AutoDL
v1.0
英語|

AutoDL Challenge@Neurips Challenge、詳細についてはAutoDLコンペティションを参照してください。
AutoDLは、任意のモダリティのマルチラベル分類を自動的に実行する一般的なアルゴリズムに焦点を当てています(画像、ビデオ、音声、テキスト、表データ)。データ調整、機能、モデル、スーパーパラメータなどのトラブルのために、わずか10秒で優れたパフォーマンスを備えた分類器を作成できます。このプロジェクトは、異なる分野での24のオフラインデータセットと15のオンラインデータセットで非常に優れた結果を達成しました。 AutoDLには次の機能があります。
full -automatic :完全に自動的な深い学習/機械学習フレームワーク、プロセス全体に手動介入は必要ありません。データ、機能、モデルのすべての詳細は、リソース制限、データスキュー、小さなデータ、機能エンジニアリング、モデル選択、ネットワーク構造の最適化、ハイパーパラメーター検索の問題が一様に解決されました。データを準備し、AutoDLを起動し、コーヒーを飲んでください。
?大学:画像、ビデオ、オーディオ、テキスト、構造化された表形式データなど、任意のモダリティをサポートし、バイナリ分類、マルチ分類、マルチラベル分類などのマルチラベル分類問題をサポートします。歩行者認識、歩行者アクション認識、顔認識、ボイスプリント認識、音楽分類、アクセント分類、言語分類、感情分類、電子メール分類、ニュース分類、広告最適化、推奨システム、検索など、さまざまな分野で非常に優れた結果を達成しました。エンジン、精密マーケティングなど
優れた結果:AutoDL競争は、従来の機械学習モデルや最新のディープラーニングモデルのサポートを含む、圧倒的なチャンピオンプログラムを獲得しました。モデルライブラリには、LR/SVM/LGB/CGB/XGBからResNet*/MC3/DNN/ThinResnet*/TextCnn/RCNN/Gru/Bertなどへの優先チャンピオンモデルが含まれています。
Extreme Speed/Real-Time :10秒で競争力のあるモデルパフォーマンスを取得します。結果はリアルタイム(秒)で更新され、待つことなくモデルに関するリアルタイムのフィードバックを得ることができます。
予備リスト(Deepwisdomは合計で1.2ランキングで1.2でランク付けされ、5つのデータセットで4つの最初のランキング)を獲得) 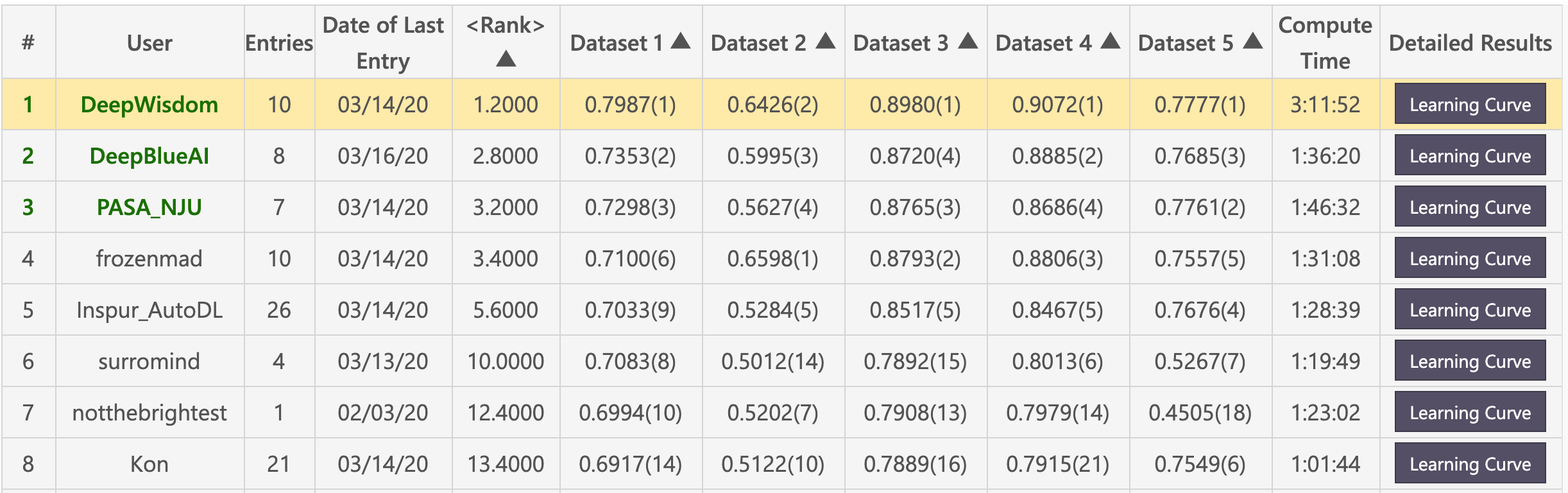
ファイナルリスト(Deepwisdomは合計で1.8のランキングで1.8で、10のデータセットで7つの最初のランクがあります) 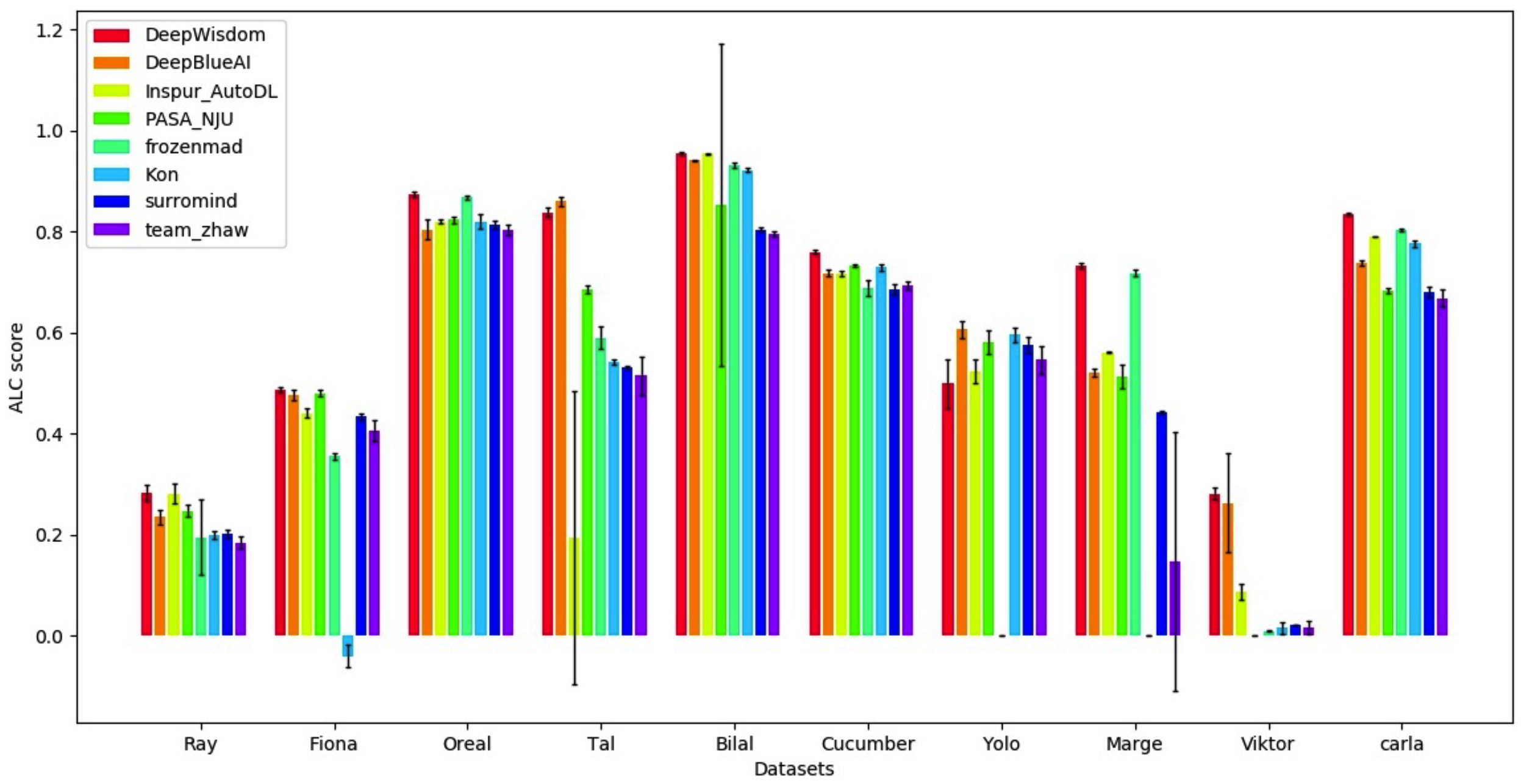
基本環境
python > =3.5
