rag experiment accelerator
1.0.0
L' accélérateur d'expérience RAG est un outil polyvalent qui vous aide à mener des expériences et des évaluations en utilisant la recherche Azure AI et le modèle de chiffon. Ce document fournit un guide complet qui couvre tout ce que vous devez savoir sur cet outil, tels que son objectif, ses fonctionnalités, son installation, son utilisation, etc.
L'objectif principal de l' accélérateur d'expérience RAG est de faciliter et plus rapidement des expériences et des évaluations des requêtes de recherche et de la qualité de la réponse d'OpenAI. Cet outil est utile pour les chercheurs, les scientifiques des données et les développeurs qui souhaitent:
18 mars 2024: Un échantillonnage de contenu a été ajouté. Cette fonctionnalité permettra à l'ensemble de données d'être échantillonné par un pourcentage spécifié. Les données sont regroupées par contenu, puis le pourcentage d'échantillon est prélevé sur chaque cluster pour tenter même la distribution des données échantillonnées.
Ceci est fait pour garantir les résultats représentatifs dans l'échantillon que l'on ferait passer sur l'ensemble de données.
Remarque : il est recommandé de reconstruire votre environnement si vous avez déjà utilisé cet outil en raison de nouvelles dépendances.
L' accélérateur de RAG Experiment est axé sur la configuration et propose un riche ensemble de fonctionnalités pour soutenir son objectif:
Configuration de l'expérience : vous pouvez définir et configurer des expériences en spécifiant une plage de paramètres de moteur de recherche, de types de recherche, de requêtes et de mesures d'évaluation.
Intégration : il s'intègre parfaitement à Azure AI Search, Azure Machine Learning, MLFlow et Azure OpenAI.
Rich Search Index : il crée plusieurs index de recherche basés sur des configurations d'hyperparamètre disponibles dans le fichier de configuration.
Plusieurs chargeurs de documents : l'outil prend en charge plusieurs chargeurs de documents, y compris le chargement via Azure Document Intelligence et Basic Langchain chargeurs. Cela vous donne la flexibilité d'expérimenter avec différentes méthodes d'extraction et d'évaluer leur efficacité.
Custom Document Intelligence Loader : Lors de la sélection du modèle API «pré-construit» pour l'intelligence de documents, l'outil utilise un chargeur de renseignement de document personnalisé pour charger les données. Ce chargeur personnalisé prend en charge le formatage des tables avec des en-têtes de colonne dans les paires de valeurs clés (pour améliorer la lisibilité pour le LLM), exclut les parties non pertinentes du fichier pour le LLM (telles que les numéros de page et les pieds de page), supprime les modèles récurrents dans le fichier à l'aide de Regex, et plus encore. Étant donné que chaque rangée de table est transformée en ligne de texte, pour éviter de casser une ligne au milieu, le groupe se fait récursivement par paragraphe et paragraphe. Le chargeur personnalisé recoure le modèle API «préfabillé« pré-construit »en tant que repli lorsque le« préfabriqué-Layout »échoue. Tout autre modèle API utilisera l'implémentation de Langchain, qui renvoie la réponse brute de l'API de Document Intelligence.
Génération de requêtes : l'outil peut générer une variété d'ensembles de requête divers et personnalisables, qui peuvent être adaptés à des besoins d'expérimentation spécifiques.
Plusieurs types de recherche : il prend en charge plusieurs types de recherche, y compris le texte pur, le vecteur pur, le vecteur croisé, le multi-vecteur, l'hybride, etc. Cela vous donne la possibilité d'effectuer une analyse complète sur les capacités de recherche et les résultats.
Sous-questionnement : le modèle évalue la requête utilisateur et si elle le trouve suffisamment complexe, elle la décompose en sous-questions plus petites pour générer un contexte pertinent.
Re-Ranking : les réponses de la requête de la recherche Azure AI sont réévaluées à l'aide de LLM et classées en fonction de la pertinence entre la requête et le contexte.
Métriques et évaluation : il prend en charge les mesures de bout en bout en comparant les réponses générées (réelles) aux réponses à la truth au sol (attendues), y compris les mesures de similitude en cosinus et sémantique. Il comprend également des mesures basées sur des composants pour évaluer les performances de récupération et de génération à l'aide de LLMS comme juges, tels que le rappel de contexte ou la pertinence de réponse, ainsi que des mesures de récupération pour évaluer les résultats de la recherche (par exemple MAP @ k).
Génération de rapports : L' accélérateur d'expérience RAG automatise le processus de génération de rapports, avec des visualisations qui facilitent l'analyse et partagent les résultats de l'expérience.
Multi-lingual : L'outil prend en charge les analyseurs de langues pour le support linguistique sur les langues individuelles et les analyseurs spécialisés (langage-agnostique) pour les modèles définis par l'utilisateur sur les index de recherche. Pour plus d'informations, voir les types d'analyseurs.
Échantillonnage : Si vous avez un grand ensemble de données et / ou que vous souhaitez accélérer l'expérimentation, un processus d'échantillonnage est disponible pour créer un petit échantillon mais représentatif des données pour le pourcentage spécifié. Les données seront regroupées par contenu et un pourcentage de chaque cluster sera sélectionné dans le cadre de l'échantillon. Les résultats obtenus doivent être à peu près indicatifs de l'ensemble de données complet dans une marge de ~ 10%. Une fois qu'une approche a été identifiée, l'exécution de l'ensemble de données complet est recommandée pour des résultats précis.
Pour le moment, l'accélérateur de l'expérience RAG peut être exécuté localement en tirant sur l'une des éléments suivants:
L'utilisation d'un conteneur de développement signifie que tous les logiciels requis sont installés pour vous. Cela nécessitera WSL. Pour plus d'informations sur les conteneurs de développement, visitez les conteneurs.dev
Installez le logiciel suivant sur la machine hôte, vous effectuez le déploiement à partir de:
- Pour Windows - Windows Store Ubuntu 22.04.3 LTS
- Docker Desktop
- Code Visual Studio
- Vs Extension de code: télécommandes
Des conseils supplémentaires sur la création de WSL peuvent être trouvés ici. Maintenant, vous avez les conditions préalables, vous pouvez:
git clone https://github.com/microsoft/rag-experiment-accelerator.git
code .Une fois le projet ouvert dans VSCODE, il devrait vous demander si vous souhaitez "rouvrir cela dans un conteneur de développement". Dites oui.
