rag experiment accelerator
1.0.0
El acelerador del experimento RAG es una herramienta versátil que lo ayuda a realizar experimentos y evaluaciones utilizando la búsqueda de IA Azure y el patrón de trapo. Este documento proporciona una guía completa que cubre todo lo que necesita saber sobre esta herramienta, como su propósito, características, instalación, uso y más.
El objetivo principal del acelerador del experimento RAG es facilitar y más rápido ejecutar experimentos y evaluaciones de consultas de búsqueda y calidad de respuesta de OpenAI. Esta herramienta es útil para investigadores, científicos de datos y desarrolladores que desean:
18 de marzo de 2024: Se ha agregado muestreo de contenido. Esta funcionalidad permitirá que el conjunto de datos sea muestreado por un porcentaje especificado. Los datos se agrupan por el contenido y luego el porcentaje de muestra se toma en cada clúster para intentar una distribución uniforme de los datos muestreados.
Esto se hace para garantizar resultados representativos en la muestra que uno obtendría en todo el conjunto de datos.
Nota : Se recomienda reconstruir su entorno si ha utilizado esta herramienta antes debido a nuevas dependencias.
El acelerador del experimento RAG está impulsado por la configuración y ofrece un conjunto rico de características para respaldar su propósito:
Configuración del experimento : puede definir y configurar experimentos especificando una gama de parámetros del motor de búsqueda, tipos de búsqueda, conjuntos de consultas y métricas de evaluación.
Integración : se integra a la perfección con la búsqueda de AI Azure, Azure Machine Learning, MLFlow y Azure OpenAi.
Índice de búsqueda enriquecido : crea múltiples índices de búsqueda basados en configuraciones de hiperparameter disponibles en el archivo de configuración.
Múltiples cargadores de documentos : la herramienta admite múltiples cargadores de documentos, incluida la carga a través de la inteligencia de documentos de Azure y los cargadores básicos de Langchain. Esto le brinda la flexibilidad para experimentar con diferentes métodos de extracción y evaluar su efectividad.
Cargador de inteligencia de documentos personalizado : al seleccionar el modelo API 'PreBuilt-Layout' para la inteligencia de documentos, la herramienta utiliza un cargador de inteligencia de documentos personalizado para cargar los datos. Este cargador personalizado admite el formato de tablas con encabezados de columna en pares de valor clave (para mejorar la legibilidad para el LLM), excluye partes irrelevantes del archivo para el LLM (como los números de página y los pies de página), elimina los patrones recurrentes en el archivo usando regex y más. Dado que cada fila de tabla se transforma en una línea de texto, para evitar romper una fila en el medio, la fragmentación se realiza de manera recursiva por párrafo y línea. El cargador personalizado recurre al modelo de API de '-Layout preBuilt' más simple como un respaldo cuando falla el '-Layout preBuilt'. Cualquier otro modelo API utilizará la implementación de Langchain, que devuelve la respuesta sin procesar de la API de Document Intelligence.
Generación de consultas : la herramienta puede generar una variedad de conjuntos de consultas diversos y personalizables, que se pueden adaptar para necesidades de experimentación específicas.
Tipos de búsqueda múltiples : admite múltiples tipos de búsqueda, incluyendo texto puro, vector puro, vector cruzado, múltiple vector, híbrido y más. Esto le brinda la capacidad de realizar un análisis exhaustivo sobre las capacidades y resultados de búsqueda.
Subcreying : el patrón evalúa la consulta del usuario y, si lo encuentra lo suficientemente complejo, lo descompone en subterías más pequeñas para generar un contexto relevante.
Re-rango : las respuestas de consulta de Azure AI Search se reevalúan usando LLM y se clasifican de acuerdo con la relevancia entre la consulta y el contexto.
Métricas y evaluación : admite métricas de extremo a extremo que comparan las respuestas generadas (reales) con las respuestas de verdad en el fondo (esperado), incluidas las métricas de similitud de distancia basadas en la distancia, coseno y semántica. También incluye métricas basadas en componentes para evaluar el rendimiento de la recuperación y la generación utilizando LLM como jueces, como recuperación de contexto o relevancia de respuesta, así como métricas de recuperación para evaluar los resultados de búsqueda (por ejemplo, MAP@K).
Generación de informes : el acelerador del experimento RAG automatiza el proceso de generación de informes, completo con visualizaciones que facilitan analizar y compartir los hallazgos de los experimentos.
Mult-lingüe : la herramienta admite analizadores de idiomas para el soporte lingüístico en idiomas individuales y analizadores especializados (degnóstico) para patrones definidos por el usuario en los índices de búsqueda. Para obtener más información, consulte los tipos de analizadores.
Muestreo : si tiene un conjunto de datos grande y/o desea acelerar la experimentación, está disponible un proceso de muestreo para crear una muestra pequeña pero representativa de los datos para el porcentaje especificado. Los datos se agruparán por contenido y se seleccionará un porcentaje de cada clúster como parte de la muestra. Los resultados obtenidos deben ser aproximadamente indicativos del conjunto de datos completo dentro de un margen de ~ 10%. Una vez que se ha identificado un enfoque, se recomienda ejecutar en el conjunto de datos completo para obtener resultados precisos.
Por el momento, el acelerador del experimento RAG se puede ejecutar localmente aprovechando uno de los siguientes:
El uso de un contenedor de desarrollo significará que todo el software requerido está instalado para usted. Esto requerirá WSL. Para obtener más información sobre los contenedores de desarrollo, visite los contenedores.dev
Instale el siguiente software en la máquina host, realizará la implementación desde:
- Para Windows - Windows Store Ubuntu 22.04.3 LTS
- Escritorio de Docker
- Código de Visual Studio
- VS Extensión del código: contenedores remotos
Puede encontrar más orientación de configurar WSL aquí. Ahora tienes los requisitos previos, puedes:
git clone https://github.com/microsoft/rag-experiment-accelerator.git
code .Una vez que el proyecto abre en VScode, debe preguntarle si desea "reabrir esto en un contenedor de desarrollo". Di que sí.
