rag experiment accelerator
1.0.0
يعد مسرع تجربة RACK أداة متعددة الاستخدامات تساعدك على إجراء تجارب وتقييمات باستخدام Azure AI Search و RAG. يوفر هذا المستند دليلًا شاملاً يغطي كل ما تحتاج إلى معرفته حول هذه الأداة ، مثل الغرض والميزات والتركيب والاستخدام والمزيد.
الهدف الرئيسي من تسريع تجربة RAG هو جعل من الأسهل وأسرع إجراء تجارب وتقييمات لاستعلامات البحث وجودة الاستجابة من Openai. هذه الأداة مفيدة للباحثين وعلماء البيانات والمطورين الذين يرغبون في:
18 مارس 2024: تمت إضافة أخذ عينات المحتوى. ستسمح هذه الوظيفة بأخذ عينات من مجموعة البيانات بنسبة مئوية محددة. يتم تجميع البيانات بواسطة المحتوى ثم يتم أخذ نسبة العينة عبر كل مجموعة لمحاولة توزيع البيانات التي تم أخذ عينات منها.
يتم ذلك لضمان نتائج التمثيلية في العينة التي يمكن للمرء عبرها عبر مجموعة البيانات بأكملها.
ملاحظة : يوصى بإعادة بناء بيئتك إذا كنت قد استخدمت هذه الأداة من قبل بسبب التبعيات الجديدة.
مسرع تجربة RAG هو التكوين مدفوع ويوفر مجموعة غنية من الميزات لدعم الغرض منها:
إعداد التجربة : يمكنك تحديد وتكوين التجارب عن طريق تحديد مجموعة من معلمات محرك البحث ، وأنواع البحث ، ومجموعات الاستعلام ، ومقاييس التقييم.
التكامل : يدمج بسلاسة مع Azure AI Search و Azure Machine Learning و Mlflow و Azure Openai.
فهرس البحث الغني : إنه ينشئ فهارس بحث متعددة بناءً على تكوينات Hyperparameter المتاحة في ملف التكوين.
لوادر مستندات متعددة : تدعم الأداة لوادر مستندات متعددة ، بما في ذلك التحميل عبر ذكاء وثيقة Azure و Langchain Loaders الأساسية. يمنحك هذا المرونة لتجربة طرق الاستخراج المختلفة وتقييم فعاليتها.
محمل ذكاء المستند المخصص : عند تحديد نموذج واجهة برمجة تطبيقات "layout" المسبق لذكاء المستند ، تستخدم الأداة محملًا مخصصًا لذكاء المستند لتحميل البيانات. يدعم هذا المحمل المخصص تنسيق الجداول مع رؤوس الأعمدة في أزواج القيمة الرئيسية (لتعزيز قابلية القراءة لـ LLM) ، يستبعد الأجزاء غير ذات الصلة من الملف لـ LLM (مثل أرقام الصفحات والتذييلات) ، ويزيل الأنماط المتكررة في الملف باستخدام regex ، وأكثر. نظرًا لأن كل صف جدول يتم تحويله إلى خط نص ، لتجنب كسر صف في الوسط ، يتم التقطيع بشكل متكرر حسب الفقرة والخط. يلجأ اللودر المخصص إلى طراز API "البسيط" الأبسط "كإحداث احتياطي" عند فشل "Layout". أي نموذج API آخر سيستخدم تطبيق Langchain ، والذي يعيد الاستجابة الأولية من واجهة برمجة تطبيقات Document Intelligence.
توليد الاستعلام : يمكن للأداة إنشاء مجموعة متنوعة من مجموعات الاستعلام المتنوعة والقابلة للتخصيص ، والتي يمكن تصميمها لتلبية احتياجات التجربة المحددة.
أنواع البحث المتعددة : يدعم أنواع البحث المتعددة ، بما في ذلك النص النقي ، المتجه النقي ، المتقاطع ، والمستقلبات المتعددة ، والهجينة ، وأكثر من ذلك. يمنحك هذا القدرة على إجراء تحليل شامل على قدرات البحث والنتائج.
الربع الفرعي : يقوم النمط بتقييم استعلام المستخدم ، وإذا وجد أنه معقد بما فيه الكفاية ، فإنه يحطمه إلى أعطال فرعية أصغر لإنشاء سياق ذي صلة.
إعادة التصنيف : يتم إعادة تقييم استجابات الاستعلام من Azure AI باستخدام LLM وتصنيفها وفقًا للأهمية بين الاستعلام والسياق.
المقاييس والتقييم : يدعم المقاييس من طرف إلى طرف مقارنة الإجابات التي تم إنشاؤها (الفعلي) مقابل إجابات الحقيقة الأرضية (المتوقعة) ، بما في ذلك مقاييس التشابه القائمة على المسافة وجيب التمام والدلالي. ويتضمن أيضًا مقاييس قائمة على المكونات لتقييم أداء الاسترجاع والأداء باستخدام LLMs كقضاة ، مثل استدعاء السياق أو صلة الإجابة ، بالإضافة إلى مقاييس الاسترجاع لتقييم نتائج البحث (على سبيل المثال MAP@K).
توليد التقارير : يقوم مسرع تجربة RAG بأتمتة عملية توليد التقارير ، مع استكمال التصورات التي تجعل من السهل تحليل ومشاركة نتائج التجربة.
متعدد اللغات : تدعم الأداة تحليلات اللغة للدعم اللغوي على اللغات الفردية والمحللات المتخصصة (الغالبية الغاضبة) للأنماط المعرفة من قبل المستخدم على فهارس البحث. لمزيد من المعلومات ، راجع أنواع المحللين.
أخذ العينات : إذا كان لديك مجموعة بيانات كبيرة و/أو ترغب في تسريع التجربة ، تتوفر عملية أخذ العينات لإنشاء عينة صغيرة ولكن تمثيلية للبيانات للنسبة المئوية المحددة. سيتم تجميع البيانات بواسطة المحتوى وسيتم اختيار نسبة مئوية من كل مجموعة كجزء من العينة. يجب أن تكون النتائج التي تم الحصول عليها مؤشراً تقريبًا على مجموعة البيانات الكاملة ضمن هامش ~ 10 ٪. بمجرد تحديد النهج ، يوصى بتشغيل مجموعة البيانات الكاملة للحصول على نتائج دقيقة.
في الوقت الحالي ، يمكن تشغيل تسريع تجربة RAG محليًا للاستفادة من أحد ما يلي:
سيعني استخدام حاوية تطوير أن جميع البرامج المطلوبة مثبتة لك. هذا سوف يتطلب WSL. لمزيد من المعلومات حول حاويات التطوير ، تفضل بزيارة الحاويات.
قم بتثبيت البرنامج التالي على الجهاز المضيف ، ستقوم بإجراء النشر من:
- لنظام التشغيل Windows - Windows Store Ubuntu 22.04.3 LTS
- سطح المكتب Docker
- رمز الاستوديو البصري
- امتداد الكود: مراقبو عن بعد
يمكن العثور على مزيد من التوجيهات لإعداد WSL هنا. الآن لديك المتطلبات الأساسية ، يمكنك:
git clone https://github.com/microsoft/rag-experiment-accelerator.git
code .بمجرد أن يفتح المشروع في VSCODE ، يجب أن يسألك إذا كنت ترغب في "إعادة فتح هذا في حاوية تطوير". قل نعم.
