GPT 4 ChatGPT Project Euler
1.0.0
Exploration of the performance of GPT-4 and ChatGPT (both OpenAI) on Project Euler, a set of problems blending mathematical reasoning and programming.
Here, I provided the text and equations (where necessary using LaTeX formatting, which GPT-4 and ChatGPT are able to parse) to represent Project Euler problems 1-30 as a prompt. For consistency, in all instances, I added a sentence requesting the solution in the form of a Python script. After evaluating this script against known, ground-truth baselines, I then prompted either GPT-4 or ChatGPT to try again, or moved onto the next problem.
I then modified the problems such that the concept and structure of the problem remained the same, but the particularities were changed (such as this example); this yielded some more interesting results (see Comments).

Here, green denotes ChatGPT finding the correct solution at first ask; orange at second ask; red means it did not find the solution. Grey means I couldn't find a good way of representing the problem, usually because it required understanding an image.
Prompting both GPT-4 and ChatGPT with the original problems also enables a direct comparison of their performance.

GPT-4 outperforms ChatGPT across matched problems.
| Problem # | Ground-truth solution | ChatGPT solutions | GPT-4 solutions |
|---|---|---|---|
| Problem 1 | problem 1 solution | first attempt | first attempt |
| Problem 2 | problem 2 solution | first attempt | first attempt |
| Problem 3 | problem 3 solution | first attempt | first attempt |
| Problem 4 | problem 4 solution | first attempt | first attempt |
| Problem 5 | problem 5 solution | first attempt - second attempt | first attempt |
| Problem 6 | problem 6 solution | first attempt | first attempt |
| Problem 7 | problem 7 solution | first attempt | first attempt |
| Problem 8 | problem 8 solution | first attempt - second attempt | first attempt |
| Problem 9 | problem 9 solution | first attempt | first attempt |
| Problem 10 | problem 10 solution | first attempt | first attempt |
| Problem 11 | problem 11 solution | first attempt - second attempt | first attempt - second attempt |
| Problem 12 | problem 12 solution | first attempt | first attempt |
| Problem 13 | problem 13 solution | first attempt - second attempt | first attempt - second attempt |
| Problem 14 | problem 14 solution | first attempt | first attempt |
| Problem 15 | problem 15 solution | n/a | n/a |
| Problem 16 | problem 16 solution | first attempt | first attempt |
| Problem 17 | problem 17 solution | first attempt - second attempt | first attempt |
| Problem 18 | problem 18 solution | n/a | first attempt |
| Problem 19 | problem 19 solution | first attempt - second attempt | first attempt |
| Problem 20 | problem 20 solution | first attempt | first attempt |
| Problem 21 | problem 21 solution | first attempt | first attempt |
| Problem 22 | problem 22 solution | n/a | n/a |
| Problem 23 | problem 23 solution | first attempt - second attempt | first attempt |
| Problem 24 | problem 24 solution | first attempt | first attempt |
| Problem 25 | problem 25 solution | first attempt | first attempt |
| Problem 26 | problem 26 solution | first attempt - second attempt | first attempt |
| Problem 27 | problem 27 solution | first attempt | first attempt |
| Problem 28 | problem 28 solution | n/a | first attempt |
| Problem 29 | problem 29 solution | first attempt | first attempt |
| Problem 30 | problem 30 solution | first attempt | first attempt |
The performance was undeniably impressive given the challenge of these problems (and significantly better than the performance of ChatGPT on matched promtps). The two problems for which GPT-4 failed to produce a working solution both involved parsing very long numbers (400 and 5000 digits, respectively), perhaps suggesting a failure of tokenisation rather than reasoning itself.