Por supuesto, puede ejecutar el acelerador del experimento RAG en una máquina Windows/Mac si lo desea; Usted es responsable de instalar las herramientas correctas. Siga estos pasos de instalación:
git clone https://github.com/microsoft/rag-experiment-accelerator.gitconda create -n rag-experiment python=3.11
conda init bashCierre su terminal, abra una nueva y ejecute:
conda activate rag-experiment
pip install .az login
az account set --subscription= " <your_subscription_guid> "
az account showHay 3 opciones para instalar todos los servicios de Azure requeridos:
Este proyecto admite Azure Developer CLI.
azd provisionazd up si lo prefiere, ya que esto llama azd provision de todos modos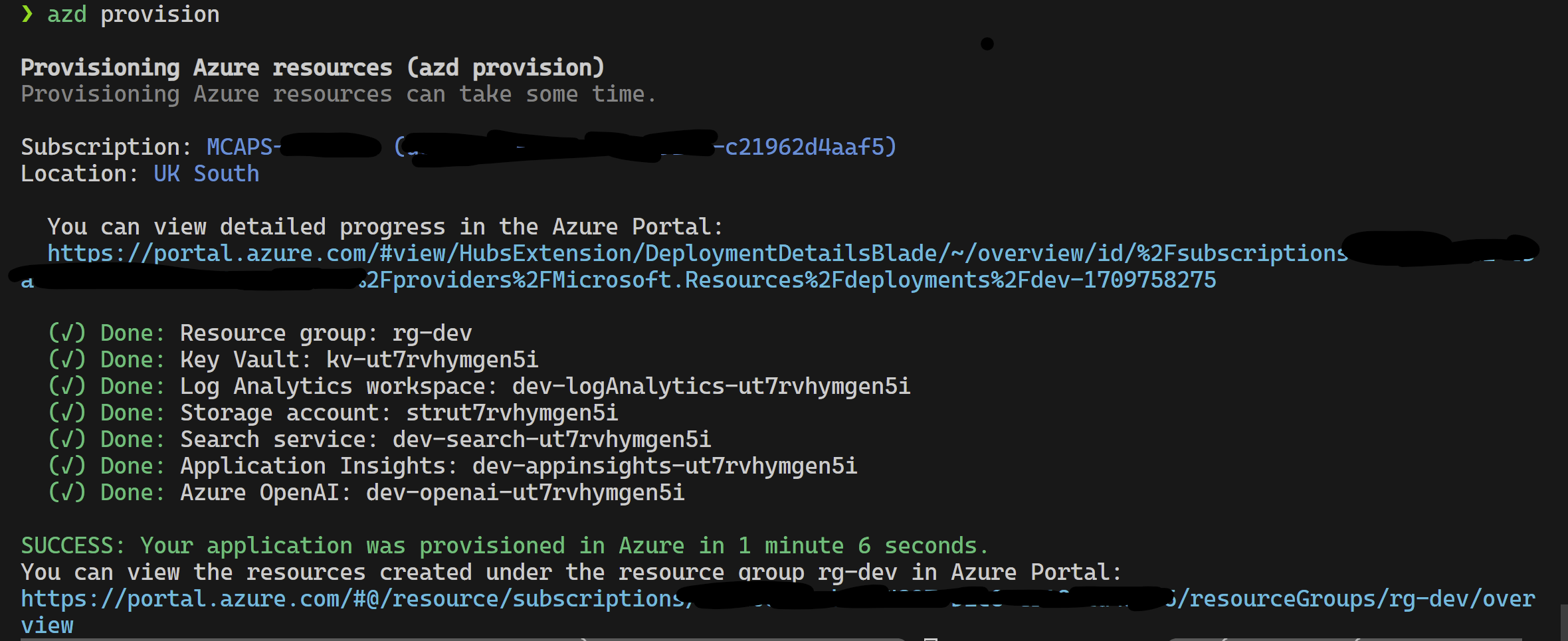
Una vez que esto se haya completado, puede usar la configuración de lanzamiento para ejecutar, o depurar los 4 pasos y el entorno actual aprovisionado por azd se cargará con los valores correctos.
Si desea implementar la infraestructura usted mismo de la plantilla, también puede hacer clic aquí:
Si no desea usar azd también puede usar la az CLI normal.
Use el siguiente comando para implementar.
az login
az deployment sub create --subscription < subscription-id > --location < location > --template-file infra/main.bicepO
Para implementar con la red aislada Use el siguiente comando. Reemplace los valores de los parámetros con los detalles de su red aislada. Debe suministrar los tres parámetros (es decir, vnetAddressSpace , proxySubnetAddressSpace y subnetAddressSpace ) si desea implementar una red aislada.
az login
az deployment sub create --location < location > --template-file infra/main.bicep
--parameters vnetAddressSpace= < vnet-address-space >
--parameters proxySubnetAddressSpace= < proxy-subnet-address-space >
--parameters subnetAddressSpace= < azure-subnet-address-space >Aquí hay un ejemplo con valores de parámetros:
az deployment sub create --location uksouth --template-file infra/main.bicep
--parameters vnetAddressSpace= ' 10.0.0.0/16 '
--parameters proxySubnetAddressSpace= ' 10.0.1.0/24 '
--parameters subnetAddressSpace= ' 10.0.2.0/24 ' Para usar el acelerador del experimento RAG localmente, siga estos pasos:
Copie el archivo .env.template proporcionado a un archivo llamado .env y actualice todos los valores requeridos. Muchos de los valores requeridos para el archivo .env vendrán de recursos que se han configurado previamente y/o pueden recopilarse a partir de los recursos aprovisionados en la sección de infraestructura de provisión. También tenga en cuenta, de forma predeterminada, LOGGING_LEVEL se establece en INFO , pero se puede cambiar a cualquiera de los siguientes niveles: NOTSET , DEBUG , INFO , WARN , ERROR , CRITICAL .
cp .env.template .env
# change parameters manually Copie el archivo config.sample.json proporcionado a un archivo llamado config.json y cambie cualquier hiperparámetro para adaptar a su experimento.
cp config.sample.json config.json
# change parameters manually Copie cualquier archivo para la ingestión (formato PDF, HTML, Markdown, Text, JSON o DOCX) en la carpeta data .
Ejecute 01_index.py (Python 01_index.py) para crear índices de búsqueda de AI Azure y cargar datos en ellos.
python 01_index.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " Ejecute 02_qa_generation.py (Python 02_qa_generation.py) para generar pares de respuesta-respuesta usando Azure OpenAI.
python 02_qa_generation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " Ejecute 03_querying.py (Python 03_querying.py) para consultar la búsqueda de ai Azure para generar contexto, volver a clasificar los elementos en contexto y obtener respuesta de Azure OpenAi usando el nuevo contexto.
python 03_querying.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " Ejecute 04_evaluation.py (Python 04_evaluation.py) para calcular las métricas utilizando varios métodos y generar gráficos e informes en Azure Machine Learning utilizando la integración de Mlflow.
python 04_evaluation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " Alternativamente, puede ejecutar los pasos anteriores (aparte de 02_qa_generation.py ) usando una tubería ML Azure. Para hacerlo, siga la guía aquí.
El muestreo se ejecutará localmente para crear una porción pequeña pero representativa de los datos. Esto ayuda con la rápida experimentación y mantiene bajos los costos. Los resultados obtenidos deben ser aproximadamente indicativos del conjunto de datos completo dentro de un margen de ~ 10%. Una vez que se ha identificado un enfoque, se recomienda ejecutar en el conjunto de datos completo para obtener resultados precisos.
Nota : El muestreo solo se puede ejecutar localmente, en esta etapa no es compatible con un clúster de cómputo AML distribuido. Entonces, el proceso sería ejecutar el muestreo localmente y luego usar el conjunto de datos de muestra generado para ejecutarse en AML.
Si tiene un conjunto de datos muy grande y desea ejecutar un enfoque similar para probar los datos, puede usar la implementación distribuida en memoria de Pyspark en el conjunto de herramientas de descubrimiento de datos para Microsoft Fabric o Azure Synapse Analytics.