CUDA 10
cuDNN 7.5クローンウェアハウス
cd <path_to_your_directory>
git clone https://github.com/DeepWisdom/AutoDL.git
モデルSpeech_model.h5をダウンロードし、 AutoDL_sample_code_submission/at_speech/pretrained_models/ directoryに入れて、事前に訓練されたモデル。
オプション:競争と同期したDocker環境を使用します
cd path/to/autodl/
docker run -it -v "$(pwd):/app/codalab" -p 8888:8888 evariste/autodl:cpu-latest
nvidia-docker run -it -v "$(pwd):/app/codalab" -p 8888:8888 evariste/autodl:gpu-latest
データセットの準備: AutoDL_sample_dataでサンプルデータセットを使用するか、バッチコンテストパブリックデータセットをダウンロードします。
ローカルテストを実行します
python run_local_test.py
ローカルテストは完全に使用されます。 python run_local_test.py -dataset_dir='AutoDL_sample_data/miniciao' -code_dir='AutoDL_sample_code_submission' AutoDL_scoring_output/ directiryでリアルタイム学習曲線フィードバックのHTMLページを表示できます。
詳細については、AutoDL Challengeの公式starting_kitを参照してください。
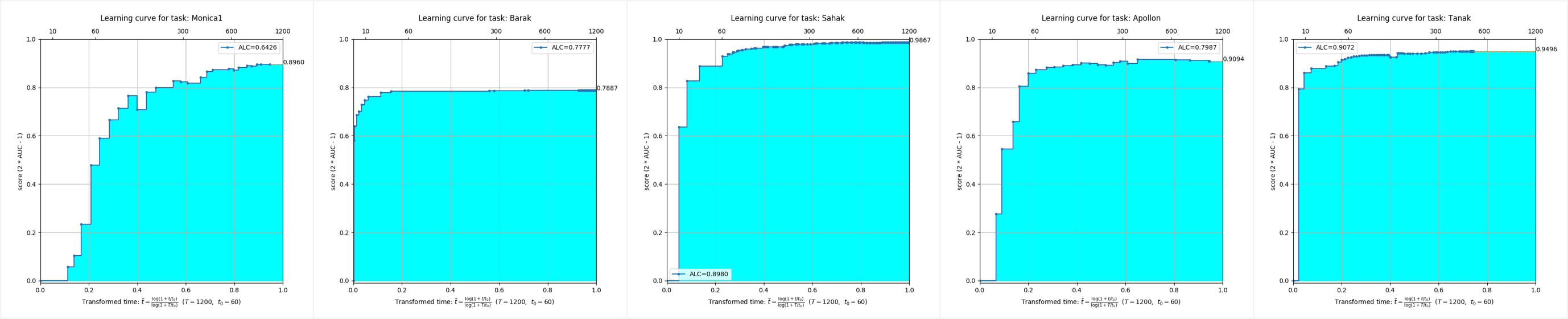
5つの異なるモードのデータセットでは、AutoDLアルゴリズムのストリームが非常に優れたフルタイム効果を達成し、非常に短い時間で非常に高い精度を達成できることがわかります。
このリポジトリは、Python 3.6+、Pytorch 1.3.1、Tensorflow 1.15でテストされています。
仮想環境にAutoDLをインストールする必要があります。 仮想環境に慣れていない場合は、ユーザーガイダンスを参照してください。
適切なPythonバージョンを使用して仮想環境を作成し、アクティブにします。
start_env.batファイルを作成しますMiniconda3ディレクトリに移動しますcmd.exe " /K " . M iniconda3 S cripts a ctivate.bat . M iniconda3start_env.batをダブルクリックして、autodl-gpuをインストールしますconda install pytorch==1.3.1
