transformers interpret
v0.10.0
トランスフォーマーの解釈は、?トランスパッケージ。
トランスフォーマーパッケージトランスの哲学に沿って、解釈することにより、トランスモデルをわずか2行で説明できます。説明者は、テキストモデルとコンピュータービジョンモデルの両方で利用できます。視覚化は、ノートブックでも利用可能であり、Savable PNGおよびHTMLファイルとしても利用できます。
こちらの流線デモアプリをご覧ください
pip install transformers - interpret変圧器のモデルとトークナイザーを初期化し、 `SequenceClassificationExplainer`を介して実行することから始めましょう。
この例ではdistilbert-base-uncased-finetuned-sst-2-english使用しています。
from transformers import AutoModelForSequenceClassification , AutoTokenizer
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
# With both the model and tokenizer initialized we are now able to get explanations on an example text.
from transformers_interpret import SequenceClassificationExplainer
cls_explainer = SequenceClassificationExplainer (
model ,
tokenizer )
word_attributions = cls_explainer ( "I love you, I like you" )これは、次のタプルのリストを返します。
> >> word_attributions
[( '[CLS]' , 0.0 ),
( 'i' , 0.2778544699186709 ),
( 'love' , 0.7792370723380415 ),
( 'you' , 0.38560088858031094 ),
( ',' , - 0.01769750505546915 ),
( 'i' , 0.12071898121557832 ),
( 'like' , 0.19091105304734457 ),
( 'you' , 0.33994871536713467 ),
( '[SEP]' , 0.0 )]正の帰属数は、単語が予測されたクラスに積極的に寄与することを示しますが、負の数は、予測クラスに否定的に寄与する単語を示します。ここで私たちはあなたを愛していることがわかります。
予測されたクラスが実際に何であるかを知りたい場合に備えて、 predicted_class_index使用できます。
> >> cls_explainer . predicted_class_index
array ( 1 )また、モデルに各クラスのラベル名がある場合、 predicted_class_nameを使用してこれらも表示できます。
> >> cls_explainer . predicted_class_name
'POSITIVE' 特に多くのテキストがある場合には、数値の属性を読むのが難しい場合があります。それを支援するために、ビルドVizライブラリのCaptumを使用して、属性を強調するHTMLファイルを作成するvisualize()メソッドも提供します。
ノートブックに載っている場合、 visualize()メソッドへの呼び出しは視覚化を内側に表示します。または、引数としてFilepathを渡すことができ、HTMLファイルが作成され、ブラウザで説明HTMLを表示できます。
cls_explainer . visualize ( "distilbert_viz.html" )
帰属の説明は、予測クラスに限定されません。混合感情を含むより複雑な文をテストしましょう。
以下の例では、実際の予測が何であるかに関係なく、ネガティブクラスについて、属性を説明したいという引数としてclass_name="NEGATIVE"を渡します。これはバイナリ分類器であるため、事実上、逆の帰属を取得しています。
cls_explainer = SequenceClassificationExplainer ( model , tokenizer )
attributions = cls_explainer ( "I love you, I like you, I also kinda dislike you" , class_name = "NEGATIVE" )この場合、Modelは同じ予測を生成したため、 predicted_class_nameポジティブクラスの予測を引き続き返しますが、それでも予測された結果に関係なく、ネガティブクラスの帰属を見ることに興味があります。
> >> cls_explainer . predicted_class_name
'POSITIVE'しかし、帰属を視覚化すると、「 ...ちょっと嫌悪」という言葉が「ネガティブ」クラスの予測に貢献していることがわかります。
cls_explainer . visualize ( "distilbert_negative_attr.html" )
さまざまなクラスの帰属を取得することは、多数の異なるクラスのモデル予測を検査し、モデルが正しいものを「見ている」という正気確認を可能にするため、マルチクラスの問題に特に洞察に富んでいます。
この例の詳細な説明については、このマルチクラス分類ノートブックをチェックアウトしてください。
PairwiseSequenceClassificationExplainerは、入力シーケンスがモデルのセパレータートークンによって区切られる2つの入力であると予想される分類モデルを使用するように設計されたSequenceClassificationExplainerのバリアントです。これの一般的な例は、互いに2つの入力の類似性を獲得するために一般的に使用されるNLIモデルとクロスエンコーダーです。
この説明担当者は、コンストラクターに与えられたモデルとトークネイザーを使用して、2つの渡された入力text1とtext2のペアワイズ属性を計算します。
また、ペアワイズシーケンス分類の一般的なユースケースは、2つの入力の類似性を比較することです。この性質のモデルは、通常、各クラスの複数ではなく単一の出力ノードのみを持っています。ペアワイズシーケンス分類には、単一ノードの出力をより明確にするためのいくつかの有用なユーティリティ関数があります。
デフォルトでは、単一のノードを出力するモデルの場合、属性は1.0に近いスコアをプッシュする入力に対する属性ですが、0.0に近いスコアに関する属性を確認する場合はflip_sign=Trueを渡すことができます。類似性ベースのモデルの場合、これは2つの入力で0.0に近いスコアを予測する可能性があるため、これは有用です。その場合、2つの入力が類似している理由を説明するために、帰属記号をめくります。