يمكنك بالطبع تشغيل مسرع تجربة RAG على جهاز Windows/Mac إذا أردت ؛ أنت مسؤول عن تثبيت الأدوات الصحيحة. اتبع خطوات التثبيت هذه:
git clone https://github.com/microsoft/rag-experiment-accelerator.gitconda create -n rag-experiment python=3.11
conda init bashأغلق المحطة الخاصة بك ، افتح واحدة جديدة ، وقم بتشغيلها:
conda activate rag-experiment
pip install .az login
az account set --subscription= " <your_subscription_guid> "
az account showهناك 3 خيارات لتثبيت جميع خدمات Azure المطلوبة:
يدعم هذا المشروع مطور Azure CLI.
azd provisionazd up إذا كنت تفضل أن هذا يستدعي azd provision على أي حال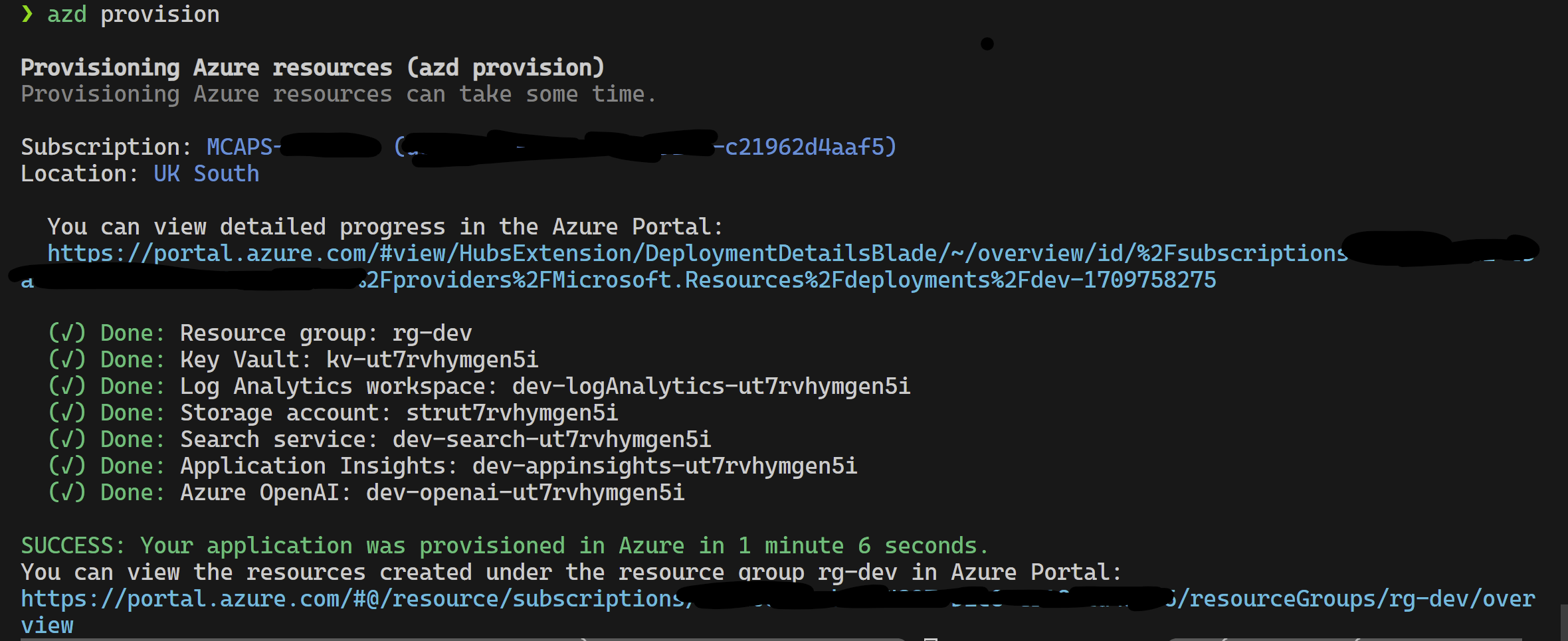
بمجرد الانتهاء من ذلك ، يمكنك استخدام تكوين الإطلاق لتشغيله ، أو تصحيح الخطوات الأربع وسيتم تحميل البيئة الحالية التي يتم توفيرها بواسطة azd بالقيم الصحيحة.
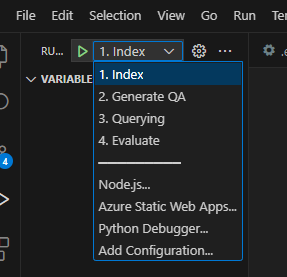
إذا كنت ترغب في نشر البنية التحتية بنفسك من القالب ، يمكنك أيضًا النقر هنا:
إذا كنت لا ترغب في استخدام azd فيمكنك استخدام az CLI العادي أيضًا.
استخدم الأمر التالي للنشر.
az login
az deployment sub create --subscription < subscription-id > --location < location > --template-file infra/main.bicepأو
للنشر مع الشبكة المعزولة استخدم الأمر التالي. استبدل قيم المعلمة بتفاصيل شبكتك المعزولة. يجب عليك توفير جميع المعلمات الثلاثة (أي vnetAddressSpace و proxySubnetAddressSpace و subnetAddressSpace ) إذا كنت ترغب في النشر على شبكة معزولة.
az login
az deployment sub create --location < location > --template-file infra/main.bicep
--parameters vnetAddressSpace= < vnet-address-space >
--parameters proxySubnetAddressSpace= < proxy-subnet-address-space >
--parameters subnetAddressSpace= < azure-subnet-address-space >فيما يلي مثال على قيم المعلمات:
az deployment sub create --location uksouth --template-file infra/main.bicep
--parameters vnetAddressSpace= ' 10.0.0.0/16 '
--parameters proxySubnetAddressSpace= ' 10.0.1.0/24 '
--parameters subnetAddressSpace= ' 10.0.2.0/24 ' لاستخدام مسرع تجربة الخرقة محليًا ، اتبع هذه الخطوات:
انسخ ملف .env.template إلى ملف يسمى .env وتحديث جميع القيم المطلوبة. ستأتي العديد من القيم المطلوبة لملف .env من الموارد التي تم تكوينها مسبقًا و/أو يمكن جمعها من الموارد التي يتم توفيرها في قسم البنية التحتية للتوفير. لاحظ أيضًا ، بشكل افتراضي ، يتم تعيين LOGGING_LEVEL على INFO ولكن يمكن تغييره إلى أي من المستويات التالية: NOTSET ، DEBUG ، INFO ، WARN ، ERROR ، CRITICAL .
cp .env.template .env
# change parameters manually انسخ ملف config.sample.json المقدم إلى ملف يدعى config.json وقم بتغيير أي فرطميات لتصميم تجربتك.
cp config.sample.json config.json
# change parameters manually انسخ أي ملفات للابتلاع (PDF ، HTML ، Markdown ، Text ، JSON أو DOCX Format) في مجلد data .
قم بتشغيل 01_index.py (Python 01_index.py) لإنشاء فهارس بحث Azure AI وتحميل البيانات فيها.
python 01_index.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " قم بتشغيل 02_qa_generation.py (Python 02_qa_generation.py) لإنشاء أزواج إجابات أسئلة باستخدام Azure Openai.
python 02_qa_generation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " قم بتشغيل 03_querying.py (Python 03_querying.py) للاستعلام عن Azure AI Search لإنشاء السياق ، وإعادة تشغيل العناصر في السياق ، والحصول على استجابة من Azure Openai باستخدام السياق الجديد.
python 03_querying.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " قم بتشغيل 04_evaluation.py (Python 04_Evaluation.py) لحساب المقاييس باستخدام طرق مختلفة وإنشاء الرسوم البيانية والتقارير في التعلم الآلي Azure باستخدام تكامل MLFLOW.
python 04_evaluation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " بدلاً من ذلك ، يمكنك تشغيل الخطوات المذكورة أعلاه (بصرف النظر عن 02_qa_generation.py ) باستخدام خط أنابيب Azure ML. للقيام بذلك ، اتبع الدليل هنا.
