3DMPPE_POSENET_RELEASE
1.0.0
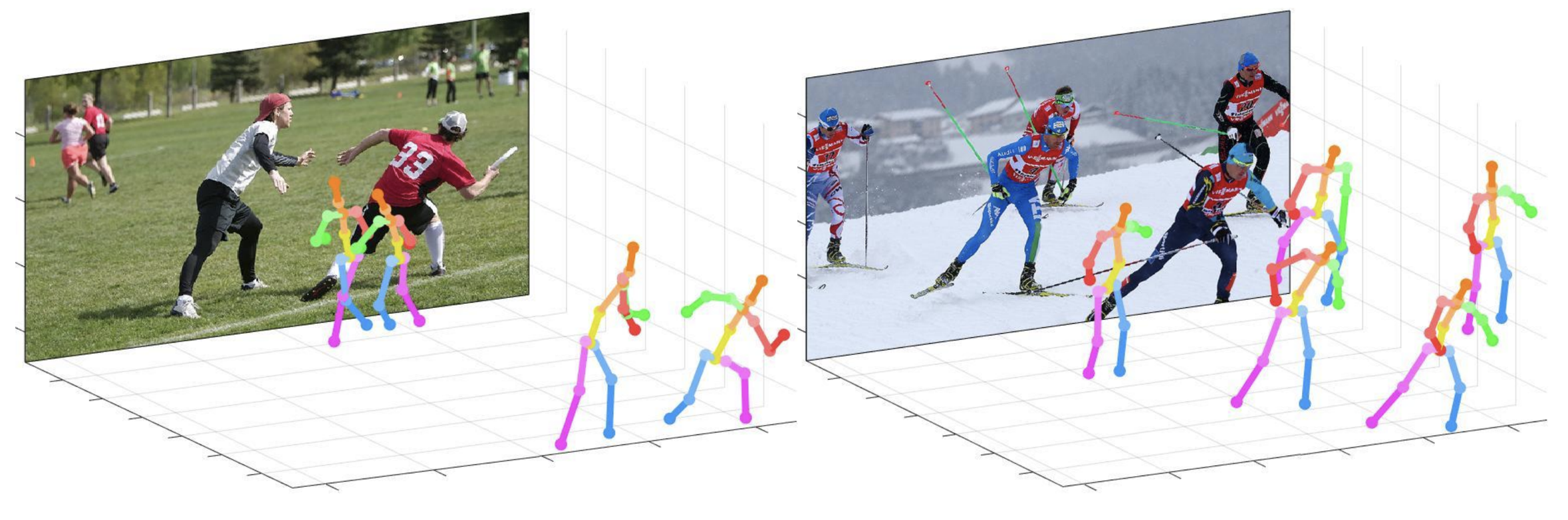

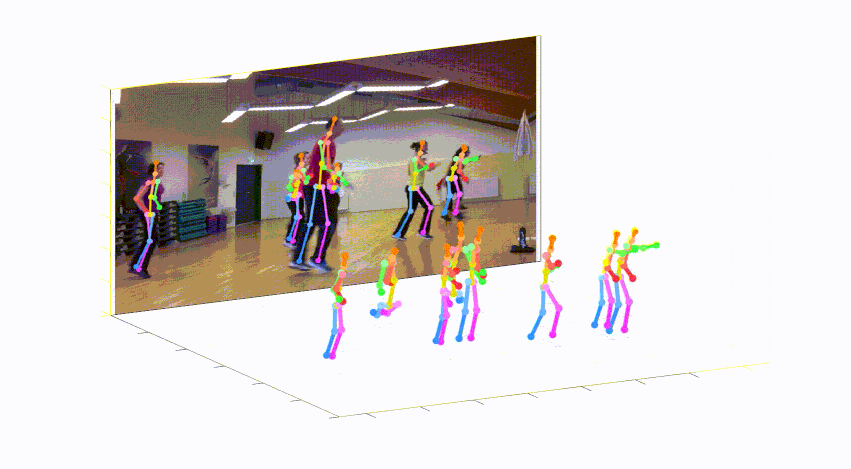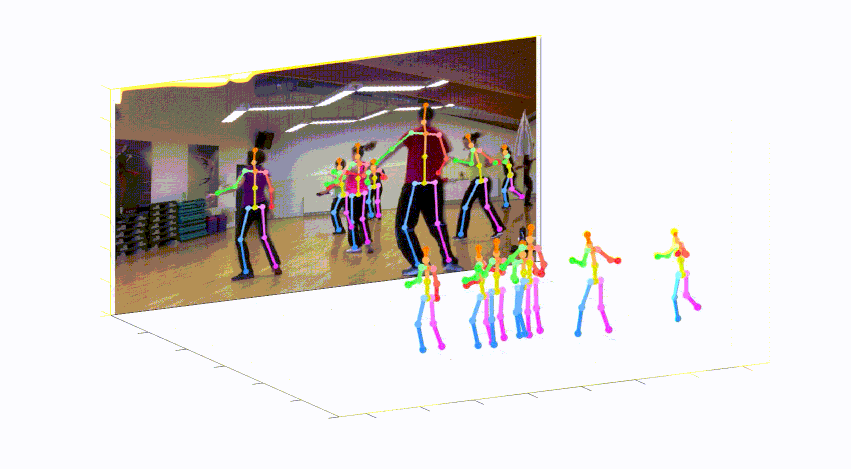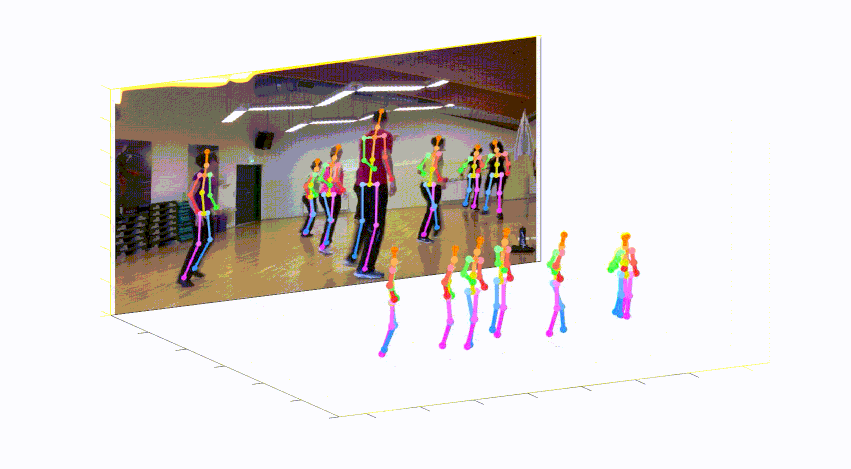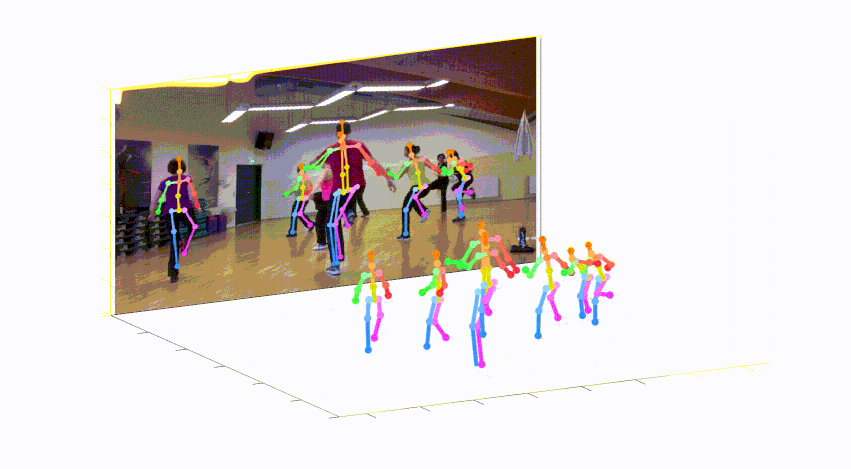


このレポは、単一のRGB画像からの3Dマルチパーソンポーズ推定のためのカメラ距離が認識されるトップダウンアプローチの公式Pytorch実装です(ICCV 2019)。 Posenet部品が含まれています。
このリポジトリが提供するもの:
このコードは、2つのNVIDIA 1080TI GPUを備えたUbuntu 16.04、Cuda 9.0、Cudnn 7.1環境でテストされています。
Anaconda 3を使用したPython 3.6.5バージョンは、開発に使用されます。
demoフォルダーでクイックデモを試すことができます。
demoフォルダーでinput.jpgを準備し、事前に訓練されたスナップショットを準備します。bbox_listを設定します。root_depth_listをここに設定します。python demo.py --gpu 0 --test_epoch 24を実行します。output_pose_2d.jpgと3Dポーズを示す新しいウィンドウを見ることができます。 ${POSE_ROOT}は以下のように説明されています。
${POSE_ROOT}
|-- data
|-- demo
|-- common
|-- main
|-- tool