まず、文化変換者が提供する事前に訓練されたクロスエンコーダーのスイートからのクロスエンコーダーモデルとトークネイザーを初期化することから始めましょう。
この例では、MSMARCOデータセットで訓練された高品質のクロスエンコーダーである"cross-encoder/ms-marco-MiniLM-L-6-v2"を使用しています。
from transformers import AutoModelForSequenceClassification , AutoTokenizer
from transformers_interpret import PairwiseSequenceClassificationExplainer
model = AutoModelForSequenceClassification . from_pretrained ( "cross-encoder/ms-marco-MiniLM-L-6-v2" )
tokenizer = AutoTokenizer . from_pretrained ( "cross-encoder/ms-marco-MiniLM-L-6-v2" )
pairwise_explainer = PairwiseSequenceClassificationExplainer ( model , tokenizer )
# the pairwise explainer requires two string inputs to be passed, in this case given the nature of the model
# we pass a query string and a context string. The question we are asking of our model is "does this context contain a valid answer to our question"
# the higher the score the better the fit.
query = "How many people live in Berlin?"
context = "Berlin has a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers."
pairwise_attr = pairwise_explainer ( query , context )これは次の帰属を返します。
> >> pairwise_attr
[( '[CLS]' , 0.0 ),
( 'how' , - 0.037558652124213034 ),
( 'many' , - 0.40348581975409786 ),
( 'people' , - 0.29756140282349425 ),
( 'live' , - 0.48979015417391764 ),
( 'in' , - 0.17844527885888117 ),
( 'berlin' , 0.3737346097442739 ),
( '?' , - 0.2281428913480142 ),
( '[SEP]' , 0.0 ),
( 'berlin' , 0.18282430604641564 ),
( 'has' , 0.039114659489254834 ),
( 'a' , 0.0820056652212297 ),
( 'population' , 0.35712150914643026 ),
( 'of' , 0.09680870840224687 ),
( '3' , 0.04791760029513795 ),
( ',' , 0.040330986539774266 ),
( '520' , 0.16307677913176166 ),
( ',' , - 0.005919693904602767 ),
( '03' , 0.019431649515841844 ),
( '##1' , - 0.0243808667024702 ),
( 'registered' , 0.07748341753369632 ),
( 'inhabitants' , 0.23904087299731255 ),
( 'in' , 0.07553221327346359 ),
( 'an' , 0.033112821611999875 ),
( 'area' , - 0.025378852244447532 ),
( 'of' , 0.026526373859562906 ),
( '89' , 0.0030700151809002147 ),
( '##1' , - 0.000410387092186983 ),
( '.' , - 0.0193147139126114 ),
( '82' , 0.0073800833347678774 ),
( 'square' , 0.028988305990861576 ),
( 'kilometers' , 0.02071182933829008 ),
( '.' , - 0.025901070914318036 ),
( '[SEP]' , 0.0 )]ペアワイズの属性を視覚化することは、シーケンス分類の説明と変わりません。 queryとcontext両方で、 berlin言葉には多くの肯定的な帰属があり、 contextにおけるpopulationとinhabitants言葉には多くの肯定的な帰属があることがわかります。
pairwise_explainer . visualize ( "cross_encoder_attr.html" )
この単一ノード出力の正のクラスからモデルを押しのけた入力属性を強調することにもっと興味があれば、渡すことができます。
pairwise_attr = explainer ( query , context , flip_sign = True )これは、単に属性の兆候を反転させ、それらが1ではなく0を出力するモデルに関して確実にすることを保証します。
この説明担当者は、 SequenceClassificationExplainerの拡張であるため、Transformersパッケージのすべてのシーケンス分類モデルと互換性があります。この説明担当者の重要な変更は、モデルの構成内の各ラベルの属性を結合し、各ラベルに単語属性wrtの辞書を返すことです。 visualize()メソッドは、ラベルごとに計算された属性を持つ帰属の表も表示します。
from transformers import AutoModelForSequenceClassification , AutoTokenizer
from transformers_interpret import MultiLabelClassificationExplainer
