pinferencia
v0.2.1

Simple, pero poderoso.
Doc inglés | 中文文档 | 中文 Readme
Se busca ayudante. Traducción, letra de rap, todo buscado. Siéntase libre de crear un problema.
¡Pinferencia intenta ser el servidor de inferencia de aprendizaje automático más simple!
Tres líneas adicionales y su modelo se conectan en línea .
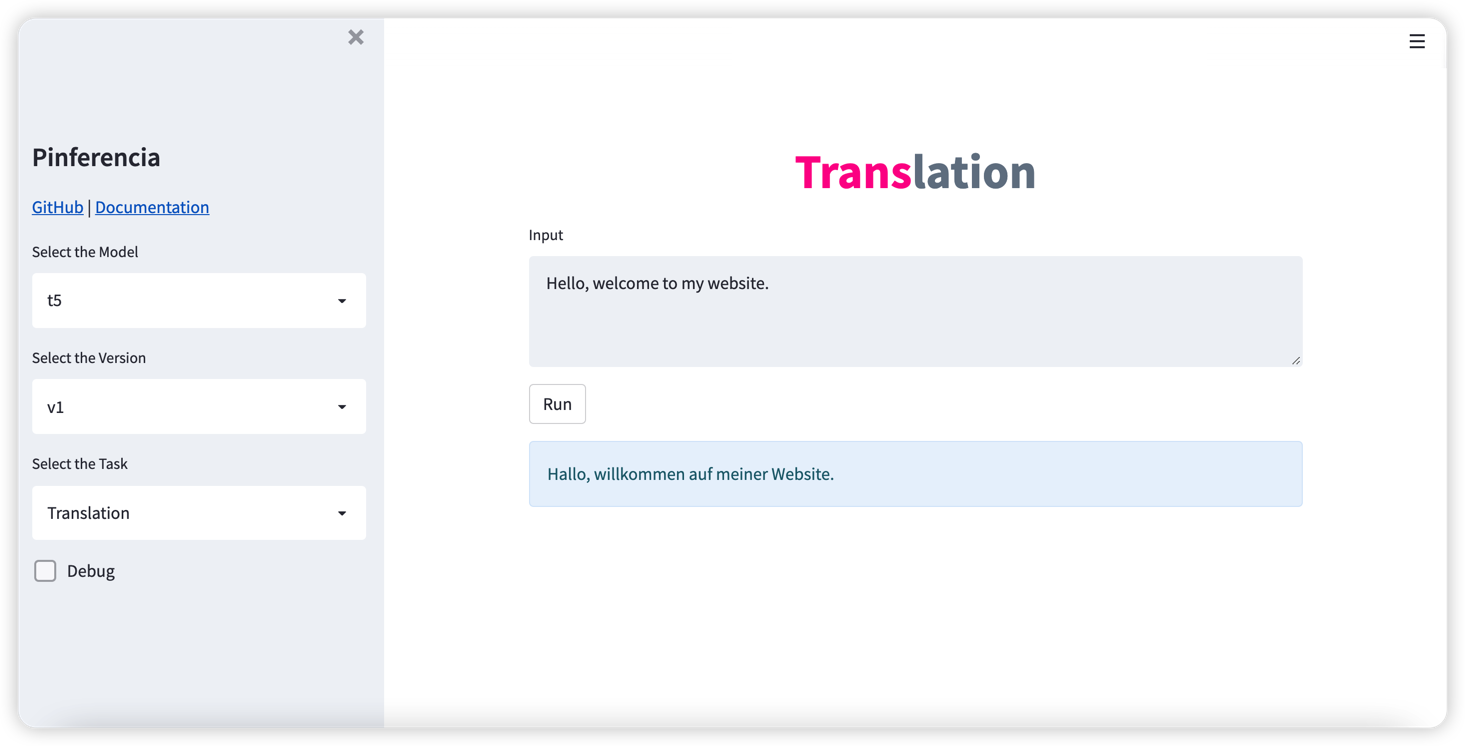
Servir un modelo con GUI y API REST nunca ha sido tan fácil.
Si quieres
Estás en el lugar correcto.
Las características de Pinferencia incluyen:
pip install " pinferencia[streamlit] "pip install " pinferencia " Servir a cualquier modelo
from pinferencia import Server
class MyModel :
def predict ( self , data ):
return sum ( data )
model = MyModel ()
service = Server ()
service . register ( model_name = "mymodel" , model = model , entrypoint = "predict" )Solo corre:
pinfer app:service
Hurra, su servicio está vivo. Vaya a http://127.0.0.1:8501/ y diviértete.
