rag experiment accelerator
1.0.0
Das Lag -Experiment -Beschleuniger ist ein vielseitiges Tool, mit dem Sie Experimente und Bewertungen mit Azure AI -Suche und Lappenmuster durchführen können. Dieses Dokument bietet einen umfassenden Leitfaden, der alles abdeckt, was Sie über dieses Tool wissen müssen, z. B. den Zweck, die Funktionen, die Installation, die Verwendung und vieles mehr.
Das Hauptziel des Lag -Experiments Beschleuniger ist es, es einfacher und schneller zu machen, Experimente und Bewertungen von Suchanfragen und Qualität der Reaktion von OpenAI durchzuführen. Dieses Tool ist nützlich für Forscher, Datenwissenschaftler und Entwickler, die möchten:
18. März 2024: Inhaltsabtastung wurde hinzugefügt. Mit dieser Funktionalität kann der Datensatz durch einen bestimmten Prozentsatz abgetastet werden. Die Daten werden durch den Inhalt geclustert und dann wird der Beispielprozentsatz in jedem Cluster angenommen, um sogar die Verteilung der Stichprobendaten zu versuchen.
Dies geschieht, um repräsentative Ergebnisse in der Stichprobe sicherzustellen, dass man den gesamten Datensatz überschreitet.
Hinweis : Es wird empfohlen, Ihre Umgebung wieder aufzubauen, wenn Sie dieses Tool bereits aufgrund neuer Abhängigkeiten verwendet haben.
Der RAG Experiment Accelerator ist konfiguriert und bietet eine große Anzahl von Funktionen, um seinen Zweck zu unterstützen:
Experiment -Setup : Sie können Experimente definieren und konfigurieren, indem Sie einen Bereich von Suchmaschinenparametern, Suchtypen, Abfragesätzen und Bewertungsmetriken angeben.
Integration : Integriert sich nahtlos in Azure AI -Suche, Azure -maschinelles Lernen, MLFlow und Azure OpenAI.
Rich Search Index : Er erstellt mehrere Suchindizes basierend auf Hyperparameter -Konfigurationen, die in der Konfigurationsdatei verfügbar sind.
Mehrere Dokumentlader : Das Tool unterstützt mehrere Dokumentlader, einschließlich des Ladens über Azure -Dokument -Intelligenz und grundlegende Langchain -Lader. Dies gibt Ihnen die Flexibilität, mit unterschiedlichen Extraktionsmethoden zu experimentieren und ihre Wirksamkeit zu bewerten.
Benutzerdefinierte Dokumentinformationslader : Bei der Auswahl des API-Modells für Dokumentinformationen "Prebuilt-Layout" für Dokumentinformationen verwendet das Tool einen benutzerdefinierten Document Intelligence Loader, um die Daten zu laden. Dieser benutzerdefinierte Loader unterstützt die Formatierung von Tabellen mit Spaltenkopfzeilen in Schlüsselwertpaare (um die Lesbarkeit für das LLM zu verbessern), die irrelevante Teile der Datei für das LLM (wie Seitenzahlen und Fußzeilen) ausschließt, wiederkehrende Muster in der Datei mit Regex und mehr entfernt. Da jede Tabellenzeile in eine Textlinie umgewandelt wird, um zu vermeiden, dass eine Reihe in der Mitte ein Brechen einer Reihe ist, erfolgt das Chunking rekursiv durch Absatz und Zeile. Der benutzerdefinierte Loader greift auf das einfachere API-Modell "Prebuilt-Layout" als Fallback zurück, wenn der "Prebuilt-Layout" fehlschlägt. Jedes andere API -Modell verwendet die Implementierung von Langchain, die die RAW -Antwort von der API von Dokument Intelligence zurückgibt.
Abfragegenerierung : Das Tool kann eine Vielzahl vielfältiger und anpassbarer Abfragesets erzeugen, die auf spezifische Experimentieranforderungen zugeschnitten werden können.
Mehrere Suchtypen : Es unterstützt mehrere Suchtypen, einschließlich reiner Text, reiner Vektor, Kreuzvektor, Multi-Vektor, Hybrid und mehr. Dies gibt Ihnen die Möglichkeit, umfassende Analysen zu Suchfunktionen und -Enteilen durchzuführen.
SUB-MONTRIKAINIERUNG : Das Muster bewertet die Benutzerabfrage und wenn es sie komplex genug findet, unterteilt es es in kleinere Unterausfragen, um einen relevanten Kontext zu erzeugen.
Neuranging : Die Abfragantworten aus der Azure-AI-Suche werden mit LLM neu bewertet und gemäß der Relevanz zwischen der Abfrage und dem Kontext eingestuft.
Metriken und Bewertungen : Es unterstützt End-to-End-Metriken, in denen die generierten Antworten (tatsächlich) mit den Grundwahrheitsantworten (erwartet), einschließlich fernbasierter, Cosinus- und semantischer Ähnlichkeitsmetriken, verglichen werden. Es enthält auch Komponenten-basierte Metriken zur Bewertung der Abruf- und Erzeugungsleistung mithilfe von LLMs als Richter, wie z. B. Relevanz oder Antwortrelevanz von Kontext, sowie Abrufmetriken zur Beurteilung von Suchergebnissen (z. B. MAP@K).
Berichtserstellung : Der RAG Experiment Accelerator automatisiert den Prozess der Berichtsgenerierung mit Visualisierungen, mit denen die Ergebnisse der Experimentierung einfach analysiert und teilen können.
Multi-Lingual : Das Tool unterstützt Sprachanalysatoren für sprachliche Unterstützung für einzelne Sprachen und spezialisierte (Sprach-Agnostische) Analysatoren für benutzerdefinierte Muster in Suchindizes. Weitere Informationen finden Sie unter Arten von Analysatoren.
Stichproben : Wenn Sie einen großen Datensatz haben und/oder das Experimentieren beschleunigen möchten, steht ein Stichprobenprozess zur Verfügung, um eine kleine, aber repräsentative Stichprobe der Daten für den angegebenen Prozentsatz zu erstellen. Die Daten werden durch den Inhalt geclustert und ein Prozentsatz jedes Cluster wird als Teil der Stichprobe ausgewählt. Die erhaltenen Ergebnisse sollten in etwa 10% Rand auf den vollständigen Datensatz eingehen. Sobald ein Ansatz identifiziert wurde, wird für genaue Ergebnisse empfohlen, auf dem vollständigen Datensatz ausgeführt zu werden.
Derzeit kann der Lag -Experimentbeschleuniger lokal durchgeführt werden, um einen der folgenden Einrichtungen zu nutzen:
Durch die Verwendung eines Entwicklungscontainers wird die gesamte erforderliche Software für Sie installiert. Dies erfordert WSL. Weitere Informationen zu Entwicklungscontainern finden Sie in Containern.dev
Installieren Sie die folgende Software auf dem Host -Computer Sie führen die Bereitstellung aus:
- Für Windows - Windows Store Ubuntu 22.04.3 LTS
- Docker Desktop
- Visual Studio -Code
- VS-Code-Erweiterung: Remote-Container
Weitere Anleitung zur Einrichtung von WSL finden Sie hier. Jetzt haben Sie die Voraussetzungen, Sie können:
git clone https://github.com/microsoft/rag-experiment-accelerator.git
code .Sobald das Projekt in VSCODE eröffnet wird, sollten Sie sich fragen, ob Sie dies "in einem Entwicklungsbehälter wiedereröffnen" möchten. Sag ja.