Vous pouvez bien sûr exécuter l' accélérateur d'expérience RAG sur une machine Windows / Mac si vous le souhaitez; Vous êtes responsable de l'installation de l'outillage correct. Suivez ces étapes d'installation:
git clone https://github.com/microsoft/rag-experiment-accelerator.gitconda create -n rag-experiment python=3.11
conda init bashFermez votre terminal, ouvrez un nouveau et exécutez:
conda activate rag-experiment
pip install .az login
az account set --subscription= " <your_subscription_guid> "
az account showIl existe 3 options pour installer tous les services Azure requis:
Ce projet soutient le développeur Azure CLI.
azd provisionazd up si vous préférez car cela appelle de toute façon azd provision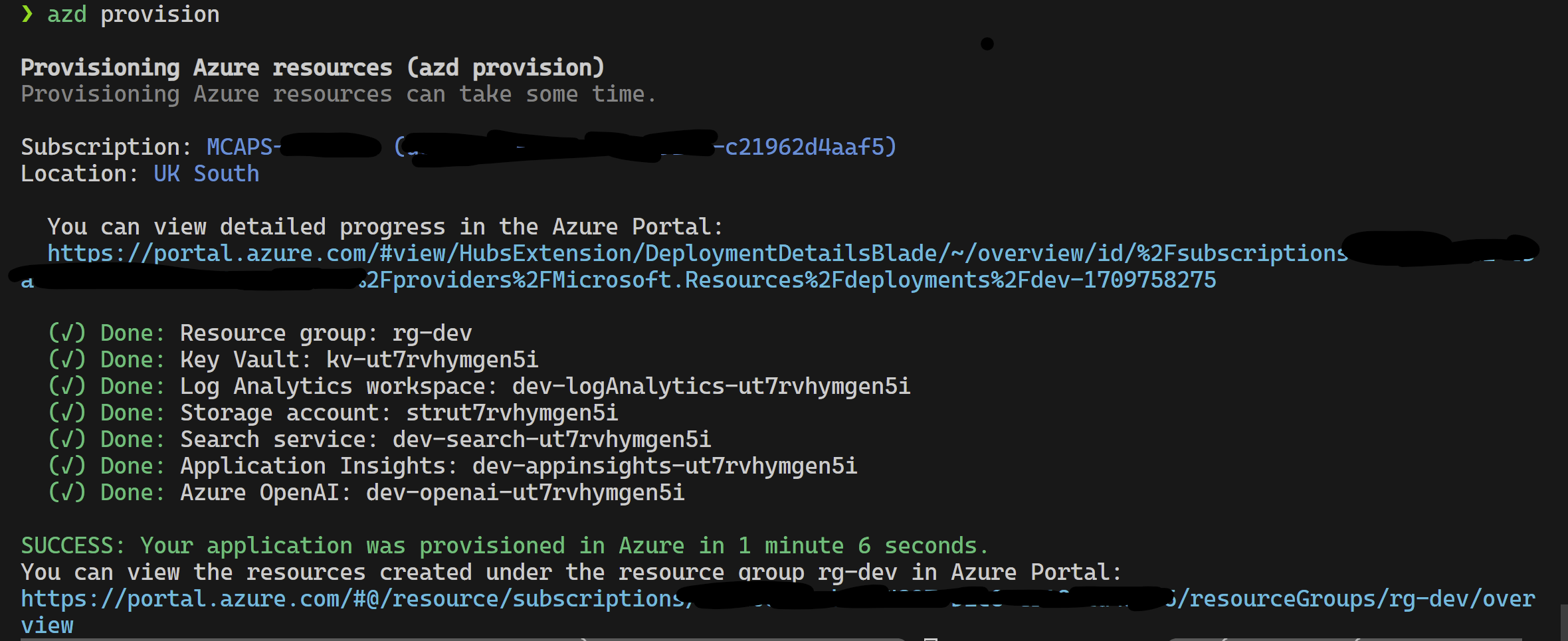
Une fois cela terminé, vous pouvez utiliser la configuration de lancement pour s'exécuter, ou déboguer les 4 étapes et l'environnement actuel fourni par azd sera chargé avec les valeurs correctes.
Si vous souhaitez déployer l'infrastructure vous-même à partir du modèle, vous pouvez également cliquer ici:
Si vous ne souhaitez pas utiliser azd vous pouvez également utiliser la CLI az normale.
Utilisez la commande suivante pour déployer.
az login
az deployment sub create --subscription < subscription-id > --location < location > --template-file infra/main.bicepOu
Pour déployer avec un réseau isolé, utilisez la commande suivante. Remplacez les valeurs des paramètres par les spécificités de votre réseau isolé. Vous devez fournir les trois paramètres (c'est-à-dire vnetAddressSpace , proxySubnetAddressSpace et subnetAddressSpace ) si vous souhaitez déployer sur un réseau isolé.
az login
az deployment sub create --location < location > --template-file infra/main.bicep
--parameters vnetAddressSpace= < vnet-address-space >
--parameters proxySubnetAddressSpace= < proxy-subnet-address-space >
--parameters subnetAddressSpace= < azure-subnet-address-space >Voici un exemple avec les valeurs des paramètres:
az deployment sub create --location uksouth --template-file infra/main.bicep
--parameters vnetAddressSpace= ' 10.0.0.0/16 '
--parameters proxySubnetAddressSpace= ' 10.0.1.0/24 '
--parameters subnetAddressSpace= ' 10.0.2.0/24 ' Pour utiliser l' accélérateur d'expérience RAG localement, suivez ces étapes:
Copiez le fichier .env.template fourni dans un fichier nommé .env et mettez à jour toutes les valeurs requises. Bon nombre des valeurs requises pour le fichier .env proviendront de ressources qui ont été précédemment configurées et / ou peuvent être recueillies à partir des ressources prévues dans la section d'infrastructure de disposition. Notez également, par défaut, LOGGING_LEVEL est défini sur INFO mais peut être modifié à l'un des niveaux suivants: NOTSET , DEBUG , INFO , WARN , ERROR , CRITICAL .
cp .env.template .env
# change parameters manually Copiez le fichier config.sample.json fourni dans un fichier nommé config.json et modifiez tous les hyperparamètres en fonction de votre expérience.
cp config.sample.json config.json
# change parameters manually Copiez tous les fichiers pour l'ingestion (PDF, HTML, Markdown, Text, JSON ou DOCX) dans le dossier data .
Exécutez 01_index.py (python 01_index.py) pour créer des index de recherche AZure AI et de charges les données.
python 01_index.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " Exécutez 02_qa_generation.py (python 02_qa_generation.py) pour générer des paires de questions-réponses à l'aide d'Azure Openai.
python 02_qa_generation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " Exécutez 03_querying.py (Python 03_Querying.py) pour interroger Azure Ai Search pour générer un contexte, ré-classez les éléments dans le contexte et obtenez la réponse d'Azure OpenAI en utilisant le nouveau contexte.
python 03_querying.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " Exécutez 04_evaluation.py (python 04_evaluation.py) pour calculer les métriques en utilisant diverses méthodes et générer des graphiques et des rapports dans l'apprentissage automatique Azure en utilisant l'intégration MLFlow.
python 04_evaluation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " Alternativement, vous pouvez exécuter les étapes ci-dessus (à l'exception de 02_qa_generation.py ) à l'aide d'un pipeline Azure ML. Pour ce faire, suivez le guide ici.
L'échantillonnage sera exécuté localement pour créer une tranche petite mais représentative des données. Cela aide à l'expérimentation rapide et maintient les coûts. Les résultats obtenus doivent être à peu près indicatifs de l'ensemble de données complet dans une marge de ~ 10%. Une fois qu'une approche a été identifiée, l'exécution de l'ensemble de données complet est recommandée pour des résultats précis.
Remarque : l'échantillonnage ne peut être exécuté que localement, à ce stade, il n'est pas pris en charge sur un cluster de calcul AML distribué. Le processus serait donc d'exécuter l'échantillonnage localement, puis d'utiliser l'échantillon de données généré pour s'exécuter sur AML.