|-- vis
`-- output
dataには、データの読み込みコードと画像へのソフトリンクと注釈ディレクトリが含まれています。demoにはデモコードが含まれています。common 、3Dマルチパーソンポーズ推定システムのカーネルコードが含まれています。main 、ネットワークをトレーニングまたはテストするための高レベルコードが含まれています。toolには、データの前処理コードが含まれています。このコードを実行する必要はありません。以下に事前に処理されたデータを提供します。visには、3D視覚化のスクリプトが含まれています。outputには、ログ、トレーニングされたモデル、視覚化された出力、およびテスト結果が含まれます。以下のように、 dataのディレクトリ構造に従う必要があります。
${POSE_ROOT}
|-- data
| |-- Human36M
| | |-- bbox_root
| | | |-- bbox_root_human36m_output.json
| | |-- images
| | |-- annotations
| |-- MPII
| | |-- images
| | |-- annotations
| |-- MSCOCO
| | |-- bbox_root
| | | |-- bbox_root_coco_output.json
| | |-- images
| | | |-- train2017
| | | |-- val2017
| | |-- annotations
| |-- MuCo
| | |-- data
| | | |-- augmented_set
| | | |-- unaugmented_set
| | | |-- MuCo-3DHP.json
| |-- MuPoTS
| | |-- bbox_root
| | | |-- bbox_mupots_output.json
| | |-- data
| | | |-- MultiPersonTestSet
| | | |-- MuPoTS-3D.json
圧縮せずにGoogleドライブから複数のファイルをダウンロードするには、これを試してください。 Google Driveリンクからデータセットをダウンロードしようとしたときに「制限のダウンロード」という問題に問題がある場合は、このトリックを試してください。
* Go the shared folder, which contains files you want to copy to your drive
* Select all the files you want to copy
* In the upper right corner click on three vertical dots and select “make a copy”
* Then, the file is copied to your personal google drive account. You can download it from your personal account.
以下のように、 outputフォルダーのディレクトリ構造に従う必要があります。
${POSE_ROOT}
|-- output
|-- |-- log
|-- |-- model_dump
|-- |-- result
`-- |-- vis