model_name = "j-hartmann/emotion-english-distilroberta-base"
model = AutoModelForSequenceClassification . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
cls_explainer = MultiLabelClassificationExplainer ( model , tokenizer )
word_attributions = cls_explainer ( "There were many aspects of the film I liked, but it was frightening and gross in parts. My parents hated it." )これにより、各単語とその帰属スコアのタプルのリストにラベルをマッピングするWord属性の辞書が生成されます。
> >> word_attributions
{ 'anger' : [( '<s>' , 0.0 ),
( 'There' , 0.09002208622000409 ),
( 'were' , - 0.025129709879675187 ),
( 'many' , - 0.028852677974079328 ),
( 'aspects' , - 0.06341968013631565 ),
( 'of' , - 0.03587626320752477 ),
( 'the' , - 0.014813095892961287 ),
( 'film' , - 0.14087587475098232 ),
( 'I' , 0.007367876912617766 ),
( 'liked' , - 0.09816592066307557 ),
( ',' , - 0.014259517291745674 ),
( 'but' , - 0.08087144668471376 ),
( 'it' , - 0.10185214349220136 ),
( 'was' , - 0.07132244710777856 ),
( 'frightening' , - 0.4125361737439814 ),
( 'and' , - 0.021761663818889918 ),
( 'gross' , - 0.10423745223600908 ),
( 'in' , - 0.02383646952201854 ),
( 'parts' , - 0.027137622525091033 ),
( '.' , - 0.02960415694062459 ),
( 'My' , 0.05642774605113695 ),
( 'parents' , 0.11146648216326158 ),
( 'hated' , 0.8497975489280364 ),
( 'it' , 0.05358116678115284 ),
( '.' , - 0.013566277162080632 ),
( '' , 0.09293256725788422 ),
( '</s>' , 0.0 )],
'disgust' : [( '<s>' , 0.0 ),
( 'There' , - 0.035296263203072 ),
( 'were' , - 0.010224922196739717 ),
( 'many' , - 0.03747571761725605 ),
( 'aspects' , 0.007696321643436715 ),
( 'of' , 0.0026740873113235107 ),
( 'the' , 0.0025752851265661335 ),
( 'film' , - 0.040890035285783645 ),
( 'I' , - 0.014710007408208579 ),
( 'liked' , 0.025696806663391577 ),
( ',' , - 0.00739107098314569 ),
( 'but' , 0.007353791868893654 ),
( 'it' , - 0.00821368234753605 ),
( 'was' , 0.005439709067819798 ),
( 'frightening' , - 0.8135974168445725 ),
( 'and' , - 0.002334953123414774 ),
( 'gross' , 0.2366024374426269 ),
( 'in' , 0.04314772995234148 ),
( 'parts' , 0.05590472194035334 ),
( '.' , - 0.04362554293972562 ),
( 'My' , - 0.04252694977895808 ),
( 'parents' , 0.051580790911406944 ),
( 'hated' , 0.5067406070057585 ),
( 'it' , 0.0527491071885104 ),
( '.' , - 0.008280280618652273 ),
( '' , 0.07412384603053103 ),
( '</s>' , 0.0 )],
'fear' : [( '<s>' , 0.0 ),
( 'There' , - 0.019615758046045408 ),
( 'were' , 0.008033402634196246 ),
( 'many' , 0.027772367717635423 ),
( 'aspects' , 0.01334130725685673 ),
( 'of' , 0.009186049991879768 ),
( 'the' , 0.005828877177384549 ),
( 'film' , 0.09882910753644959 ),
( 'I' , 0.01753565003544039 ),
( 'liked' , 0.02062597344466885 ),
( ',' , - 0.004469530636560965 ),
( 'but' , - 0.019660439408176984 ),
( 'it' , 0.0488084071292538 ),
( 'was' , 0.03830859527501167 ),
( 'frightening' , 0.9526443954511705 ),
( 'and' , 0.02535156284103706 ),
( 'gross' , - 0.10635301961551227 ),
( 'in' , - 0.019190425328209065 ),
( 'parts' , - 0.01713006453323631 ),
( '.' , 0.015043169035757302 ),