Sie können natürlich den RAG Experiment Accelerator auf einem Windows/Mac -Computer ausführen, wenn Sie möchten. Sie sind für die Installation der richtigen Werkzeuge verantwortlich. Befolgen Sie diese Installationsschritte:
git clone https://github.com/microsoft/rag-experiment-accelerator.gitconda create -n rag-experiment python=3.11
conda init bashSchließen Sie Ihr Terminal, öffnen Sie einen neuen und rennen Sie:
conda activate rag-experiment
pip install .az login
az account set --subscription= " <your_subscription_guid> "
az account showEs gibt 3 Optionen, um alle erforderlichen Azure -Dienste zu installieren:
Dieses Projekt unterstützt Azure Developer CLI.
azd provisionazd up auch verwenden, wenn Sie es vorziehen, da diese azd provision ohnehin nennt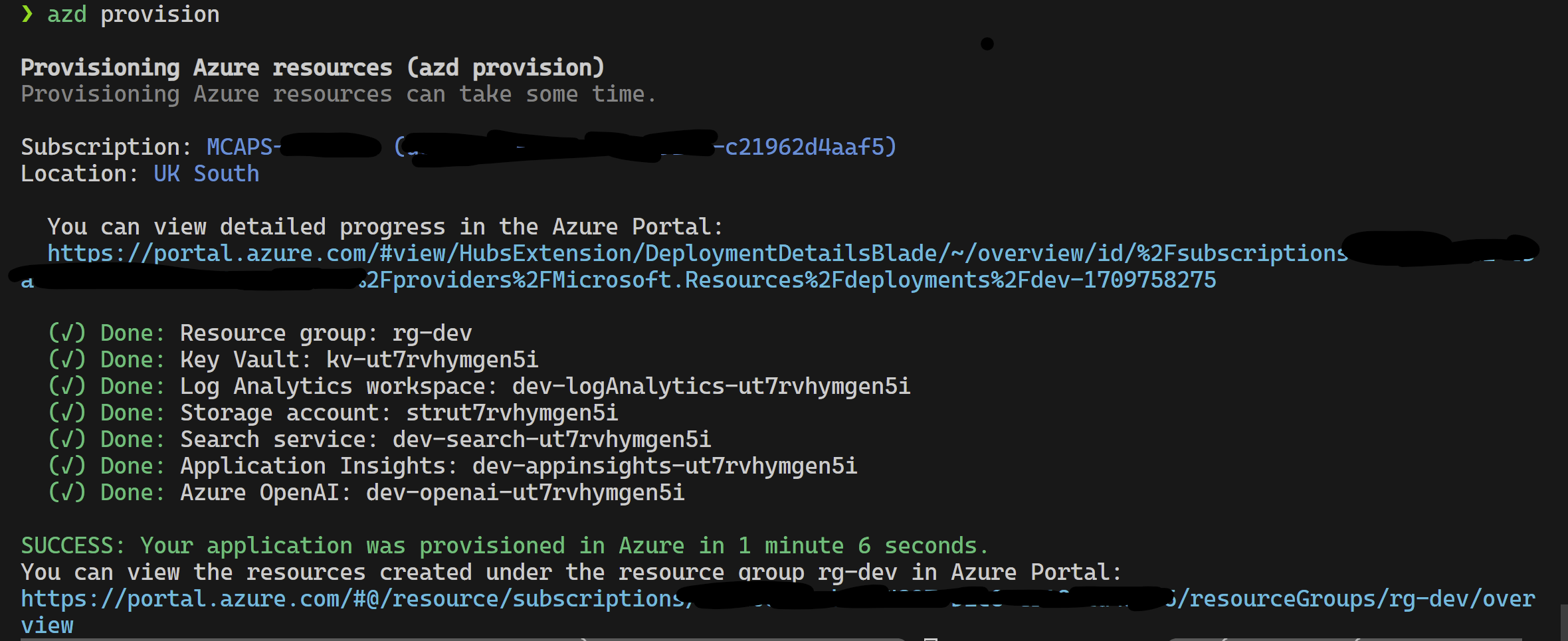
Sobald dies abgeschlossen ist, können Sie die Startkonfiguration zum Ausführen verwenden oder die 4 Schritte debuggen, und die aktuelle von azd bereitgestellte Umgebung wird mit den richtigen Werten geladen.
Wenn Sie die Infrastruktur selbst aus der Vorlage bereitstellen möchten, können Sie auch hier klicken:
Wenn Sie azd nicht verwenden möchten, können Sie auch die normale az CLI verwenden.
Verwenden Sie den folgenden Befehl zur Bereitstellung.
az login
az deployment sub create --subscription < subscription-id > --location < location > --template-file infra/main.bicepOder
So Bereitstellung mit isoliertem Netzwerkverwandungsbefehl. Ersetzen Sie die Parameterwerte durch die Einzelheiten Ihres isolierten Netzwerks. Sie müssen alle drei subnetAddressSpace ( vnetAddressSpace proxySubnetAddressSpace
az login
az deployment sub create --location < location > --template-file infra/main.bicep
--parameters vnetAddressSpace= < vnet-address-space >
--parameters proxySubnetAddressSpace= < proxy-subnet-address-space >
--parameters subnetAddressSpace= < azure-subnet-address-space >Hier ist ein Beispiel mit Parameterwerten:
az deployment sub create --location uksouth --template-file infra/main.bicep
--parameters vnetAddressSpace= ' 10.0.0.0/16 '
--parameters proxySubnetAddressSpace= ' 10.0.1.0/24 '
--parameters subnetAddressSpace= ' 10.0.2.0/24 ' Befolgen Sie die folgenden Schritte, um den Lag -Experiment -Beschleuniger lokal zu verwenden:
Kopieren Sie die bereitgestellte .env.template -Datei in eine Datei mit dem Namen .env und aktualisieren Sie alle erforderlichen Werte. Viele der erforderlichen Werte für die .env -Datei stammen aus Ressourcen, die zuvor konfiguriert wurden und/oder aus Ressourcen gesammelt werden können, die im Abschnitt zur Bereitstellungsinfrastruktur bereitgestellt wurden. Beachten Sie auch, dass LOGGING_LEVEL standardmäßig auf INFO eingestellt ist, kann jedoch auf eine der folgenden Ebenen geändert werden: NOTSET , DEBUG , INFO , WARN , ERROR , CRITICAL .
cp .env.template .env
# change parameters manually Kopieren Sie die bereitgestellte Datei config.sample.json in eine Datei namens config.json und ändern Sie alle Hyperparameter in Ihr Experiment.
cp config.sample.json config.json
# change parameters manually Kopieren Sie alle Dateien zur Einnahme (PDF, HTML, Markdown, Text, JSON oder DOCX -Format) in den data .
Führen Sie 01_index.py (Python 01_index.py) aus, um Azure AI -Suchindizes zu erstellen und Daten in sie zu laden.
python 01_index.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " Führen Sie 02_qa_generation.py (Python 02_Qa_Generation.py) aus, um Fragen zu EINs mit Azure OpenAI zu generieren.
python 02_qa_generation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " Führen Sie 03_querying.py (Python 03_Querying.py) aus, um die Azure-AI-Suche abzufragen, um Kontext zu generieren, Elemente in den Kontext neu zu beziehen und von Azure OpenAI mit dem neuen Kontext eine Antwort zu erhalten.
python 03_querying.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " Führen Sie 04_evaluation.py (Python 04_Evaluation.py) aus, um Metriken mithilfe verschiedener Methoden zu berechnen und Diagramme und Berichte im maschinellen Lernen von Azure unter Verwendung der MLFlow -Integration zu generieren.
python 04_evaluation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " Alternativ können Sie die obigen Schritte (abgesehen von 02_qa_generation.py ) mit einer Azure ML -Pipeline ausführen. Folgen Sie dazu dem Leitfaden hier.
Die Probenahme wird lokal ausgeführt, um ein kleines, aber repräsentatives Stück der Daten zu erstellen. Dies hilft beim schnellen Experimentieren und hält die Kosten niedrig. Die erhaltenen Ergebnisse sollten in etwa 10% Rand auf den vollständigen Datensatz eingehen. Sobald ein Ansatz identifiziert wurde, wird für genaue Ergebnisse empfohlen, auf dem vollständigen Datensatz ausgeführt zu werden.