Si vous avez un très grand ensemble de données et que vous souhaitez exécuter une approche similaire pour échantillonner les données, vous pouvez utiliser l'implémentation distribuée en mémoire Pyspark dans la boîte à outils de découverte de données pour Microsoft Fabric ou Azure Synapse Analytics.
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"only_run_sampling" : " If set to true, this will only run the sampling step and will not create an index or any subsequent steps, use this if you want to build a small sampled dataset to run in AML " ,
"sample_percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 " ,
},Le processus d'échantillonnage produira les artefacts suivants dans le répertoire d'échantillonnage:
job_name contenant le sous-ensemble de fichiers échantillonnés, ceux-ci peuvent être spécifiés comme argument --data_dir Lors de l'exécution de l'ensemble du processus sur AML.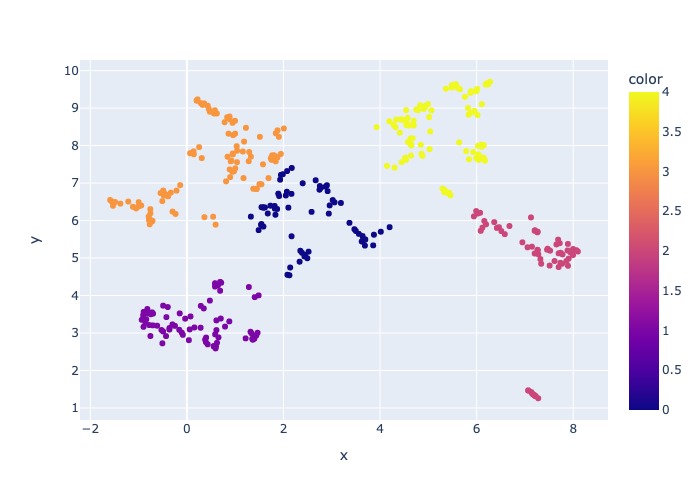
"optimum_k": auto Config est défini sur Auto, le processus d'échantillonnage tentera de définir automatiquement le nombre optimal de clusters. Cela peut être remplacé si vous savez à peu près combien de grands seaux de contenu existent dans vos données. Un graphique du coude sera généré dans le dossier d'échantillonnage. 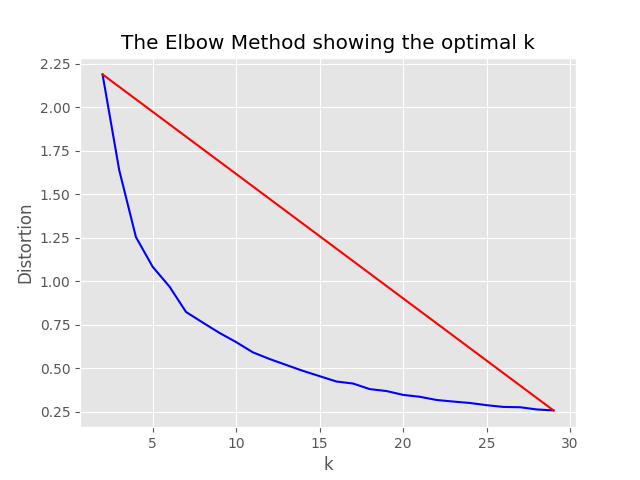
Deux options existent pour l'échantillonnage de l'exécution, à savoir:
Définissez les valeurs suivantes pour exécuter le processus d'indexation localement:
"sampling" : {
"sample_data" : true ,
"only_run_sampling" : false ,
"sample_percentage" : 10 ,
"optimum_k" : auto,
"min_cluster" : 2 ,
"max_cluster" : 30
}, Si only_run_sampling la valeur de configuration de la configuration est définie sur true, cela ne fera que l'exécution de l'étape d'échantillonnage, aucun index ne sera créé et toute autre étape suivante ne sera pas exécutée. Définissez l'argument --data_dir sur le répertoire créé par le processus d'échantillonnage qui sera:
artifacts/sampling/config.[job_name] et exécutez l'étape du pipeline AML.
Toutes les valeurs peuvent être des listes d'éléments. Y compris les configurations imbriquées. Chaque tableau produira les combinaisons de configurations plates lorsque la méthode flatten() est appelée sur un nœud particulier, pour sélectionner 1 combinaison aléatoire - appelez l' sample() .
{
"experiment_name" : " If provided, this will be the experiment name in Azure ML and it will group all job run under the same experiment, otherwise (if left empty) index_name_prefix will be used and there may be more than one experiment " ,
"job_name" : " If provided, all jobs runs in Azure ML will be named with this property value plus timestamp, otherwise (if left empty) each job with be named only with timestamp " ,
"job_description" : " You may provide a description for the current job run which describes in words what you are about to experiment with " ,
"data_formats" : " Specifies the supported data formats for the application. You can choose from a variety of formats such as JSON, CSV, PDF, and more. [*] - means all formats included " ,
"main_instruction" : " Defines the main instruction prompt coming with queries to LLM " ,
"use_checkpoints" : " A boolean. If true, enables use of checkpoints to load data and skip processing that was already done in previous executions. " ,
"index" : {
"index_name_prefix" : " Search index name prefix " ,
"ef_construction" : " ef_construction value determines the value of Azure AI Search vector configuration. " ,
"ef_search" : " ef_search value determines the value of Azure AI Search vector configuration. " ,
"chunking" : {
"preprocess" : " A boolean. If true, preprocess documents, split into smaller chunks, embed and enrich them, and finally upload documents chunks for retrieval into Azure Search Index. " ,
"chunk_size" : " Size of each chunk e.g. [500, 1000, 2000] " ,
"overlap_size" : " Overlap Size for each chunk e.g. [100, 200, 300] " ,
"generate_title" : " A boolean. If true, a title is generated for the chunk of content and an embedding is created for it " ,
"generate_summary" : " A boolean. If true, a summary is generated for the chunk of content and an embedding is created for it " ,
"override_content_with_summary" : " A boolean. If true, The chunk content is replaced with its summary " ,
"chunking_strategy" : " determines the chunking strategy. Valid values are 'azure-document-intelligence' or 'basic' " ,
"azure_document_intelligence_model" : " represents the Azure Document Intelligence Model. Used when chunking strategy is 'azure-document-intelligence'. When set to 'prebuilt-layout', provides additional features (see above) "
},
"embedding_model" : " see 'Description of embedding models config' below " ,
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 "
}
},
"language" : {
"analyzer" : {
"analyzer_name" : " name of the analyzer to use for the field. This option can be used only with searchable fields and it can't be set together with either searchAnalyzer or indexAnalyzer. " ,
"index_analyzer_name" : " name of the analyzer used at indexing time for the field. This option can be used only with searchable fields. It must be set together with searchAnalyzer and it cannot be set together with the analyzer option. " ,
"search_analyzer_name" : " name of the analyzer used at search time for the field. This option can be used only with searchable fields. It must be set together with indexAnalyzer and it cannot be set together with the analyzer option. This property cannot be set to the name of a language analyzer; use the analyzer property instead if you need a language analyzer. " ,
"char_filters" : " The character filters for the index " ,
"tokenizers" : " The tokenizers for the index " ,
"token_filters" : " The token filters for the index "
},
"query_language" : " The language of the query. Possible values: en-us, en-gb, fr-fr etc. "
},
"rerank" : {
"enabled" : " determines if search results should be re-ranked. Value values are TRUE or FALSE " ,
