Tim peneliti Universitas Tsinghua meluncurkan platform simulasi sumber suara seluler SonicSim dan kumpulan data SonicSet, yang bertujuan untuk memecahkan masalah kekurangan data dalam skenario sumber suara seluler di bidang pemrosesan ucapan. Editor Downcodes akan membawa Anda untuk memahami hasil penelitian terobosan ini, bagaimana ia mensimulasikan lingkungan akustik nyata, dan bagaimana ia memberikan dukungan data berkualitas tinggi untuk pelatihan model pemisahan dan peningkatan ucapan.
Sebuah tim peneliti dari Universitas Tsinghua baru-baru ini merilis platform simulasi sumber suara seluler yang disebut SonicSim, yang bertujuan untuk memecahkan masalah kekurangan data saat ini di bidang pemrosesan ucapan dalam skenario sumber suara seluler.
Platform ini dibangun di atas platform simulasi Habitat-sim, yang dapat mensimulasikan lingkungan akustik dunia nyata dengan ketelitian tinggi dan memberikan dukungan data yang lebih baik untuk pelatihan dan evaluasi model pemisahan dan peningkatan ucapan.
Sebagian besar kumpulan data pemisahan dan peningkatan ucapan yang ada didasarkan pada sumber suara statis, yang sulit memenuhi kebutuhan skenario sumber suara bergerak.
Meskipun beberapa kumpulan data yang direkam secara nyata juga ada di dunia nyata, skalanya terbatas dan biaya pengumpulannya tinggi. Sebaliknya, meskipun kumpulan data sintetik berskala lebih besar, simulasi akustiknya seringkali tidak cukup realistis untuk secara akurat mencerminkan karakteristik akustik di lingkungan nyata.
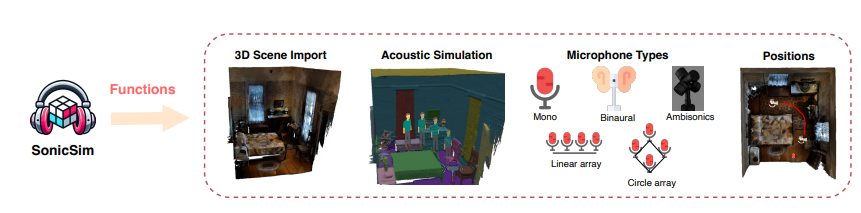
Kemunculan platform SonicSim secara efektif memecahkan permasalahan di atas. Platform ini dapat mensimulasikan berbagai lingkungan akustik yang kompleks, termasuk penghalang, geometri ruangan, dan karakteristik penyerapan suara, refleksi, dan hamburan dari berbagai bahan, dan mendukung tata letak pemandangan yang ditentukan pengguna, sumber suara dan posisi mikrofon, jenis mikrofon, dll. .

Berdasarkan platform SonicSim, tim peneliti juga membangun kumpulan data sumber suara seluler multi-adegan berskala besar yang disebut SonicSet.
Kumpulan data ini menggunakan data ucapan dan kebisingan dari LibriSpeech, Freesound Dataset50k, dan Arsip Musik Gratis, serta 90 adegan nyata dari kumpulan data Matterport3D, yang berisi data ucapan kaya, kebisingan lingkungan, dan kebisingan musik.
Proses konstruksi kumpulan data SonicSet sangat otomatis dan dapat secara acak menghasilkan posisi sumber suara dan mikrofon serta lintasan gerakan sumber suara, sehingga memastikan keaslian dan keragaman data.
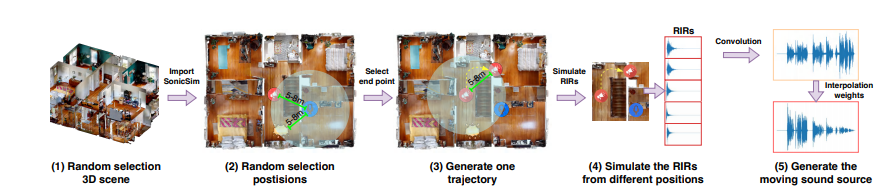
Untuk memverifikasi efektivitas platform SonicSim dan kumpulan data SonicSet, tim peneliti melakukan sejumlah besar eksperimen pada tugas pemisahan ucapan dan peningkatan ucapan.
Hasilnya menunjukkan bahwa model yang dilatih pada kumpulan data SonicSet mencapai kinerja yang lebih baik pada kumpulan data rekaman dunia nyata, membuktikan bahwa platform SonicSim dapat secara efektif mensimulasikan lingkungan akustik dunia nyata dan memberikan dasar yang kuat untuk penelitian di bidang ucapan. pemrosesan.
Peluncuran platform SonicSim dan kumpulan data SonicSet telah membawa terobosan baru dalam penelitian di bidang pemrosesan ucapan. Dengan peningkatan berkelanjutan pada alat simulasi dan optimalisasi algoritma model, penerapan teknologi pemrosesan ucapan di lingkungan yang kompleks akan semakin dipromosikan di masa depan.
Namun realisme platform SonicSim masih dibatasi oleh detail pemodelan adegan 3D. Ketika adegan 3D yang diimpor memiliki struktur yang hilang atau tidak lengkap, platform tidak dapat secara akurat mensimulasikan efek gema di lingkungan saat ini.
Alamat makalah: https://arxiv.org/pdf/2410.01481
Kemunculan SonicSim dan SonicSet membawa harapan baru bagi perkembangan teknologi pemrosesan suara, namun masih perlu terus ditingkatkan. Berharap untuk melihat penerapan teknologi ini di lingkungan akustik yang lebih kompleks di masa depan. Redaksi Downcodes akan terus memperhatikan kemajuan penelitian di bidang ini.