( 'My' , 0.017068079071414916 ),
( 'parents' , - 0.0630781275517486 ),
( 'hated' , - 0.23630028921273583 ),
( 'it' , - 0.056057044429020306 ),
( '.' , 0.0015102052077844612 ),
( '' , - 0.010045048665404609 ),
( '</s>' , 0.0 )],
'joy' : [( '<s>' , 0.0 ),
( 'There' , 0.04881772670614576 ),
( 'were' , - 0.0379316152427468 ),
( 'many' , - 0.007955371089444285 ),
( 'aspects' , 0.04437296429416574 ),
( 'of' , - 0.06407011137335743 ),
( 'the' , - 0.07331568926973099 ),
( 'film' , 0.21588462483311055 ),
( 'I' , 0.04885724513463952 ),
( 'liked' , 0.5309510543276107 ),
( ',' , 0.1339765195225006 ),
( 'but' , 0.09394079060730279 ),
( 'it' , - 0.1462792330432028 ),
( 'was' , - 0.1358591558323458 ),
( 'frightening' , - 0.22184169339341142 ),
( 'and' , - 0.07504142930419291 ),
( 'gross' , - 0.005472075984252812 ),
( 'in' , - 0.0942152657437379 ),
( 'parts' , - 0.19345218754215965 ),
( '.' , 0.11096247277185402 ),
( 'My' , 0.06604512262645984 ),
( 'parents' , 0.026376541098236207 ),
( 'hated' , - 0.4988319510231699 ),
( 'it' , - 0.17532499366236615 ),
( '.' , - 0.022609976138939034 ),
( '' , - 0.43417114685294833 ),
( '</s>' , 0.0 )],
'neutral' : [( '<s>' , 0.0 ),
( 'There' , 0.045984598036642205 ),
( 'were' , 0.017142566357474697 ),
( 'many' , 0.011419348619472542 ),
( 'aspects' , 0.02558593440287365 ),
( 'of' , 0.0186162232003498 ),
( 'the' , 0.015616416841815963 ),
( 'film' , - 0.021190511300570092 ),
( 'I' , - 0.03572427925026324 ),
( 'liked' , 0.027062554960050455 ),
( ',' , 0.02089914209290366 ),
( 'but' , 0.025872618597570115 ),
( 'it' , - 0.002980407262316265 ),
( 'was' , - 0.022218157611174086 ),
( 'frightening' , - 0.2982516449116045 ),
( 'and' , - 0.01604643529040792 ),
( 'gross' , - 0.04573829263548096 ),
( 'in' , - 0.006511536166676108 ),
( 'parts' , - 0.011744224307968652 ),
( '.' , - 0.01817041167875332 ),
( 'My' , - 0.07362312722231429 ),
( 'parents' , - 0.06910711601816408 ),
( 'hated' , - 0.9418903509267312 ),
( 'it' , 0.022201795222373488 ),
( '.' , 0.025694319747309045 ),
( '' , 0.04276690822325994 ),
( '</s>' , 0.0 )],
'sadness' : [( '<s>' , 0.0 ),
( 'There' , 0.028237893283377526 ),
( 'were' , - 0.04489910545229568 ),
( 'many' , 0.004996044977269471 ),
( 'aspects' , - 0.1231292680125582 ),
( 'of' , - 0.04552690725956671 ),
( 'the' , - 0.022077819961347042 ),
( 'film' , - 0.14155752357877663 ),
( 'I' , 0.04135347872193571 ),
( 'liked' , - 0.3097732540526099 ),
( ',' , 0.045114660009053134 ),
( 'but' , 0.0963352125332619 ),
( 'it' , - 0.08120617610094617 ),
( 'was' , - 0.08516150809170213 ),
( 'frightening' , - 0.10386889639962761 ),
( 'and' , - 0.03931986389970189 ),
( 'gross' , - 0.2145059013625132 ),
( 'in' , - 0.03465423285571697 ),
( 'parts' , - 0.08676627134611635 ),
( '.' , 0.19025217371906333 ),
( 'My' , 0.2582092561303794 ),
( 'parents' , 0.15432351476960307 ),
( 'hated' , 0.7262186310977987 ),
( 'it' , - 0.029160655114499095 ),
( '.' , - 0.002758524253450406 ),
( '' , - 0.33846410359182094 ),
( '</s>' , 0.0 )],
'surprise' : [( '<s>' , 0.0 ),
( 'There' , 0.07196110795254315 ),