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"only_run_sampling" : " If set to true, this will only run the sampling step and will not create an index or any subsequent steps, use this if you want to build a small sampled dataset to run in AML " ,
"sample_percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 " ,
},El proceso de muestreo producirá los siguientes artefactos en el directorio de muestreo:
job_name que contiene el subconjunto de archivos muestreados, se pueden especificar como --data_dir al argumento al ejecutar todo el proceso en AML.
"optimum_k": auto Config está configurado en Auto, el proceso de muestreo intentará establecer el número óptimo de clústeres automáticamente. Esto se puede anular si sabe aproximadamente cuántos cubos amplios de contenido existen en sus datos. Se generará un gráfico de codo en la carpeta de muestreo. 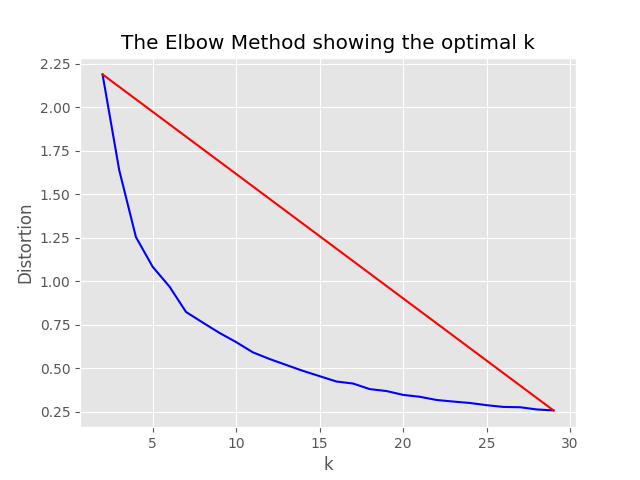
Existen dos opciones para ejecutar muestreo, a saber:
Establezca los siguientes valores para ejecutar el proceso de indexación localmente:
"sampling" : {
"sample_data" : true ,
"only_run_sampling" : false ,
"sample_percentage" : 10 ,
"optimum_k" : auto,
"min_cluster" : 2 ,
"max_cluster" : 30
}, Si only_run_sampling Config Value se establece en True, esto solo ejecutará el paso de muestreo, no se creará ningún índice y no se ejecutará ningún otro paso posterior. Establezca el argumento --data_dir en el directorio creado por el proceso de muestreo que será:
artifacts/sampling/config.[job_name] y ejecute el paso de tubería AML.
Todos los valores pueden ser listas de elementos. Incluyendo las configuraciones anidadas. Cada matriz producirá las combinaciones de configuraciones planas cuando se llama al método flatten() en un nodo particular, para seleccionar 1 combinación aleatoria: llamar al método sample() .
{
"experiment_name" : " If provided, this will be the experiment name in Azure ML and it will group all job run under the same experiment, otherwise (if left empty) index_name_prefix will be used and there may be more than one experiment " ,
"job_name" : " If provided, all jobs runs in Azure ML will be named with this property value plus timestamp, otherwise (if left empty) each job with be named only with timestamp " ,
"job_description" : " You may provide a description for the current job run which describes in words what you are about to experiment with " ,
"data_formats" : " Specifies the supported data formats for the application. You can choose from a variety of formats such as JSON, CSV, PDF, and more. [*] - means all formats included " ,
"main_instruction" : " Defines the main instruction prompt coming with queries to LLM " ,
"use_checkpoints" : " A boolean. If true, enables use of checkpoints to load data and skip processing that was already done in previous executions. " ,
"index" : {
"index_name_prefix" : " Search index name prefix " ,
"ef_construction" : " ef_construction value determines the value of Azure AI Search vector configuration. " ,
"ef_search" : " ef_search value determines the value of Azure AI Search vector configuration. " ,
"chunking" : {
