GPT 4 ChatGPT Project Euler
1.0.0
Erkundung der Leistung von GPT-4 und Chatgpt (beide OpenAI) zu Project Euler, einer Reihe von Problemen, die mathematisches Denken und Programmierung verbinden.
Hier stellte ich den Text und die Gleichungen zur Verfügung (bei Bedarf unter Verwendung der Latex-Formatierung, die GPT-4 und Chatgpt analysieren können), um Projekte-Euler-Probleme 1-30 als Aufforderung darzustellen. Für die Konsistenz habe ich in allen Fällen einen Satz hinzugefügt, in dem die Lösung in Form eines Python -Skripts angefordert wurde. Nachdem ich dieses Skript gegen Bekannte, Ground-Truth-Baselines bewertet hatte, forderte ich dann entweder GPT-4 oder Chatgpt auf, es erneut zu versuchen, oder über das nächste Problem.
Ich habe dann die Probleme so geändert, dass das Konzept und die Struktur des Problems gleich blieben, die Besonderheiten jedoch geändert wurden (z. B. dieses Beispiel); Dies führte zu einigen interessanteren Ergebnissen (siehe Kommentare).

Hier bezeichnet Green Chatgpt, die zuerst die richtige Lösung findet. Orange bei Second Ask; Rot bedeutet, dass es die Lösung nicht gefunden hat. Grau bedeutet, dass ich keinen guten Weg finden konnte, um das Problem darzustellen, normalerweise weil es ein Bild verstehen musste.
Wenn Sie sowohl GPT-4 als auch ChatGPT mit den ursprünglichen Problemen auffordern, ermöglicht es auch einen direkten Vergleich ihrer Leistung.

GPT-4 übertrifft Chatgpt über entsprechende Probleme.
| Problem # | Grundwahrheitslösung | Chatgpt -Lösungen | GPT-4-Lösungen |
|---|---|---|---|
| Problem 1 | Problem 1 Lösung | Erster Versuch | Erster Versuch |
| Problem 2 | Problem 2 Lösung | Erster Versuch | Erster Versuch |
| Problem 3 | Problem 3 Lösung | Erster Versuch | Erster Versuch |
| Problem 4 | Problem 4 Lösung | Erster Versuch | Erster Versuch |
| Problem 5 | Problem 5 Lösung | Erster Versuch - zweiter Versuch | Erster Versuch |
| Problem 6 | Problem 6 Lösung | Erster Versuch | Erster Versuch |
| Problem 7 | Problem 7 Lösung | Erster Versuch | Erster Versuch |
| Problem 8 | Problem 8 Lösung | Erster Versuch - zweiter Versuch | Erster Versuch |
| Problem 9 | Problem 9 Lösung | Erster Versuch | Erster Versuch |
| Problem 10 | Problem 10 Lösung | Erster Versuch | Erster Versuch |
| Problem 11 | Problem 11 Lösung | Erster Versuch - zweiter Versuch | Erster Versuch - zweiter Versuch |
| Problem 12 | Problem 12 Lösung | Erster Versuch | Erster Versuch |
| Problem 13 | Problem 13 Lösung | Erster Versuch - zweiter Versuch | Erster Versuch - zweiter Versuch |
| Problem 14 | Problem 14 Lösung | Erster Versuch | Erster Versuch |
| Problem 15 | Problem 15 Lösung | n / A | n / A |
| Problem 16 | Problem 16 Lösung | Erster Versuch | Erster Versuch |
| Problem 17 | Problem 17 Lösung | Erster Versuch - zweiter Versuch | Erster Versuch |
| Problem 18 | Problem 18 Lösung | n / A | Erster Versuch |
| Problem 19 | Problem 19 Lösung | Erster Versuch - zweiter Versuch | Erster Versuch |
| Problem 20 | Problem 20 Lösung | Erster Versuch | Erster Versuch |
| Problem 21 | Problem 21 Lösung | Erster Versuch | Erster Versuch |
| Problem 22 | Problem 22 Lösung | n / A | n / A |
| Problem 23 | Problem 23 Lösung | Erster Versuch - zweiter Versuch | Erster Versuch |
| Problem 24 | Problem 24 Lösung | Erster Versuch | Erster Versuch |
| Problem 25 | Problem 25 Lösung | Erster Versuch | Erster Versuch |
| Problem 26 | Problem 26 Lösung | Erster Versuch - zweiter Versuch | Erster Versuch |
| Problem 27 | Problem 27 Lösung | Erster Versuch | Erster Versuch |
| Problem 28 | Problem 28 Lösung | n / A | Erster Versuch |
| Problem 29 | Problem 29 Lösung | Erster Versuch | Erster Versuch |
| Problem 30 | Problem 30 Lösung | Erster Versuch | Erster Versuch |
Die Aufführung war angesichts der Herausforderung dieser Probleme unbestreitbar beeindruckend (und deutlich besser als die Leistung von ChatGPT auf passenden Promtps). Bei den beiden Problemen, bei denen GPT-4 keine funktionierende Lösung erzeugt, waren beide sehr lange Zahlen (400 bzw. 5000 Ziffern) analysiert, was möglicherweise auf ein Versagen der Tokenisierung als die Begründung selbst hinweist.