( 'were' , 0.1434314520711312 ),
( 'many' , 0.08812238369489701 ),
( 'aspects' , 0.013432396769890982 ),
( 'of' , - 0.07127508805657243 ),
( 'the' , - 0.14079766624810955 ),
( 'film' , - 0.16881201614906485 ),
( 'I' , 0.040595668935112135 ),
( 'liked' , 0.03239855530171577 ),
( ',' , - 0.17676382558158257 ),
( 'but' , - 0.03797939330341559 ),
( 'it' , - 0.029191325089641736 ),
( 'was' , 0.01758013584108571 ),
( 'frightening' , - 0.221738963726823 ),
( 'and' , - 0.05126920277135527 ),
( 'gross' , - 0.33986913466614044 ),
( 'in' , - 0.018180366628697 ),
( 'parts' , 0.02939418603252064 ),
( '.' , 0.018080129971003226 ),
( 'My' , - 0.08060162218059498 ),
( 'parents' , 0.04351719139081836 ),
( 'hated' , - 0.6919028585285265 ),
( 'it' , 0.0009574844165327357 ),
( '.' , - 0.059473118237873344 ),
( '' , - 0.465690452620123 ),
( '</s>' , 0.0 )]}特に多くのテキストがある場合には、数値の属性を読むのが難しい場合があります。それを支援するために、ビルドVizライブラリのCaptumを使用して、属性を強調するHTMLファイルを作成するvisualize()メソッドも提供します。このために、説明の属性は各ラベルにWRTを表示します。
ノートブックに載っている場合、 visualize()メソッドへの呼び出しは視覚化を内側に表示します。または、引数としてFilepathを渡すことができ、HTMLファイルが作成され、ブラウザで説明HTMLを表示できます。
cls_explainer . visualize ( "multilabel_viz.html" )
この説明を使用したモデルは、以前にNLI分類下流タスクでトレーニングされ、モデルの構成に「巻き込み」または「巻き込み」と呼ばれるラベルを持っている必要があります。
この説明担当者は、モデルなどのゼロショット分類のために属性を計算できます。これを達成するために、顔を抱き締めることで採用された同じ方法論を使用します。顔を抱きしめてゼロショット分類を達成することで採用されている馴染みのない方法では、NLIモデルの「含意」ラベルを活用することによるものです。以下は、それについてもっと説明する論文へのリンクです。この説明者と互換性があることが保証されているNLIモデルのリストは、モデルハブにあります。
まず、変圧器のシーケンス分類モデルを初期化し、NLIタスクで訓練されたトークン剤をZeroshotClassificationExplainerに渡すことから始めましょう。
この例では、SNLIおよびNLIデータセットデータセットでトレーニングされたDeBertaベースモデルのチェックポイントであるcross-encoder/nli-deberta-base使用しています。このモデルは通常、文のペアが誘惑、中立、または矛盾であるかどうかを予測しますが、ゼロショットの場合、誘惑ラベルのみに見えます。
クラスインスタンスに独自のカスタムラベル["finance", "technology", "sports"]渡すことに注意してください。わずか1つのラベルを含めて、任意の数のラベルを渡すことができます。どちらのラベルスコアがpredicted_labelで最も高いスコアにアクセスできますか?特定のラベルの属性を確認したい場合は、その1つのラベルを渡すためだけに推奨され、その属性がそのラベルを計算することが保証されます。
from transformers import AutoModelForSequenceClassification , AutoTokenizer
from transformers_interpret import ZeroShotClassificationExplainer
tokenizer = AutoTokenizer . from_pretrained ( "cross-encoder/nli-deberta-base" )
model = AutoModelForSequenceClassification . from_pretrained ( "cross-encoder/nli-deberta-base" )
zero_shot_explainer = ZeroShotClassificationExplainer ( model , tokenizer )
word_attributions = zero_shot_explainer (
"Today apple released the new Macbook showing off a range of new features found in the proprietary silicon chip computer. " ,
labels = [ "finance" , "technology" , "sports" ],
)これは、各ラベルの次の帰属タプルリストを返します。
> >> word_attributions
{ 'finance' : [( '[CLS]' , 0.0 ),
( 'Today' , 0.144761198095125 ),
( 'apple' , 0.05008283286211926 ),
( 'released' , - 0.29790757134109724 ),
( 'the' , - 0.09931162582050683 ),
( 'new' , - 0.151252730475885 ),
( 'Mac' , 0.19431968978659608 ),
( 'book' , 0.059431761386793486 ),
( 'showing' , - 0.30754747734942633 ),
( 'off' , 0.0329034397830471 ),
( 'a' , 0.04198035048519715 ),
( 'range' , - 0.00413947940202566 ),