"preprocess" : " A boolean. If true, preprocess documents, split into smaller chunks, embed and enrich them, and finally upload documents chunks for retrieval into Azure Search Index. " ,
"chunk_size" : " Size of each chunk e.g. [500, 1000, 2000] " ,
"overlap_size" : " Overlap Size for each chunk e.g. [100, 200, 300] " ,
"generate_title" : " A boolean. If true, a title is generated for the chunk of content and an embedding is created for it " ,
"generate_summary" : " A boolean. If true, a summary is generated for the chunk of content and an embedding is created for it " ,
"override_content_with_summary" : " A boolean. If true, The chunk content is replaced with its summary " ,
"chunking_strategy" : " determines the chunking strategy. Valid values are 'azure-document-intelligence' or 'basic' " ,
"azure_document_intelligence_model" : " represents the Azure Document Intelligence Model. Used when chunking strategy is 'azure-document-intelligence'. When set to 'prebuilt-layout', provides additional features (see above) "
},
"embedding_model" : " see 'Description of embedding models config' below " ,
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 "
}
},
"language" : {
"analyzer" : {
"analyzer_name" : " name of the analyzer to use for the field. This option can be used only with searchable fields and it can't be set together with either searchAnalyzer or indexAnalyzer. " ,
"index_analyzer_name" : " name of the analyzer used at indexing time for the field. This option can be used only with searchable fields. It must be set together with searchAnalyzer and it cannot be set together with the analyzer option. " ,
"search_analyzer_name" : " name of the analyzer used at search time for the field. This option can be used only with searchable fields. It must be set together with indexAnalyzer and it cannot be set together with the analyzer option. This property cannot be set to the name of a language analyzer; use the analyzer property instead if you need a language analyzer. " ,
"char_filters" : " The character filters for the index " ,
"tokenizers" : " The tokenizers for the index " ,
"token_filters" : " The token filters for the index "
},
"query_language" : " The language of the query. Possible values: en-us, en-gb, fr-fr etc. "
},
"rerank" : {
"enabled" : " determines if search results should be re-ranked. Value values are TRUE or FALSE " ,
"type" : " determines the type of re-ranking. Value values are llm or cross_encoder " ,
"llm_rerank_threshold" : " determines the threshold when using llm re-ranking. Chunks with rank above this number are selected in range from 1 - 10. " ,
"cross_encoder_at_k" : " determines the threshold when using cross-encoding re-ranking. Chunks with given rank value are selected. " ,
"cross_encoder_model" : " determines the model used for cross-encoding re-ranking step. Valid value is cross-encoder/stsb-roberta-base "
},
"search" : {
"retrieve_num_of_documents" : " determines the number of chunks to retrieve from the search index " ,
"search_type" : " determines the search types used for experimentation. Valid value are search_for_match_semantic, search_for_match_Hybrid_multi, search_for_match_Hybrid_cross, search_for_match_text, search_for_match_pure_vector, search_for_match_pure_vector_multi, search_for_match_pure_vector_cross, search_for_manual_hybrid. e.g. ['search_for_manual_hybrid', 'search_for_match_Hybrid_multi','search_for_match_semantic'] " ,