Hinweis : Die Probenahme kann nur lokal ausgeführt werden. In diesem Stadium wird sie nicht auf einem verteilten AML -Rechencluster unterstützt. Der Prozess wäre also, die Probenahme lokal auszuführen und dann den generierten Beispieldatensatz für AML zu verwenden.
Wenn Sie über einen sehr großen Datensatz verfügen und einen ähnlichen Ansatz zur Probe der Daten ausführen möchten, können Sie die PYSPARK-In-Memory-Distributed-Implementierung im Data Discovery Toolkit für Microsoft Fabric oder Azure Synapse Analytics verwenden.
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"only_run_sampling" : " If set to true, this will only run the sampling step and will not create an index or any subsequent steps, use this if you want to build a small sampled dataset to run in AML " ,
"sample_percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 " ,
},Der Stichprobenprozess erzeugt die folgenden Artefakte im Stichprobenverzeichnis:
job_name benannt ist, der die Teilmenge der abgetasteten Dateien enthält. Diese können beim Ausführen des gesamten Vorgangs auf AML als --data_dir Argument angegeben werden.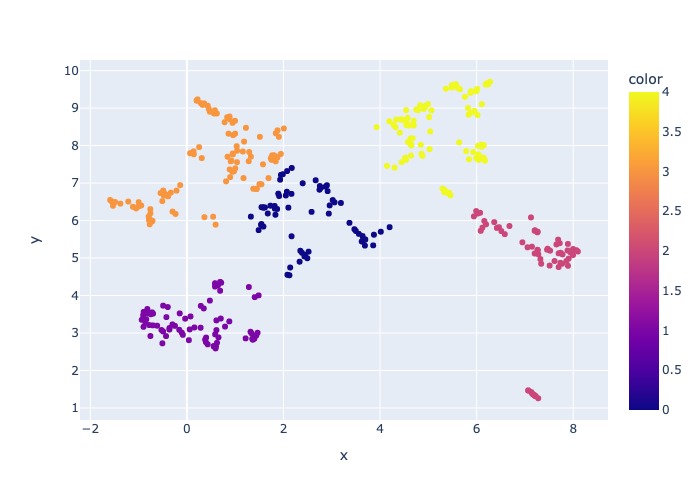
"optimum_k": auto -Konfigurationswert auf automatisch eingestellt ist, versucht der Stichprobenprozess, die optimale Anzahl von Clustern automatisch festzulegen. Dies kann überschrieben werden, wenn Sie ungefähr wissen, wie viele breite Inhaltsschaufel in Ihren Daten vorhanden sind. Im Stichprobenordner wird ein Ellbogendiagramm erzeugt. 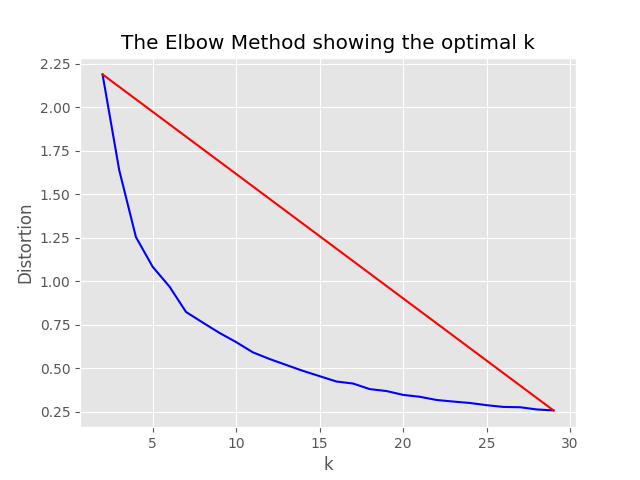
Es gibt zwei Optionen zum Ausführen von Probenahme, nämlich:
Legen Sie die folgenden Werte fest, um den Indexierungsprozess lokal auszuführen:
"sampling" : {
"sample_data" : true ,
"only_run_sampling" : false ,
"sample_percentage" : 10 ,
"optimum_k" : auto,
"min_cluster" : 2 ,
"max_cluster" : 30
}, Wenn der Konfigurationswert von only_run_sampling auf true festgelegt wird, wird nur der Stichprobenschritt ausgeführt, kein Index wird erstellt und andere nachfolgende Schritte werden nicht ausgeführt. Legen Sie das Argument --data_dir auf Verzeichnis fest, das durch den Stichprobenprozess erstellt wurde, der lautet:
artifacts/sampling/config.[job_name] und führen Sie den AML -Pipeline -Schritt aus.
Alle Werte können Elementlisten sein. Einschließlich der verschachtelten Konfigurationen. Jedes Array erzeugt die Kombinationen von flachen Konfigurationen, wenn die Methode flatten() auf einen bestimmten Knoten aufgerufen wird, um 1 zufällige Kombination auszuwählen - rufen Sie die Methode sample() auf.
{
"experiment_name" : " If provided, this will be the experiment name in Azure ML and it will group all job run under the same experiment, otherwise (if left empty) index_name_prefix will be used and there may be more than one experiment " ,
"job_name" : " If provided, all jobs runs in Azure ML will be named with this property value plus timestamp, otherwise (if left empty) each job with be named only with timestamp " ,
"job_description" : " You may provide a description for the current job run which describes in words what you are about to experiment with " ,
"data_formats" : " Specifies the supported data formats for the application. You can choose from a variety of formats such as JSON, CSV, PDF, and more. [*] - means all formats included " ,
"main_instruction" : " Defines the main instruction prompt coming with queries to LLM " ,
"use_checkpoints" : " A boolean. If true, enables use of checkpoints to load data and skip processing that was already done in previous executions. " ,
"index" : {
"index_name_prefix" : " Search index name prefix " ,
"ef_construction" : " ef_construction value determines the value of Azure AI Search vector configuration. " ,
"ef_search" : " ef_search value determines the value of Azure AI Search vector configuration. " ,
"chunking" : {
"preprocess" : " A boolean. If true, preprocess documents, split into smaller chunks, embed and enrich them, and finally upload documents chunks for retrieval into Azure Search Index. " ,
"chunk_size" : " Size of each chunk e.g. [500, 1000, 2000] " ,
"overlap_size" : " Overlap Size for each chunk e.g. [100, 200, 300] " ,
"generate_title" : " A boolean. If true, a title is generated for the chunk of content and an embedding is created for it " ,
"generate_summary" : " A boolean. If true, a summary is generated for the chunk of content and an embedding is created for it " ,
"override_content_with_summary" : " A boolean. If true, The chunk content is replaced with its summary " ,
"chunking_strategy" : " determines the chunking strategy. Valid values are 'azure-document-intelligence' or 'basic' " ,
"azure_document_intelligence_model" : " represents the Azure Document Intelligence Model. Used when chunking strategy is 'azure-document-intelligence'. When set to 'prebuilt-layout', provides additional features (see above) "
},
"embedding_model" : " see 'Description of embedding models config' below " ,
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 "
}
},
"language" : {
"analyzer" : {
"analyzer_name" : " name of the analyzer to use for the field. This option can be used only with searchable fields and it can't be set together with either searchAnalyzer or indexAnalyzer. " ,
"index_analyzer_name" : " name of the analyzer used at indexing time for the field. This option can be used only with searchable fields. It must be set together with searchAnalyzer and it cannot be set together with the analyzer option. " ,
"search_analyzer_name" : " name of the analyzer used at search time for the field. This option can be used only with searchable fields. It must be set together with indexAnalyzer and it cannot be set together with the analyzer option. This property cannot be set to the name of a language analyzer; use the analyzer property instead if you need a language analyzer. " ,
"char_filters" : " The character filters for the index " ,
"tokenizers" : " The tokenizers for the index " ,
"token_filters" : " The token filters for the index "
},