( 'of' , 0.7135069733740484 ),
( 'new' , 0.2294990755900286 ),
( 'features' , - 0.1523457769188503 ),
( 'found' , - 0.016804346228170633 ),
( 'in' , 0.1185751939327566 ),
( 'the' , - 0.06990875734316043 ),
( 'proprietary' , 0.16339657649559983 ),
( 'silicon' , 0.20461302470245252 ),
( 'chip' , 0.033304742383885574 ),
( 'computer' , - 0.058821677910955064 ),
( '.' , - 0.19741292299059068 )],
'technology' : [( '[CLS]' , 0.0 ),
( 'Today' , 0.1261355373492264 ),
( 'apple' , - 0.06735584800073911 ),
( 'released' , - 0.37758515332894504 ),
( 'the' , - 0.16300368060788886 ),
( 'new' , - 0.1698884472100767 ),
( 'Mac' , 0.41505959302727347 ),
( 'book' , 0.321276307285395 ),
( 'showing' , - 0.2765988420377037 ),
( 'off' , 0.19388699112601515 ),
( 'a' , - 0.044676708673846766 ),
( 'range' , 0.05333370699507288 ),
( 'of' , 0.3654053610507722 ),
( 'new' , 0.3143976769670845 ),
( 'features' , 0.2108588137592185 ),
( 'found' , 0.004676960337191403 ),
( 'in' , 0.008026783104605233 ),
( 'the' , - 0.09961358108721637 ),
( 'proprietary' , 0.18816708356062326 ),
( 'silicon' , 0.13322691438800874 ),
( 'chip' , 0.015141805082331294 ),
( 'computer' , - 0.1321895049108681 ),
( '.' , - 0.17152401596638975 )],
'sports' : [( '[CLS]' , 0.0 ),
( 'Today' , 0.11751821789941418 ),
( 'apple' , - 0.024552367058659215 ),
( 'released' , - 0.44706064525430567 ),
( 'the' , - 0.10163968191086448 ),
( 'new' , - 0.18590036257614642 ),
( 'Mac' , 0.0021649499897370725 ),
( 'book' , 0.009141161101058446 ),
( 'showing' , - 0.3073791152936541 ),
( 'off' , 0.0711051596941137 ),
( 'a' , 0.04153236257439005 ),
( 'range' , 0.01598478741712663 ),
( 'of' , 0.6632118834641558 ),
( 'new' , 0.2684728052423898 ),
( 'features' , - 0.10249856013919137 ),
( 'found' , - 0.032459999377294144 ),
( 'in' , 0.11078761617308391 ),
( 'the' , - 0.020530085754695244 ),
( 'proprietary' , 0.17968209761431955 ),
( 'silicon' , 0.19997909769476027 ),
( 'chip' , 0.04447720580439545 ),
( 'computer' , 0.018515748463790047 ),
( '.' , - 0.1686603393466192 )]}どのラベルが予測されたかを知ることができます:
> >> zero_shot_explainer . predicted_label
'technology' ZeroShotClassificationExplainerの場合、Visualize()メソッドは、 SequenceClassificationExplainerと同様のテーブルを返しますが、すべてのラベルの属性があります。
zero_shot_explainer . visualize ( "zero_shot.html" )
Transformersの質問回答モデルとトークンザーを初期化し、 QuestionAnsweringExplainerを実行することから始めましょう。
この例ではbert-large-uncased-whole-word-masking-finetuned-squadを使用しています。
from transformers import AutoModelForQuestionAnswering , AutoTokenizer
from transformers_interpret import QuestionAnsweringExplainer
tokenizer = AutoTokenizer . from_pretrained ( "bert-large-uncased-whole-word-masking-finetuned-squad" )
model = AutoModelForQuestionAnswering . from_pretrained ( "bert-large-uncased-whole-word-masking-finetuned-squad" )
qa_explainer = QuestionAnsweringExplainer (
model ,
tokenizer ,
)
context = """
In Artificial Intelligence and machine learning, Natural Language Processing relates to the usage of machines to process and understand human language.
Many researchers currently work in this space.