"type" : " determines the type of re-ranking. Value values are llm or cross_encoder " ,
"llm_rerank_threshold" : " determines the threshold when using llm re-ranking. Chunks with rank above this number are selected in range from 1 - 10. " ,
"cross_encoder_at_k" : " determines the threshold when using cross-encoding re-ranking. Chunks with given rank value are selected. " ,
"cross_encoder_model" : " determines the model used for cross-encoding re-ranking step. Valid value is cross-encoder/stsb-roberta-base "
},
"search" : {
"retrieve_num_of_documents" : " determines the number of chunks to retrieve from the search index " ,
"search_type" : " determines the search types used for experimentation. Valid value are search_for_match_semantic, search_for_match_Hybrid_multi, search_for_match_Hybrid_cross, search_for_match_text, search_for_match_pure_vector, search_for_match_pure_vector_multi, search_for_match_pure_vector_cross, search_for_manual_hybrid. e.g. ['search_for_manual_hybrid', 'search_for_match_Hybrid_multi','search_for_match_semantic'] " ,
"search_relevancy_threshold" : " the similarity threshold to determine if a doc is relevant. Valid ranges are from 0.0 to 1.0 "
},
"query_expansion" : {
"expand_to_multiple_questions" : " whether the system should expand a single question into multiple related questions. By enabling this feature, you can generate a set of alternative related questions that may improve the retrieval process and provide more accurate results " .,
"query_expansion" : " determines if query expansion feature is on. Value values are TRUE or FALSE " ,
"hyde" : " this feature allows you to experiment with various query expansion approaches which may improve the retrieval metrics. The possible values are 'disabled' (default), 'generated_hypothetical_answer', 'generated_hypothetical_document_to_answer' reference article - Precise Zero-Shot Dense Retrieval without Relevance Labels (HyDE - Hypothetical Document Embeddings) - https://arxiv.org/abs/2212.10496 " ,
"min_query_expansion_related_question_similarity_score" : " minimum similarity score in percentage between LLM generated related queries to the original query using cosine similarly score. default 90% "
},
"openai" : {
"azure_oai_chat_deployment_name" : " determines the Azure OpenAI deployment name " ,
"azure_oai_eval_deployment_name" : " determines the Azure OpenAI deployment name used for evaluation " ,
"temperature" : " determines the OpenAI temperature. Valid value ranges from 0 to 1. "
},
"eval" : {
"metric_types" : " determines the metrics used for evaluation (end-to-end or component-wise metrics using LLMs). Valid values for end-to-end metrics are lcsstr, lcsseq, cosine, jaro_winkler, hamming, jaccard, levenshtein, fuzzy_score, cosine_ochiai, bert_all_MiniLM_L6_v2, bert_base_nli_mean_tokens, bert_large_nli_mean_tokens, bert_large_nli_stsb_mean_tokens, bert_distilbert_base_nli_stsb_mean_tokens, bert_paraphrase_multilingual_MiniLM_L12_v2. Valid values for component-wise LLM-based metrics are llm_answer_relevance, llm_context_precision and llm_context_recall. e.g ['fuzzy_score','bert_all_MiniLM_L6_v2','cosine_ochiai','bert_distilbert_base_nli_stsb_mean_tokens', 'llm_answer_relevance'] " ,
}
}Remarque: Lorsque vous modifiez la configuration, n'oubliez pas de changer:
config.sample.json (l'exemple config à copier par d'autres) embedding_model est un tableau contenant la configuration pour les modèles d'intégration. type de modèle d'incorporation doit être azure pour les modèles Azure OpenAI et sentence-transformer pour les modèles de transformateur de phrase en étreinte.
{
"type" : " azure " ,
"model_name" : " the name of the Azure OpenAI model " ,
"dimension" : " the dimension of the embedding model. For example, 1536 which is the dimension of text-embedding-ada-002 "
} Si vous utilisez un modèle autre que text-embedding-ada-002 , vous devez spécifier la dimension correspondante du modèle dans le champ dimension ; Par exemple:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 3072
}Les dimensions pour les différents modèles Azure Openai Embeddings peuvent être trouvées dans la documentation des modèles de service Azure OpenAI.
Lorsque vous utilisez les nouveaux modèles d'incorporation (V3), vous pouvez également tirer parti de leur support pour le raccourcissement des incorporations. Dans ce cas, spécifiez le nombre de dimensions dont vous avez besoin et ajoutez l'indicateur shorten_dimensions pour indiquer que vous souhaitez raccourcir les intégres. Par exemple:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 256 ,
"shorten_dimensions" : true
}{
"type" : " sentence-transformer " ,
"model_name" : " the name of the sentence transformer model " ,
"dimension" : " the dimension of the model. This field is not required if model name is one of ['all-MiniLM-L6-v2', 'all-mpnet-base-v2', 'bert-large-nli-mean-tokens] "
}En donnant un exemple de réponse hypothétique à la question dans la requête, un passage hypothétique qui contient une réponse à la requête, ou générer peu de questions liées à une alternative pourrait améliorer la récupération et ainsi obtenir des morceaux de documents plus précis pour passer dans le contexte LLM. Sur la base de l'article de référence - une récupération dense précise zéro sans étiquettes de pertinence (Hyde - Hypothétique intégration de documents).
Les options de configuration suivantes activent cette approche d'expérimentation:
{
"hyde" : " generated_hypothetical_answer "
}{
"hyde" : " generated_hypothetical_document_to_answer "
} Cette fonctionnalité générera de belles questions liées, filtrera celles qui sont inférieures à min_query_expansion_related_question_similarity_score pour cent à partir de la requête d'origine (en utilisant le score de similitude en cosinus), et recherchent des documents pour chacun d'eux avec la requête d'origine, les résultats déduisés et les renvoyez dans les pas de remeranker et en haut.