"search_relevancy_threshold" : " the similarity threshold to determine if a doc is relevant. Valid ranges are from 0.0 to 1.0 "
},
"query_expansion" : {
"expand_to_multiple_questions" : " whether the system should expand a single question into multiple related questions. By enabling this feature, you can generate a set of alternative related questions that may improve the retrieval process and provide more accurate results " .,
"query_expansion" : " determines if query expansion feature is on. Value values are TRUE or FALSE " ,
"hyde" : " this feature allows you to experiment with various query expansion approaches which may improve the retrieval metrics. The possible values are 'disabled' (default), 'generated_hypothetical_answer', 'generated_hypothetical_document_to_answer' reference article - Precise Zero-Shot Dense Retrieval without Relevance Labels (HyDE - Hypothetical Document Embeddings) - https://arxiv.org/abs/2212.10496 " ,
"min_query_expansion_related_question_similarity_score" : " minimum similarity score in percentage between LLM generated related queries to the original query using cosine similarly score. default 90% "
},
"openai" : {
"azure_oai_chat_deployment_name" : " determines the Azure OpenAI deployment name " ,
"azure_oai_eval_deployment_name" : " determines the Azure OpenAI deployment name used for evaluation " ,
"temperature" : " determines the OpenAI temperature. Valid value ranges from 0 to 1. "
},
"eval" : {
"metric_types" : " determines the metrics used for evaluation (end-to-end or component-wise metrics using LLMs). Valid values for end-to-end metrics are lcsstr, lcsseq, cosine, jaro_winkler, hamming, jaccard, levenshtein, fuzzy_score, cosine_ochiai, bert_all_MiniLM_L6_v2, bert_base_nli_mean_tokens, bert_large_nli_mean_tokens, bert_large_nli_stsb_mean_tokens, bert_distilbert_base_nli_stsb_mean_tokens, bert_paraphrase_multilingual_MiniLM_L12_v2. Valid values for component-wise LLM-based metrics are llm_answer_relevance, llm_context_precision and llm_context_recall. e.g ['fuzzy_score','bert_all_MiniLM_L6_v2','cosine_ochiai','bert_distilbert_base_nli_stsb_mean_tokens', 'llm_answer_relevance'] " ,
}
}Nota: Al cambiar la configuración, recuerde cambiar:
config.sample.json (la configuración de ejemplo a copiar por otros) embedding_model es una matriz que contiene la configuración para los modelos de incrustación. type de modelo de incrustación debe ser azure para los modelos Azure OpenAI y sentence-transformer para los modelos de transformadores de oraciones de Huggingface.
{
"type" : " azure " ,
"model_name" : " the name of the Azure OpenAI model " ,
"dimension" : " the dimension of the embedding model. For example, 1536 which is the dimension of text-embedding-ada-002 "
} Si está utilizando un modelo que no sea text-embedding-ada-002 , debe especificar la dimensión correspondiente para el modelo en el campo dimension ; Por ejemplo:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 3072