سيتم تشغيل أخذ العينات محليًا لإنشاء شريحة صغيرة ولكن تمثيلية من البيانات. هذا يساعد في التجريب السريع ويحافظ على انخفاض التكاليف. يجب أن تكون النتائج التي تم الحصول عليها مؤشراً تقريبًا على مجموعة البيانات الكاملة ضمن هامش ~ 10 ٪. بمجرد تحديد النهج ، يوصى بتشغيل مجموعة البيانات الكاملة للحصول على نتائج دقيقة.
ملاحظة : لا يمكن تشغيل أخذ العينات محليًا إلا في هذه المرحلة ، في هذه المرحلة لا يتم دعمها على مجموعة حساب AML الموزعة. وبالتالي فإن العملية هي تشغيل أخذ العينات محليًا ثم استخدام مجموعة بيانات العينات التي تم إنشاؤها لتشغيلها على AML.
إذا كان لديك مجموعة بيانات كبيرة جدًا وترغب في تشغيل نهج مماثل لتذوق البيانات ، فيمكنك استخدام التنفيذ الموزع في الذاكرة Pyspark في مجموعة أدوات اكتشاف البيانات لمجموعة Microsoft Fabric أو Azure Synapse Analytics.
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"only_run_sampling" : " If set to true, this will only run the sampling step and will not create an index or any subsequent steps, use this if you want to build a small sampled dataset to run in AML " ,
"sample_percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 " ,
},ستنتج عملية أخذ العينات القطع الأثرية التالية في دليل أخذ العينات:
job_name الذي يحتوي على مجموعة فرعية من الملفات التي تم أخذ عينات منها ، يمكن تحديدها كسيطة --data_dir عند تشغيل العملية بأكملها على AML.
"optimum_k": auto Config على تلقائي ، فستحاول عملية أخذ العينات تعيين العدد الأمثل من المجموعات تلقائيًا. يمكن تجاوز هذا إذا كنت تعرف تقريبًا عدد الدلاء الواسعة من المحتوى الموجودة في بياناتك. سيتم إنشاء رسم بياني الكوع في مجلد أخذ العينات. 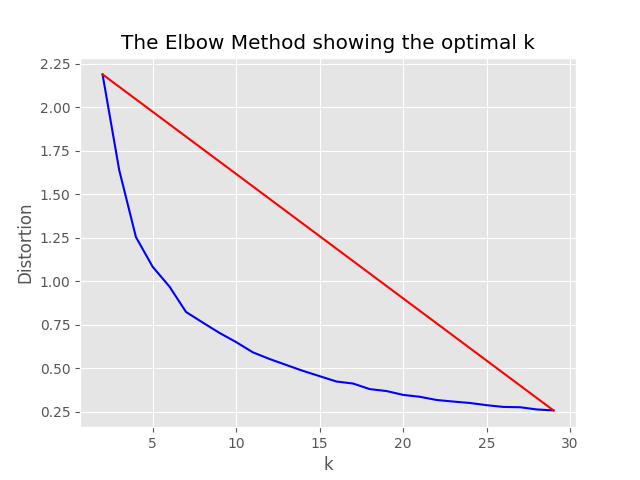
يوجد خياران لتشغيل أخذ العينات ، وهما:
اضبط القيم التالية لتشغيل عملية الفهرسة محليًا:
"sampling" : {
"sample_data" : true ,
"only_run_sampling" : false ,
"sample_percentage" : 10 ,
"optimum_k" : auto,
"min_cluster" : 2 ,
"max_cluster" : 30
}, إذا تم تعيين قيمة التكوين only_run_sampling على صحيح ، فسيقوم ذلك بتشغيل خطوة أخذ العينات فقط ، ولن يتم إنشاء أي فهرس ولن يتم تنفيذ أي خطوات لاحقة. قم بتعيين وسيطة --data_dir إلى الدليل الذي أنشأته عملية أخذ العينات والتي ستكون:
artifacts/sampling/config.[job_name] وتنفيذ خطوة خط أنابيب AML.
جميع القيم يمكن أن تكون قوائم العناصر. بما في ذلك التكوينات المتداخلة. ستنتج كل صفيف مجموعات من التكوينات المسطحة عندما يتم استدعاء الطريقة flatten() في عقدة معينة ، لتحديد مجموعة عشوائية واحدة - استدعاء sample() .
{
"experiment_name" : " If provided, this will be the experiment name in Azure ML and it will group all job run under the same experiment, otherwise (if left empty) index_name_prefix will be used and there may be more than one experiment " ,
"job_name" : " If provided, all jobs runs in Azure ML will be named with this property value plus timestamp, otherwise (if left empty) each job with be named only with timestamp " ,
"job_description" : " You may provide a description for the current job run which describes in words what you are about to experiment with " ,
"data_formats" : " Specifies the supported data formats for the application. You can choose from a variety of formats such as JSON, CSV, PDF, and more. [*] - means all formats included " ,
"main_instruction" : " Defines the main instruction prompt coming with queries to LLM " ,
"use_checkpoints" : " A boolean. If true, enables use of checkpoints to load data and skip processing that was already done in previous executions. " ,
"index" : {
"index_name_prefix" : " Search index name prefix " ,
"ef_construction" : " ef_construction value determines the value of Azure AI Search vector configuration. " ,
"ef_search" : " ef_search value determines the value of Azure AI Search vector configuration. " ,
"chunking" : {
"preprocess" : " A boolean. If true, preprocess documents, split into smaller chunks, embed and enrich them, and finally upload documents chunks for retrieval into Azure Search Index. " ,
"chunk_size" : " Size of each chunk e.g. [500, 1000, 2000] " ,
"overlap_size" : " Overlap Size for each chunk e.g. [100, 200, 300] " ,
"generate_title" : " A boolean. If true, a title is generated for the chunk of content and an embedding is created for it " ,
"generate_summary" : " A boolean. If true, a summary is generated for the chunk of content and an embedding is created for it " ,
"override_content_with_summary" : " A boolean. If true, The chunk content is replaced with its summary " ,
"chunking_strategy" : " determines the chunking strategy. Valid values are 'azure-document-intelligence' or 'basic' " ,
"azure_document_intelligence_model" : " represents the Azure Document Intelligence Model. Used when chunking strategy is 'azure-document-intelligence'. When set to 'prebuilt-layout', provides additional features (see above) "
},
"embedding_model" : " see 'Description of embedding models config' below " ,
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 "
}
},
"language" : {
"analyzer" : {
"analyzer_name" : " name of the analyzer to use for the field. This option can be used only with searchable fields and it can't be set together with either searchAnalyzer or indexAnalyzer. " ,
"index_analyzer_name" : " name of the analyzer used at indexing time for the field. This option can be used only with searchable fields. It must be set together with searchAnalyzer and it cannot be set together with the analyzer option. " ,
"search_analyzer_name" : " name of the analyzer used at search time for the field. This option can be used only with searchable fields. It must be set together with indexAnalyzer and it cannot be set together with the analyzer option. This property cannot be set to the name of a language analyzer; use the analyzer property instead if you need a language analyzer. " ,
"char_filters" : " The character filters for the index " ,