La valeur par défaut pour min_query_expansion_related_question_similarity_score est définie sur 90%, vous pouvez le modifier dans la config.json
{
"query_expansion" : true ,
"min_query_expansion_related_question_similarity_score" : 90
}La solution s'intègre à l'apprentissage automatique Azure et utilise MLFlow pour gérer les expériences, les travaux et les artefacts. Vous pouvez afficher les rapports suivants dans le cadre du processus d'évaluation:
all_metrics_current_run.html affiche des scores moyens sur les questions et les types de recherche pour chaque métrique sélectionnée:
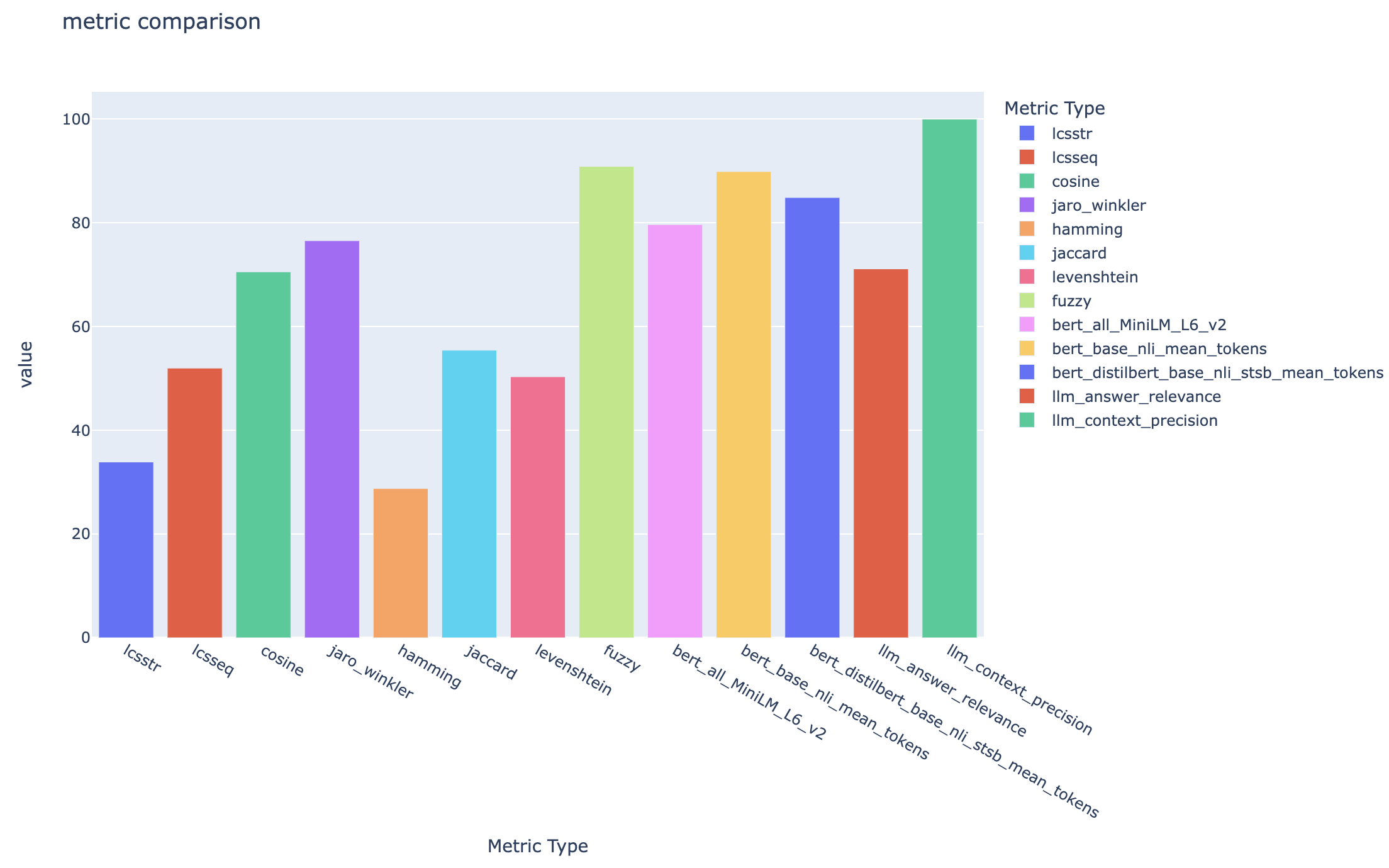
Le calcul de chaque métrique et des champs utilisés pour l'évaluation sont suivis pour chaque question et type de recherche dans le fichier CSV de sortie:
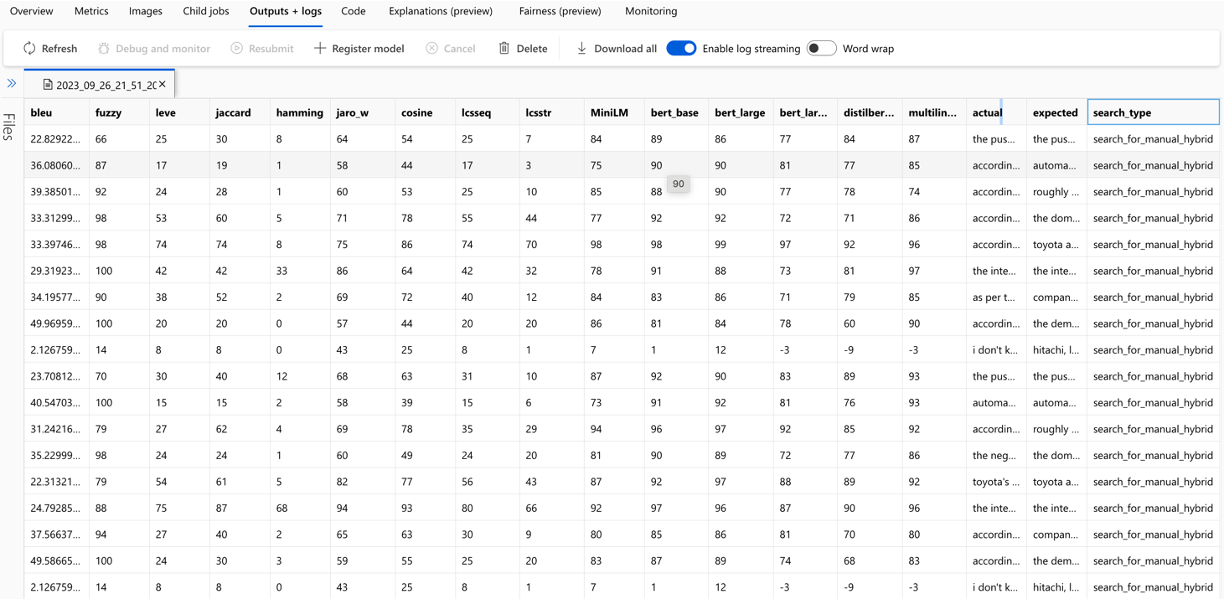
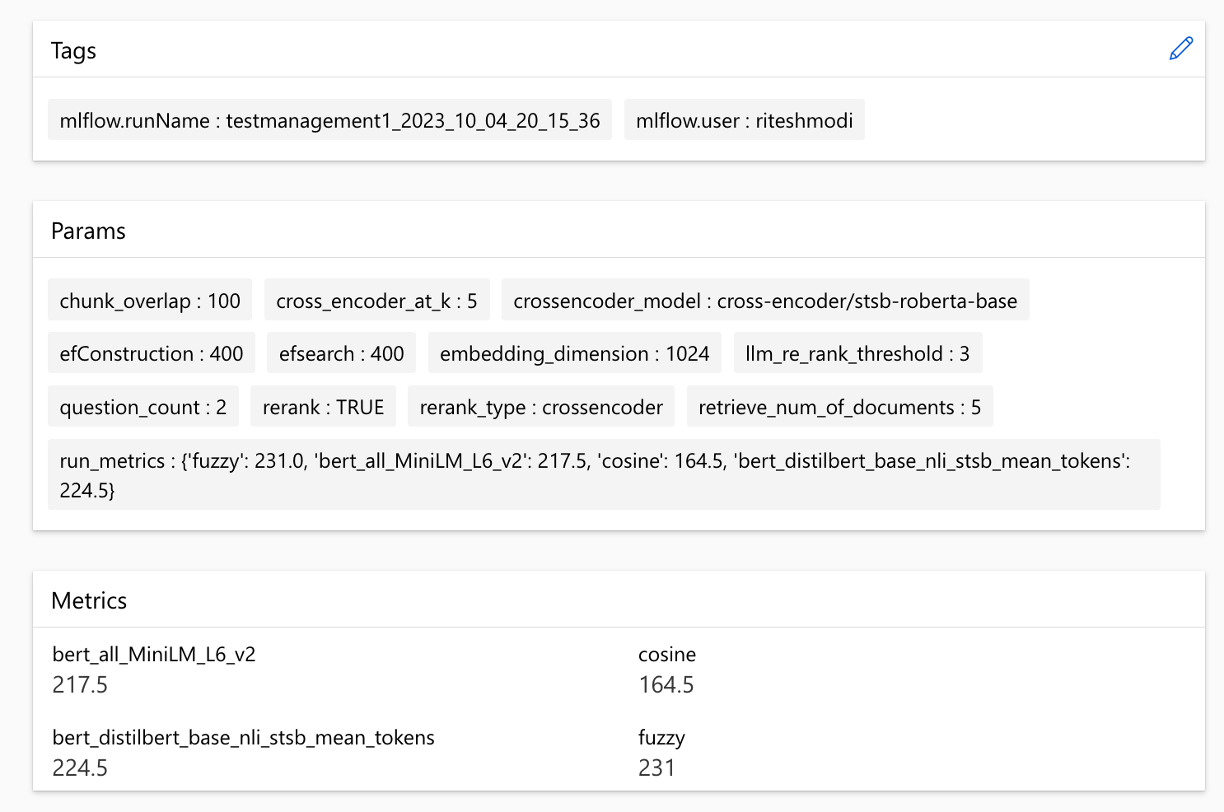
Les mesures peuvent être comparées entre les courses:
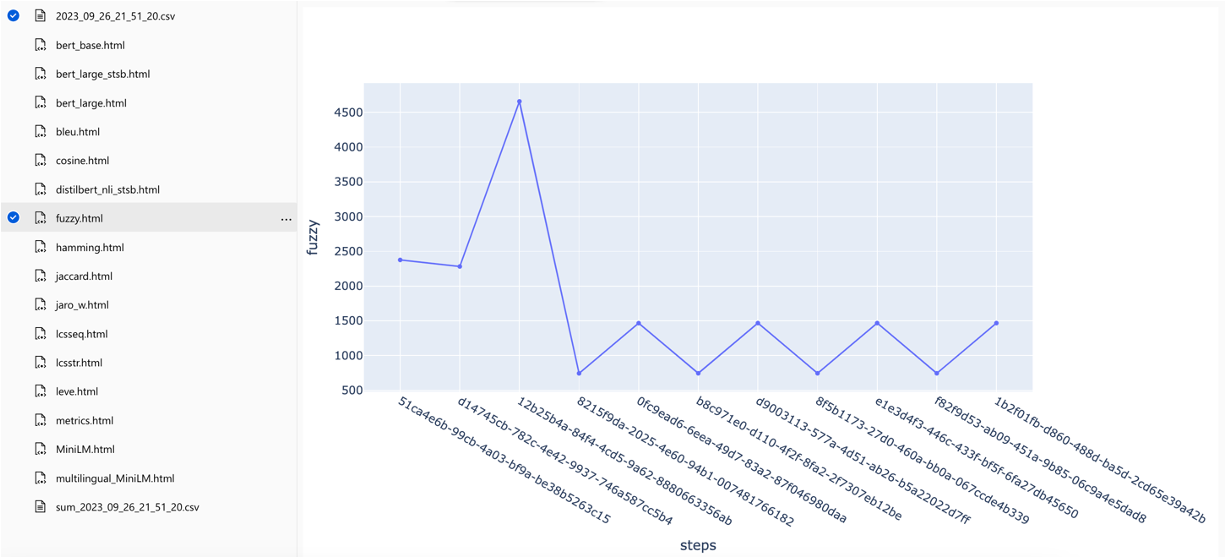
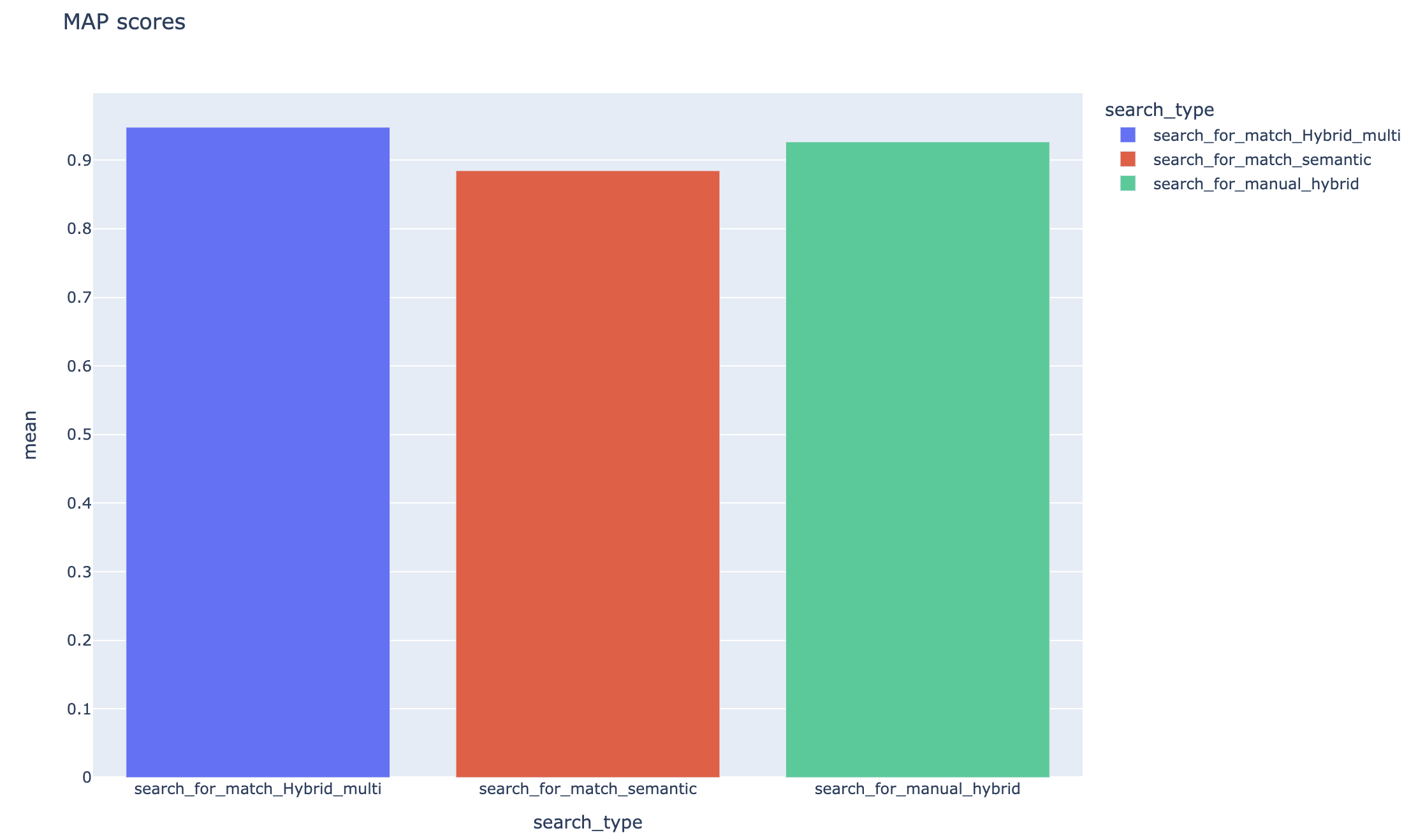