}Las dimensiones para los diferentes modelos de incrustaciones de Azure OpenAI se pueden encontrar en la documentación de los modelos de servicio Azure OpenAI.
Al usar los modelos de incrustaciones más nuevos (V3), también puede aprovechar su soporte para acortar los incrustaciones. En este caso, especifique el número de dimensiones que necesita y agregue el indicador shorten_dimensions para indicar que desea acortar los incrustaciones. Por ejemplo:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 256 ,
"shorten_dimensions" : true
}{
"type" : " sentence-transformer " ,
"model_name" : " the name of the sentence transformer model " ,
"dimension" : " the dimension of the model. This field is not required if model name is one of ['all-MiniLM-L6-v2', 'all-mpnet-base-v2', 'bert-large-nli-mean-tokens] "
}Dando un ejemplo de una respuesta hipotética para la pregunta en la consulta, un pasaje hipotético que contiene una respuesta a la consulta, o generar pocas preguntas relacionadas alternativas podría mejorar la recuperación y, por lo tanto, obtener trozos más precisos de los documentos para pasar al contexto de LLM. Basado en el artículo de referencia, recuperación densa precisa de disparo cero sin etiquetas de relevancia (Hyde - incrustaciones de documentos hipotéticos).
Las siguientes opciones de configuración giran esta experimentación se acerca:
{
"hyde" : " generated_hypothetical_answer "
}{
"hyde" : " generated_hypothetical_document_to_answer "
} Esta característica generará excelentes preguntas relacionadas, filtrará aquellas que son menos que min_query_expansion_related_question_similarity_score porcentaje de la consulta original (usando el puntaje de similitud coseno) y busca documentos para cada uno de ellos junto con la consulta original, los resultados de deduplicado y los devuelven a los pasos de Reranker y Top K.
El valor predeterminado para min_query_expansion_related_question_similarity_score está configurado en 90%, puede cambiar esto en config.json
{
"query_expansion" : true ,
"min_query_expansion_related_question_similarity_score" : 90
}La solución se integra con Azure Machine Learning y utiliza MLFLOW para administrar experimentos, trabajos y artefactos. Puede ver los siguientes informes como parte del proceso de evaluación:
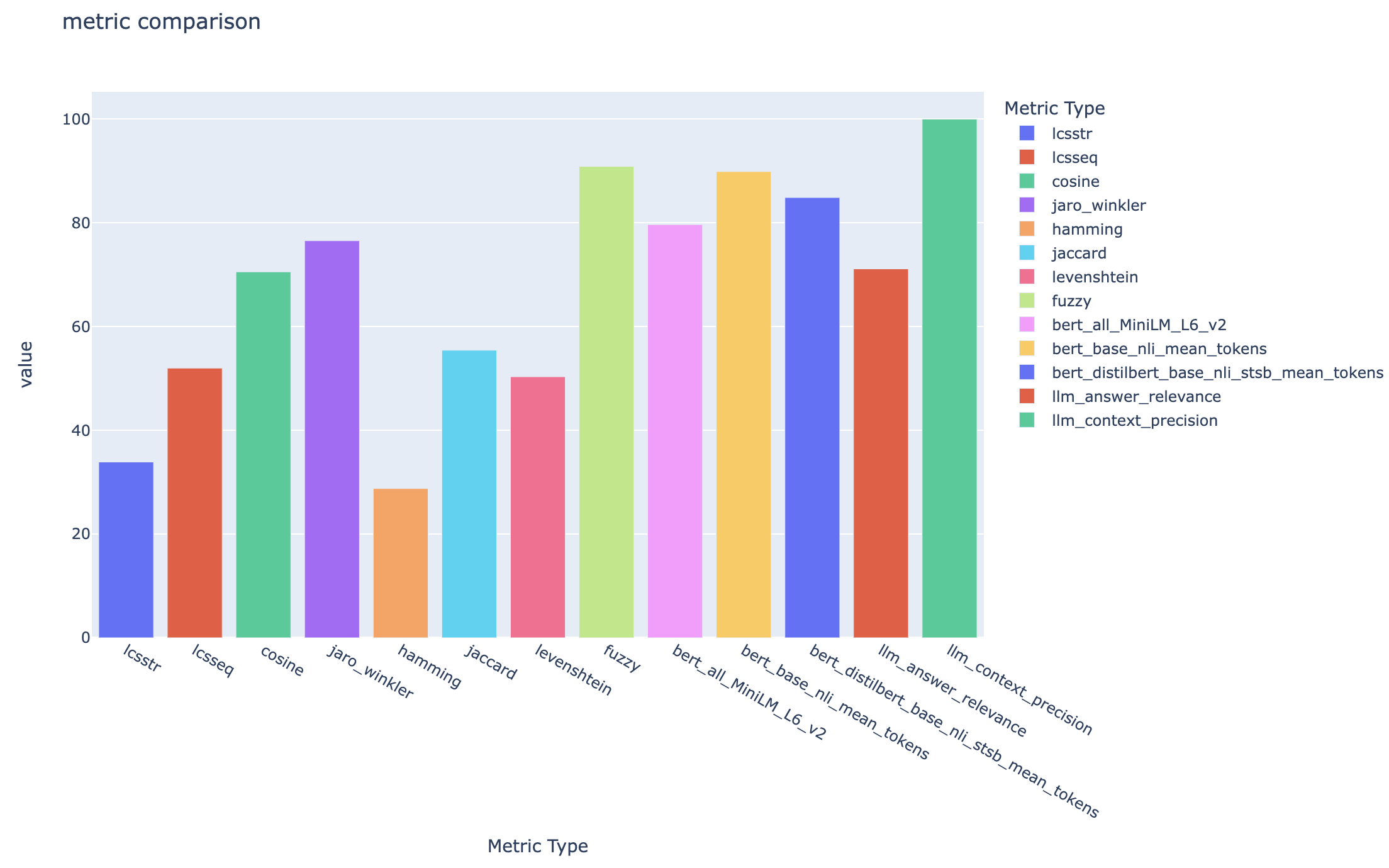
all_metrics_current_run.html muestra puntajes promedio entre preguntas y tipos de búsqueda para cada métrica seleccionada:
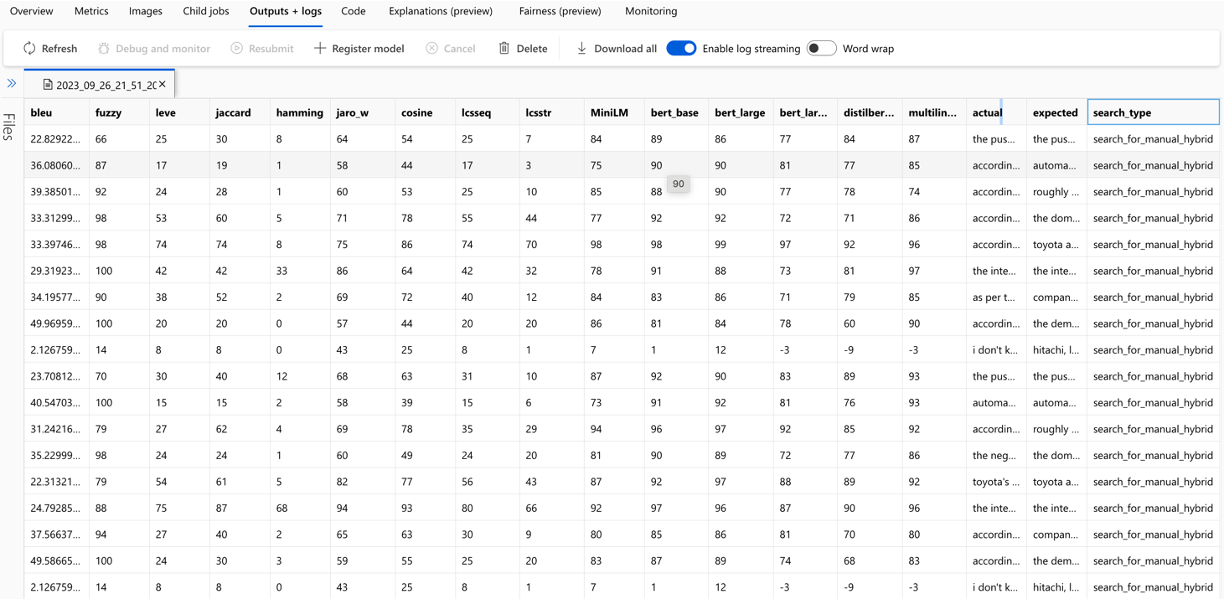
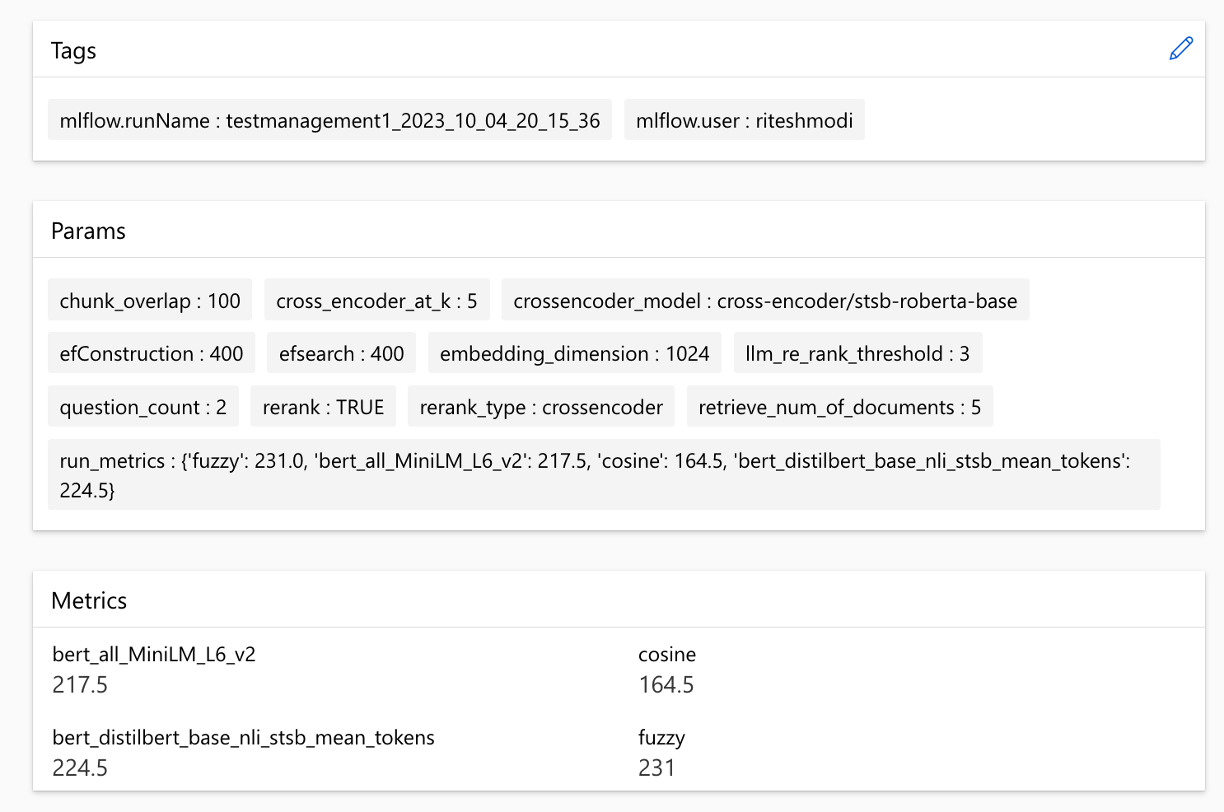
El cálculo de cada métrica y los campos utilizados para la evaluación se rastrean para cada pregunta y tipo de búsqueda en el archivo CSV de salida:
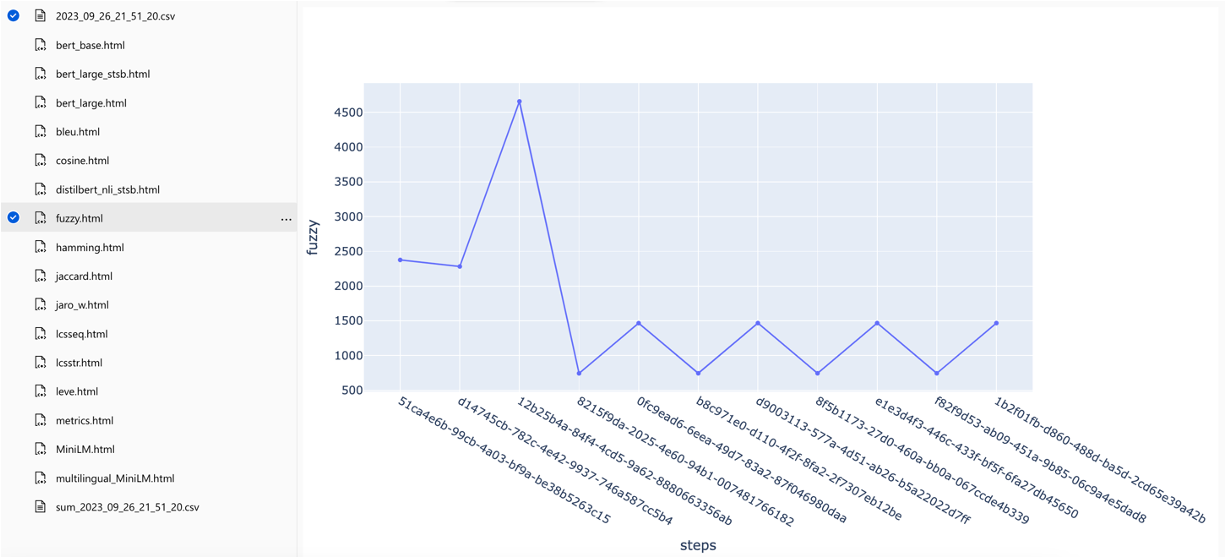
Las métricas se pueden comparar en las ejecuciones:
Las métricas se pueden comparar en diferentes estrategias de búsqueda:
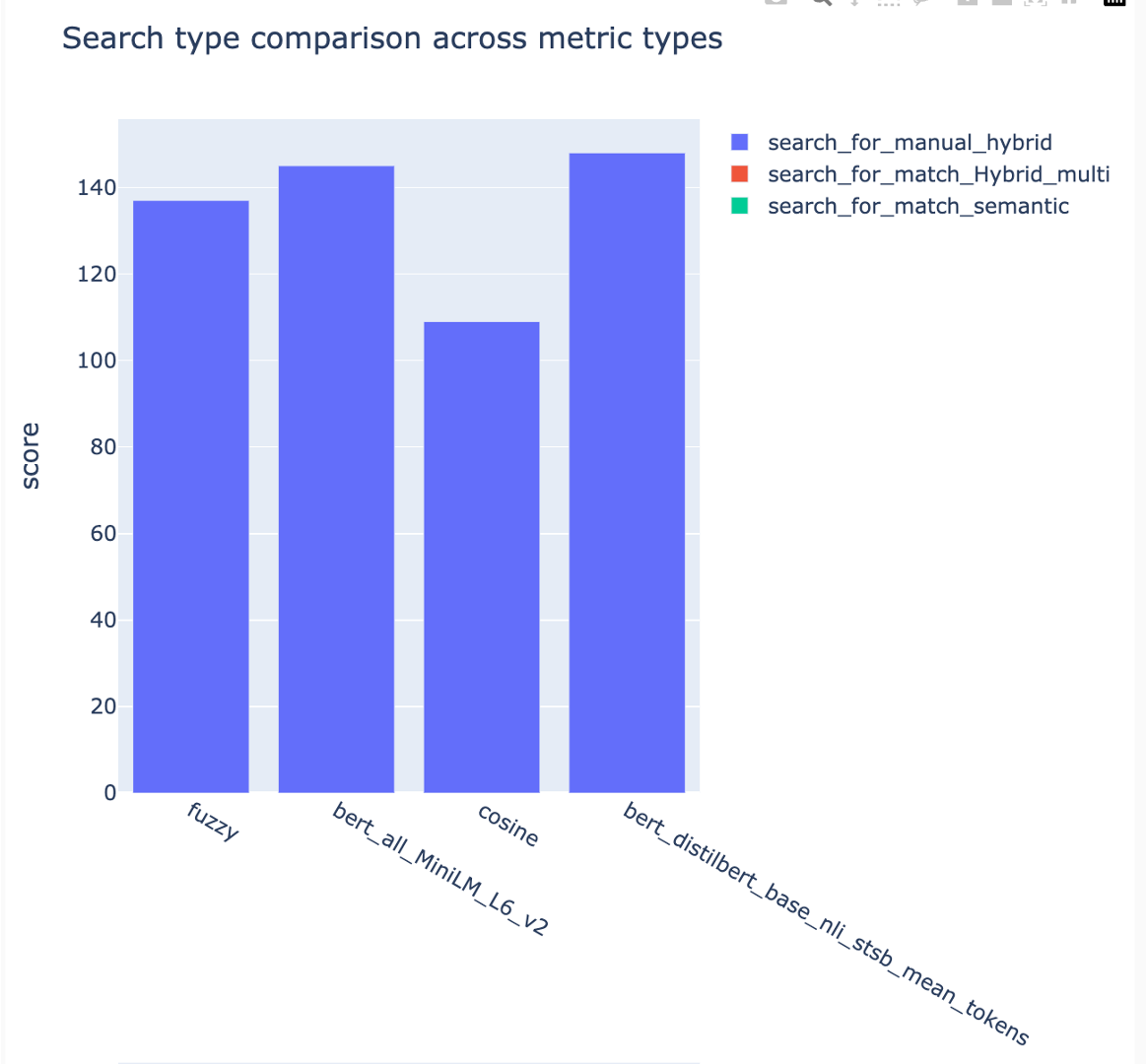
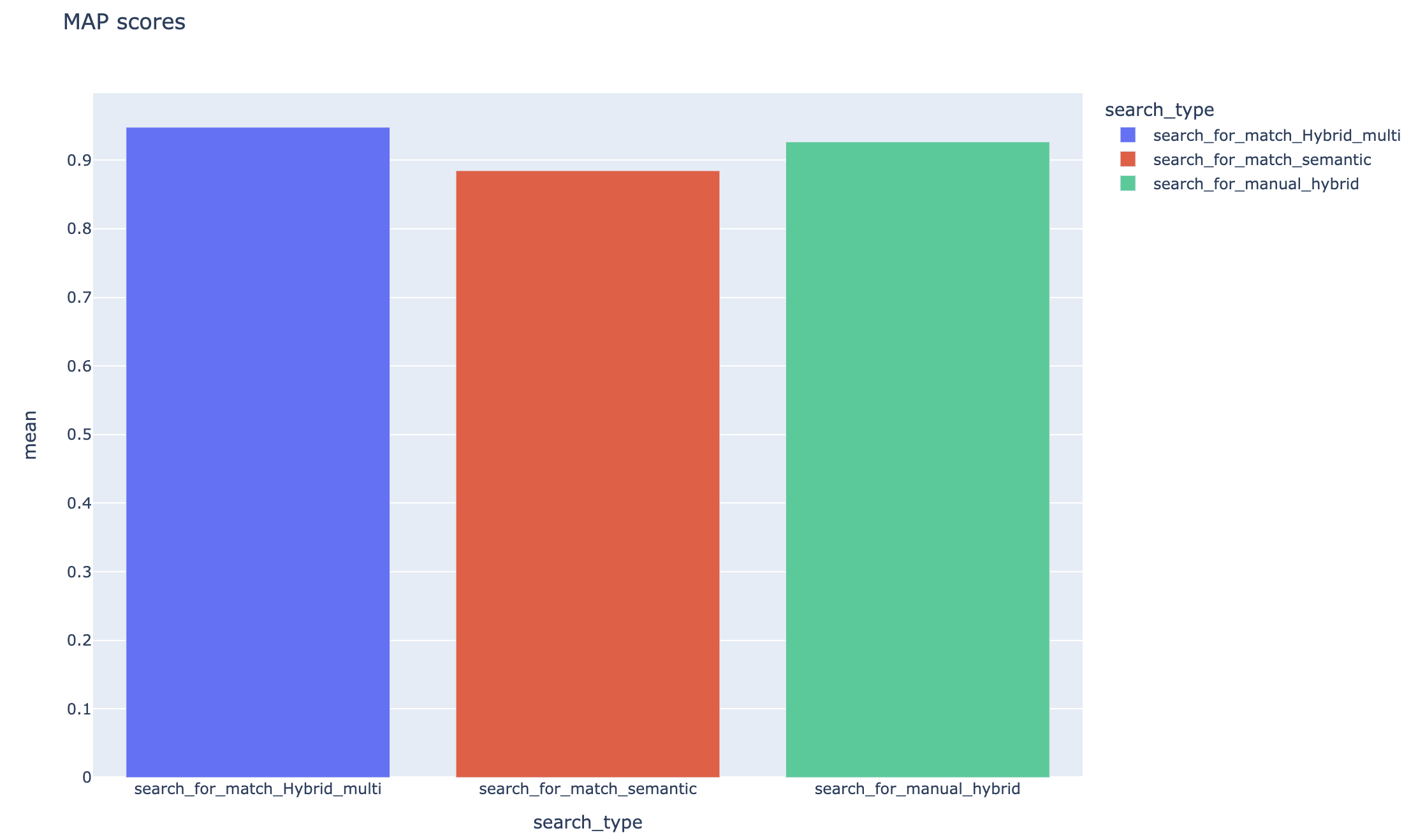
Se rastrean los puntajes promedio de precisión promedio y las puntuaciones de mapa promedio se pueden comparar en todo el tipo de búsqueda:
Esta sección describe los gotchas o trampas comunes que los ingenieros/desarrolladores/científicos de datos pueden encontrar mientras trabajan con el acelerador de experimentos RAG.