"query_language" : " The language of the query. Possible values: en-us, en-gb, fr-fr etc. "
},
"rerank" : {
"enabled" : " determines if search results should be re-ranked. Value values are TRUE or FALSE " ,
"type" : " determines the type of re-ranking. Value values are llm or cross_encoder " ,
"llm_rerank_threshold" : " determines the threshold when using llm re-ranking. Chunks with rank above this number are selected in range from 1 - 10. " ,
"cross_encoder_at_k" : " determines the threshold when using cross-encoding re-ranking. Chunks with given rank value are selected. " ,
"cross_encoder_model" : " determines the model used for cross-encoding re-ranking step. Valid value is cross-encoder/stsb-roberta-base "
},
"search" : {
"retrieve_num_of_documents" : " determines the number of chunks to retrieve from the search index " ,
"search_type" : " determines the search types used for experimentation. Valid value are search_for_match_semantic, search_for_match_Hybrid_multi, search_for_match_Hybrid_cross, search_for_match_text, search_for_match_pure_vector, search_for_match_pure_vector_multi, search_for_match_pure_vector_cross, search_for_manual_hybrid. e.g. ['search_for_manual_hybrid', 'search_for_match_Hybrid_multi','search_for_match_semantic'] " ,
"search_relevancy_threshold" : " the similarity threshold to determine if a doc is relevant. Valid ranges are from 0.0 to 1.0 "
},
"query_expansion" : {
"expand_to_multiple_questions" : " whether the system should expand a single question into multiple related questions. By enabling this feature, you can generate a set of alternative related questions that may improve the retrieval process and provide more accurate results " .,
"query_expansion" : " determines if query expansion feature is on. Value values are TRUE or FALSE " ,
"hyde" : " this feature allows you to experiment with various query expansion approaches which may improve the retrieval metrics. The possible values are 'disabled' (default), 'generated_hypothetical_answer', 'generated_hypothetical_document_to_answer' reference article - Precise Zero-Shot Dense Retrieval without Relevance Labels (HyDE - Hypothetical Document Embeddings) - https://arxiv.org/abs/2212.10496 " ,
"min_query_expansion_related_question_similarity_score" : " minimum similarity score in percentage between LLM generated related queries to the original query using cosine similarly score. default 90% "
},
"openai" : {
"azure_oai_chat_deployment_name" : " determines the Azure OpenAI deployment name " ,
"azure_oai_eval_deployment_name" : " determines the Azure OpenAI deployment name used for evaluation " ,
"temperature" : " determines the OpenAI temperature. Valid value ranges from 0 to 1. "
},
"eval" : {
"metric_types" : " determines the metrics used for evaluation (end-to-end or component-wise metrics using LLMs). Valid values for end-to-end metrics are lcsstr, lcsseq, cosine, jaro_winkler, hamming, jaccard, levenshtein, fuzzy_score, cosine_ochiai, bert_all_MiniLM_L6_v2, bert_base_nli_mean_tokens, bert_large_nli_mean_tokens, bert_large_nli_stsb_mean_tokens, bert_distilbert_base_nli_stsb_mean_tokens, bert_paraphrase_multilingual_MiniLM_L12_v2. Valid values for component-wise LLM-based metrics are llm_answer_relevance, llm_context_precision and llm_context_recall. e.g ['fuzzy_score','bert_all_MiniLM_L6_v2','cosine_ochiai','bert_distilbert_base_nli_stsb_mean_tokens', 'llm_answer_relevance'] " ,
}
}Hinweis: Wenn Sie die Konfiguration ändern, müssen Sie sich ändern:
config.sample.json (die Beispielkonfiguration, die von anderen kopiert werden soll) embedding_model ist ein Array, das die Konfiguration für die verwendeten Einbettungsmodelle enthält. sentence-transformer type azure -Satztransformatormodelle sein.
{
"type" : " azure " ,
"model_name" : " the name of the Azure OpenAI model " ,
"dimension" : " the dimension of the embedding model. For example, 1536 which is the dimension of text-embedding-ada-002 "
} Wenn Sie ein anderes Modell als text-embedding-ada-002 verwenden, müssen Sie die entsprechende Dimension für das Modell im dimension angeben. Zum Beispiel:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 3072
}Die Abmessungen für die verschiedenen Azure OpenAI -Einbettungsmodelle finden Sie in der Dokumentation von Azure OpenAI -Dienstmodellen.
Bei Verwendung der neueren Emboden -Modelle (V3) können Sie auch ihre Unterstützung für die Verkürzung der Einbettungen nutzen. Geben Sie in diesem Fall die Anzahl der benötigten Dimensionen an und fügen Sie das Flag shorten_dimensions hinzu, um anzuzeigen, dass Sie die Einbettungsdings verkürzen möchten. Zum Beispiel:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 256 ,
"shorten_dimensions" : true
}{
"type" : " sentence-transformer " ,
"model_name" : " the name of the sentence transformer model " ,
"dimension" : " the dimension of the model. This field is not required if model name is one of ['all-MiniLM-L6-v2', 'all-mpnet-base-v2', 'bert-large-nli-mean-tokens] "
}Wenn Sie ein Beispiel für eine hypothetische Antwort auf die Frage in der Abfrage geben, könnte eine hypothetische Passage, die eine Antwort auf die Abfrage enthält, oder nur wenige alternativen Frage generieren, und kann das Abruf verbessern und somit genauere Dokumente einbeziehen, um sie in den LLM -Kontext zu übergeben. Basierend auf dem Referenzartikel - präzises Zero -Shot -dichter Abruf ohne Relevanzbezeichnungen (hyde - hypothetisches Dokumenteinbettung).
Die folgenden Konfigurationsoptionen schalten diese Experimentieransätze ein:
{
"hyde" : " generated_hypothetical_answer "
}{
"hyde" : " generated_hypothetical_document_to_answer "
} Diese Funktion generiert fein verwandte Fragen, filtern Sie diejenigen heraus, die weniger als min_query_expansion_related_question_similarity_score -Prozent aus der ursprünglichen Abfrage (unter Verwendung von Cosinus -Ähnlichkeitsbewertungen) sind, und Suchdokumente für jede von ihnen zusammen mit der ursprünglichen Abfrage, den Ersatzteilen und der Wiederherstellung der Wiederherstellungen und der Top -k -Schritte.
