AutoDL
v1.0
English | Simplified Chinese

AutoDL Challenge@NeurIPS Challenge, see AutoDL Competition for details.
AutoDL focuses on a general algorithm that automatically performs multi-label classification of arbitrary modalities (image, video, voice, text, tabular data). It can use a set of standard algorithm streams to solve complex classification problems in the real world, and solve data adjustment, features, models, For troubles such as super-parameters, you can make a classifier with excellent performance in as little as 10 seconds. This project has achieved extremely excellent results in 24 offline data sets and 15 online data sets in different fields . AutoDL has the following features:
☕Full -automatic : Fully automatic deep learning/machine learning framework, no manual intervention is required for the entire process. All details of data, features, and models have been adjusted to the best, and the problems of resource limitation, data skew, small data, feature engineering, model selection, network structure optimization, and hyperparameter search have been uniformly solved. Just prepare the data, start AutoDL, and have a cup of coffee .
? University : Supports arbitrary modalities, including images, video, audio, text and structured tabular data, and supports any multi-label classification problem , including binary classification, multi-classification, and multi-label classification. It has achieved extremely excellent results in different fields , such as pedestrian recognition, pedestrian action recognition, face recognition, voiceprint recognition, music classification, accent classification, language classification, emotion classification, email classification, news classification, advertising optimization, recommendation Systems, search engines, precision marketing, etc.