Para utilizar con éxito esta solución, primero debe autenticarse iniciando sesión en su cuenta de Azure. Este paso esencial asegura que tenga los permisos requeridos para acceder y administrar los recursos de Azure utilizados por él. Puede errores relacionados con el almacenamiento de datos de QNA en activos de datos de aprendizaje automático de Azure, ejecutando la consulta y el paso de evaluación como resultado de una autorización inapropiada y autenticación a Azure. Consulte el punto 4 en este documento para la autenticación y la autorización.
Puede haber situaciones en las que la solución aún generaría errores a pesar de la autenticación y autorización válidas. En tales casos, inicie una nueva sesión con una nueva instancia de terminal, inicie sesión en Azure utilizando los pasos mencionados en el Paso 4 y también verifique si el usuario ha contribuido con el acceso a los recursos de Azure relacionados con la solución.
Esta solución utiliza varios parámetros de configuración en config.json que afectan directamente su funcionalidad y rendimiento. Preste mucha atención a esta configuración:
Remieve_num_of_documents: esta configuración controla el número inicial de documentos recuperados para el análisis. Los valores excesivamente altos o bajos pueden conducir a errores de "índice fuera de rango" debido al procesamiento de rango de los resultados de IA de búsqueda.
Cross_encoder_at_k: esta configuración influye en el proceso de clasificación. Un valor alto podría dar lugar a que se incluyan documentos irrelevantes en los resultados finales.
LLM_RERANK_TRESHOLD: esta configuración determina qué documentos se pasan al modelo de idioma (LLM) para su posterior procesamiento. Establecer este valor demasiado alto podría crear un contexto demasiado grande para que el LLM lo maneje, lo que puede conducir a errores de procesamiento o resultados degradados. Esto también podría dar como resultado una excepción desde el punto final de Azure OpenAI.
Antes de ejecutar esta solución, asegúrese de configurar correctamente su nombre de implementación de Azure OpenAI dentro del archivo config.json y agregue secretos relevantes a las variables de entorno (archivo .env). Esta información es crucial para que la aplicación se conecte a los recursos y la función apropiados de Azure OpenAI según lo diseñado. Si no está seguro sobre los datos de configuración, consulte el archivo .env.template y config.json. La solución se ha probado con el modelo Turbo GPT 3.5 y necesita más pruebas para cualquier otro modelo.
Durante el paso de generación de QNA, ocasionalmente puede encontrar errores relacionados con la salida JSON recibida de Azure OpenAI. Estos errores pueden evitar la generación exitosa de pocas preguntas y respuestas. Esto es lo que necesitas saber:
Formato incorrecto: la salida JSON de Azure OpenAI puede no cumplir con el formato esperado, causando problemas con el proceso de generación de QNA. Filtrado de contenido: Azure OpenAI tiene filtros de contenido en su lugar. Si el texto de entrada o las respuestas generadas se consideran inapropiadas, podría conducir a errores. Limitaciones de API: el servicio Azure OpenAI tiene limitaciones de token y velocidad que afectan la salida.