Standardwert für min_query_expansion_related_question_similarity_score ist auf 90%gesetzt. Sie können dies in der config.json ändern
{
"query_expansion" : true ,
"min_query_expansion_related_question_similarity_score" : 90
}Die Lösung integriert sich in das maschinelle Lernen von Azure und verwendet MLFlow, um Experimente, Jobs und Artefakte zu verwalten. Sie können die folgenden Berichte als Teil des Bewertungsprozesses anzeigen:
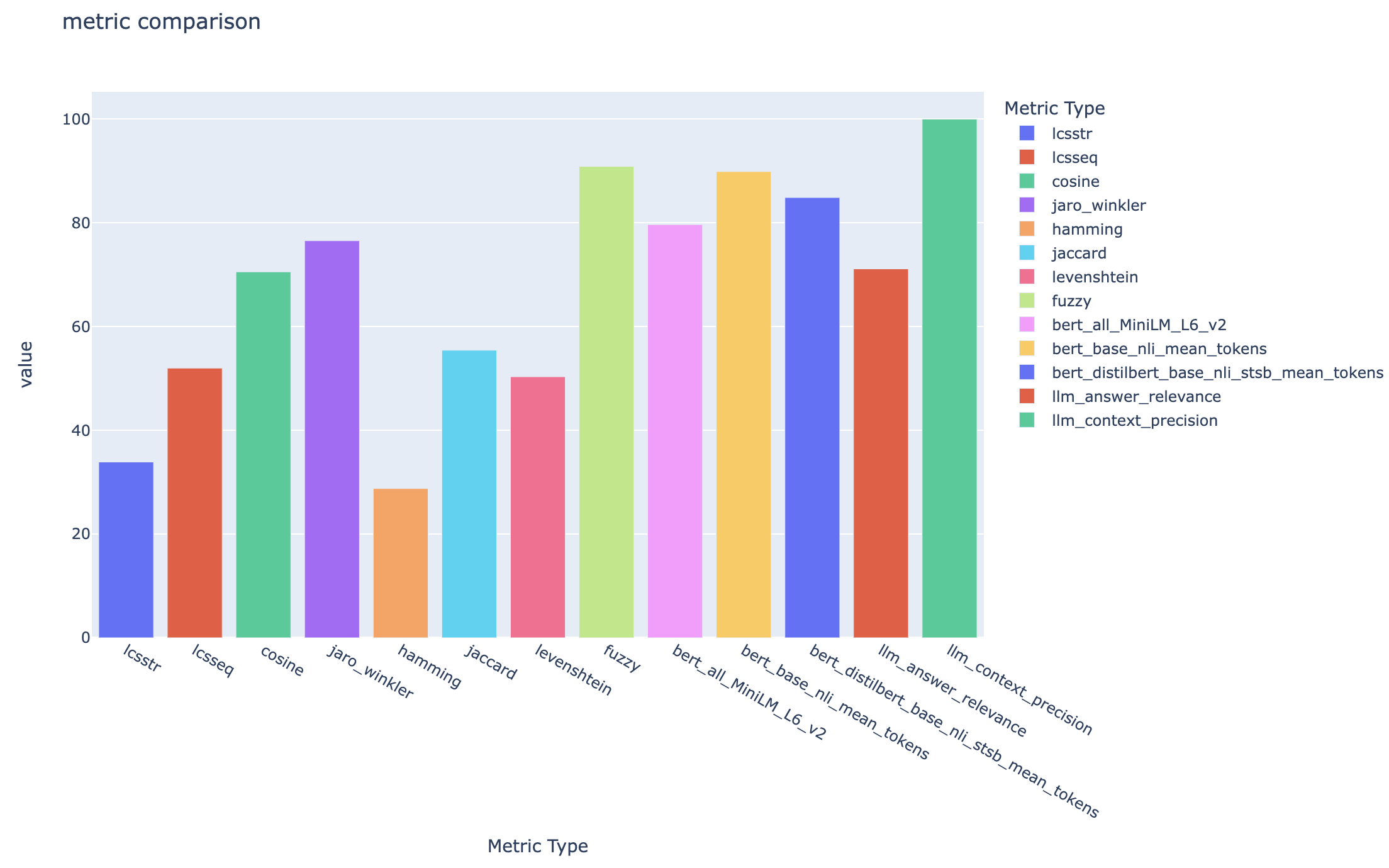
