GPT 4 ChatGPT Project Euler
1.0.0
Project Euler에서 GPT-4 및 ChatGpt (OpenAI)의 성능 탐색, 수학적 추론 및 프로그래밍을 혼합하는 일련의 문제.
여기에서는 프로젝트 오일러 문제 1-30을 프롬프트로 표현하기 위해 텍스트 및 방정식 (GPT-4 및 ChatGpt가 구문 분석 할 수있는 라텍스 형식을 사용하는 경우 필요한 경우)을 제공했습니다. 일관성을 위해, 모든 경우에, 나는 파이썬 스크립트 형식으로 솔루션을 요청하는 문장을 추가했습니다. 알려진 지상 진실 기준선에 대해이 스크립트를 평가 한 후 GPT-4 또는 ChatGpt에게 다시 시도하거나 다음 문제로 옮겼습니다.
그런 다음 문제의 개념과 구조가 동일하게 유지되도록 문제를 수정했지만 특수성이 변경되었습니다 (예 :이 예). 이것은 좀 더 흥미로운 결과를 얻었습니다 (주석 참조).

여기에서 Green은 Chatgpt가 처음에 올바른 솔루션을 찾는 것을 나타냅니다. 두 번째 질문에서 오렌지; 빨간색은 솔루션을 찾지 못했음을 의미합니다. 그레이는 문제를 나타내는 좋은 방법을 찾을 수 없다는 것을 의미합니다. 일반적으로 이미지를 이해해야하기 때문입니다.
원래 문제로 GPT-4와 Chatgpt를 모두 제기하면 성능을 직접 비교할 수 있습니다.

GPT-4는 일치하는 문제에 대한 ChatGpt보다 성능이 우수합니다.
| 문제 # | 지상 진실 솔루션 | chatgpt 솔루션 | GPT-4 솔루션 |
|---|---|---|---|
| 문제 1 | 문제 1 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 2 | 문제 2 해결책 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 3 | 문제 3 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 4 | 문제 4 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 5 | 문제 5 솔루션 | 첫 번째 시도 - 두 번째 시도 | 첫 번째 시도 |
| 문제 6 | 문제 6 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 7 | 문제 7 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 8 | 문제 8 솔루션 | 첫 번째 시도 - 두 번째 시도 | 첫 번째 시도 |
| 문제 9 | 문제 9 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 10 | 문제 10 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 11 | 문제 11 솔루션 | 첫 번째 시도 - 두 번째 시도 | 첫 번째 시도 - 두 번째 시도 |
| 문제 12 | 문제 12 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 13 | 문제 13 솔루션 | 첫 번째 시도 - 두 번째 시도 | 첫 번째 시도 - 두 번째 시도 |
| 문제 14 | 문제 14 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 15 | 문제 15 솔루션 | N/A | N/A |
| 문제 16 | 문제 16 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 17 | 문제 17 솔루션 | 첫 번째 시도 - 두 번째 시도 | 첫 번째 시도 |
| 문제 18 | 문제 18 솔루션 | N/A | 첫 번째 시도 |
| 문제 19 | 문제 19 해결책 | 첫 번째 시도 - 두 번째 시도 | 첫 번째 시도 |
| 문제 20 | 문제 20 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 21 | 문제 21 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 22 | 문제 22 솔루션 | N/A | N/A |
| 문제 23 | 문제 23 솔루션 | 첫 번째 시도 - 두 번째 시도 | 첫 번째 시도 |
| 문제 24 | 문제 24 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 25 | 문제 25 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 26 | 문제 26 솔루션 | 첫 번째 시도 - 두 번째 시도 | 첫 번째 시도 |
| 문제 27 | 문제 27 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 28 | 문제 28 솔루션 | N/A | 첫 번째 시도 |
| 문제 29 | 문제 29 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
| 문제 30 | 문제 30 솔루션 | 첫 번째 시도 | 첫 번째 시도 |
이러한 문제에 대한 도전을 감안할 때 성능은 의심 할 여지없이 인상적이었습니다 (그리고 일치하는 PROMTPS에서 ChatGpt의 성능보다 훨씬 우수함). GPT-4가 작동 솔루션을 생성하지 못한 두 가지 문제는 둘 다 매우 긴 숫자 (각각 400 및 5000 자리)를 구문 분석하는 것과 관련이 있으며, 아마도 추론보다는 토큰 화의 실패를 시사합니다.
