pinferencia
v0.2.1

Simples, mas poderoso.
Doc | 中文文档 | 中文 Readme
Procura-se ajuda. Tradução, letras de rap, All Wanted. Sinta -se à vontade para criar um problema.
O Pinferencia tenta ser o servidor de inferência de aprendizado de máquina mais simples de todos os tempos!
Três linhas extras e seu modelo fica online .
Servir um modelo com API GUI e REST nunca foi tão fácil.
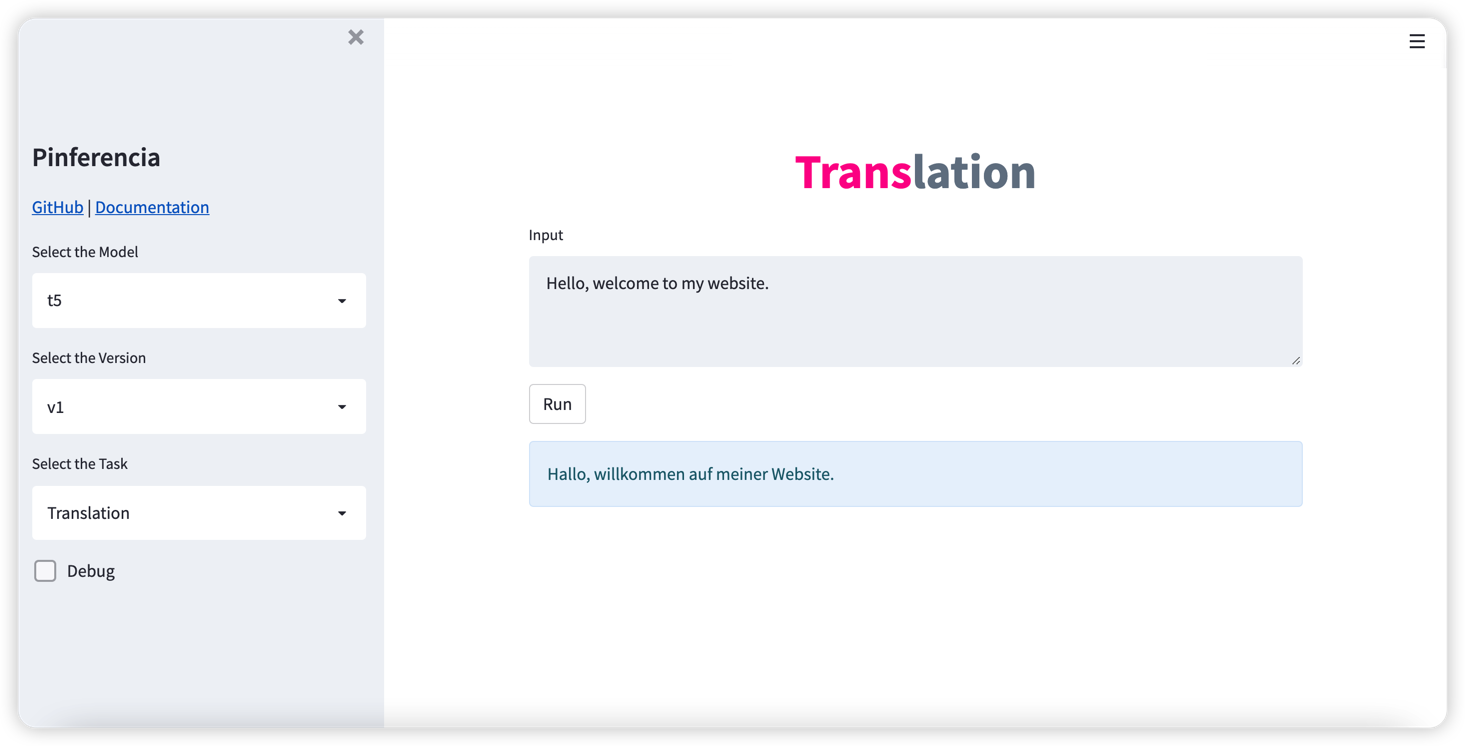
Se você quiser
Você está no lugar certo.
Os recursos da pinferencia incluem:
pip install " pinferencia[streamlit] "pip install " pinferencia " Sirva qualquer modelo
from pinferencia import Server
class MyModel :
def predict ( self , data ):
return sum ( data )
model = MyModel ()
service = Server ()
service . register ( model_name = "mymodel" , model = model , entrypoint = "predict" )Apenas corra:
pinfer app:service
Viva, seu serviço está vivo. Vá para http://127.0.0.1:8501/ e divirta -se.
Algum modelos de aprendizado profundo? Tão fácil. Trem simples ou carregue seu modelo e registre -o no serviço. Vá vivo imediatamente.