"tokenizers" : " The tokenizers for the index " ,
"token_filters" : " The token filters for the index "
},
"query_language" : " The language of the query. Possible values: en-us, en-gb, fr-fr etc. "
},
"rerank" : {
"enabled" : " determines if search results should be re-ranked. Value values are TRUE or FALSE " ,
"type" : " determines the type of re-ranking. Value values are llm or cross_encoder " ,
"llm_rerank_threshold" : " determines the threshold when using llm re-ranking. Chunks with rank above this number are selected in range from 1 - 10. " ,
"cross_encoder_at_k" : " determines the threshold when using cross-encoding re-ranking. Chunks with given rank value are selected. " ,
"cross_encoder_model" : " determines the model used for cross-encoding re-ranking step. Valid value is cross-encoder/stsb-roberta-base "
},
"search" : {
"retrieve_num_of_documents" : " determines the number of chunks to retrieve from the search index " ,
"search_type" : " determines the search types used for experimentation. Valid value are search_for_match_semantic, search_for_match_Hybrid_multi, search_for_match_Hybrid_cross, search_for_match_text, search_for_match_pure_vector, search_for_match_pure_vector_multi, search_for_match_pure_vector_cross, search_for_manual_hybrid. e.g. ['search_for_manual_hybrid', 'search_for_match_Hybrid_multi','search_for_match_semantic'] " ,
"search_relevancy_threshold" : " the similarity threshold to determine if a doc is relevant. Valid ranges are from 0.0 to 1.0 "
},
"query_expansion" : {
"expand_to_multiple_questions" : " whether the system should expand a single question into multiple related questions. By enabling this feature, you can generate a set of alternative related questions that may improve the retrieval process and provide more accurate results " .,
"query_expansion" : " determines if query expansion feature is on. Value values are TRUE or FALSE " ,
"hyde" : " this feature allows you to experiment with various query expansion approaches which may improve the retrieval metrics. The possible values are 'disabled' (default), 'generated_hypothetical_answer', 'generated_hypothetical_document_to_answer' reference article - Precise Zero-Shot Dense Retrieval without Relevance Labels (HyDE - Hypothetical Document Embeddings) - https://arxiv.org/abs/2212.10496 " ,
"min_query_expansion_related_question_similarity_score" : " minimum similarity score in percentage between LLM generated related queries to the original query using cosine similarly score. default 90% "
},
"openai" : {
"azure_oai_chat_deployment_name" : " determines the Azure OpenAI deployment name " ,
"azure_oai_eval_deployment_name" : " determines the Azure OpenAI deployment name used for evaluation " ,
"temperature" : " determines the OpenAI temperature. Valid value ranges from 0 to 1. "
},
"eval" : {
"metric_types" : " determines the metrics used for evaluation (end-to-end or component-wise metrics using LLMs). Valid values for end-to-end metrics are lcsstr, lcsseq, cosine, jaro_winkler, hamming, jaccard, levenshtein, fuzzy_score, cosine_ochiai, bert_all_MiniLM_L6_v2, bert_base_nli_mean_tokens, bert_large_nli_mean_tokens, bert_large_nli_stsb_mean_tokens, bert_distilbert_base_nli_stsb_mean_tokens, bert_paraphrase_multilingual_MiniLM_L12_v2. Valid values for component-wise LLM-based metrics are llm_answer_relevance, llm_context_precision and llm_context_recall. e.g ['fuzzy_score','bert_all_MiniLM_L6_v2','cosine_ochiai','bert_distilbert_base_nli_stsb_mean_tokens', 'llm_answer_relevance'] " ,
}
}ملاحظة: عند تغيير التكوين ، تذكر التغيير:
config.sample.json (مثال تكوينه ليتم نسخه من قبل الآخرين) embedding_model هو صفيف يحتوي على التكوين لنماذج التضمين المراد استخدامها. يجب أن يكون type نموذج التضمين azure لنماذج Azure Openai sentence-transformer لنماذج محول الجملة المعانقة.
{
"type" : " azure " ,
"model_name" : " the name of the Azure OpenAI model " ,
"dimension" : " the dimension of the embedding model. For example, 1536 which is the dimension of text-embedding-ada-002 "
} إذا كنت تستخدم نموذجًا آخر غير text-embedding-ada-002 ، فيجب عليك تحديد البعد المقابل للنموذج في حقل dimension ؛ على سبيل المثال:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 3072
}يمكن العثور على أبعاد نماذج Azure Openai للتضمين المختلفة في وثائق نماذج خدمة Azure Openai.
عند استخدام نماذج التضمين الأحدث (V3) ، يمكنك أيضًا الاستفادة من دعمها لتقصير التضمينات. في هذه الحالة ، حدد عدد الأبعاد التي تحتاجها ، وأضف علامة shorten_dimensions للإشارة إلى أنك تريد تقصير التضمين. على سبيل المثال:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 256 ,
"shorten_dimensions" : true
}{
"type" : " sentence-transformer " ,
"model_name" : " the name of the sentence transformer model " ,
"dimension" : " the dimension of the model. This field is not required if model name is one of ['all-MiniLM-L6-v2', 'all-mpnet-base-v2', 'bert-large-nli-mean-tokens] "
}إعطاء مثال على إجابة افتراضية للسؤال في الاستعلام ، قد يكون المقطع الافتراضي الذي يحمل إجابة على الاستعلام ، أو توليد القليل من الأسئلة البديلة ذات الصلة قد يحسن الاسترجاع وبالتالي الحصول على أجزاء أكثر دقة من المستندات للانتقال إلى سياق LLM. استنادًا إلى المقالة المرجعية - استرجاع كثيف بدقة صفرية بدون ملصقات ذات صلة (Hyde - تضمينات الوثيقة الافتراضية).
تدور خيارات التكوين التالية على نهج التجربة:
{
"hyde" : " generated_hypothetical_answer "
}{
"hyde" : " generated_hypothetical_document_to_answer "
} ستقوم هذه الميزة بإنشاء أسئلة ذات صلة دقيقة ، وتصفية تلك التي تكون أقل من min_query_expansion_related_question_similarity_score في المئة من الاستعلام الأصلي (باستخدام درجة تشابه جيب التمام) ، ووثائق البحث لكل واحد منها مع الاستعلام الأصلي ، ونتائج التكنولوجيا وإعادتها إلى Reranker و Top K steps.