conda install torchvision -c pytorch
pip install autodl-gpupip install autodl-gpu手順については、迅速なアクセスのためにAutoDLローカルエフェクトテストを参照してください。例:コードなどの例/run_local_test.pyを参照してください。
クイックスタート画像分類を参照してください。サンプルコードはexamples/run_image_classification_example.pyに示されています
手順については、クイックスタートビデオ分類を参照してください
手順については、クイックアクセスについてはオーディオ分類を参照してください。たとえば、コードを参照してください。例/run_speech_classification_example.pyを参照してください
ガイダンスについては、迅速なテキストのテキスト分類を参照して、例/run_text_classification_example.pyのサンプルコードを参照してください。
ガイダンスについては、クイックスタートテーブルの分類を参照して、例:コードなどの例/run_tabular_classification_example.pyを参照してください。
python download_public_datasets.py| # | 名前 | タイプ | ドメイン | サイズ | ソース | データ(テストラベル付き) | テストラベル |
|---|---|---|---|---|---|---|---|
| 1 | ミュンスター | 画像 | HWR | 18 MB | mnist | Munster.Data | Munster.Solution |
| 2 | 市 | 画像 | オブジェクト | 128 MB | CIFAR-10 | City.Data | City.Solution |
| 3 | チャッキー | 画像 | オブジェクト | 128 MB | CIFAR-100 | Chucky.data | Chucky.Solution |
| 4 | ペドロ | 画像 | 人々 | 377 MB | PA-100K | pedro.data | Pedro.Solution |
| 5 | デカール | 画像 | 空中 | 73 MB | NWPU VHR-10 | decal.data | decal.solution |
| 6 | ハンマー | 画像 | 医学 | 111 MB | HAM10000 | hammer.data | Hammer.Solution |
| 7 | Kreatur | ビデオ | アクション | 469 MB | kth | kreatur.data | Kreatur.Solution |
