação podem ser ajustados e estão incluídos no arquivo prompts.py ( llm_answer_relevance_instruction , llm_context_recall_instruction , llm_context_precision_instruction ).
Métricas baseadas em recuperação: as pontuações dos mapas são calculadas comparando cada pedaço recuperado com a pergunta e o pedaço usado para gerar o par QNA. Para avaliar se um pedaço recuperado é relevante ou não, a semelhança entre o pedaço recuperado e a concatenação da questão do usuário final e o pedaço usado na etapa QNA ( 02_qa_generation.py ) é calculado usando o SpacyEvaluator. A similaridade do Spacy é o padrão da média dos vetores de token, o que significa que o cálculo é insensível à ordem das palavras. Por padrão, o limite de similaridade é definido como 80% ( spacy_evaluator.py ).
Congratulamo -nos com suas contribuições e sugestões. Para contribuir, você precisa concordar com um contrato de licença de colaborador (CLA) que confirme que você tem o direito de e realmente fazer, conceda -nos os direitos de usar sua contribuição. Para detalhes, visite [https://cla.opensource.microsoft.com].
Quando você envia uma solicitação de tração, um bot do CLA verifica automaticamente se você precisa fornecer um CLA e fornecer instruções (por exemplo, verificação de status, comentar). Siga as instruções do bot. Você só precisa fazer isso uma vez para todos os repositórios que usam nosso CLA.
Antes de contribuir, certifique -se de correr
pip install -e .
pre-commit install
Este projeto segue o Código de Conduta Open da Microsoft. Para obter mais informações, consulte o Código de Conduta Perguntas frequentes ou entre em contato com [email protected] com quaisquer perguntas ou comentários.
bug/11-short-descriptionfeature/22-short-descriptionexample_snake_case .git config --global user.name "First Last"Este projeto pode conter marcas comerciais ou logotipos para projetos, produtos ou serviços. Você deve seguir as diretrizes de marca registrada e marca da Microsoft para usar as marcas comerciais ou logotipos da Microsoft corretamente. Não use marcas comerciais ou logotipos da Microsoft em versões modificadas deste projeto de uma maneira que causa confusão ou implica patrocínio da Microsoft. Siga as políticas de quaisquer marcas comerciais ou logotipos de terceiros que este projeto contém.