"""
word_attributions = qa_explainer (
"What is natural language processing ?" ,
context ,
)これにより、回答の予測された開始位置と終了位置の両方に対して、次のDictを含む単語の属性を返します。
> >> word_attributions
{ 'start' : [( '[CLS]' , 0.0 ),
( 'what' , 0.9177170660377296 ),
( 'is' , 0.13382234898765258 ),
( 'natural' , 0.08061747350142005 ),
( 'language' , 0.013138062762511409 ),
( 'processing' , 0.11135923869816286 ),
( '?' , 0.00858057388924361 ),
( '[SEP]' , - 0.09646373141894966 ),
( 'in' , 0.01545633993975799 ),
( 'artificial' , 0.0472082598707737 ),
( 'intelligence' , 0.026687249355110867 ),
( 'and' , 0.01675371260058537 ),
( 'machine' , - 0.08429502436554961 ),
( 'learning' , 0.0044827685126163355 ),
( ',' , - 0.02401013152520878 ),
( 'natural' , - 0.0016756080249823537 ),
( 'language' , 0.0026815068421401885 ),
( 'processing' , 0.06773157580722854 ),
( 'relates' , 0.03884601576992908 ),
( 'to' , 0.009783797821526368 ),
( 'the' , - 0.026650922910540952 ),
( 'usage' , - 0.010675019721821147 ),
( 'of' , 0.015346787885898537 ),
( 'machines' , - 0.08278008270160107 ),
( 'to' , 0.12861387892768839 ),
( 'process' , 0.19540146386642743 ),
( 'and' , 0.009942879959615826 ),
( 'understand' , 0.006836894853320319 ),
( 'human' , 0.05020451122579102 ),
( 'language' , - 0.012980795199301 ),
( '.' , 0.00804358248127772 ),
( 'many' , 0.02259009321498161 ),
( 'researchers' , - 0.02351650942555469 ),
( 'currently' , 0.04484573078852946 ),
( 'work' , 0.00990399948294476 ),
( 'in' , 0.01806961211334615 ),
( 'this' , 0.13075899776164499 ),
( 'space' , 0.004298315347838973 ),
( '.' , - 0.003767904539347979 ),
( '[SEP]' , - 0.08891544093454595 )],
'end' : [( '[CLS]' , 0.0 ),
( 'what' , 0.8227231947501547 ),
( 'is' , 0.0586864942952253 ),
( 'natural' , 0.0938903563379123 ),
( 'language' , 0.058596976016400674 ),
( 'processing' , 0.1632374290269829 ),
( '?' , 0.09695686057123237 ),
( '[SEP]' , - 0.11644447033554006 ),
( 'in' , - 0.03769172371919206 ),
( 'artificial' , 0.06736158404049886 ),
( 'intelligence' , 0.02496399001288386 ),
( 'and' , - 0.03526028847762427 ),
( 'machine' , - 0.20846431491771975 ),
( 'learning' , 0.00904892847529654 ),
( ',' , - 0.02949905488474854 ),
( 'natural' , 0.011024507784743872 ),
( 'language' , 0.0870741751282507 ),
( 'processing' , 0.11482449622317169 ),
( 'relates' , 0.05008962090922852 ),
( 'to' , 0.04079118393166258 ),
( 'the' , - 0.005069048880616451 ),
( 'usage' , - 0.011992752445836278 ),
( 'of' , 0.01715183316135495 ),
( 'machines' , - 0.29823535624026265 ),
( 'to' , - 0.0043760160855057925 ),
( 'process' , 0.10503217484645223 ),
( 'and' , 0.06840313586976698 ),
( 'understand' , 0.057184000619403944 ),
( 'human' , 0.0976805947708315 ),
( 'language' , 0.07031163646606695 ),
( '.' , 0.10494566513897102 ),
( 'many' , 0.019227154676079487 ),
( 'researchers' , - 0.038173913797800885 ),
( 'currently' , 0.03916641120002003 ),
( 'work' , 0.03705371672439422 ),
( 'in' , - 0.0003155975107591203 ),
( 'this' , 0.17254932354022232 ),
( 'space' , 0.0014311439625599323 ),
( '.' , 0.060637932829867736 ),
( '[SEP]' , - 0.09186286505530596 )]}予測された答えのテキストスパンを取得できます。
> >> qa_explainer . predicted_answer
'usage of machines to process and understand human language' QuestionAnsweringExplainerの場合、Visualize()メソッドは2行のテーブルを返します。最初の行は、回答の開始位置の帰属を表し、2番目の行は回答のエンド位置の属性を表します。
qa_explainer . visualize ( "bert_qa_viz.html" )
これは現在、アクティブな開発中の実験的説明者であり、まだ完全にテストされていません。説明担当者のAPIは、帰属方法と同様に変更される場合があります。バグが見つかった場合はお知らせください。
Transformersのトークンクラスフィケーションモデルとトークンザーを初期化し、 TokenClassificationExplainerを実行することから始めましょう。
この例では、 dslim/bert-base-NERを使用しています。これは、conll-2003という名前のエンティティ認識データセットで微調整されたBertモデルです。
from transformers import AutoModelForTokenClassification , AutoTokenizer
from transformers_interpret import TokenClassificationExplainer
model = AutoModelForTokenClassification . from_pretrained ( 'dslim/bert-base-NER' )
tokenizer = AutoTokenizer . from_pretrained ( 'dslim/bert-base-NER' )
ner_explainer = TokenClassificationExplainer (
model ,
tokenizer ,
)
sample_text = "We visited Paris last weekend, where Emmanuel Macron lives."