| 8 | Kreatur3 | ビデオ | アクション | 588 MB | kth | kreatur3.data | Kreatur3.Solution |
| 9 | クラウト | ビデオ | アクション | 1.9 GB | kth | kraut.data | Kraut.Solution |
| 10 | カッツェ | ビデオ | アクション | 1.9 GB | kth | katze.data | Katze.Solution |
| 11 | data01 | スピーチ | スピーカー | 1.8 GB | - | data01.data | data01.Solution |
| 12 | data02 | スピーチ | 感情 | 53 MB | - | data02.data | data02.Solution |
| 13 | data03 | スピーチ | アクセント | 1.8 GB | - | data03.data | data03.Solution |
| 14 | data04 | スピーチ | ジャンル | 469 MB | - | data04.data | data04.Solution |
| 15 | data05 | スピーチ | 言語 | 208 MB | - | data05.data | data05.Solution |
| 16 | O1 | 文章 | コメント | 828 kb | - | o1.data | O1.Solution |
| 17 | O2 | 文章 | 感情 | 25 MB | - | o2.data | O2.Solution |
| 18 | O3 | 文章 | ニュース | 88 MB | - | o3.data | o3.solution |
| 19 | O4 | 文章 | スパム | 87 MB | - | o4.data | O4.Solution |
| 20 | O5 | 文章 | ニュース | 14 MB | - | o5.data | o5.solution |
| 21 | アダルト | 表形式 | 国勢調査 | 2 MB | アダルト | Adult.data | Adult.Solution |
| 22 | ディルバート | 表形式 | - | 162 MB | - | dilbert.data | Dilbert.Solution |
| 23 | 数字 | 表形式 | HWR | 137 MB | mnist | digits.data | 桁。ソリューション |
| 24 | マデリン | 表形式 | - | 2.6 MB | - | madeline.data | Madeline.Solution |
∎貢献への参加をheしないでください問題を開くか、PRを提出してください。

Apacheライセンス2.0