Les mesures peuvent être comparées à différentes stratégies de recherche:
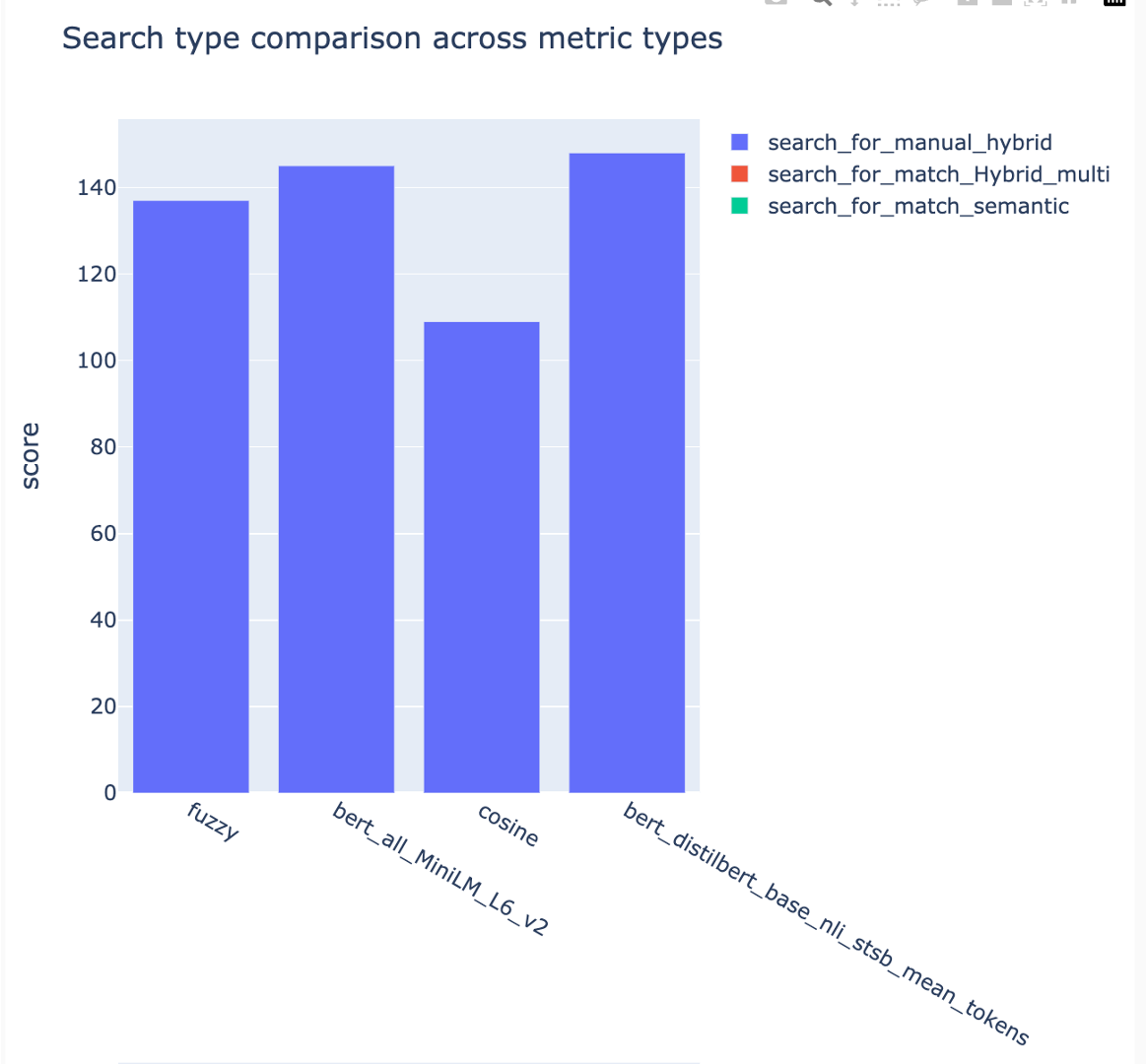
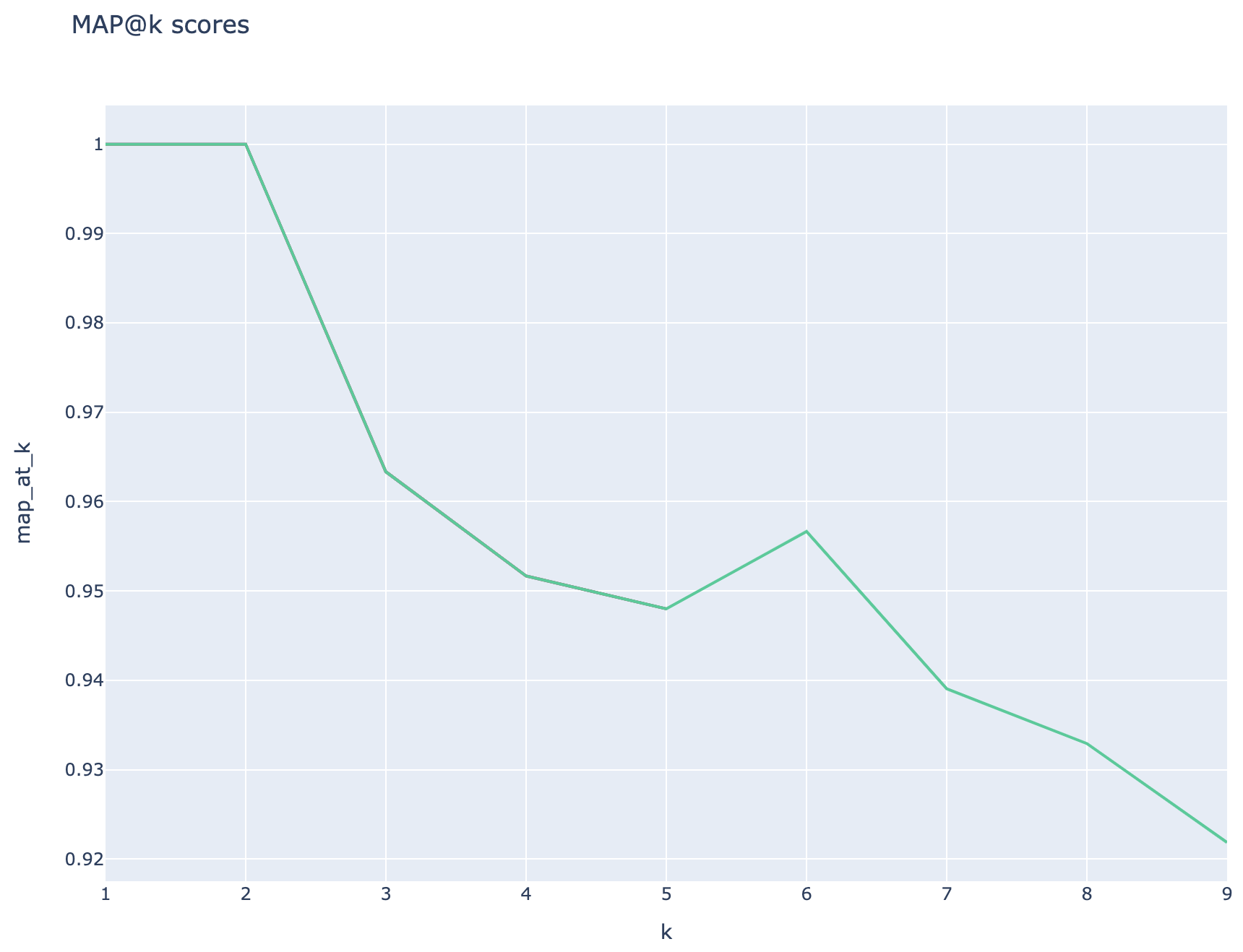
Les scores moyens de précision moyens sont suivis et les scores de carte moyens peuvent être comparés sur le type de recherche:
Cette section décrit les gatchas ou les pièges communs que les ingénieurs / développeurs / scientifiques des données peuvent rencontrer tout en travaillant avec RAG Experiment Accelerator.