outputフォルダーを作成すると、フォルダーフォームではなく、大きなストレージ容量が必要になるため、推奨されます。logフォルダーには、トレーニングログファイルが含まれています。model_dumpフォルダーには、各エポックの保存されたチェックポイントが含まれています。resultフォルダーには、テスト段階で生成された最終推定ファイルが含まれています。visフォルダーには視覚化された結果が含まれています。$DB_NAME_img_name.pyを実行して、 .txt形式で画像ファイル名を取得します。preds_2d_kpt_$DB_NAME.mat 、 preds_3d_kpt_$DB_NAME.mat )をsingleまたはmultiフォルダーに配置します。draw_3Dpose_$DB_NAME.mを実行しますmain/config.pyでは、使用するデータセット、ネットワークバックボーン、入力サイズなどを含むモデルの設定を変更できます。mainフォルダーで実行します
python train.py --gpu 0-1GPU 0,1でネットワークをトレーニングします。
実験を続けたい場合は、実行してください
python train.py --gpu 0-1 --continue --gpu 0,1 --gpu 0-1の代わりに使用できます。
訓練されたモデルoutput/model_dump/に配置します。
mainフォルダーで実行します
python test.py --gpu 0-1 --test_epoch 20 20番目のエポック訓練モデルでGPU 0,1のネットワークをテストする。 --gpu 0,1 --gpu 0-1の代わりに使用できます。
ここでは、PosEnetのパフォーマンスを報告します。
評価のために、 test.pyを実行するか、 Human36Mに評価コードがあります。
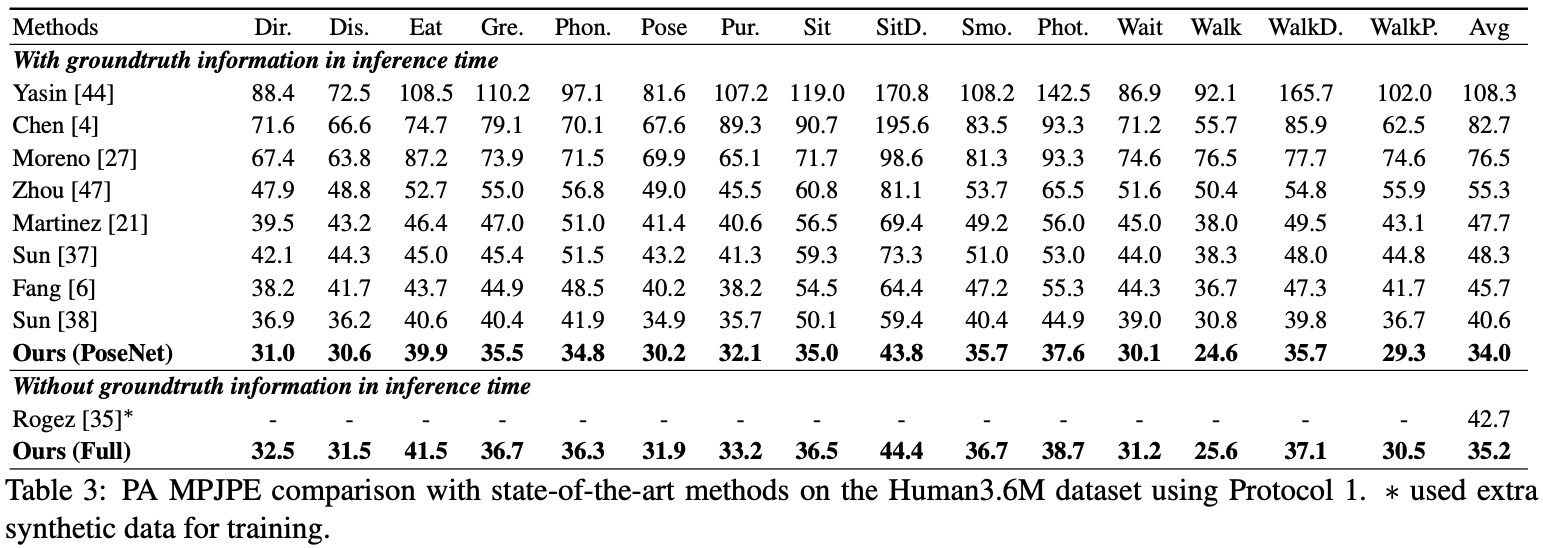