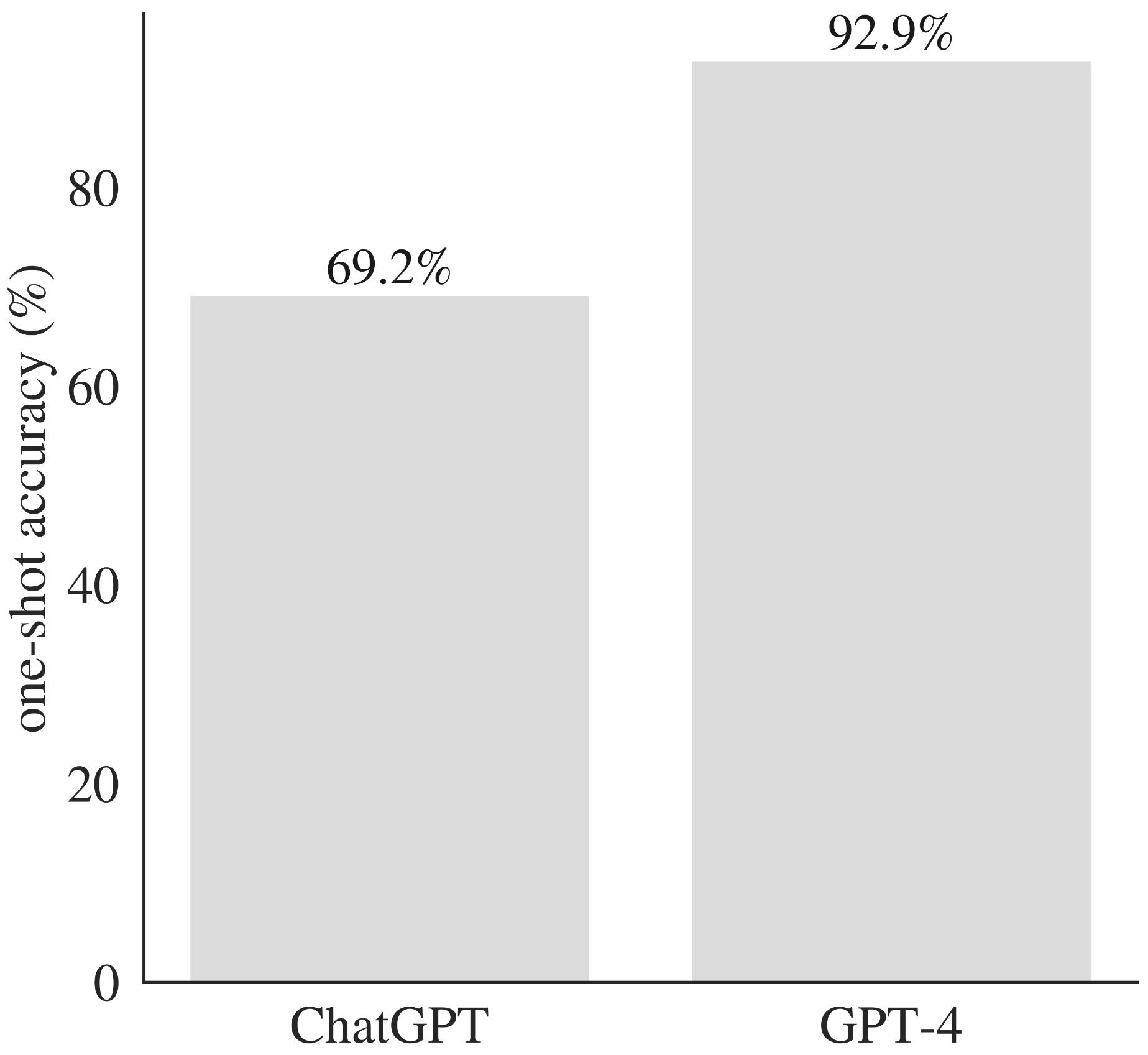
GPT-4는 다양한 수학 및 프로그래밍 문제에 대한 원샷 정확도로 ChatGpt를 능가합니다.
제 생각에는 공연은 상당히 인상적이었습니다. Chatgpt는 훈련 데이터 세트에서 코드 샘플을 역류하지 않았으며 (Github 또는 Gitlab에서 생성 된 Python 스크립트 중 어느 것도 일치하지 않았으며, 때로는 솔루션을 최적화하려고 시도했습니다 (예 : 문제 19에서 또는 문제가 사용하는 문제 6에서는 다음과 같습니다.
다른 사람들이 언급했듯이, 모델은 문제의 개념적 어려움을 눈에 띄게 증가시키지 않더라도 매우 많은 수로 어려움을 겪고 있습니다 (CF 문제 13).
마지막으로, 수정 된 문제는 몇 가지 통찰력을 얻었습니다. 여러 경우에, 모델은 정답을 생성하는 파이썬 스크립트를 생성했지만 (수정 된 문제에 대한) Chatgpt는 원래 질문에서 숫자 답변을 썼습니다. 다른 경우에는 수정 된 문구를 완전히 무시하고 문제의 원래 프레임에 대한 작업 솔루션을 제공했습니다.


