AutoDL
v1.0
Inglés |

Autodl Challenge@Neurips Challenge, consulte la competencia Autodl para más detalles.
Autodl se centra en un algoritmo general que realiza automáticamente la clasificación de etiquetas múltiples de modalidades arbitrarias (imagen, video, voz, texto, datos tabulares). Ajuste de datos, características, modelos, para problemas como los super-parámetros, puede hacer un clasificador con un excelente rendimiento en tan solo 10 segundos. Este proyecto ha logrado resultados extremadamente excelentes en 24 conjuntos de datos fuera de línea y 15 conjuntos de datos en línea en diferentes campos . Autodl tiene las siguientes características:
☕Full -Automatic : Marco de aprendizaje profundo/aprendizaje profundo totalmente automático, no se requiere una intervención manual para todo el proceso. Todos los detalles de datos, características y modelos se han ajustado a los mejores, y los problemas de limitación de recursos, sesgo de datos, datos pequeños, ingeniería de características, selección de modelos, optimización de la estructura de red y búsqueda de hiperparameter se han resuelto uniformemente. Simplemente prepare los datos, inicie Autodl y tome una taza de café .
? Ha logrado resultados extremadamente excelentes en diferentes campos , como reconocimiento de peatones, reconocimiento de acción peatonal, reconocimiento facial, reconocimiento de huellas de voz, clasificación de música, clasificación de acento, clasificación de idiomas, clasificación de emociones, clasificación de correo electrónico, clasificación de noticias, optimización publicitaria, sistemas de recomendación, búsqueda de búsqueda motores, marketing de precisión, etc.
? La biblioteca de modelos incluye modelos campeones preferidos de LR/SVM/LGB/CGB/XGB a Resnet*/MC3/DNN/TinResnet*/Textcnn/Rcnn/Gru/Bert y así sucesivamente.
⚡Extreme Velocidad/tiempo real : Obtenga un rendimiento competitivo del modelo en tan rápido como diez segundos. Los resultados se actualizan en tiempo real (segundos) y puede recibir comentarios en tiempo real sobre el modelo sin esperar.
Lista preliminar (Deepwisdom clasificada primero en total, con una clasificación promedio de 1.2, y ganó 4 primeros en 5 conjuntos de datos) 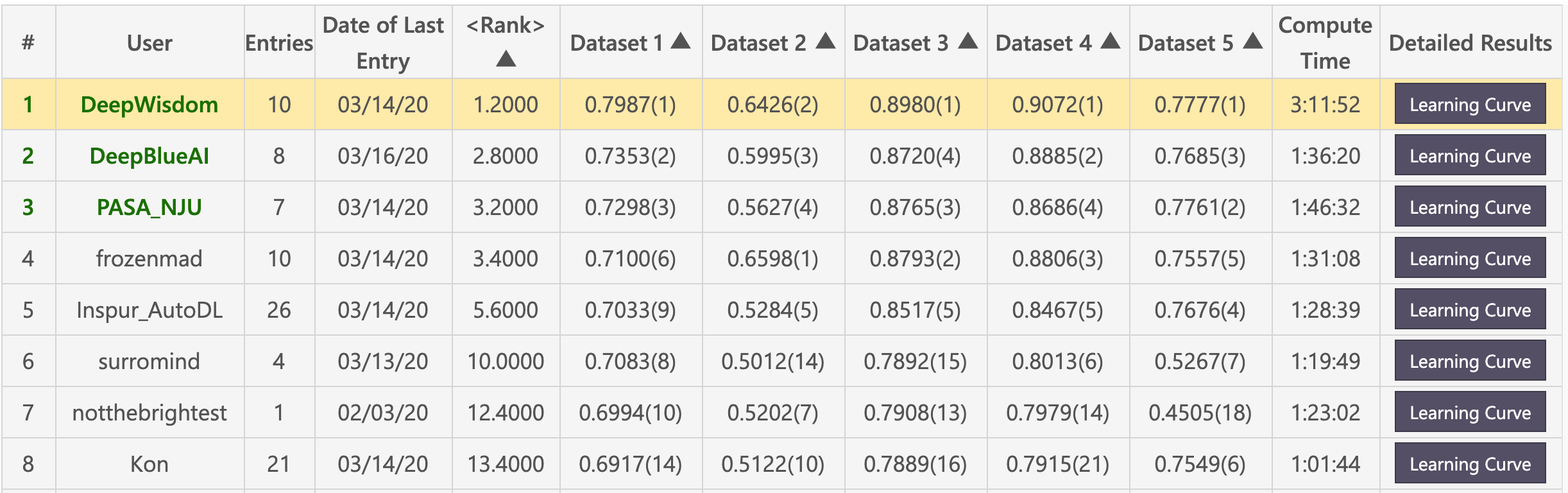
Lista de finales (Deepwisdom clasificada primero en total, con una clasificación promedio de 1.8, y clasificó 7 primeros en 10 conjuntos de datos) 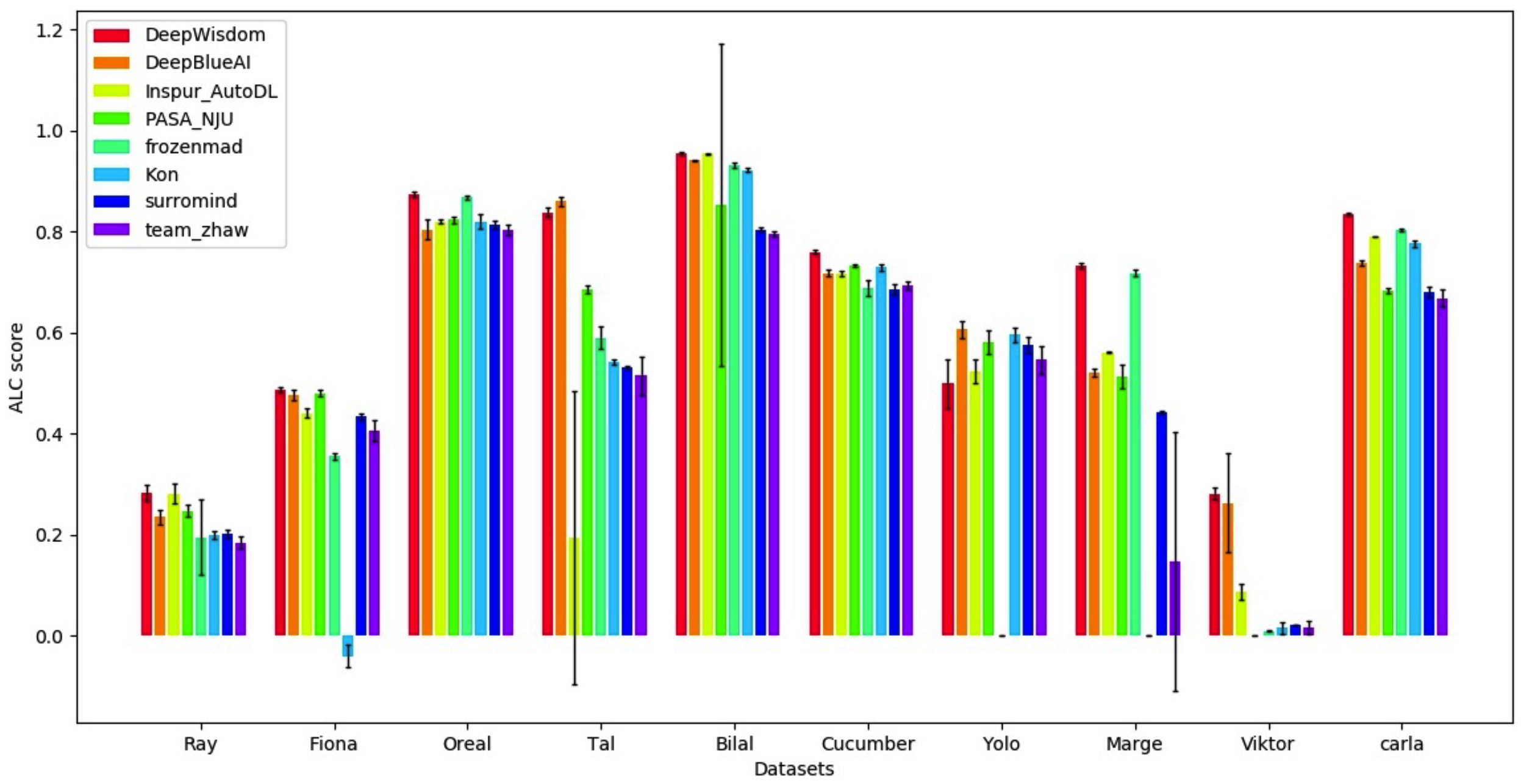
Entorno básico
python > =3.5
CUDA 10
cuDNN 7.5almacén de clon
cd <path_to_your_directory>
git clone https://github.com/DeepWisdom/AutoDL.git
Modelo previamente capacitado para descargar el modelo Speech_model.h5 y colóquelo en AutoDL_sample_code_submission/at_speech/pretrained_models/ directorio.
