AutoDL
v1.0
영어 |. 단순화

AutoDl Challenge@Neurips Challenge, 자세한 내용은 AutoDl 경쟁을 참조하십시오.
AutoDl은 자의식 방식의 다중 라벨 분류를 자동으로 수행하는 일반 알고리즘에 중점을 둡니다 (이미지, 비디오, 음성, 텍스트, 테이블 데이터). 데이터 조정, 기능, 모델, 슈퍼 파라미터와 같은 문제는 10 초 안에 탁월한 성능으로 분류기를 만들 수 있습니다. 이 프로젝트는 다른 분야에서 24 개의 오프라인 데이터 세트와 15 개의 온라인 데이터 세트에서 매우 우수한 결과를 얻었습니다 . AutoDl에는 다음과 같은 기능이 있습니다.
full -Automatic : 완전 자동 딥 러닝/머신 학습 프레임 워크, 전체 프로세스에는 수동 개입이 필요하지 않습니다. 데이터, 기능 및 모델에 대한 모든 세부 사항은 최상의 상태로 조정되었으며 리소스 제한, 데이터 스 태우, 소규모 데이터, 기능 엔지니어링, 모델 선택, 네트워크 구조 최적화 및 하이퍼 파라미터 검색의 문제는 균일하게 해결되었습니다. 데이터를 준비하고 AutoDl을 시작하고 커피 한 잔을 마시십시오 .
? 보행자 인식, 보행자 행동 인식, 얼굴 인식, 음성 인식 인식, 음악 분류, 악센트 분류, 언어 분류, 감정 분류, 이메일 분류, 뉴스 분류, 광고 최적화, 추천 시스템, 검색 시스템과 같은 다양한 분야 에서 매우 우수한 결과를 얻었습니다. 엔진, 정밀 마케팅 등