Pour utiliser avec succès cette solution, vous devez d'abord vous authentifier en vous connectant à votre compte Azure. Cette étape essentielle garantit que vous disposez des autorisations requises pour accéder et gérer les ressources Azure utilisées par elle. Vous pouvez des erreurs liées au stockage des données QNA dans les actifs de données d'apprentissage automatique Azure, à l'exécution de l'étape de requête et d'évaluation en raison d'une autorisation et d'une authentification inappropriées à Azure. Reportez-vous au point 4 de ce document pour l'authentification et l'autorisation.
Il pourrait y avoir des situations dans lesquelles la solution générerait toujours des erreurs malgré l'authentification et l'autorisation valides. Dans de tels cas, démarrez une nouvelle session avec une toute nouvelle instance de terminal, connectez-vous à Azure en utilisant les étapes mentionnées à l'étape 4 et vérifiez également si l'utilisateur a contribué à l'accès aux ressources Azure liées à la solution.
Cette solution utilise plusieurs paramètres de configuration dans config.json qui ont un impact direct sur sa fonctionnalité et ses performances. Veuillez prêter une attention particulière à ces paramètres:
rétrive_num_of_documents: Cette configuration contrôle le nombre initial de documents récupérés pour l'analyse. Des valeurs excessivement élevées ou faibles peuvent conduire à des erreurs "index hors de la plage" en raison du traitement du rang des résultats de l'IA de recherche.
cross_encoder_at_k: cette configuration influence le processus de classement. Une valeur élevée peut entraîner l'inclusion des documents non pertinents dans les résultats finaux.
LLM_RERANK_THRESHOLD: Cette configuration détermine quels documents sont transmis au modèle de langue (LLM) pour un traitement ultérieur. La définition de cette valeur trop élevée pourrait créer un contexte trop grand pour le LLM à gérer, conduisant potentiellement à des erreurs de traitement ou à des résultats dégradés. Cela pourrait également entraîner une exception du point de terminaison Azure Openai.
Avant d'exécuter cette solution, veuillez vous assurer que vous avez correctement configuré votre nom de déploiement Azure Openai dans le fichier config.json et ajoutez des secrets pertinents aux variables d'environnement (fichier .env). Ces informations sont cruciales pour que l'application se connecte aux ressources et fonctions Azure OpenAI appropriées telles que conçues. Si vous n'êtes pas sûr des données de configuration, veuillez vous référer au fichier .env.template et config.json. La solution a été testée avec le modèle Turbo GPT 3.5 et a besoin de tests supplémentaires pour tout autre modèle.
Au cours de l'étape de génération QNA, vous pouvez parfois rencontrer des erreurs liées à la sortie JSON reçue d'Azure OpenAI. Ces erreurs peuvent empêcher la génération réussie de quelques questions et réponses. Voici ce que vous devez savoir:
Formatage incorrect: la sortie JSON d'Azure OpenAI peut ne pas adhérer au format attendu, provoquant des problèmes avec le processus de génération QNA. Filtrage de contenu: Azure OpenAI a des filtres de contenu en place. Si le texte d'entrée ou les réponses générées sont jugées inappropriées, cela pourrait entraîner des erreurs. Limitations de l'API: le service Azure OpenAI a des limitations de jetons et de taux qui affectent la sortie.
Métriques d'évaluation de bout en bout: toutes les mesures comparant les réponses générées et au sol ne peuvent pas saisir les différences de sémantique. Par exemple, des métriques telles que levenshtein ou jaro_winkler mesurent uniquement les distances de modification. La métrique cosine ne permet pas non plus la comparaison de la sémantique: elle utilise l'implémentation basée sur les jetons TextDistance basée sur des vecteurs de fréquence à terme. Pour calculer la similitude sémantique entre les réponses générées et les réponses attendues, envisagez d'utiliser des métriques basées sur l'intégration telles que les scores Bert ( bert_ ).
Métriques d'évaluation en termes de composants: les mesures d'évaluation utilisant LLM-As-Juds ne sont pas déterministes. Les métriques llm_ incluses dans l'accélérateur utilisent le modèle indiqué dans le champ de configuration azure_oai_eval_deployment_name . Les invites utilisées pour l'instruction d'évaluation peuvent être ajustées et sont incluses dans le fichier prompts.py ( llm_answer_relevance_instruction , llm_context_recall_instruction , llm_context_precision_instruction ).
Métriques basées sur la récupération: les scores MAP sont calculés en comparant chaque morceau récupéré avec la question et le morceau utilisé pour générer la paire QNA. Pour évaluer si un morceau récupéré est pertinent ou non, la similitude entre le morceau récupéré et la concaténation de la question de l'utilisateur final et le morceau utilisé dans l'étape QNA ( 02_qa_generation.py ) est calculé à l'aide du spacyevaluator. La similitude de Spacy est par défaut avec la moyenne des vecteurs de jeton, ce qui signifie que le calcul est insensible à l'ordre des mots. Par défaut, le seuil de similitude est défini sur 80% ( spacy_evaluator.py ).
Nous accueillons vos contributions et suggestions. Pour contribuer, vous devez accepter un contrat de licence de contributeur (CLA) qui confirme que vous avez le droit de faire, et en fait, accordez-nous les droits d'utilisation de votre contribution. Pour plus de détails, visitez [https://cla.opensource.microsoft.com].
Lorsque vous soumettez une demande de traction, un bot CLA vérifiera automatiquement si vous devez fournir un CLA et vous donner des instructions (par exemple, vérification d'état, commentaire). Suivez les instructions du bot. Vous n'avez besoin de le faire qu'une seule fois pour tous les dépôts qui utilisent notre CLA.
Avant de contribuer, assurez-vous de courir
pip install -e .
pre-commit install
Ce projet suit le code de conduite open source Microsoft. Pour plus d'informations, consultez le code de conduite FAQ ou contactez [email protected] avec toutes les questions ou commentaires.
bug/11-short-descriptionfeature/22-short-descriptionexample_snake_case .git config --global user.name "First Last"Ce projet peut contenir des marques ou des logos pour des projets, des produits ou des services. Vous devez suivre les directives de marque et de marque de Microsoft pour utiliser correctement les marques ou les logos de Microsoft. N'utilisez pas les marques ou les logos de Microsoft dans des versions modifiées de ce projet d'une manière qui provoque la confusion ou implique le parrainage de Microsoft. Suivez les politiques de toutes les marques ou logos tiers que contient ce projet.