? Excellent results : AutoDL competition won an overwhelming champion program, including support for traditional machine learning models and the latest deep learning models. The model library includes preferred champion models from LR/SVM/LGB/CGB/XGB to ResNet*/MC3/DNN/ThinResnet*/TextCNN/RCNN/GRU/BERT and so on.
⚡Extreme Speed/Real-Time : Get competitive model performance in as fast as ten seconds. The results are refreshed in real time (seconds) and you can get real-time feedback on the model without waiting.
Preliminary list (DeepWisdom ranked first in total, with an average ranking of 1.2, and won 4 firsts in 5 data sets) 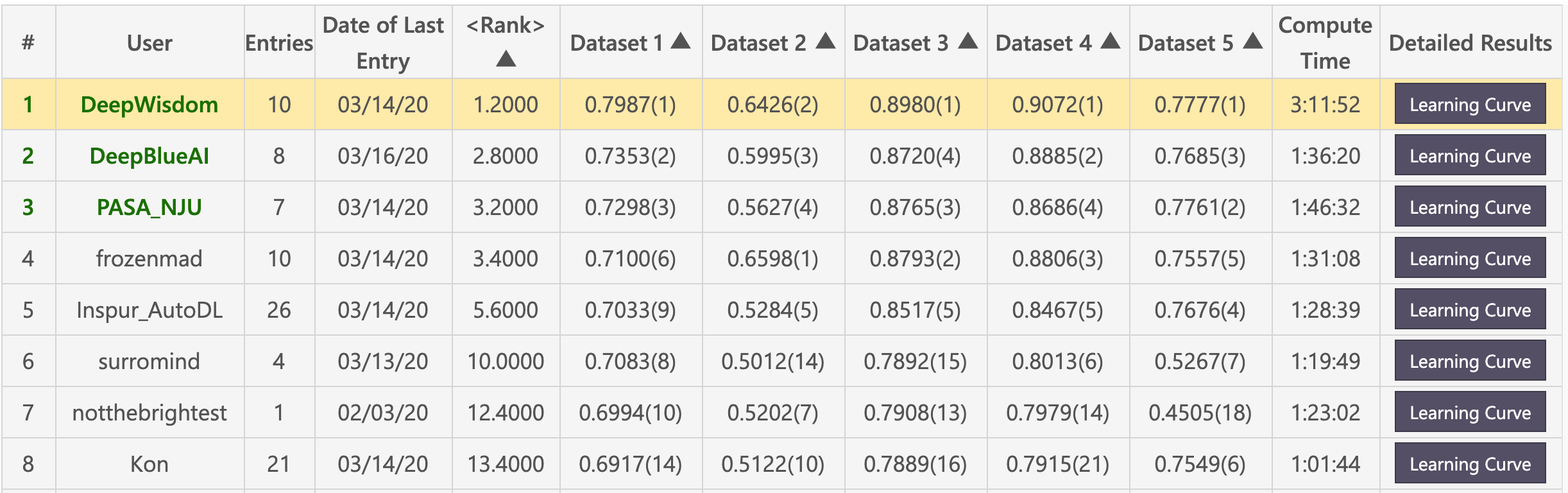
Finals list (DeepWisdom ranked first in total, with an average ranking of 1.8, and ranked 7 firsts in 10 data sets) 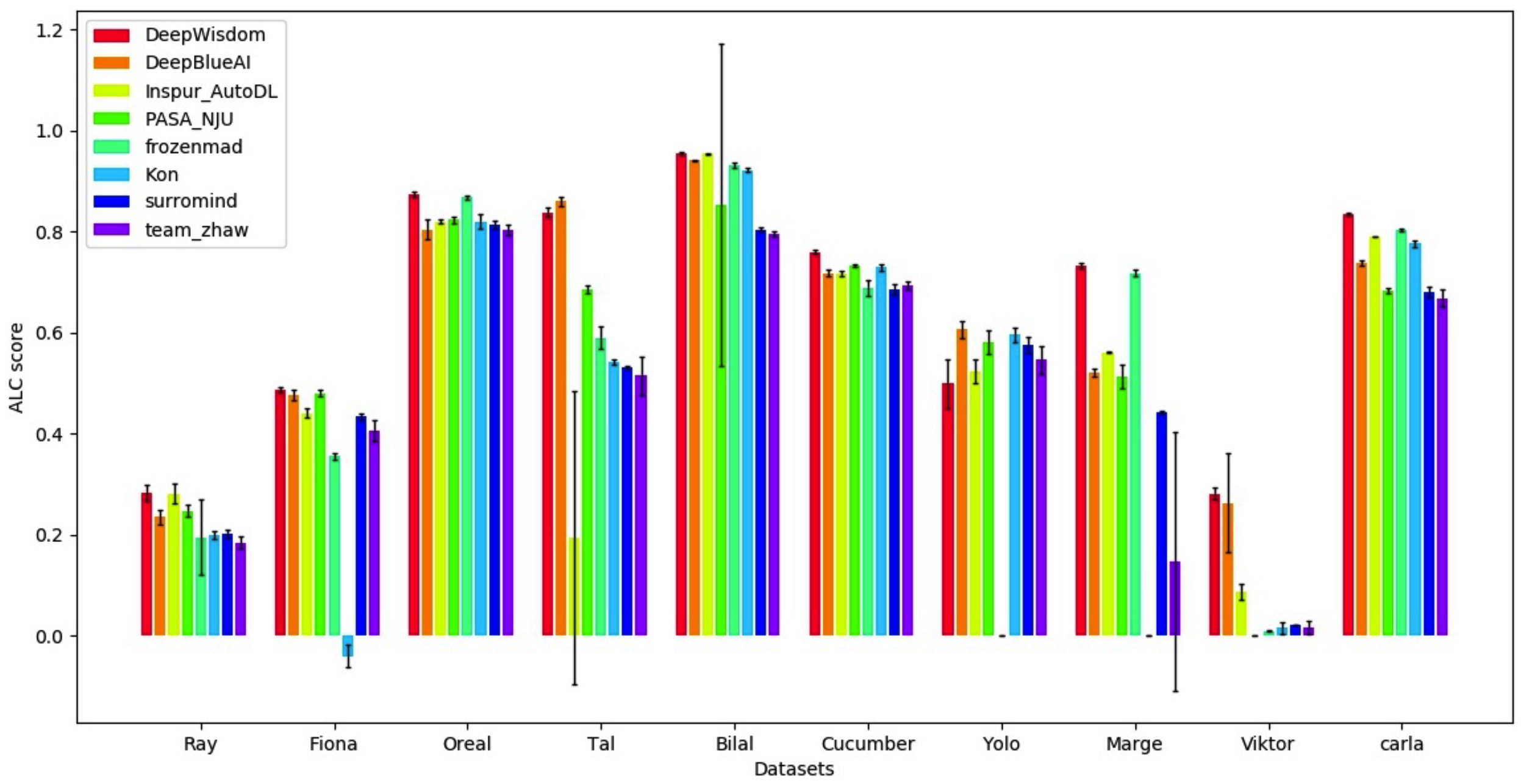
Basic environment
python > =3.5
CUDA 10
cuDNN 7.5clone warehouse
cd <path_to_your_directory>
git clone https://github.com/DeepWisdom/AutoDL.git
Pre-trained model to download the model speech_model.h5 and put it in AutoDL_sample_code_submission/at_speech/pretrained_models/ directory.
Optional: Use a docker environment synchronized with the competition
cd path/to/autodl/
docker run -it -v "$(pwd):/app/codalab" -p 8888:8888 evariste/autodl:cpu-latest
nvidia-docker run -it -v "$(pwd):/app/codalab" -p 8888:8888 evariste/autodl:gpu-latest
Dataset preparation: Use the sample dataset in AutoDL_sample_data , or batch download the contest public dataset.
Perform local testing
python run_local_test.py
Local tests are used in full. python run_local_test.py -dataset_dir='AutoDL_sample_data/miniciao' -code_dir='AutoDL_sample_code_submission' You can view the HTML page for real-time learning curve feedback in AutoDL_scoring_output/ directory.
For details, please refer to AutoDL Challenge official starting_kit.
