GPT 4 ChatGPT Project Euler
1.0.0
Project EulerでのGPT-4とCHATGPT(両方のOpenai)のパフォーマンスの調査。数学的な推論とプログラミングをブレンドする一連の問題。
ここでは、プロジェクトオイラーの問題1〜30をプロンプトとして表現するために、テキストと方程式(GPT-4とCHATGPTが解析できることを使用して必要な場合)を提供しました。一貫性のために、すべての場合において、Pythonスクリプトの形でソリューションを要求する文を追加しました。既知のグラウンドトゥルースベースラインに対してこのスクリプトを評価した後、GPT-4またはChatGPTのいずれかを再試行するか、次の問題に移行しました。
次に、問題の概念と構造が同じままになるように問題を変更しましたが、特殊性は変更されました(この例など)。これにより、より興味深い結果が得られました(コメントを参照)。

ここで、GreenはChatGptを最初に尋ねたときに正しいソリューションを見つけることを示します。 2番目の質問でオレンジ。赤は解決策を見つけられなかったことを意味します。グレーは、問題を表現する良い方法を見つけることができなかったことを意味します。これは通常、画像を理解する必要があるためです。
GPT-4とCHATGPTの両方を元の問題で促すことにより、パフォーマンスを直接比較することができます。

GPT-4は、一致した問題全体でChatGPTを上回ります。
| 問題 # | グラウンドトゥラースソリューション | ChatGptソリューション | GPT-4ソリューション |
|---|---|---|---|
| 問題1 | 問題1ソリューション | 最初の試み | 最初の試み |
| 問題2 | 問題2ソリューション | 最初の試み | 最初の試み |
| 問題3 | 問題3ソリューション | 最初の試み | 最初の試み |
| 問題4 | 問題4解決策 | 最初の試み | 最初の試み |
| 問題5 | 問題5解決策 | 最初の試行 - 2回目の試行 | 最初の試み |
| 問題6 | 問題6解決策 | 最初の試み | 最初の試み |
| 問題7 | 問題7解決策 | 最初の試み | 最初の試み |
| 問題8 | 問題8解決策 | 最初の試行 - 2回目の試行 | 最初の試み |
| 問題9 | 問題9ソリューション | 最初の試み | 最初の試み |
| 問題10 | 問題10解決策 | 最初の試み | 最初の試み |
| 問題11 | 問題11ソリューション | 最初の試行 - 2回目の試行 | 最初の試行 - 2回目の試行 |
| 問題12 | 問題12ソリューション | 最初の試み | 最初の試み |
| 問題13 | 問題13ソリューション | 最初の試行 - 2回目の試行 | 最初の試行 - 2回目の試行 |
| 問題14 | 問題14解決策 | 最初の試み | 最初の試み |