Métricas de evaluación de extremo a extremo: no todas las métricas que comparan las respuestas generadas y de verdad por tierra pueden capturar diferencias en la semántica. Por ejemplo, las métricas como levenshtein o jaro_winkler solo miden las distancias de edición. La métrica cosine tampoco permite la comparación de la semántica: utiliza la implementación basada en tokens TextDistance basada en vectores de frecuencia de términos. Para calcular la similitud semántica entre las respuestas generadas y las respuestas esperadas, considere usar métricas basadas en la incrustación, como las puntuaciones Bert ( bert_ ).
Métricas de evaluación de componentes: métricas de evaluación que utilizan LLM-As-Judges no son deterministas. Las métricas llm_ incluidas en el acelerador usan el modelo indicado en el campo de configuración azure_oai_eval_deployment_name . Las indicaciones utilizadas para la instrucción de evaluación se pueden ajustar y se incluyen en el archivo prompts.py ( llm_answer_relevance_instruction , llm_context_recall_instruction , llm_context_precision_instruction ).
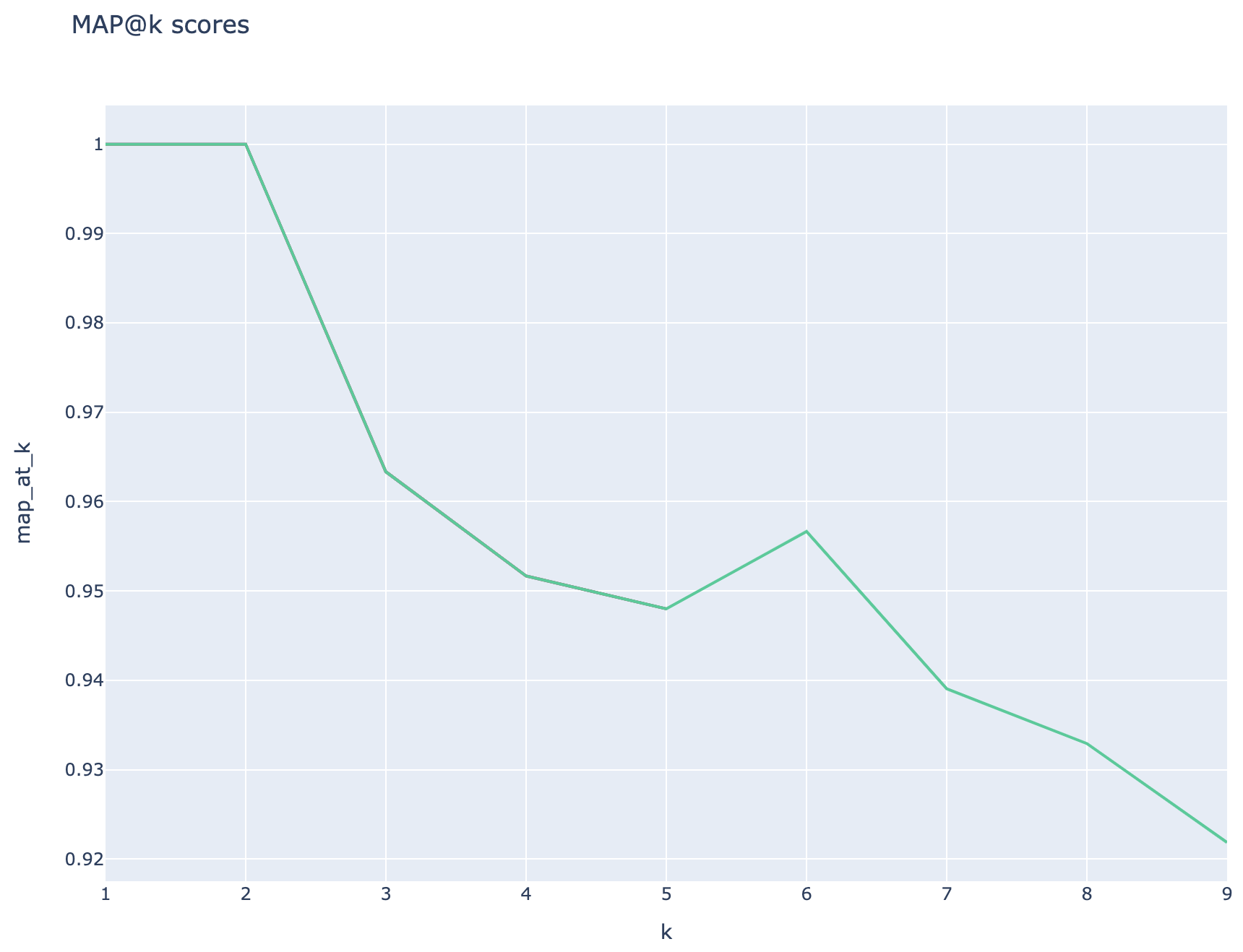
Métricas basadas en la recuperación: las puntuaciones de los mapas se calculan comparando cada fragmento recuperado con la pregunta y el fragmento utilizado para generar el par QNA. Para evaluar si un fragmento recuperado es relevante o no, la similitud entre el fragmento recuperado y la concatenación de la pregunta del usuario final y el fragmento utilizado en el paso QNA ( 02_qa_generation.py ) se calcula utilizando el SpacialEvaluator. La similitud de espacios predeterminada al promedio de los vectores de token, lo que significa que el cálculo es insensible al orden de las palabras. Por defecto, el umbral de similitud se establece en 80% ( spacy_evaluator.py ).
Agradecemos sus contribuciones y sugerencias. Para contribuir, debe aceptar un acuerdo de licencia de contribuyente (CLA) que confirme que tiene derecho y realmente hacernos los derechos para usar su contribución. Para más detalles, visite [https://cla.opensource.microsoft.com].
Cuando envía una solicitud de extracción, un BOT CLA verificará automáticamente si necesita proporcionar un CLA y darle instrucciones (por ejemplo, verificación de estado, comentario). Siga las instrucciones del bot. Solo necesita hacer esto una vez para todos los reposadores que usan nuestro CLA.
Antes de contribuir, asegúrese de ejecutar
pip install -e .
pre-commit install
Este proyecto sigue el Código de Conducta Open Open Microsoft. Para obtener más información, consulte el Código de Conducta Preguntas frecuentes o comuníquese con [email protected] con cualquier pregunta o comentario.
bug/11-short-descriptionfeature/22-short-descriptionexample_snake_case .git config --global user.name "First Last"Este proyecto puede contener marcas comerciales o logotipos para proyectos, productos o servicios. Debe seguir las pautas de marca y marca de Microsoft para usar marcas comerciales o logotipos de Microsoft correctamente. No use marcas registradas de Microsoft o logotipos en versiones modificadas de este proyecto de una manera que cause confusión o implique el patrocinio de Microsoft. Siga las políticas de cualquier marca comercial o logotipos de terceros que contenga este proyecto.