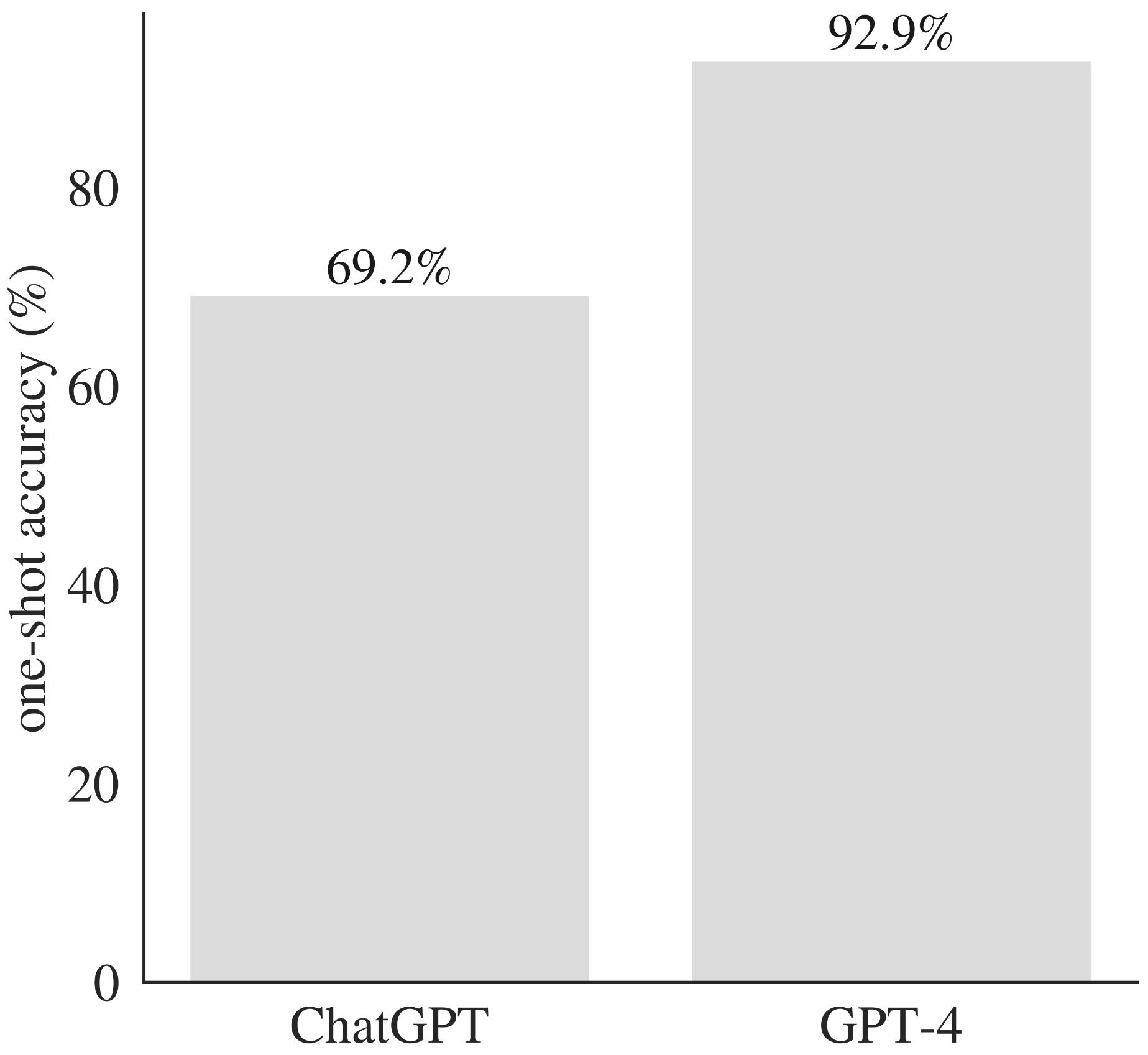
GPT-4 übertrifft ChatGPT in Bezug auf eine Ein-Schuss-Genauigkeit in einer Reihe von mathematischen und Programmierproblemen.
Die Leistung war meiner Meinung nach sehr beeindruckend. Chatgpt hat (offensichtlich) Code-Muster aus seinem Trainingsdatensatz (keiner der Python-Skripte generiert, die auf Github oder GitLab erzeugt wurden) und manchmal Versuche, die Lösung zu optimieren (z. B. mithilfe von Divide-and-Conquer-Ansätzen in Problem 19, oder in Problem 6, in dem es verwendet wird, wenn es verwendet wird: IT verwendet:
Wie von anderen erwähnt, kämpft das Modell mit sehr großen Zahlen, auch wenn sie die konzeptionelle Schwierigkeit des Problems nicht wesentlich erhöhen (vgl. Problem 13).
Schließlich ergaben die modifizierten Probleme einige Erkenntnisse. In einer Reihe von Fällen generierte das Modell ein Python -Skript, das die richtige Antwort generierte (für das geänderte Problem), aber Chatgpt schrieb die numerische Antwort aus der ursprünglichen Frage. In anderen Fällen ignorierte es den modifizierten Wortlaut vollständig und versorgte mir eine funktionierende Lösung für die ursprüngliche Rahmen des Problems.