우수한 결과 : AutoDl Competition은 기존의 기계 학습 모델 및 최신 딥 러닝 모델을 포함하여 압도적 인 챔피언 프로그램을 수상했습니다. 모델 라이브러리에는 LR/SVM/LGB/CGB/XGB에서 RESNET*/MC3/DNN/THINRESNET*/TEXTCNN/RCNN/GRU/BERT 등의 선호하는 챔피언 모델이 포함됩니다.
extreme 속도/실시간 : 10 초 만에 경쟁 모델 성능을 얻습니다. 결과는 실시간 (초)으로 새로 고침되며 기다리지 않고 모델에 대한 실시간 피드백을 얻을 수 있습니다.
예비 목록 (Deepwisdom은 총 1 위, 평균 순위는 1.2, 5 개의 데이터 세트에서 4 위를 차지했습니다) 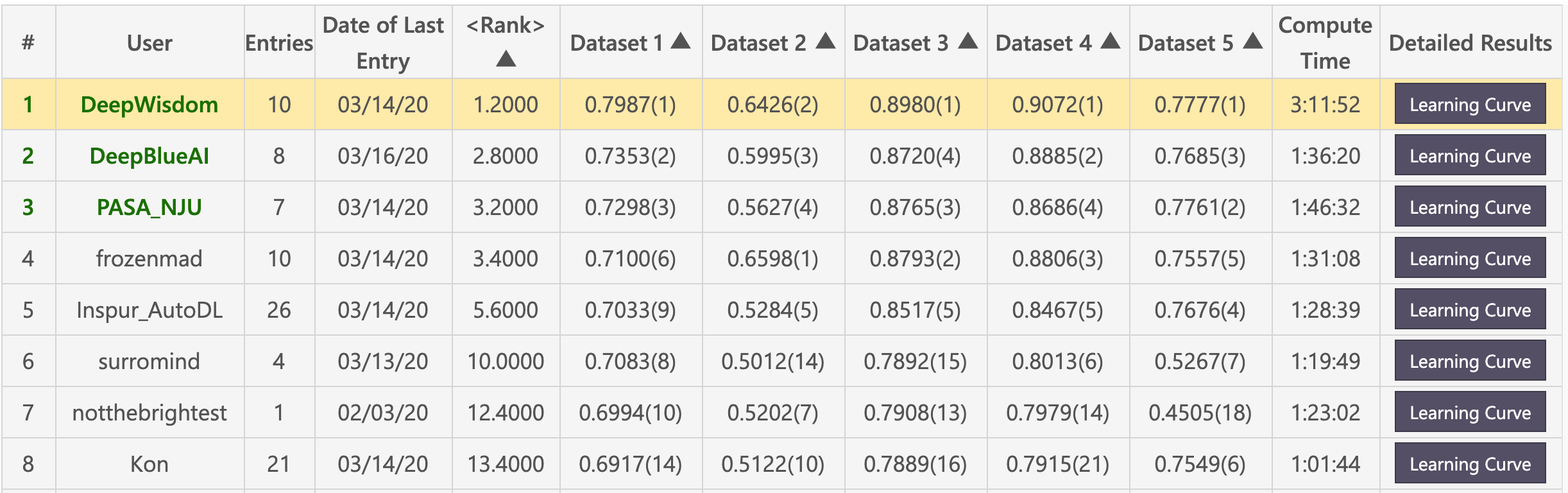
Finals List (DeepWisdom은 총 1 위, 평균 순위는 1.8, 10 개의 데이터 세트에서 7 위) 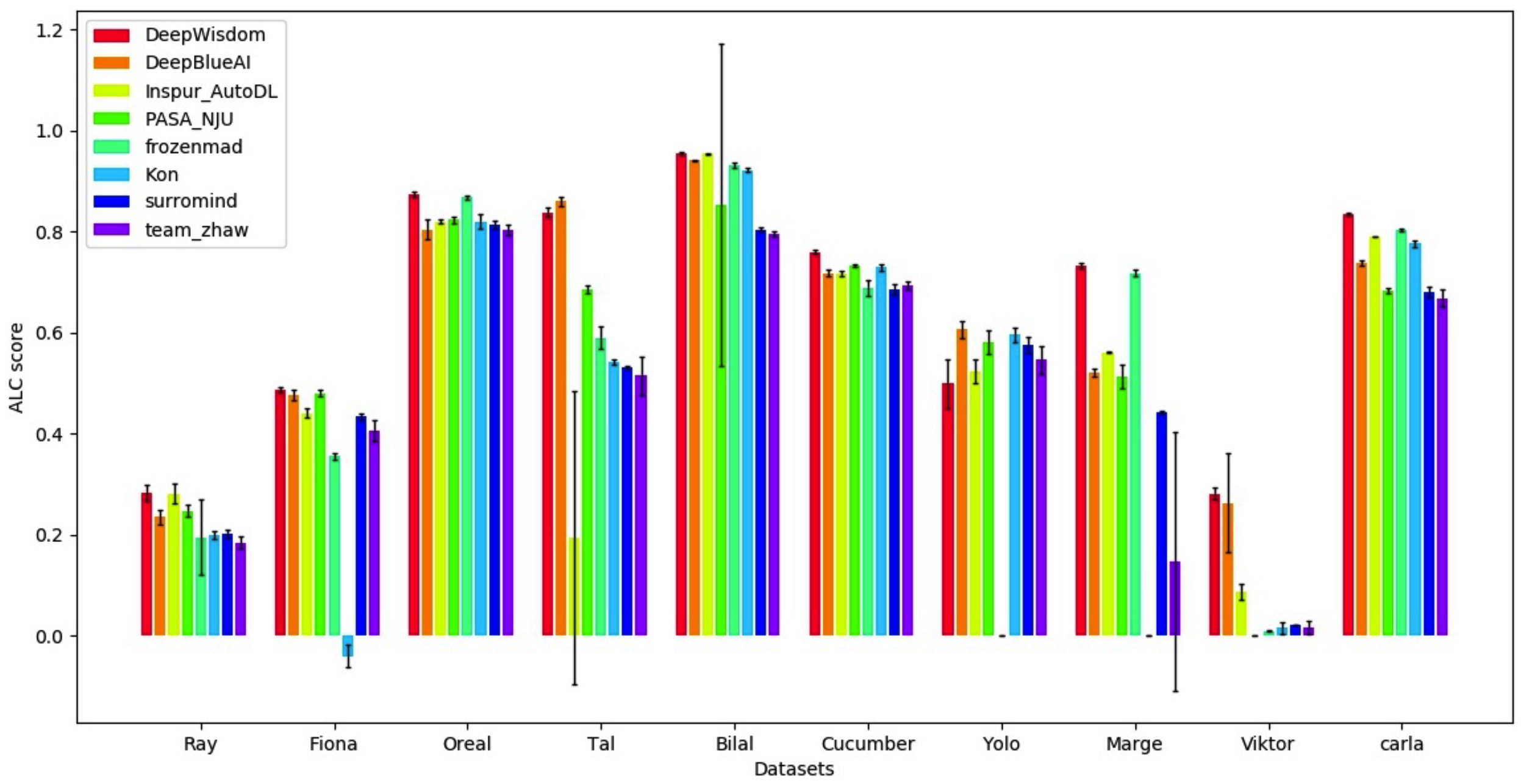
기본 환경
python > =3.5
CUDA 10
cuDNN 7.5클론 창고
cd <path_to_your_directory>
git clone https://github.com/DeepWisdom/AutoDL.git
미리 훈련 된 모델 Model Speech_Model.h5를 다운로드하여 AutoDL_sample_code_submission/at_speech/pretrained_models/ directory에 넣습니다.