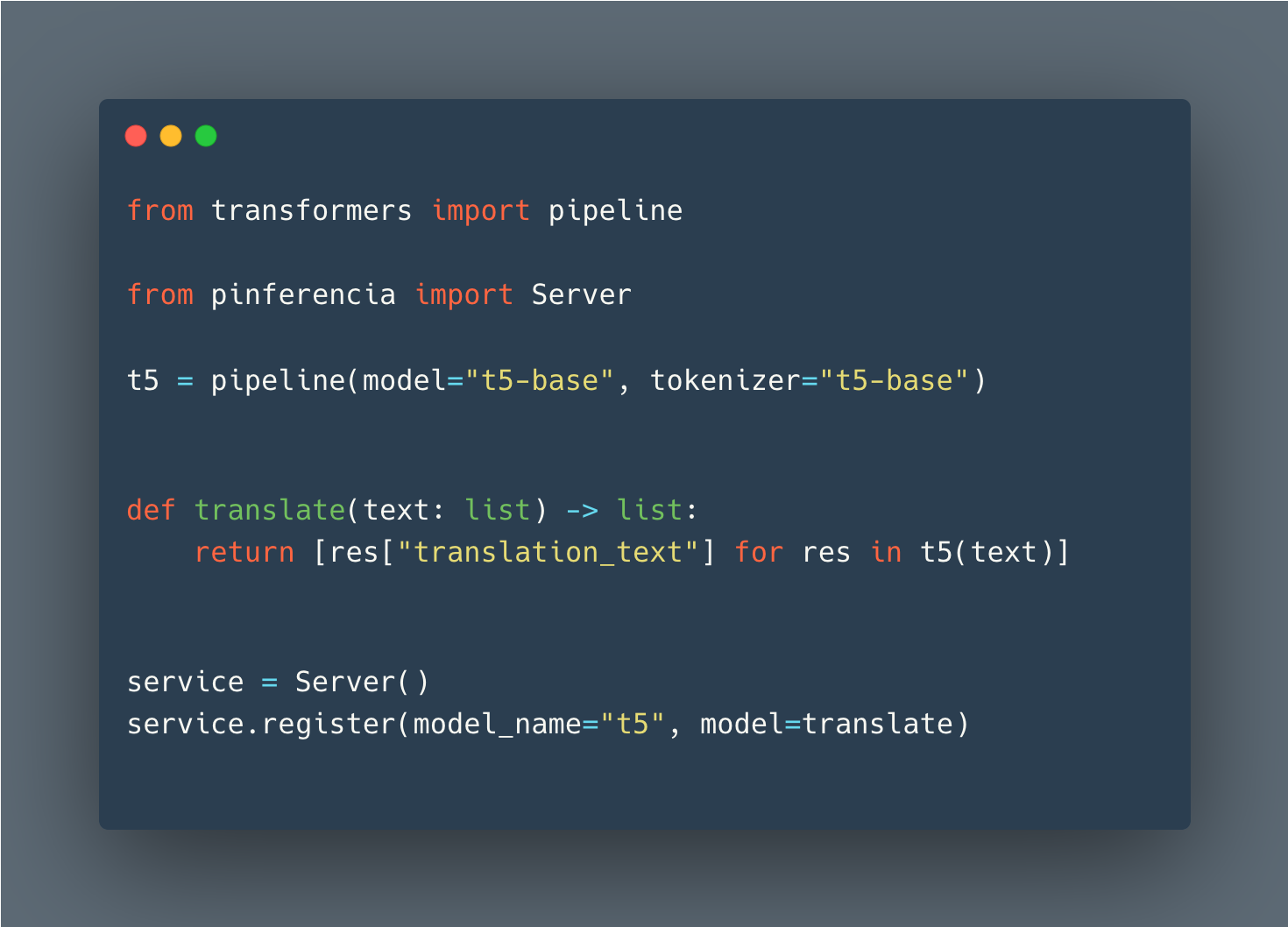
Abraçando o rosto
Detalhes: Huggingface Pipeline - Visão
from transformers import pipeline
from pinferencia import Server
vision_classifier = pipeline ( task = "image-classification" )
def predict ( data ):
return vision_classifier ( images = data )
service = Server ()
service . register ( model_name = "vision" , model = predict )Pytorch
import torch
from pinferencia import Server
# train your models
model = "..."
# or load your models (1)
# from state_dict
model = TheModelClass ( * args , ** kwargs )
model . load_state_dict ( torch . load ( PATH ))
# entire model
model = torch . load ( PATH )
# torchscript
model = torch . jit . load ( 'model_scripted.pt' )
model . eval ()
service = Server ()
service . register ( model_name = "mymodel" , model = model )Tensorflow
import tensorflow as tf
from pinferencia import Server
# train your models
model = "..."
# or load your models (1)
# saved_model
model = tf . keras . models . load_model ( 'saved_model/model' )
# HDF5
model = tf . keras . models . load_model ( 'model.h5' )
# from weights
model = create_model ()
model . load_weights ( './checkpoints/my_checkpoint' )
loss , acc = model . evaluate ( test_images , test_labels , verbose = 2 )
service = Server ()
service . register ( model_name = "mymodel" , model = model , entrypoint = "predict" ) Qualquer modelo de qualquer estrutura funcionará da mesma maneira. Agora execute uvicorn app:service --reload e aproveite!
Se você quiser contribuir, os detalhes estão aqui