القيمة الافتراضية لـ min_query_expansion_related_question_similarity_score تم تعيينها على 90 ٪ ، يمكنك تغيير هذا في config.json
{
"query_expansion" : true ,
"min_query_expansion_related_question_similarity_score" : 90
}يتكامل الحل مع التعلم الآلي Azure ويستخدم MLFlow لإدارة التجارب والوظائف والتحف. يمكنك عرض التقارير التالية كجزء من عملية التقييم:
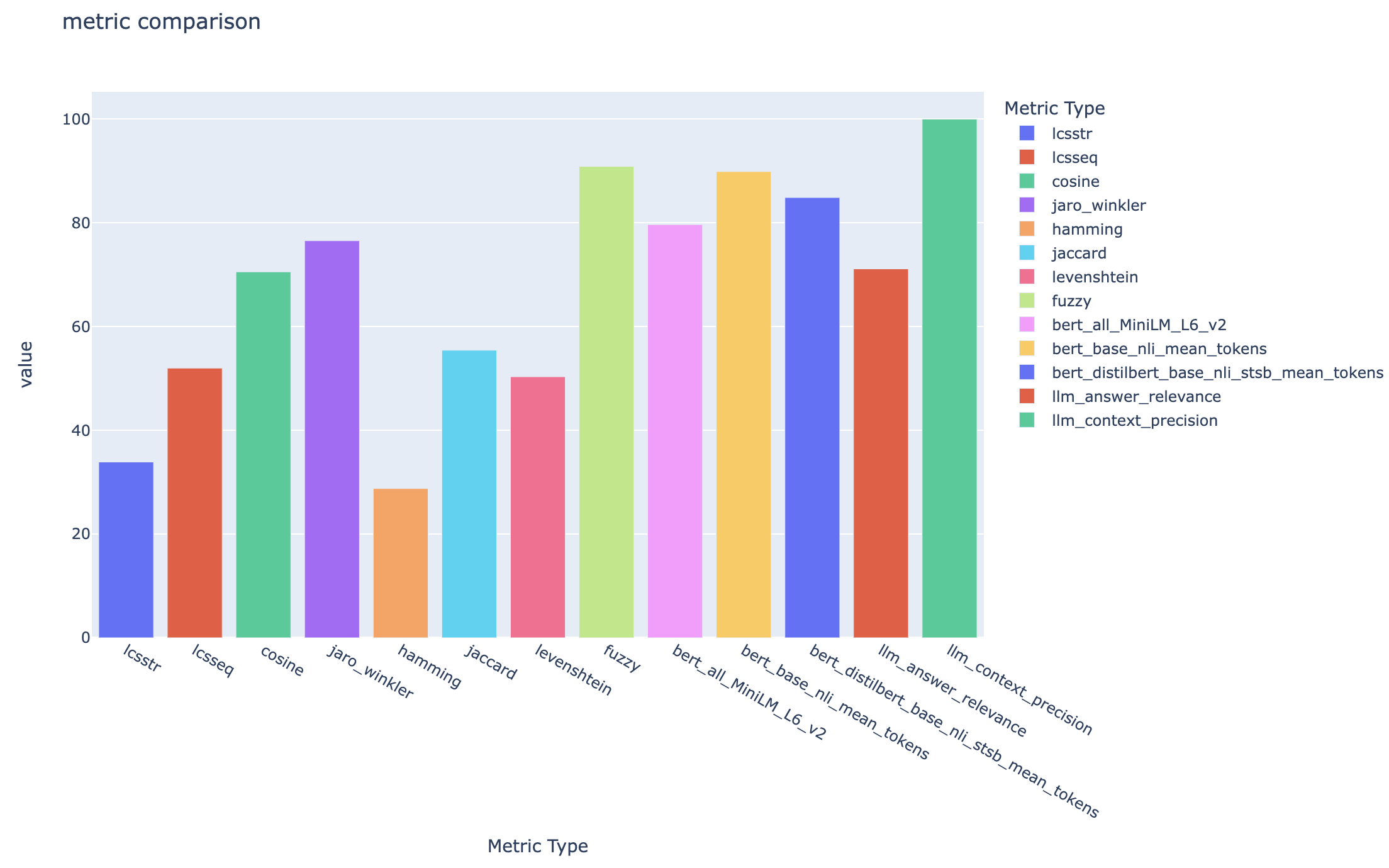
يعرض all_metrics_current_run.html متوسط الدرجات عبر الأسئلة وأنواع البحث لكل مقياس محدد:
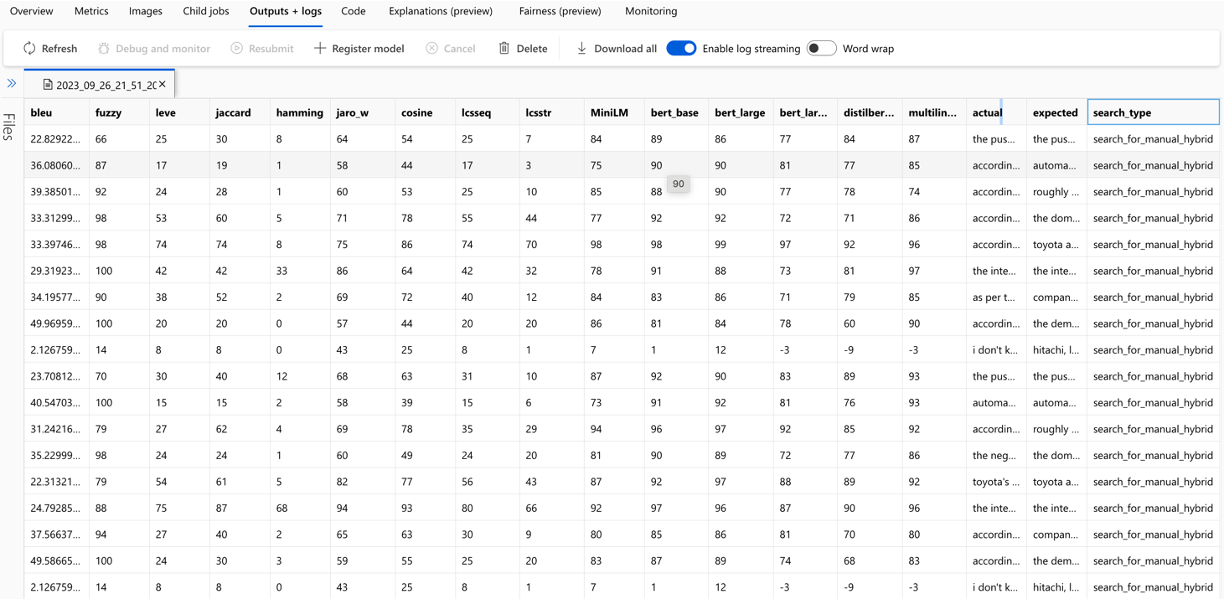
يتم تتبع حساب كل مقياس والحقول المستخدمة للتقييم لكل سؤال ونوع البحث في ملف CSV الإخراج:
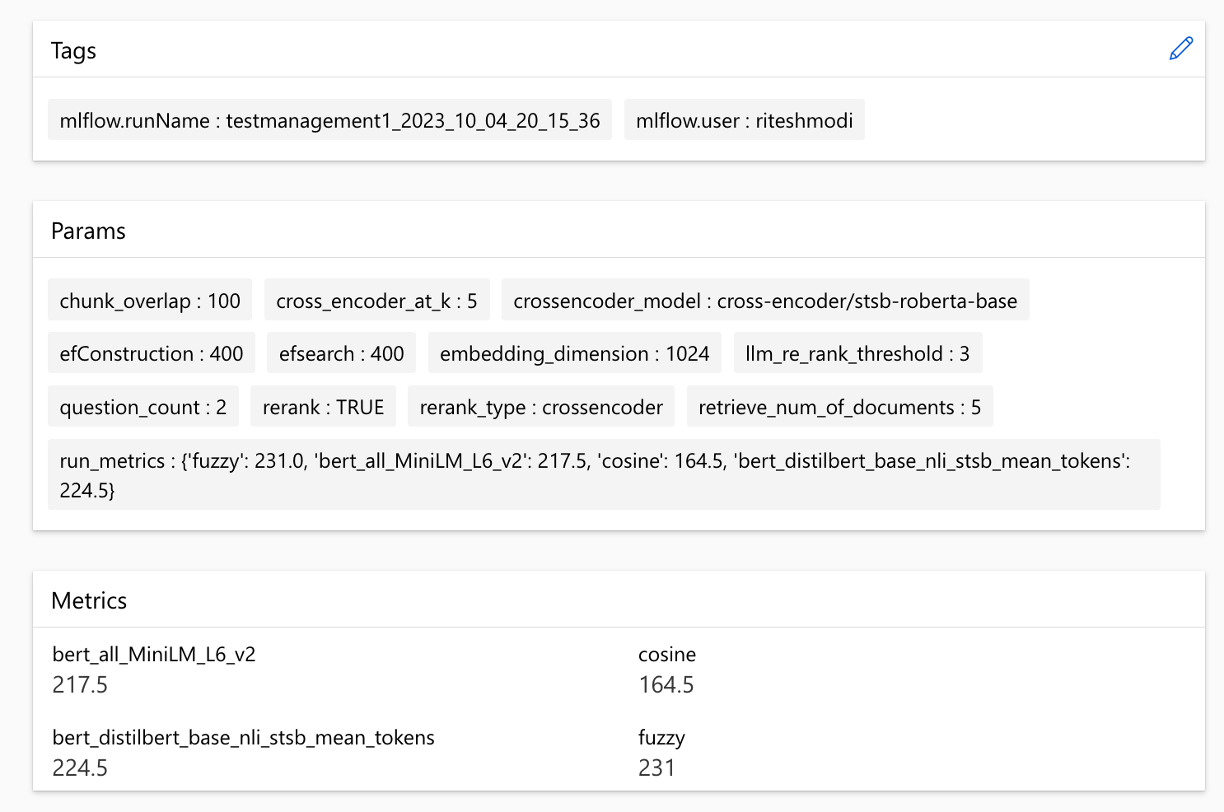
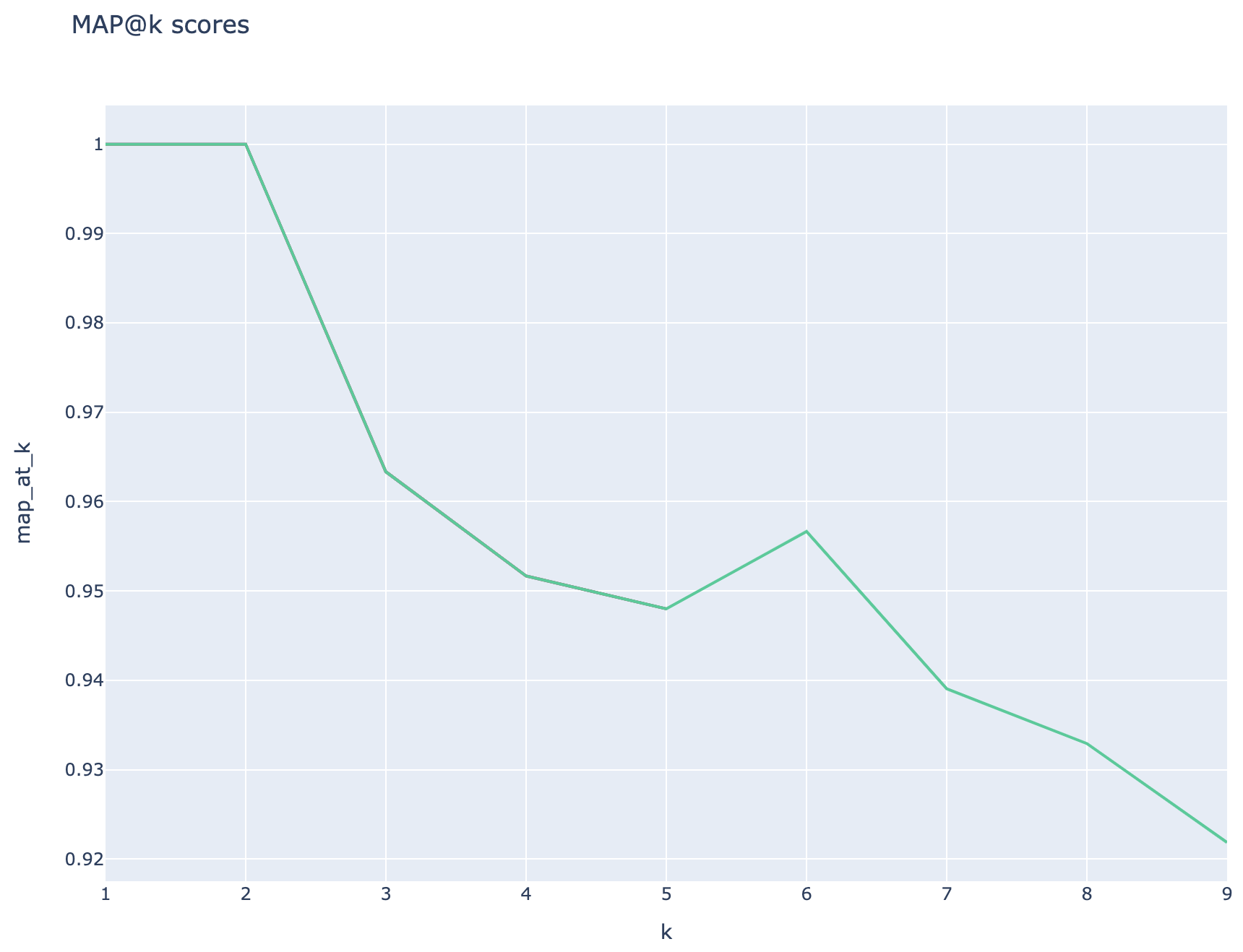
يمكن مقارنة المقاييس عبر أشواط:
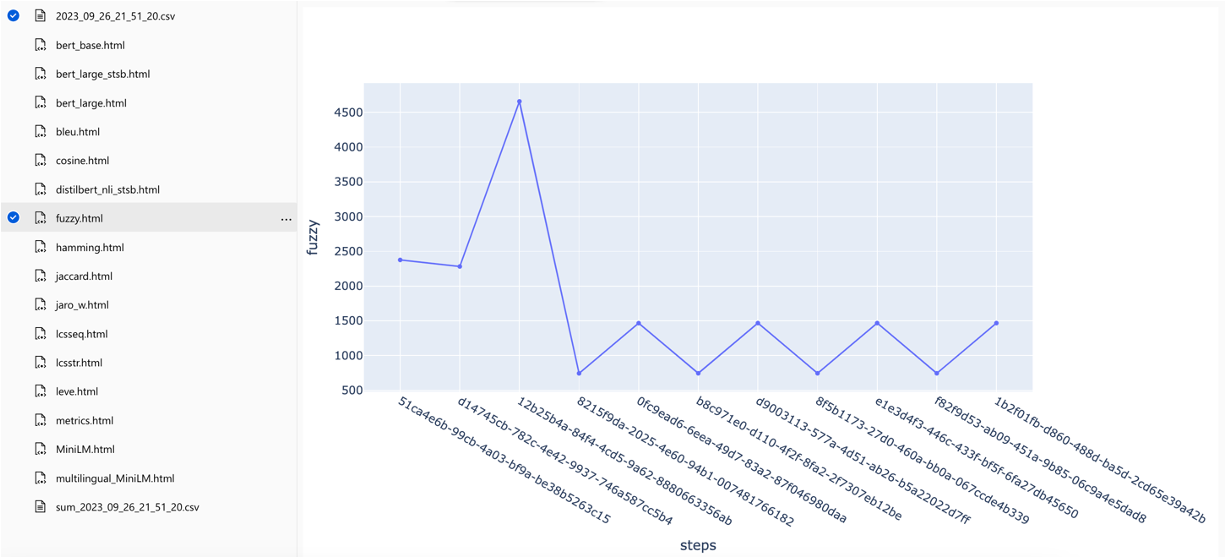
يمكن مقارنة المقاييس عبر استراتيجيات البحث المختلفة:
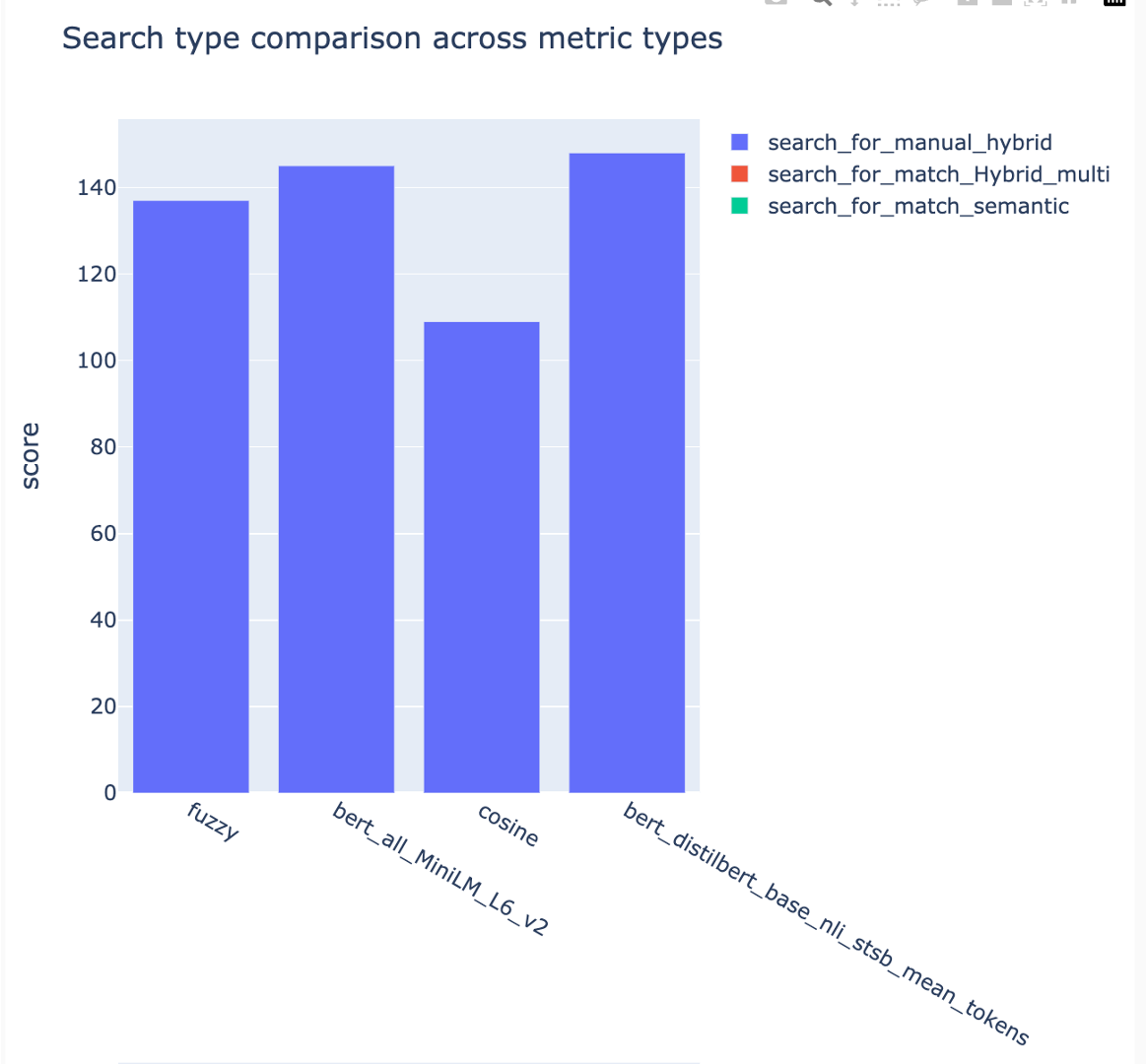
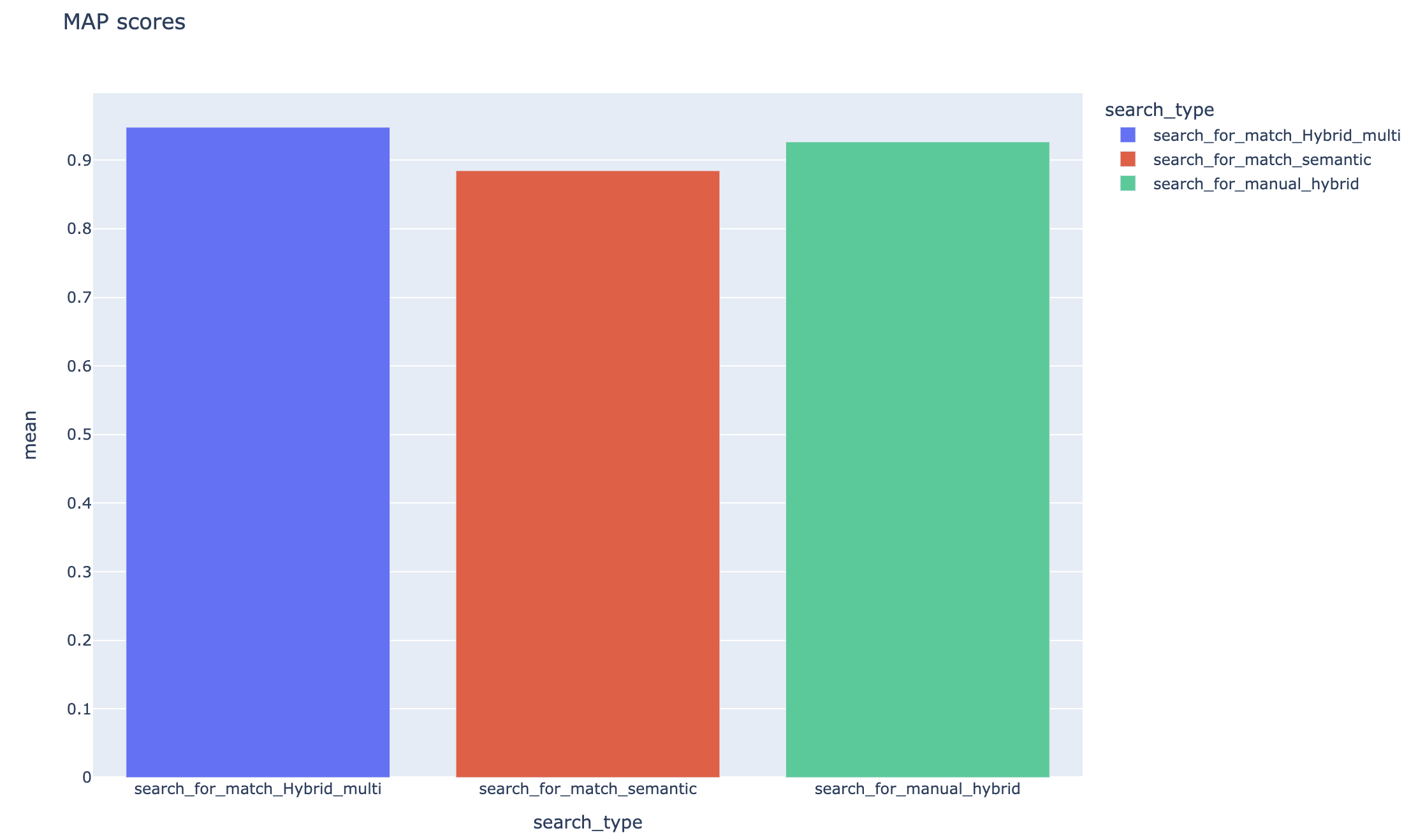
متوسط متوسط الدرجات الدقيقة يتم تتبعه ويمكن مقارنة متوسط درجات الخريطة عبر نوع البحث:
يوضح هذا القسم مسكات أو عيوب شائعة قد يواجهها المهندسون/المطورين/علماء البيانات أثناء العمل مع Rag Experience Accelerator.