all_metrics_current_run.html zeigt durchschnittliche Punkte über Fragen und Suchtypen für jede ausgewählte Metrik:
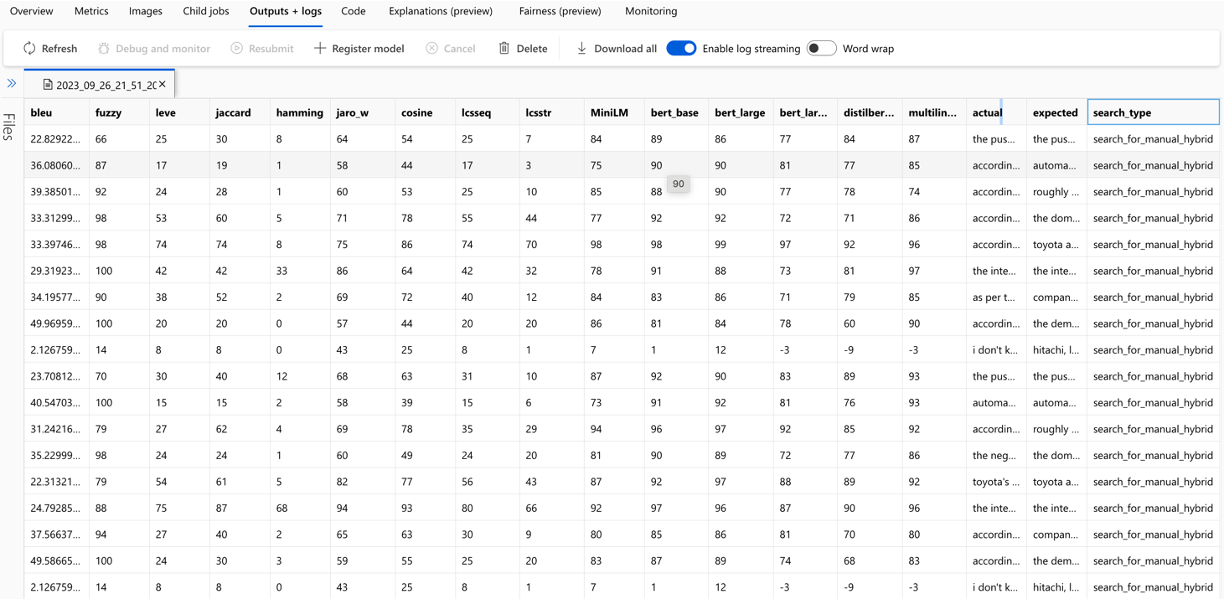
Die Berechnung jeder Metrik und der für die Bewertung verwendeten Felder werden für jede Frage- und Suchtyp in der Ausgabe -CSV -Datei verfolgt:
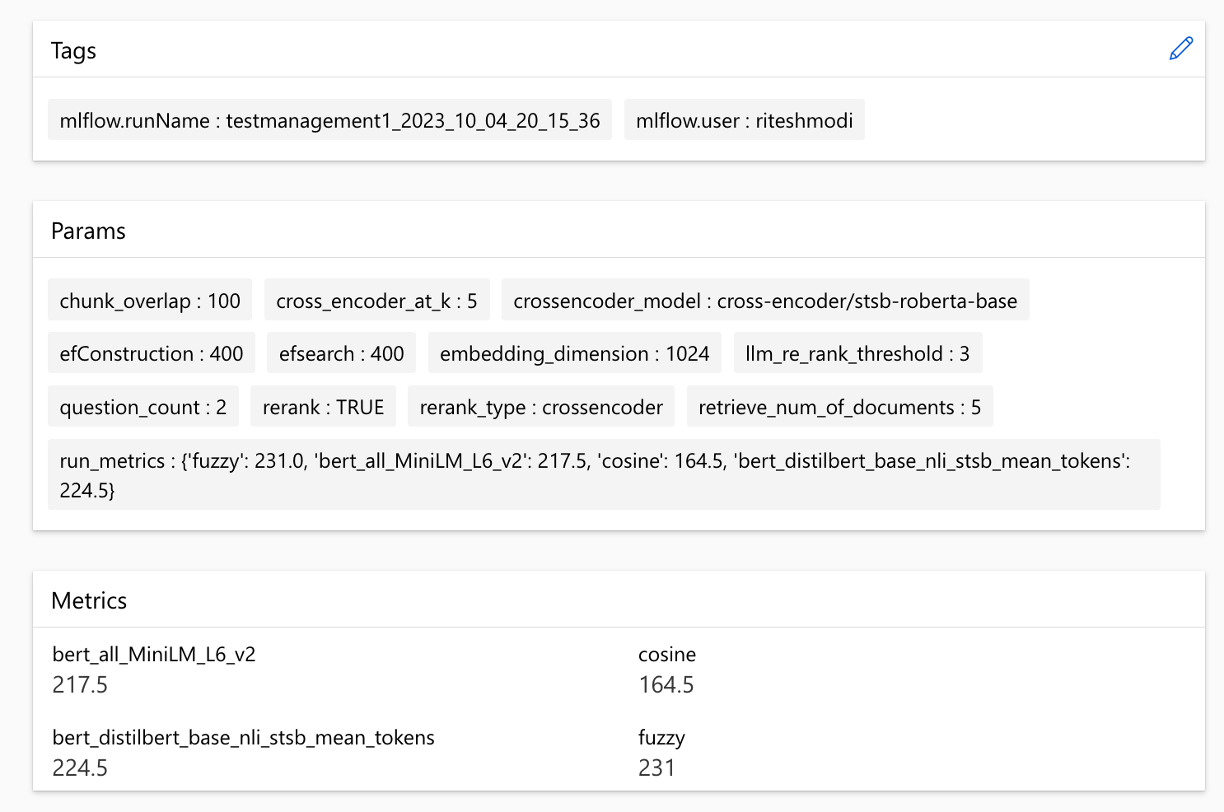
Metriken können über Läufe verglichen werden:
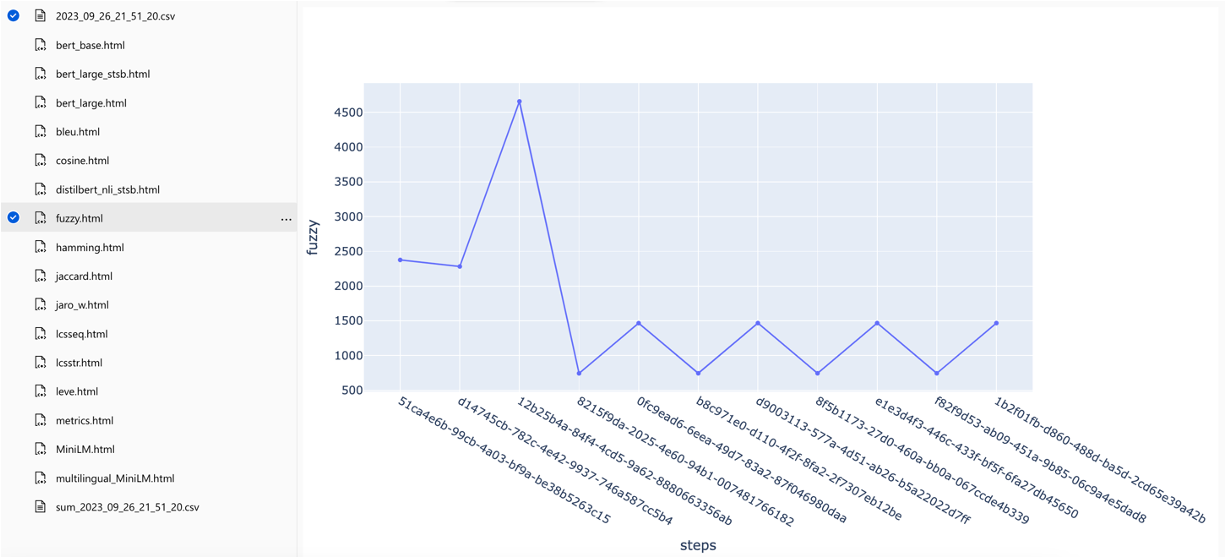
Metriken können über verschiedene Suchstrategien verglichen werden:
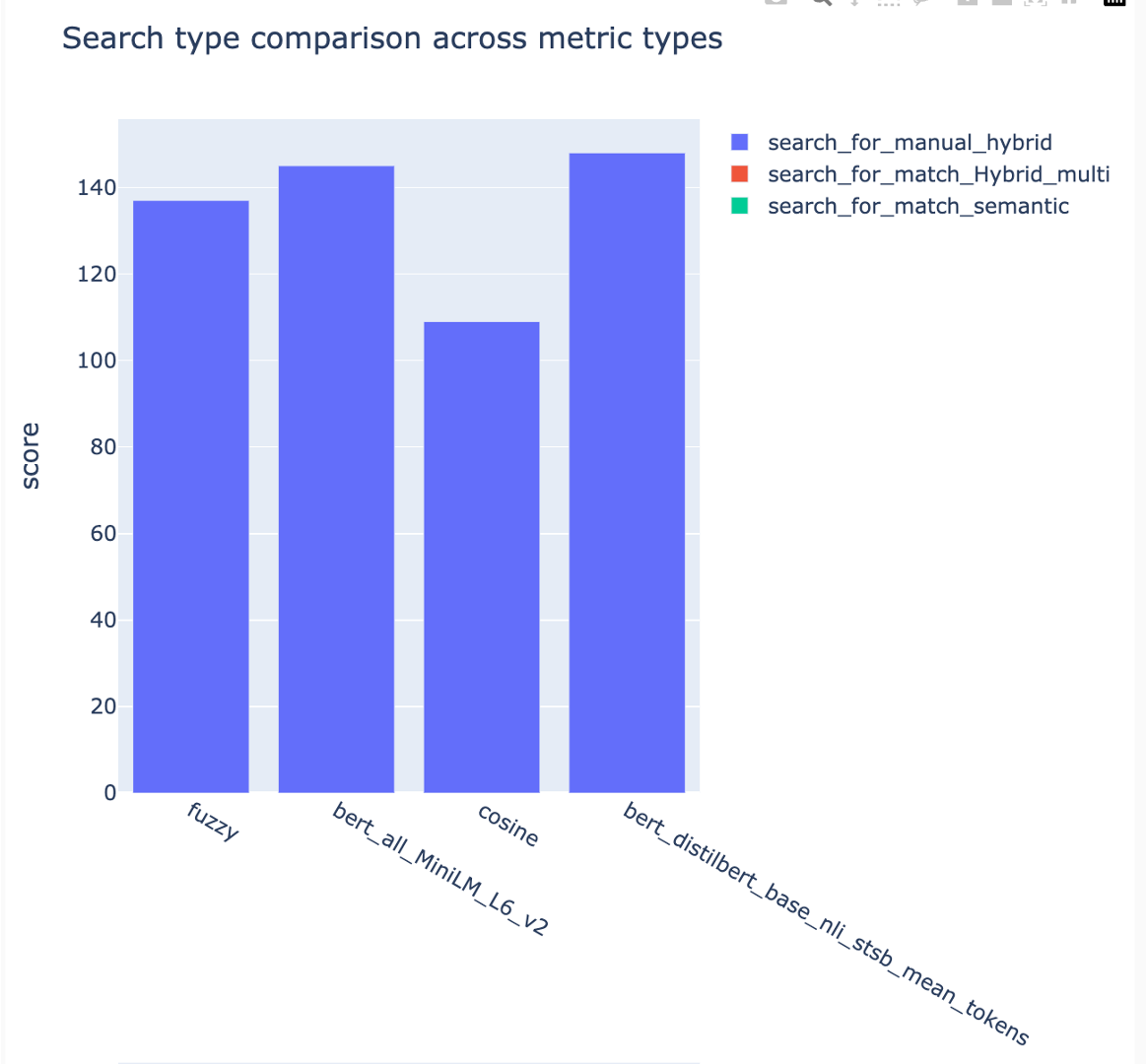
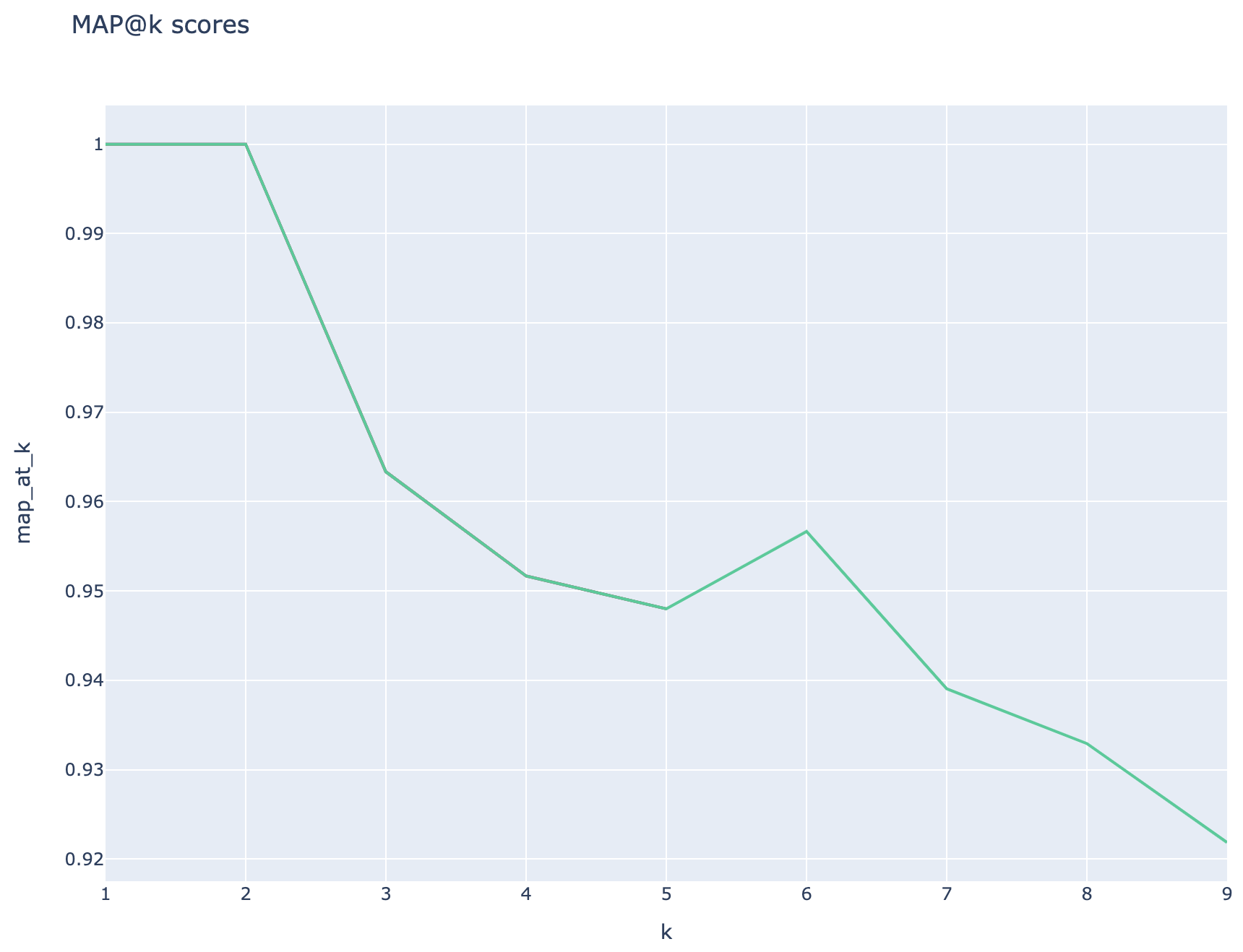
Die mittleren durchschnittlichen Präzisionswerte werden verfolgt und die durchschnittlichen Kartenwerte können über den Suchtyp hinweg verglichen werden:
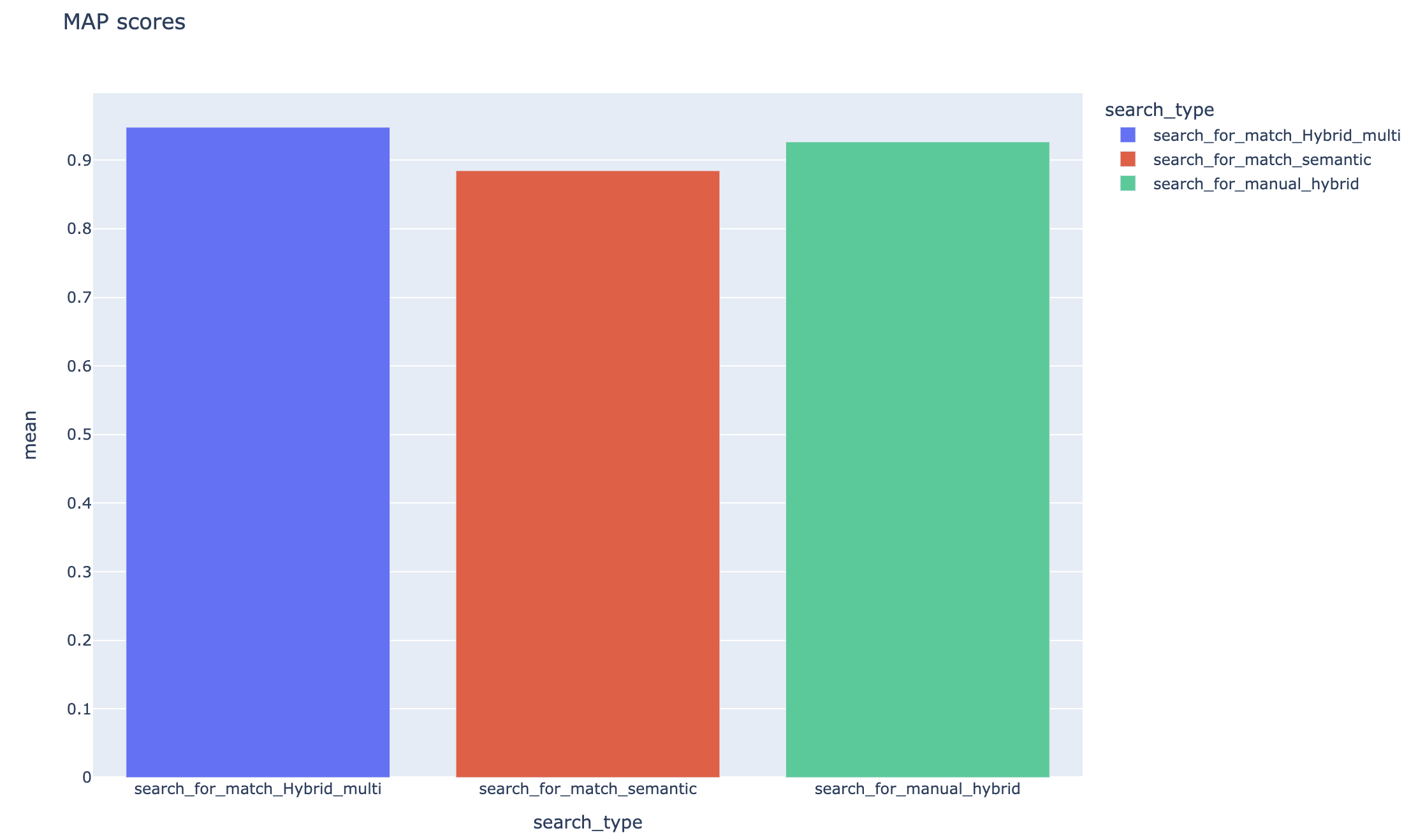
In diesem Abschnitt werden gemeinsame GOTCHAS oder Fallstricke beschrieben, auf die Ingenieure/Entwickler/Datenwissenschaftler während der Arbeit mit RAG -Experimentbeschleuniger begegnen können.