선택 사항 : 경쟁과 동기화 된 도커 환경을 사용하십시오
cd path/to/autodl/
docker run -it -v "$(pwd):/app/codalab" -p 8888:8888 evariste/autodl:cpu-latest
nvidia-docker run -it -v "$(pwd):/app/codalab" -p 8888:8888 evariste/autodl:gpu-latest
데이터 세트 준비 : AutoDL_sample_data 에서 샘플 데이터 세트를 사용하거나 컨테스트 공개 데이터 세트를 다운로드하십시오.
로컬 테스트를 수행하십시오
python run_local_test.py
로컬 테스트는 전체적으로 사용됩니다. python run_local_test.py -dataset_dir='AutoDL_sample_data/miniciao' -code_dir='AutoDL_sample_code_submission' AutoDL_scoring_output/ directory에서 실시간 학습 곡선 피드백을 위해 html 페이지를 볼 수 있습니다.
자세한 내용은 AutoDl Challenge 공식 STARK_KIT를 참조하십시오.
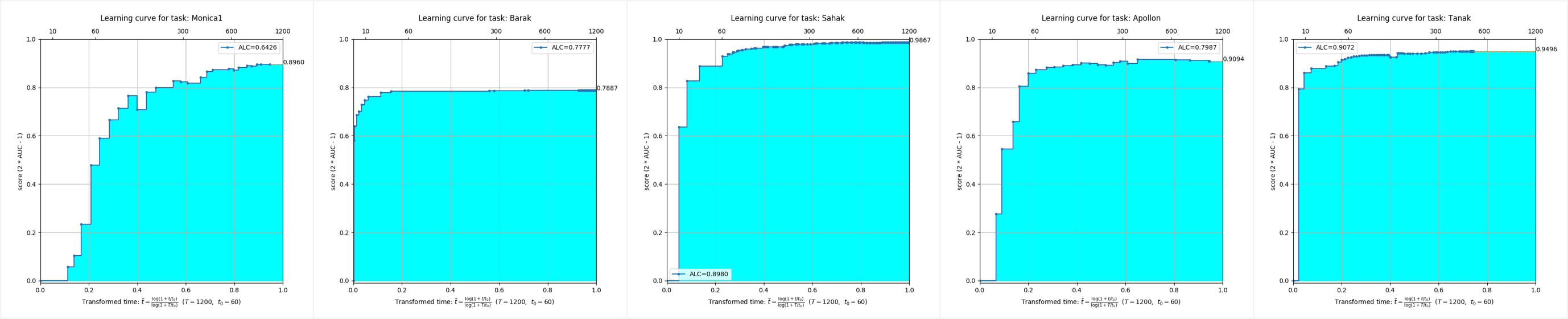
5 가지 모드의 데이터 세트에서 AutoDL 알고리즘 스트림은 매우 우수한 풀 타임 효과를 달성했으며 매우 짧은 시간에 매우 높은 정확도를 달성 할 수 있음을 알 수 있습니다.
이 저장소는 Python 3.6+, Pytorch 1.3.1 및 Tensorflow 1.15에서 테스트됩니다.
가상 환경에 AutoDL을 설치해야합니다. 가상 환경에 익숙하지 않은 경우 사용자 지침을 참조하십시오.