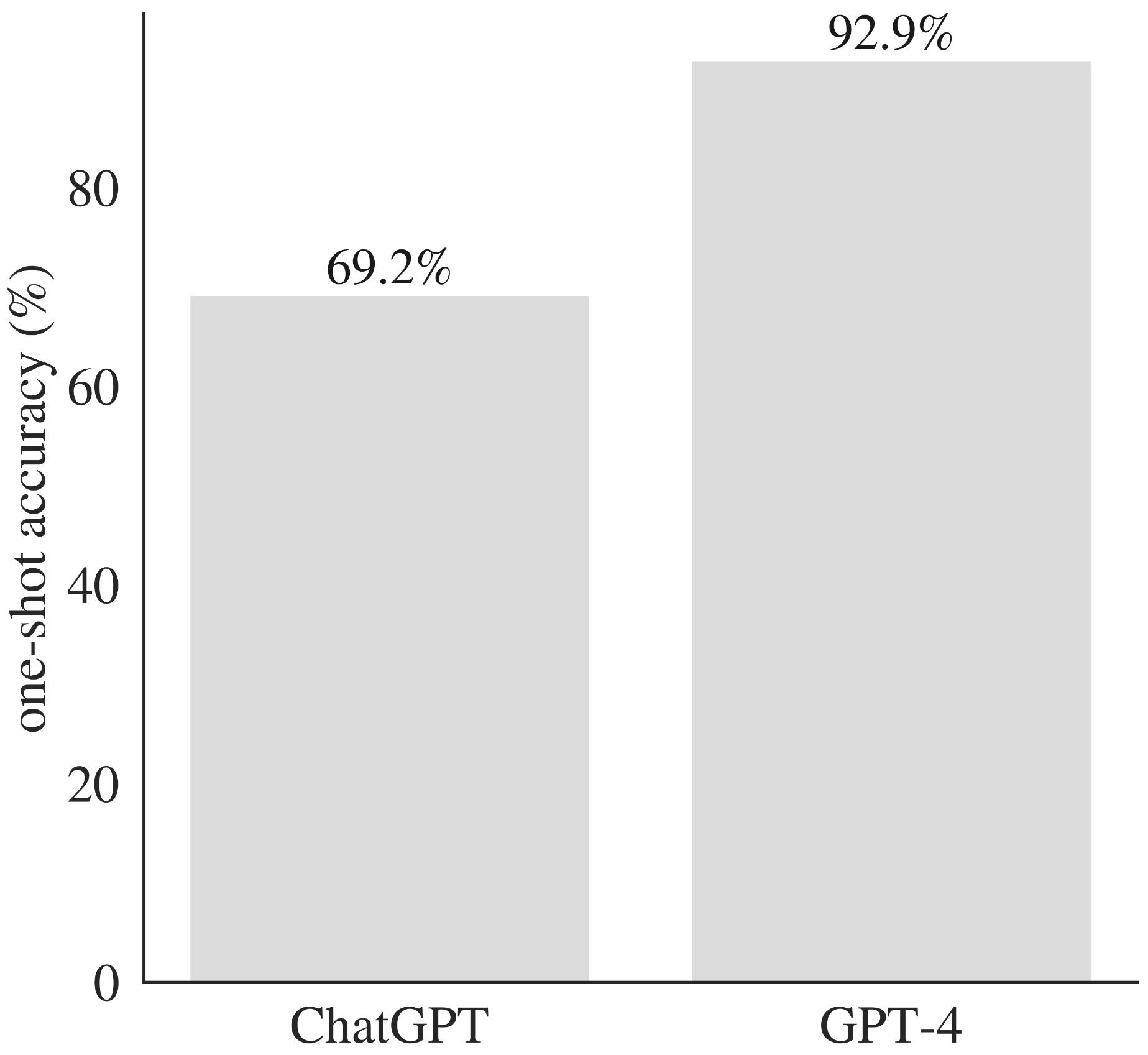
GPT-4 outperforms ChatGPT in terms of one-shot accuracy across a range of mathematical and programming problems.
Performance was, in my opinion, quite impressive. ChatGPT did not (obviously) regurgitate code samples from its training dataset (none of the Python scripts generated matched any on Github or Gitlab), and sometimes made attempts to optimise the solution (e.g. using divide-and-conquer approaches in problem 19, or in problem 6 where it uses:
As noted by others, the model struggles with very large numbers, even when they do not appreciably increase the conceptual difficulty of the problem (c.f. problem 13).
Finally, the modified problems yielded some insights. In a number of cases, the model generated a Python script that generated the correct answer (for the modified problem), but ChatGPT wrote the numerical answer from the original question. In other cases, it ignored the modified wording entirely, and provided me with a working solution to the original framing of the problem.


