칭화대학교 연구팀은 음성 처리 분야 모바일 음원 시나리오의 데이터 부족 문제를 해결하기 위해 SonicSim 모바일 음원 시뮬레이션 플랫폼과 SonicSet 데이터 세트를 출시했습니다. Downcodes의 편집자는 이 획기적인 연구 결과, 실제 음향 환경을 시뮬레이션하는 방법, 음성 분리 및 향상 모델 훈련을 위한 고품질 데이터 지원을 제공하는 방법을 이해하도록 안내합니다.
칭화대학교 연구팀은 최근 모바일 음원 시나리오에서 음성 처리 분야의 데이터 부족 문제를 해결하기 위해 SonicSim이라는 모바일 음원 시뮬레이션 플랫폼을 출시했습니다.
이 플랫폼은 실제 음향 환경을 높은 충실도로 시뮬레이션하고 음성 분리 및 향상 모델의 훈련 및 평가를 위한 더 나은 데이터 지원을 제공할 수 있는 Habitat-sim 시뮬레이션 플랫폼을 기반으로 구축되었습니다.
기존 음성 분리 및 향상 데이터 세트의 대부분은 정적 음원을 기반으로 하므로 움직이는 음원 시나리오의 요구 사항을 충족하기 어렵습니다.
실제 기록된 데이터 세트도 현실 세계에 존재하지만 그 규모가 제한적이고 수집 비용이 높습니다. 이와 대조적으로 합성 데이터 세트는 규모가 더 크지만 음향 시뮬레이션은 실제 환경의 음향 특성을 정확하게 반영할 만큼 현실적이지 않은 경우가 많습니다.
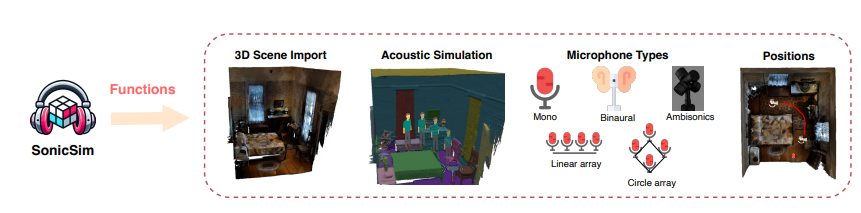
SonicSim 플랫폼의 등장은 위의 문제를 효과적으로 해결합니다. 플랫폼은 장애물, 실내 기하학적 구조, 다양한 재료의 흡음, 반사 및 산란 특성을 포함한 다양하고 복잡한 음향 환경을 시뮬레이션할 수 있으며 사용자 정의 장면 레이아웃, 음원 및 마이크 위치, 마이크 유형 등을 지원합니다. .

연구팀은 SonicSim 플랫폼을 기반으로 SonicSet이라는 대규모 다중 장면 모바일 음원 데이터 세트도 구축했습니다.
이 데이터 세트는 LibriSpeech, Freesound Dataset50k 및 Free Music Archive의 음성 및 소음 데이터뿐만 아니라 풍부한 음성, 환경 소음 및 음악 소음 데이터가 포함된 Matterport3D 데이터 세트의 90개 실제 장면을 사용합니다.
SonicSet 데이터 세트의 구성 프로세스는 고도로 자동화되어 있으며 음원과 마이크의 위치는 물론 음원의 모션 궤적을 무작위로 생성하여 데이터의 신뢰성과 다양성을 보장합니다.
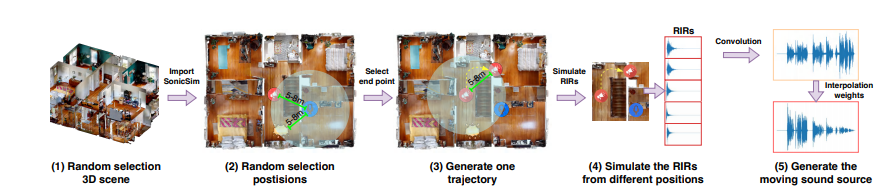
SonicSim 플랫폼과 SonicSet 데이터 세트의 효율성을 검증하기 위해 연구팀은 음성 분리 및 음성 향상 작업에 대한 많은 실험을 수행했습니다.
결과는 SonicSet 데이터 세트에서 훈련된 모델이 실제 기록된 데이터 세트에서 더 나은 성능을 달성했음을 보여주며 SonicSim 플랫폼이 실제 음향 환경을 효과적으로 시뮬레이션하고 음성 분야 연구를 위한 강력한 기반을 제공할 수 있음을 입증합니다. 처리.
SonicSim 플랫폼과 SonicSet 데이터 세트의 출시는 음성 처리 분야 연구에 새로운 혁신을 가져왔습니다. 시뮬레이션 도구의 지속적인 개선과 모델 알고리즘의 최적화를 통해 복잡한 환경에서 음성 처리 기술의 적용은 앞으로 더욱 촉진될 것입니다.
그러나 SonicSim 플랫폼의 현실감은 여전히 3D 장면 모델링의 세부 사항에 의해 제한됩니다. 가져온 3D 장면에 누락되거나 불완전한 구조가 있는 경우 플랫폼은 현재 환경에서 잔향 효과를 정확하게 시뮬레이션할 수 없습니다.
논문 주소: https://arxiv.org/pdf/2410.01481
SonicSim과 SonicSet의 등장은 음성 처리 기술 개발에 새로운 희망을 가져왔지만, 여전히 지속적인 개선이 필요합니다. 앞으로는 더욱 복잡한 음향 환경에서 이 기술을 적용할 수 있을 것으로 기대됩니다. Downcodes의 편집자는 이 분야의 연구 진행 상황에 계속해서 주의를 기울일 것입니다.