لاستخدام هذا الحل بنجاح ، يجب عليك أولاً مصادقة نفسك عن طريق تسجيل الدخول إلى حساب Azure الخاص بك. تضمن هذه الخطوة الأساسية أن يكون لديك الأذونات المطلوبة للوصول إلى موارد Azure وإدارتها. قد تكون أخطاء تتعلق بتخزين بيانات QNA في أصول بيانات التعلم الآلي Azure ، وتنفيذ خطوة الاستعلام والتقييم نتيجة لترخيص ومصادقة غير لائقة إلى Azure. ارجع إلى النقطة 4 في هذا المستند للمصادقة والترخيص.
قد تكون هناك حالات لا يزال فيها الحل يولد أخطاء على الرغم من المصادقة والترخيص الصالحة. في مثل هذه الحالات ، ابدأ جلسة جديدة مع مثيل طرفي جديد تمامًا ، وتسجيل الدخول إلى Azure باستخدام الخطوات المذكورة في الخطوة 4 وأيضًا تحقق مما إذا كان المستخدم يساهم في الوصول إلى موارد Azure المتعلقة بالحل.
يستخدم هذا الحل العديد من معلمات التكوين في config.json التي تؤثر بشكل مباشر على وظائفها وأدائها. يرجى الانتباه عن كثب لهذه الإعدادات:
Retrieve_num_of_documents: يتحكم هذا التكوين في العدد الأولي للمستندات التي تم استردادها للتحليل. يمكن أن تؤدي القيم المرتفعة أو المنخفضة بشكل مفرط إلى أخطاء "فهرس خارج النطاق" بسبب معالجة تصنيف نتائج البحث عن الذكاء الاصطناعي.
cross_encoder_at_k: يؤثر هذا التكوين على عملية الترتيب. قد تؤدي القيمة العالية إلى تضمين مستندات غير ذات صلة في النتائج النهائية.
llm_rerank_threshold: يحدد هذا التكوين المستندات التي يتم تمريرها إلى نموذج اللغة (LLM) لمزيد من المعالجة. يمكن أن يؤدي تعيين هذه القيمة عالية جدًا إلى إنشاء سياق كبير للغاية لـ LLM للتعامل معه ، مما يؤدي إلى معالجة أخطاء أو نتائج متدهورة. قد يؤدي هذا أيضًا إلى استثناء من نقطة نهاية Azure Openai.
قبل تشغيل هذا الحل ، يرجى التأكد من قيامك بإعداد اسم نشر Azure Openai بشكل صحيح داخل ملف config.json وإضافة أسرار ذات صلة إلى متغيرات البيئة (ملف .env). هذه المعلومات أمر بالغ الأهمية للتطبيق للتواصل مع موارد Azure Openai المناسبة والوظيفة كما تم تصميمها. إذا كنت غير متأكد من بيانات التكوين ، فيرجى الرجوع إلى ملف .env.template و config.json. تم اختبار الحل باستخدام نموذج GPT 3.5 Turbo ويحتاج إلى اختبارات أخرى لأي نموذج آخر.
أثناء خطوة توليد QNA ، قد تواجه أحيانًا أخطاء تتعلق بإخراج JSON الذي تم استلامه من Azure Openai. يمكن لهذه الأخطاء أن تمنع الجيل الناجح من بعض الأسئلة والأجوبة. هذا ما تحتاج إلى معرفته:
التنسيق غير الصحيح: قد لا يلتزم إخراج JSON من Azure Openai بالتنسيق المتوقع ، مما يسبب مشكلات في عملية توليد QNA. تصفية المحتوى: يحتوي Azure Openai على مرشحات المحتوى في مكانها. إذا تم اعتبار نص الإدخال أو الاستجابات التي تم إنشاؤها غير مناسب ، فقد يؤدي ذلك إلى أخطاء. قيود API: تحتوي خدمة Azure Openai على قيود الرمز المميز والأسعار التي تؤثر على الإخراج.
مقاييس التقييم من طرف إلى طرف: لا تتمكن جميع المقاييس التي تقارن إجابات الحقيقة التي تم إنشاؤها والحماس الأرضي من التقاط الاختلافات في الدلالات. على سبيل المثال ، قياس مقاييس مثل levenshtein أو jaro_winkler فقط. لا يسمح مقياس cosine بمقارنة الدلالات إما: إنه يستخدم التنفيذ المستند إلى رمز TextDistance استنادًا إلى متجهات التردد المصطلح. لحساب التشابه الدلالي بين الإجابات التي تم إنشاؤها والاستجابات المتوقعة ، فكر في استخدام المقاييس القائمة على التضمين مثل درجات BERT ( bert_ ).
مقاييس التقييم المكون: مقاييس التقييم باستخدام LLM-as-accouns ليست حتمية. تستخدم مقاييس llm_ المدرجة في المسرع النموذج المشار إليه في حقل التكوين azure_oai_eval_deployment_name . يمكن تعديل المطالبات المستخدمة لتعليم التقييم وإدراجها في ملف prompts.py ( llm_answer_relevance_instruction ، llm_context_recall_instruction ، llm_context_precision_instruction ).
المقاييس القائمة على الاسترجاع: يتم حساب درجات MAP من خلال مقارنة كل قطعة تم استردادها مقابل السؤال والقطعة المستخدمة لإنشاء زوج QNA. لتقييم ما إذا كان الجزء الذي تم استرداده مناسبًا أم لا ، يتم حساب التشابه بين الجزء الذي تم استرداده وتسلسل سؤال المستخدم النهائي والقطعة المستخدمة في خطوة QNA ( 02_qa_generation.py ) باستخدام spacyevaluator. يتخلف تشابه Spacy إلى متوسط ناقلات الرمز المميز ، مما يعني أن الحساب غير حساس لترتيب الكلمات. بشكل افتراضي ، يتم تعيين عتبة التشابه على 80 ٪ ( spacy_evaluator.py ).
نرحب بمساهماتك واقتراحاتك. للمساهمة ، تحتاج إلى الموافقة على اتفاقية ترخيص المساهم (CLA) التي تؤكد أن لديك الحق في ذلك ، والقيام به ، في الواقع ، يمنحنا حقوق استخدام مساهمتك. لمزيد من التفاصيل ، تفضل بزيارة [https://cla.opensource.microsoft.com].
عند إرسال طلب سحب ، سيقوم CLA Bot بالتحقق تلقائيًا مما إذا كنت بحاجة إلى تقديم CLA وإعطائك تعليمات (على سبيل المثال ، التحقق من الحالة ، التعليق). اتبع التعليمات من الروبوت. ما عليك سوى القيام بذلك مرة واحدة لجميع إعادة الشراء التي تستخدم CLA لدينا.
قبل المساهمة ، تأكد من الركض
pip install -e .
pre-commit install
يتبع هذا المشروع رمز سلوك المصدر المفتوح Microsoft. لمزيد من المعلومات ، راجع برنامج Code of Conducted أو اتصل بـ [email protected] مع أي أسئلة أو تعليقات.
bug/11-short-descriptionfeature/22-short-descriptionexample_snake_case .git config --global user.name "First Last"قد يحتوي هذا المشروع على علامات تجارية أو شعارات للمشاريع أو المنتجات أو الخدمات. يجب عليك اتباع إرشادات العلامات التجارية والعلامة التجارية لشركة Microsoft لاستخدام علامات Microsoft التجارية أو الشعارات بشكل صحيح. لا تستخدم علامات Microsoft التجارية أو الشعارات في إصدارات معدلة من هذا المشروع بطريقة تسبب الارتباك أو تعني رعاية Microsoft. اتبع سياسات أي علامات تجارية أو شعارات تابعة لجهة خارجية تحتوي عليها هذا المشروع.