評価のために、 test.pyを実行するか、 Human36Mに評価コードがあります。
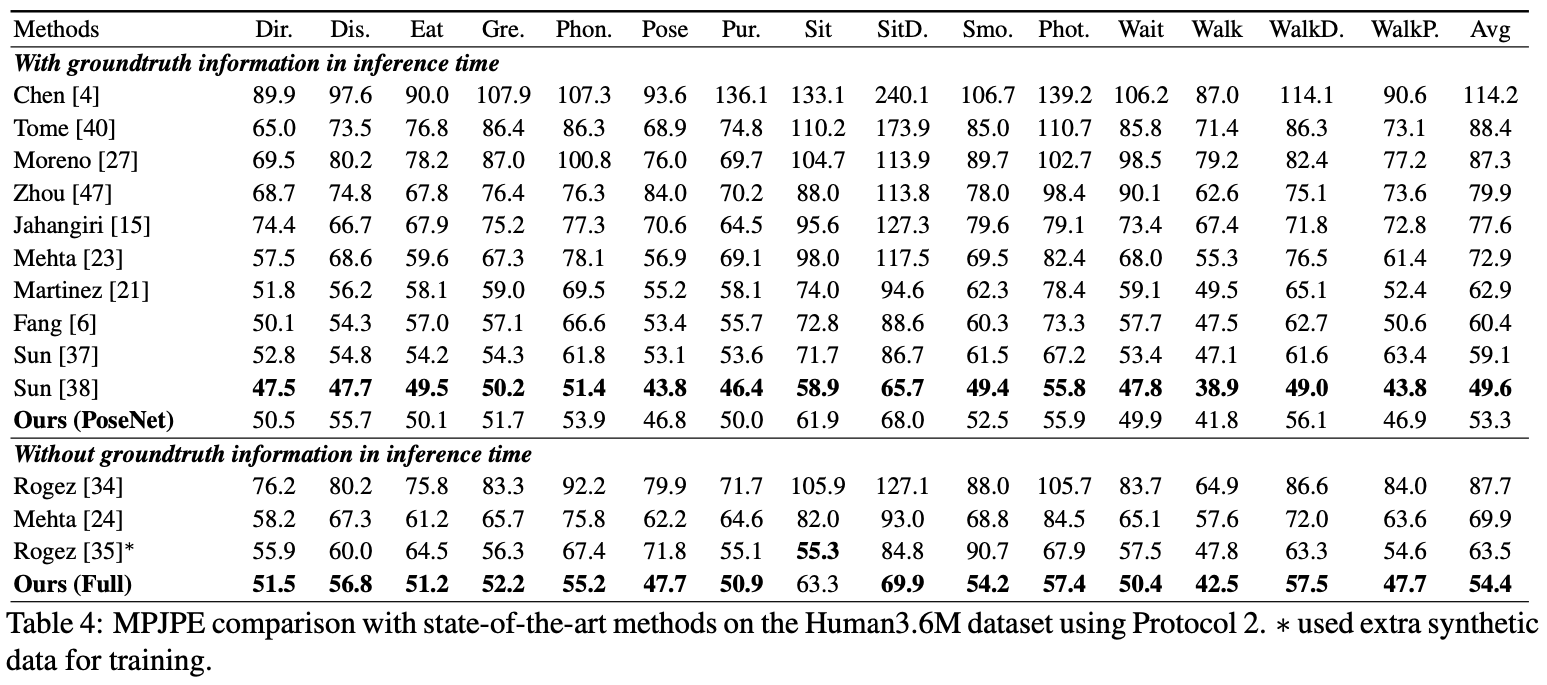
評価のために、 test.pyを実行します。その後、 data/MuPoTS/mpii_mupots_multiperson_eval.m data/MuPoTS/dataに移動します。また、テスト結果ファイル( preds_2d_kpt_mupots.matおよびpreds_3d_kpt_mupots.mat )をdata/MuPoTS/dataに移動します。次に、評価モードの引数でmpii_mupots_multiperson_eval.mを実行します。
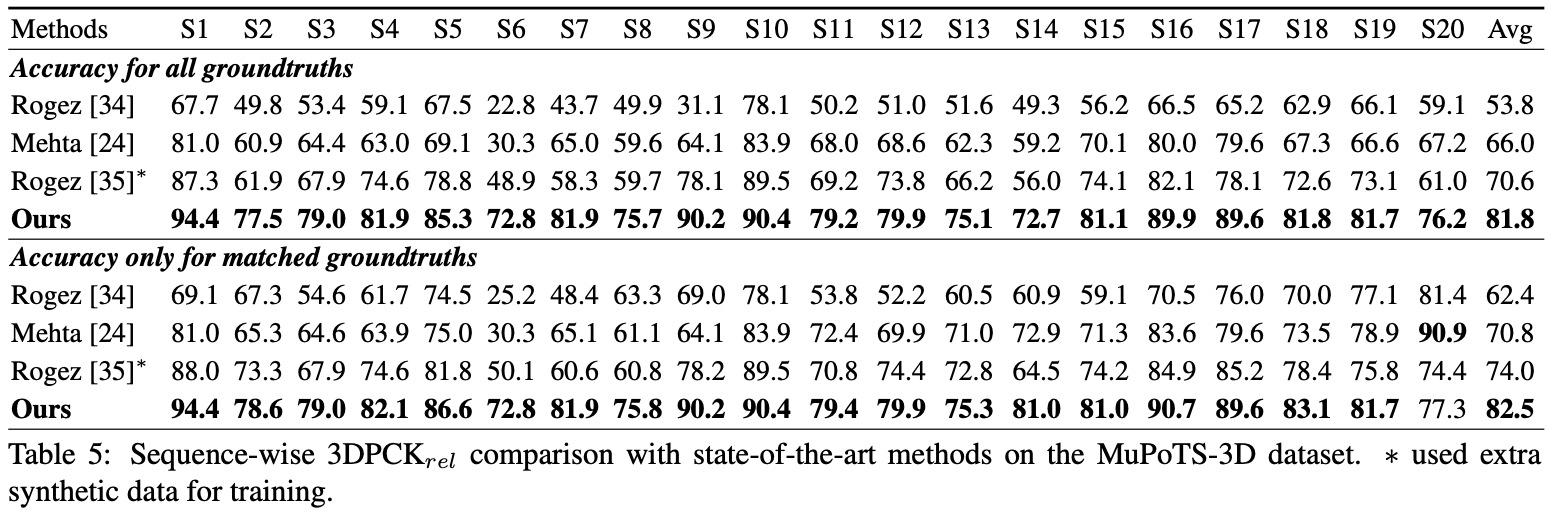
さらに、MSCOCOデータセットで推定3Dヒトルート座標を提供します。座標は3Dカメラ座標系にあり、焦点距離はx軸とy軸の両方で1500mmに設定されています。私の論文の補足物質の式2または方程式を使用して、焦点距離と対応する距離を変更できます。
@InProceedings{Moon_2019_ICCV_3DMPPE,
author = {Moon, Gyeongsik and Chang, Juyong and Lee, Kyoung Mu},
title = {Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image},
booktitle = {The IEEE Conference on International Conference on Computer Vision (ICCV)},
year = {2019}
}