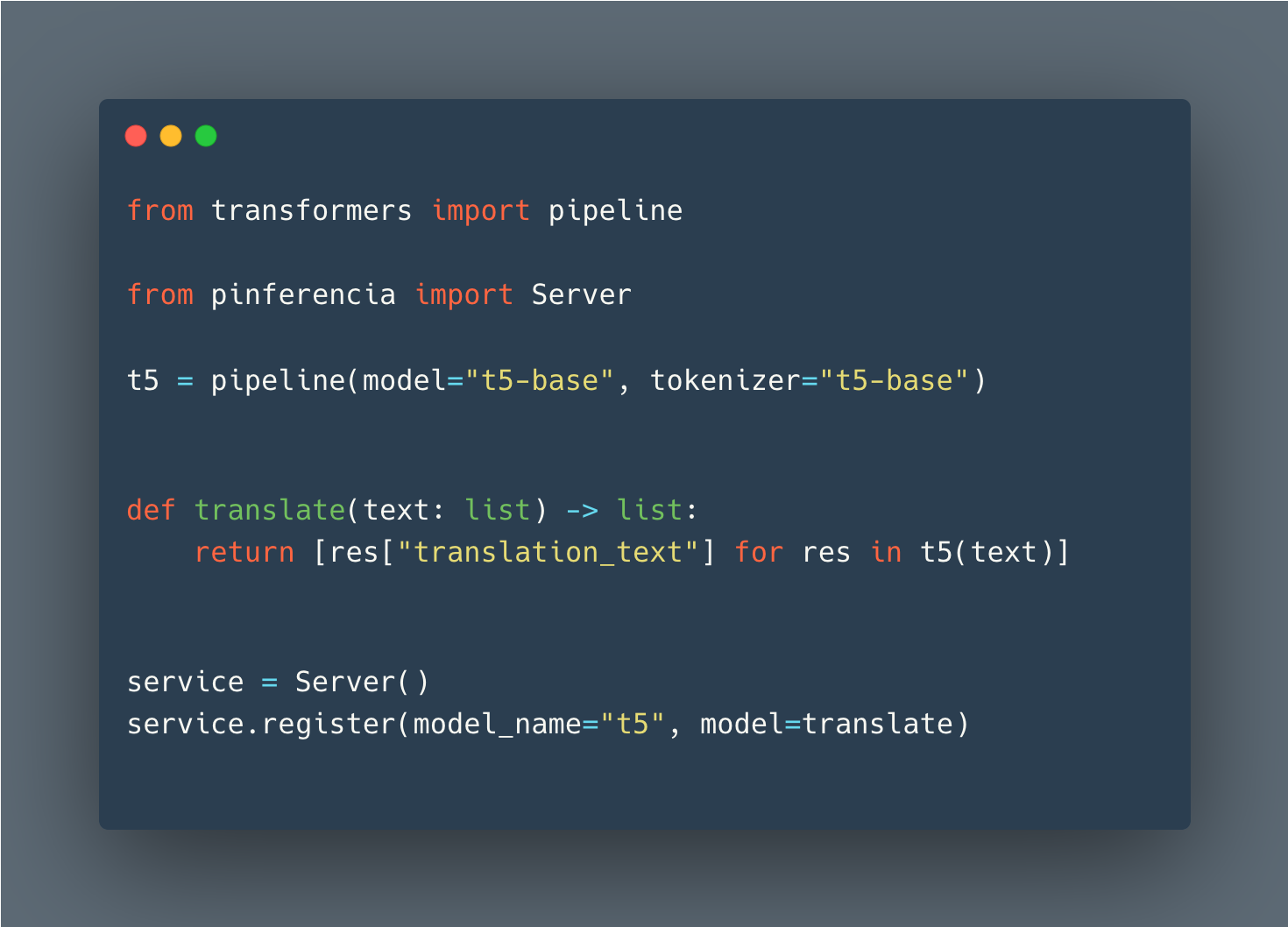
¿Algún modelo de aprendizaje profundo? Igual de fácil. Tren simple o cargue su modelo, y regístrelo con el servicio. Ve con vida inmediatamente.
Cara abrazada
Detalles: Huggingface Pipeline - Visión
from transformers import pipeline
from pinferencia import Server
vision_classifier = pipeline ( task = "image-classification" )
def predict ( data ):
return vision_classifier ( images = data )
service = Server ()
service . register ( model_name = "vision" , model = predict )Pytorch
import torch
from pinferencia import Server
# train your models
model = "..."
# or load your models (1)
# from state_dict
model = TheModelClass ( * args , ** kwargs )
model . load_state_dict ( torch . load ( PATH ))
# entire model
model = torch . load ( PATH )
# torchscript
model = torch . jit . load ( 'model_scripted.pt' )
model . eval ()
service = Server ()
service . register ( model_name = "mymodel" , model = model )Flujo tensor
import tensorflow as tf
from pinferencia import Server
# train your models
model = "..."
# or load your models (1)
# saved_model
model = tf . keras . models . load_model ( 'saved_model/model' )
# HDF5
model = tf . keras . models . load_model ( 'model.h5' )
# from weights
model = create_model ()
model . load_weights ( './checkpoints/my_checkpoint' )
loss , acc = model . evaluate ( test_images , test_labels , verbose = 2 )
service = Server ()
service . register ( model_name = "mymodel" , model = model , entrypoint = "predict" ) Cualquier modelo de cualquier marco funcionará de la misma manera. Ahora ejecute uvicorn app:service --reload y disfrute!
Si desea contribuir, los detalles están aquí