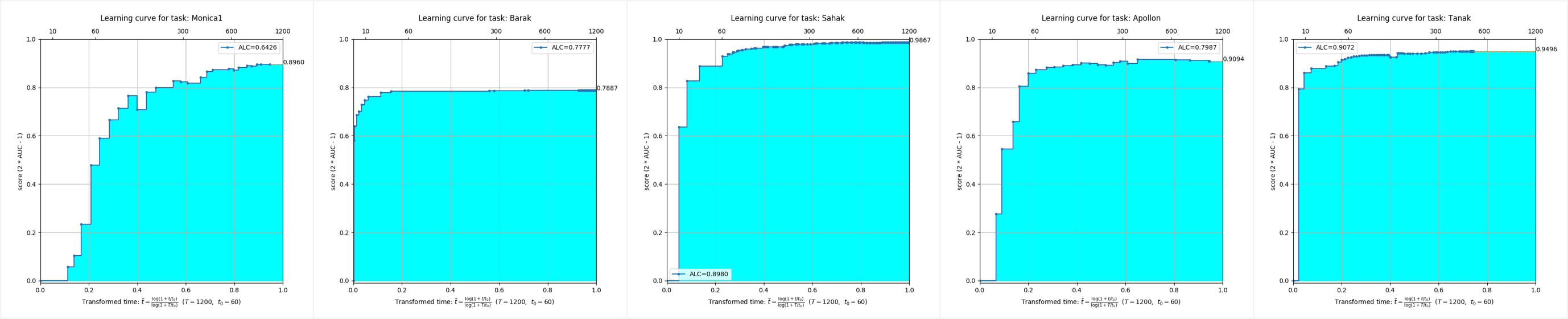
It can be seen that under the data sets of five different modes, the AutoDL algorithm streams have achieved extremely excellent full-time effects and can achieve extremely high accuracy in a very short time.
This repository is tested on Python 3.6+, PyTorch 1.3.1 and TensorFlow 1.15.
You should install autodl in the virtual environment. If you are not familiar with the virtual environment, please refer to user guidance.
Create a virtual environment with the appropriate Python version and activate it.
start_env.bat fileMiniconda3 directory cmd.exe " /K " . M iniconda3 S cripts a ctivate.bat . M iniconda3start_env.bat to install autodl-gpu conda install pytorch==1.3.1
conda install torchvision -c pytorch
pip install autodl-gpupip install autodl-gpuFor instructions, please refer to the AutoDL local effect test for quick access, and see examples/run_local_test.py for example code.
See the quick start image classification, and the sample code is shown in examples/run_image_classification_example.py
For instructions, please refer to the quick start video classification. For example code, please refer to examples/run_video_classification_example.py
For instructions, please refer to the audio classification for quick access, and for example code, please refer to examples/run_speech_classification_example.py
For guidance, see the text classification of quick-to-hand text, and see example codes in examples/run_text_classification_example.py.
For guidance, see the quick start table classification, and see examples/run_tabular_classification_example.py for example code.
python download_public_datasets.py| # | Name | Type | Domain | Size | Source | Data (w/o test labels) | Test labels |
|---|---|---|---|---|---|---|---|
| 1 | Munster | Image | HWR | 18 MB | MNIST | munster.data | munster.solution |
| 2 | City | Image | Objects | 128 MB | Cifar-10 | city.data | city.solution |
| 3 | Chucky | Image | Objects | 128 MB | Cifar-100 | chucky.data | chucky.solution |
| 4 | Pedro | Image | People | 377 MB | PA-100K | pedro.data | pedro.solution |
| 5 | Decal | Image | Aerial | 73 MB | NWPU VHR-10 | decal.data | decal.solution |
| 6 | Hammer | Image | Medical | 111 MB | Ham10000 | hammer.data | hammer.solution |
| 7 | Kreatur | Video | Action | 469 MB | KTH | kreatur.data | kreatur.solution |
| 8 | Kreatur3 | Video | Action | 588 MB | KTH | kreatur3.data | kreatur3.solution |
| 9 | Kraut | Video | Action | 1.9 GB | KTH | kraut.data | kraut.solution |
| 10 | Katze | Video | Action | 1.9 GB | KTH | katze.data | katze.solution |
| 11 | data01 | Speech | Speaker | 1.8 GB | -- | data01.data | data01.solution |
| 12 | data02 | Speech | Emotion | 53 MB | -- | data02.data | data02.solution |
| 13 | data03 | Speech | Accent | 1.8 GB | -- | data03.data | data03.solution |
| 14 | data04 | Speech | Genre | 469 MB | -- | data04.data | data04.solution |
| 15 | data05 | Speech | Language | 208 MB | -- | data05.data | data05.solution |
| 16 | O1 | Text | Comments | 828 KB | -- | O1.data | O1.solution |
| 17 | O2 | Text | Emotion | 25 MB | -- | O2.data | O2.solution |
| 18 | O3 | Text | News | 88 MB | -- | O3.data | O3.solution |
| 19 | O4 | Text | Spam | 87 MB | -- | O4.data | O4.solution |
| 20 | O5 | Text | News | 14 MB | -- | O5.data | O5.solution |
| twenty one | Adult | Tabular | Census | 2 MB | Adult | adult.data | adult.solution |
| twenty two | Dilbert | Tabular | -- | 162 MB | -- | dilbert.data | dilbert.solution |
| twenty three | Digits | Tabular | HWR | 137 MB | MNIST | digits.data | digits.solution |
| twenty four | Madeline | Tabular | -- | 2.6 MB | -- | madeline.data | madeline.solution |
❤️ Please do not hesitate to participate in the contribution Open an issue or submit PRs.

Apache License 2.0