Um diese Lösung erfolgreich zu nutzen, müssen Sie sich zuerst authentifizieren, indem Sie sich in Ihrem Azure -Konto anmelden. Dieser wesentliche Schritt stellt sicher, dass Sie über die erforderlichen Berechtigungen verfügen, um von ihm verwendete Azure -Ressourcen zuzugreifen und zu verwalten. Sie können Fehler im Zusammenhang mit der Speicherung von QNA -Daten in Datenvermögen von Azure Machine Learning und der Ausführung des Abfrage- und Bewertungsschritts als Ergebnis einer unangemessenen Autorisierung und Authentifizierung in Azure ausführen. Siehe Punkt 4 in diesem Dokument zur Authentifizierung und Autorisierung.
Es kann Situationen geben, in denen die Lösung trotz gültiger Authentifizierung und Genehmigung immer noch Fehler erzeugen würde. Starten Sie in solchen Fällen eine neue Sitzung mit einer brandneuen Terminalinstanz, melden Sie sich bei Azure anhand von Schritten an, die in Schritt 4 erwähnt wurden, und prüfen Sie außerdem, ob der Benutzer den Zugriff auf die Azure -Ressourcen im Zusammenhang mit der Lösung beigetragen hat.
Diese Lösung verwendet mehrere Konfigurationsparameter in config.json , die sich direkt auf die Funktionalität und Leistung auswirken. Bitte achten Sie genau auf diese Einstellungen:
ARINGABE_NUM_OF_DOCUMENTS: Diese Konfiguration steuert die anfängliche Anzahl der für die Analyse abgerufenen Dokumente. Übermäßig hohe oder niedrige Werte können aufgrund der Rangverarbeitung von Such -AI -Ergebnissen zu "Index außerhalb des Bereichs" -Fehler führen.
Cross_encoder_at_k: Diese Konfiguration beeinflusst den Ranking -Prozess. Ein hoher Wert kann dazu führen, dass irrelevante Dokumente in die Endergebnisse aufgenommen werden.
llm_rerank_threshold: Diese Konfiguration bestimmt, welche Dokumente zur weiteren Verarbeitung an das Sprachmodell (LLM) übergeben werden. Wenn Sie diesen Wert zu hoch festlegen, können Sie einen übermäßig großen Kontext für die LLM erzeugen, was möglicherweise zu Verarbeitungsfehlern oder degradierten Ergebnissen führt. Dies kann auch zu einer Ausnahme des Azure OpenAI -Endpunkts führen.
Bitte stellen Sie vor dem Ausführen dieser Lösung sicher, dass Sie sowohl Ihren Azure OpenAI -Bereitstellungsnamen in config.json -Datei korrekt eingerichtet haben, und fügen Sie den Umgebungsvariablen (.env -Datei) relevante Geheimnisse hinzu. Diese Informationen sind für die Anwendung von entscheidender Bedeutung, um eine Verbindung zu den entsprechenden Azure OpenAI -Ressourcen und -funktionen herzustellen. Wenn Sie sich über die Konfigurationsdaten nicht sicher sind, lesen Sie bitte .Env.Template und config.json -Datei. Die Lösung wurde mit GPT 3.5 Turbo -Modell getestet und benötigt weitere Tests für jedes andere Modell.
Während der QNA -Erzeugungsschritte können Sie gelegentlich Fehler auf die von Azure OpenAI erhaltenen JSON -Ausgangsausgabe treffen. Diese Fehler können die erfolgreiche Generation weniger Fragen und Antworten verhindern. Folgendes müssen Sie wissen:
Falsche Formatierung: Die JSON -Ausgabe von Azure OpenAI hält möglicherweise nicht an das erwartete Format und verursacht Probleme mit dem QNA -Erzeugungsprozess. Inhaltsfilterung: Azure Openai verfügt über Inhaltsfilter. Wenn der Eingangstext oder die generierten Antworten als unangemessen angesehen werden, kann dies zu Fehlern führen. API -Einschränkungen: Der Azure OpenAI -Dienst hat Token- und Ratenbeschränkungen, die die Ausgabe beeinflussen.
End-to-End-Evaluierungsmetriken: Nicht alle Metriken, die die generierten und Ground-Wahrs-Antworten vergleichen, können Unterschiede in der Semantik erfassen. Beispielsweise messen Metriken wie levenshtein oder jaro_winkler nur Bearbeitungsentfernungen. Die cosine Metrik erlaubt auch nicht den Vergleich der Semantik: Sie verwendet die auf dem Textdistanz -Token-basierte Implementierung basierend auf Begriffsfrequenzvektoren. Um die semantische Ähnlichkeit zwischen den generierten Antworten und den erwarteten Antworten zu berechnen, sollten Sie in Einbettungsmetriken wie Bert-Scores (BERT_) einbettungsbasierte Metriken wie Bert-Scores ( bert_ ) erwägen.
Komponenten-Weise Bewertungsmetriken: Bewertungsmetriken unter Verwendung von LLM-as-ungers sind nicht deterministisch. Die im Accelerator enthaltenen llm_ -Metriken verwenden das im Feld azure_oai_eval_deployment_name angegebene Modell. Die für die Bewertungsanweisung verwendeten Eingabeaufforderungen können angepasst werden und sind in der prompts.py ( llm_answer_relevance_instruction , llm_context_recall_instruction , llm_context_precision_instruction ) enthalten.
Abrufbasierte Metriken: MAP-Scores werden berechnet, indem jeder abgerufene Chunk mit der Frage und dem Chunk verglichen wird, mit dem das QNA-Paar generiert wird. Um zu beurteilen, ob ein abgerufener Teil relevant ist oder nicht, wird die Ähnlichkeit zwischen dem abgerufenen Stück und der Verkettung der Endbenutzerfrage und dem im QNA -Schritt ( 02_qa_generation.py ) verwendeten Stör mit dem Spacevaluator berechnet. Die Ähnlichkeit der Spacy -Ähnlichkeit stand im Durchschnitt der Token -Vektoren, was bedeutet, dass die Berechnung unempfindlich gegenüber der Reihenfolge der Wörter ist. Standardmäßig ist der Ähnlichkeitsschwellenwert auf 80% ( spacy_evaluator.py ).
Wir begrüßen Ihre Beiträge und Vorschläge. Um einen Beitrag zu leisten, müssen Sie einer Contributor Lizenzvereinbarung (CLA) zustimmen, die bestätigt, dass Sie das Recht haben und uns tatsächlich tun, um uns die Rechte zu gewähren, Ihren Beitrag zu verwenden. Weitere Informationen finden Sie unter [https://cla.opensource.microsoft.com].
Wenn Sie eine Pull -Anfrage einreichen, prüft ein Cla -Bot automatisch, ob Sie einen CLA bereitstellen und Ihnen Anweisungen geben müssen (z. B. Statusprüfung, Kommentar). Befolgen Sie die Anweisungen aus dem Bot. Sie müssen dies nur einmal für alle Repos tun, die unseren CLA verwenden.
Bevor Sie dazu beitragen, stellen Sie sicher, dass Sie laufen
pip install -e .
pre-commit install
Dieses Projekt folgt dem Microsoft Open Source -Verhaltenscode. Weitere Informationen finden Sie im FAQ oder wenden Sie sich an [email protected] mit Fragen oder Kommentaren.
bug/11-short-descriptionfeature/22-short-descriptionexample_snake_case .git config --global user.name "First Last"Dieses Projekt kann Marken oder Logos für Projekte, Produkte oder Dienstleistungen enthalten. Sie müssen die Marken- und Markenrichtlinien von Microsoft befolgen, um Microsoft -Marken oder Logos korrekt zu verwenden. Verwenden Sie keine Microsoft -Marken oder Logos in modifizierten Versionen dieses Projekts auf eine Weise, die Verwirrung verursacht oder Microsoft -Sponsoring impliziert. Befolgen Sie die Richtlinien von Marken oder Logos von Drittanbietern, die dieses Projekt enthält.