Opcional: use un entorno Docker sincronizado con la competencia
cd path/to/autodl/
docker run -it -v "$(pwd):/app/codalab" -p 8888:8888 evariste/autodl:cpu-latest
nvidia-docker run -it -v "$(pwd):/app/codalab" -p 8888:8888 evariste/autodl:gpu-latest
Preparación del conjunto de datos: use el conjunto de datos de muestra en AutoDL_sample_data , o descargue el conjunto de datos públicos del concurso.
Realizar pruebas locales
python run_local_test.py
Las pruebas locales se utilizan en su totalidad. python run_local_test.py -dataset_dir='AutoDL_sample_data/miniciao' -code_dir='AutoDL_sample_code_submission' Puede ver la página HTML para recibir comentarios de curva en tiempo real en AutoDL_scoring_output/ .
Para más detalles, consulte el Oficial de Autodl Challenge Starting_Kit.
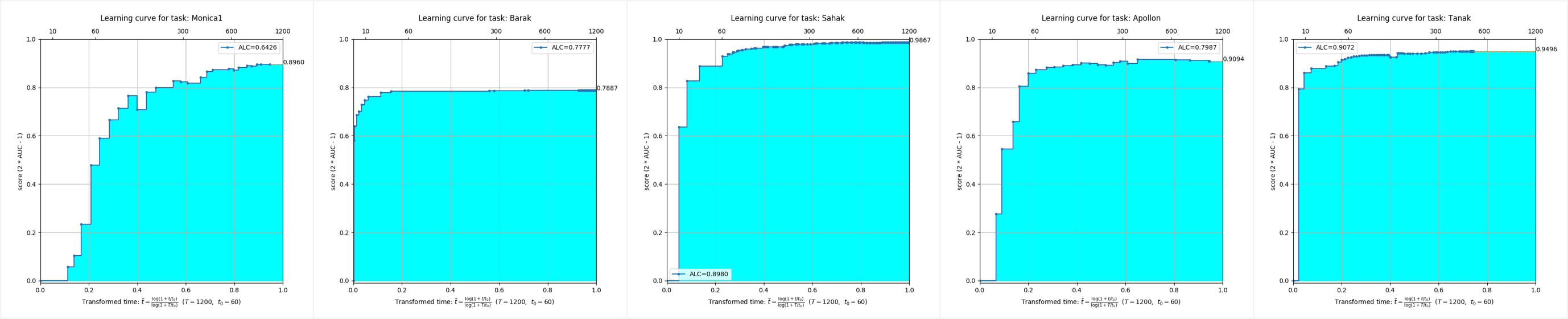
Se puede ver que, en los conjuntos de datos de cinco modos diferentes, las corrientes de algoritmo AutoDL han logrado efectos de tiempo completo extremadamente excelentes y pueden lograr una precisión extremadamente alta en muy poco tiempo.
Este repositorio se prueba en Python 3.6+, Pytorch 1.3.1 y TensorFlow 1.15.
Debe instalar Autodl en el entorno virtual. Si no está familiarizado con el entorno virtual, consulte la guía del usuario.