적절한 Python 버전으로 가상 환경을 만들고 활성화하십시오.
start_env.bat 파일을 만듭니다Miniconda3 디렉토리로 이동하십시오 cmd.exe " /K " . M iniconda3 S cripts a ctivate.bat . M iniconda3start_env.bat 두 번 클릭하여 autodl-gpu를 설치하십시오 conda install pytorch==1.3.1
conda install torchvision -c pytorch
pip install autodl-gpupip install autodl-gpu지침은 빠른 액세스를 위해 AutoDl 로컬 효과 테스트를 참조하고 예를 들어/run_local_test.py 예를 참조하십시오.
빠른 시작 이미지 분류를 참조하면 샘플 코드가 예제/run_image_classification_example.py에 표시됩니다.
지침은 Quick 시작 비디오 분류를 참조하십시오
지침은 빠른 액세스에 대해서는 오디오 분류를 참조하고 코드를 예를 들어, 예제/run_speech_classification_example.py를 참조하십시오.
지침은 빠른 텍스트의 텍스트 분류를 참조하고 예제/run_text_classification_example.py의 예제 코드를 참조하십시오.
지침은 빠른 시작 테이블 분류를 참조하고 예제/run_tabular_classification_example.py 예를 참조하십시오.
python download_public_datasets.py| 틀 | 이름 | 유형 | 도메인 | 크기 | 원천 | 데이터 (W/O 테스트 레이블) | 테스트 레이블 |
|---|---|---|---|---|---|---|---|
| 1 | 문스터 | 영상 | HWR | 18 MB | mnist | munster.data | munster.solution |
| 2 | 도시 | 영상 | 사물 | 128MB | Cifar-10 | City.data | City.solution |
| 3 | chucky | 영상 | 사물 | 128MB | CIFAR-100 | Chucky.data | Chucky.solution |
| 4 | 페드로 | 영상 | 사람들 | 377 MB | PA-100K | pedro.data | Pedro.solution |
| 5 | 데칼 | 영상 | 공중선 | 73MB | NWPU VHR-10 | DECAL.DATA | DECAL.Solution |
| 6 | 망치 | 영상 | 의료 | 111 MB | HAM10000 | 해머. 다타 | 해머 |
| 7 | Kreatur | 동영상 | 행동 | 469 MB | Kth | kreatur.data | kreatur.solution |
| 8 | Kreatur3 | 동영상 | 행동 | 588 MB | Kth | Kreatur3.Data | kreatur3.solution |
| 9 | 크라우트 | 동영상 | 행동 | 1.9 GB | Kth | kraut.data | Kraut.Solution |
| 10 | Katze | 동영상 | 행동 | 1.9 GB | Kth | katze.data | Katze.solution |
| 11 | 데이터 01 | 연설 | 스피커 | 1.8GB | - | Data01.Data | Data01.Solution |
| 12 | 데이터 02 | 연설 | 감정 | 53MB | - | data02.data | Data02.Solution |
| 13 | 데이터 03 | 연설 | 악센트 | 1.8GB | - | data03.data | Data03.Solution |
| 14 | 데이터 04 | 연설 | 장르 | 469 MB | - | data04.data | Data04.Solution |
| 15 | 데이터 05 | 연설 | 언어 | 208 MB | - | data05.data | Data05.Solution |
| 16 | O1 | 텍스트 | 의견 | 828 KB | - | o1.Data | O1.Solution |
| 17 | O2 | 텍스트 | 감정 | 25MB | - | o2.data | o2. 분리 |
| 18 | O3 | 텍스트 | 소식 | 88MB | - | o3.data | o3. 분리 |
| 19 | O4 | 텍스트 | 스팸 | 87MB | - | o4.Data | o4. 통화 |
| 20 | O5 | 텍스트 | 소식 | 14 MB | - | o5.Data | o5. 분리 |
| 스물 하나 | 성인 | 표의 | 인구 조사 | 2 MB | 성인 | 성인 .Data | 성인 |
| 스물 두 번째 | 딜버트 | 표의 | - | 162 MB | - | Dilbert.data | Dilbert.Solution |
| 스물 셋 | 숫자 | 표의 | HWR | 137 MB | mnist | Digits.data | Digits.solution |
| 24 | 매드 라인 | 표의 | - | 2.6MB | - | Madeline.data | Madeline.Solution |
❤️ 주저하지 말고 기부금에 참여하거나 PR을 제출하십시오.

아파치 라이센스 2.0