| 問題15 | 問題15解決策 | n/a | n/a |
| 問題16 | 問題16ソリューション | 最初の試み | 最初の試み |
| 問題17 | 問題17ソリューション | 最初の試行 - 2回目の試行 | 最初の試み |
| 問題18 | 問題18ソリューション | n/a | 最初の試み |
| 問題19 | 問題19ソリューション | 最初の試行 - 2回目の試行 | 最初の試み |
| 問題20 | 問題20ソリューション | 最初の試み | 最初の試み |
| 問題21 | 問題21ソリューション | 最初の試み | 最初の試み |
| 問題22 | 問題22ソリューション | n/a | n/a |
| 問題23 | 問題23ソリューション | 最初の試行 - 2回目の試行 | 最初の試み |
| 問題24 | 問題24解決策 | 最初の試み | 最初の試み |
| 問題25 | 問題25ソリューション | 最初の試み | 最初の試み |
| 問題26 | 問題26ソリューション | 最初の試行 - 2回目の試行 | 最初の試み |
| 問題27 | 問題27ソリューション | 最初の試み | 最初の試み |
| 問題28 | 問題28解決策 | n/a | 最初の試み |
| 問題29 | 問題29ソリューション | 最初の試み | 最初の試み |
| 問題30 | 問題30ソリューション | 最初の試み | 最初の試み |
これらの問題の課題を考えると、パフォーマンスは間違いなく印象的でした(そして、一致したPROMTPでのChatGPTのパフォーマンスよりも大幅に優れています)。 GPT-4が作業ソリューションを生成できなかった2つの問題は、非常に長い数値(それぞれ400桁と5000桁)の両方を解析することを伴い、おそらくそれ自体を推論するのではなく、トークン化の障害を示唆しています。
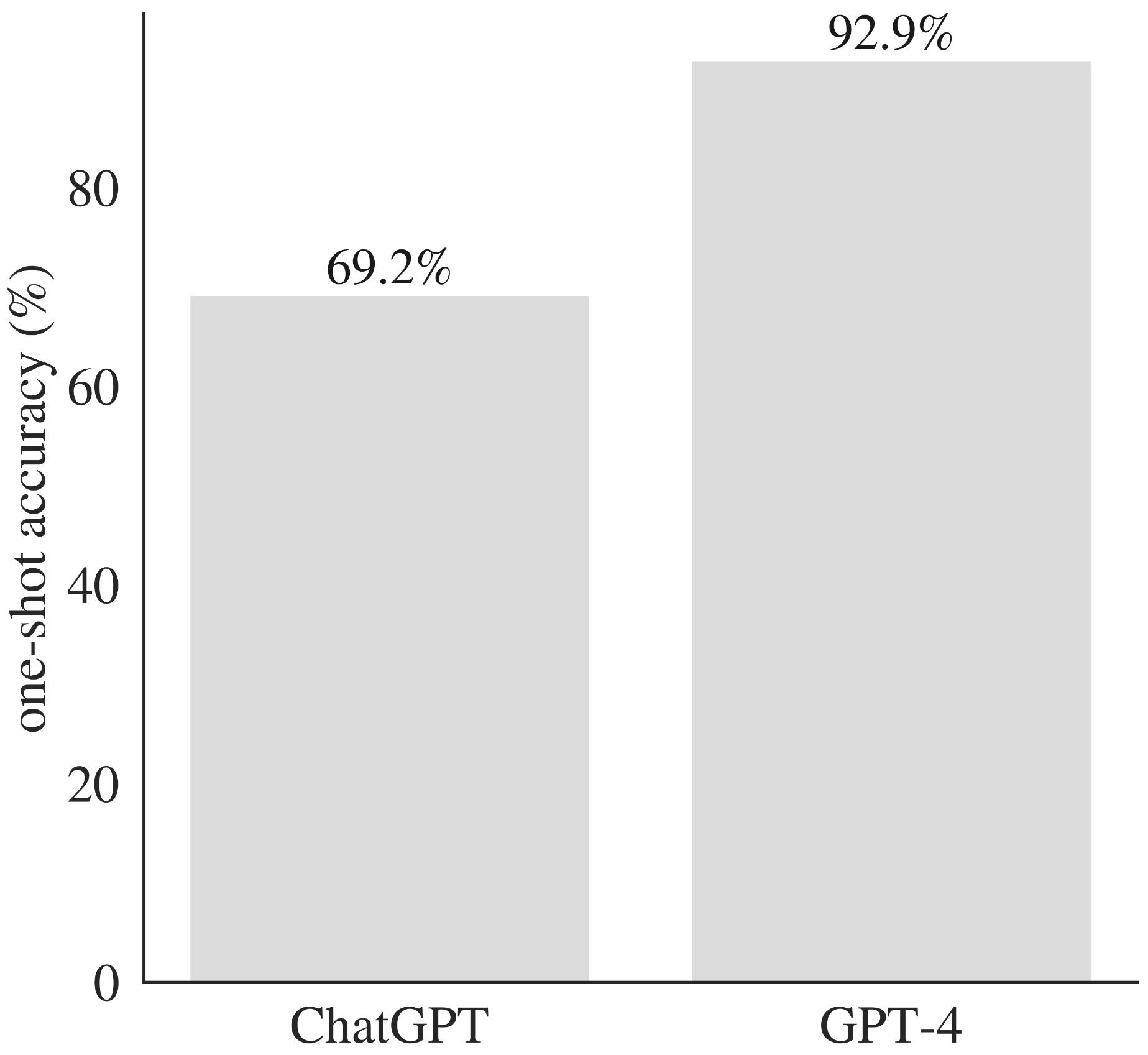
GPT-4は、さまざまな数学的およびプログラミングの問題にわたるワンショットの精度の観点からChatGPTを上回ります。
私の意見では、パフォーマンスは非常に印象的でした。 CHATGPTは、トレーニングデータセットからコードサンプルを(明らかに)逆流させませんでした(生成されたPythonスクリプトは、GithubまたはGitLabで一致していません)。
他の人が指摘したように、このモデルは、問題の概念的な難しさをそれほど増えない場合でも、非常に多くの数と格闘しています(CF問題13)。
最後に、修正された問題はいくつかの洞察をもたらしました。多くの場合、モデルは正しい答えを生成する(修正された問題のために)生成するPythonスクリプトを生成しましたが、ChatGptは元の質問から数値の答えを書きました。他の場合には、修正された文言を完全に無視し、問題の元のフレーミングに対する実用的なソリューションを提供してくれました。