Cree un entorno virtual con la versión Python apropiada y activelo.
start_env.batMiniconda3 instalado cmd.exe " /K " . M iniconda3 S cripts a ctivate.bat . M iniconda3start_env.bat para instalar autodl-gpu conda install pytorch==1.3.1
conda install torchvision -c pytorch
pip install autodl-gpupip install autodl-gpuPara obtener instrucciones, consulte la prueba de efecto local de AutoDL para obtener acceso rápido y consulte Ejemplos/run_local_test.py por ejemplo.
Consulte la clasificación de imagen de inicio rápido y el código de muestra se muestra en ejemplos/run_image_classification_example.py
Para obtener instrucciones, consulte la clasificación de video de inicio rápido.
Para obtener instrucciones, consulte la clasificación de audio para obtener acceso rápido y, por ejemplo, el código, consulte Ejemplos/Run_speech_Classification_Example.py
Para obtener orientación, consulte la clasificación de texto de texto rápido y vea los códigos de ejemplo en ejemplos/run_text_classification_example.py.
Para obtener orientación, consulte la clasificación rápida de la tabla de inicio y vea los ejemplos/run_tabular_classification_example.py, por ejemplo, el código.
python download_public_datasets.py| # | Nombre | Tipo | Dominio | Tamaño | Fuente | Datos (sin etiquetas de prueba) | Etiquetas de prueba |
|---|---|---|---|---|---|---|---|
| 1 | Munster | Imagen | HWR | 18 MB | Mnista | munster.data | Munster.Solución |
| 2 | Ciudad | Imagen | Objetos | 128 MB | Cifar-10 | Ciudad. Data | ciudad.Solución |
| 3 | Fucky | Imagen | Objetos | 128 MB | Cifar-100 | chucky.data | Chucky.Solución |
| 4 | Pedo | Imagen | Gente | 377 MB | PA-100K | pedro.data | Pedro.Solución |
| 5 | Calcomanía | Imagen | Aéreo | 73 MB | NWPU VHR-10 | calcomanía. Data | calcomanía. |
| 6 | Martillo | Imagen | Médico | 111 MB | Ham10000 | martillo | martillo |
| 7 | Kreatur | Video | Acción | 469 MB | Kth | kreatur.data | Kreatur.Solución |
| 8 | Kreatur3 | Video | Acción | 588 MB | Kth | kreatur3.data | Kreatur3.Solución |
| 9 | Kraut | Video | Acción | 1.9 GB | Kth | kraut.data | Kraut.Solución |
| 10 | Katze | Video | Acción | 1.9 GB | Kth | katze.data | Katze.Solución |
| 11 | Data01 | Discurso | Vocero | 1.8 GB | - | data.data | Data01.Solution |
| 12 | Data02 | Discurso | Emoción | 53 MB | - | data02.data | Data02.Solution |
| 13 | Data03 | Discurso | Acento | 1.8 GB | - | data03.data | Data03.Solution |
| 14 | Data04 | Discurso | Género | 469 MB | - | data04.data | Data04.Solución |
| 15 | Data05 | Discurso | Idioma | 208 MB | - | data05.data | Data05.Solution |
| 16 | O1 | Texto | Comentario | 828 kb | - | O1.data | O1.Solución |
| 17 | O2 | Texto | Emoción | 25 MB | - | O2. Data | O2.SOLUCIÓN |
| 18 | O3 | Texto | Noticias | 88 MB | - | O3. Data | O3.SOLUCIÓN |
| 19 | O4 | Texto | Correo basura | 87 MB | - | O4. Data | O4.Solución |
| 20 | O5 | Texto | Noticias | 14 MB | - | O5. Data | O5.Solución |
| veintiuno | Adulto | Tabular | Censo | 2 MB | Adulto | Data para adultos | adulto. Solución |
| Veintidós | Dilbert | Tabular | - | 162 MB | - | Dilbert.data | Dilbert.Solution |
| veintitrés | Dígitos | Tabular | HWR | 137 MB | Mnista | data.data | dígitos. Solución |
| veinticuatro | Madeline | Tabular | - | 2.6 MB | - | Madeline. Data | Madeline.SOLUCIÓN |
❤️ Por favor, no dude en participar en la contribución, abra un problema o envíe PRS.

Licencia de Apache 2.0