word_attributions = ner_explainer ( sample_text , ignored_labels = [ 'O' ])計算される属性の数を減らすために、予測されたラベルが'O'であるトークンを無視するように説明者に指示します。また、パラメーターignored_indexes _indexesの引数としてリストを提供する特定のインデックスを無視するように説明者に伝えることもできます。
これは、「O」として予測されたものを除き、予測されたラベルと各トークンの属性を含む次のdictを返します。
> >> word_attributions
{ 'paris' : { 'label' : 'B-LOC' ,
'attribution_scores' : [( '[CLS]' , 0.0 ),
( 'we' , - 0.014352325471387907 ),
( 'visited' , 0.32915222186559123 ),
( 'paris' , 0.9086791784795596 ),
( 'last' , 0.15181203147624034 ),
( 'weekend' , 0.14400210630677038 ),
( ',' , 0.01899744327012935 ),
( 'where' , - 0.039402005463239465 ),
( 'emmanuel' , 0.061095284002642025 ),
( 'macro' , 0.004192922551105228 ),
( '##n' , 0.09446355513057757 ),
( 'lives' , - 0.028724312616455003 ),
( '.' , 0.08099007392937585 ),
( '[SEP]' , 0.0 )]},
'emmanuel' : { 'label' : 'B-PER' ,
'attribution_scores' : [( '[CLS]' , 0.0 ),
( 'we' , - 0.006933030636686712 ),
( 'visited' , 0.10396962390436904 ),
( 'paris' , 0.14540758744233165 ),
( 'last' , 0.08024018944451371 ),
( 'weekend' , 0.10687970996804418 ),
( ',' , 0.1793198466387937 ),
( 'where' , 0.3436407835483767 ),
( 'emmanuel' , 0.8774892642652167 ),
( 'macro' , 0.03559399361048316 ),
( '##n' , 0.1516315604785551 ),
( 'lives' , 0.07056441327498127 ),
( '.' , - 0.025820924624605487 ),
( '[SEP]' , 0.0 )]},
'macro' : { 'label' : 'I-PER' ,
'attribution_scores' : [( '[CLS]' , 0.0 ),
( 'we' , 0.05578067326280157 ),
( 'visited' , 0.00857021283406586 ),
( 'paris' , 0.16559056506114297 ),
( 'last' , 0.08285256685903823 ),
( 'weekend' , 0.10468727443796395 ),
( ',' , 0.09949509071515888 ),
( 'where' , 0.3642458274356929 ),
( 'emmanuel' , 0.7449335213978788 ),
( 'macro' , 0.3794625659183485 ),
( '##n' , - 0.2599031433800762 ),
( 'lives' , 0.20563450682196147 ),
( '.' , - 0.015607017319486929 ),
( '[SEP]' , 0.0 )]},
'##n' : { 'label' : 'I-PER' ,
'attribution_scores' : [( '[CLS]' , 0.0 ),
( 'we' , 0.025194121717285252 ),
( 'visited' , - 0.007415022865239864 ),
( 'paris' , 0.09478357303107598 ),
( 'last' , 0.06927939834474463 ),
( 'weekend' , 0.0672008033510708 ),
( ',' , 0.08316907214363504 ),
( 'where' , 0.3784915854680165 ),
( 'emmanuel' , 0.7729352621546081 ),
( 'macro' , 0.4148652759139777 ),
( '##n' , - 0.20853534512145033 ),
( 'lives' , 0.09445057087678274 ),
( '.' , - 0.094274985907366 ),
( '[SEP]' , 0.0 )]},
'[SEP]' : { 'label' : 'B-LOC' ,
'attribution_scores' : [( '[CLS]' , 0.0 ),
( 'we' , - 0.3694351403796742 ),
( 'visited' , 0.1699038407402483 ),
( 'paris' , 0.5461587414992369 ),
( 'last' , 0.0037948102770307517 ),
( 'weekend' , 0.1628100955702496 ),
( ',' , 0.4513093410909263 ),
( 'where' , - 0.09577409464161038 ),
( 'emmanuel' , 0.48499459835388914 ),
( 'macro' , - 0.13528905587653023 ),
( '##n' , 0.14362969934754344 ),
( 'lives' , - 0.05758007024257254 ),
( '.' , - 0.13970977266152554 ),
( '[SEP]' , 0.0 )]}}TokenClassificationExplainerの場合、Visualize()メソッドは、トークンと同じ数の行でテーブルを返します。
ner_explainer . visualize ( "bert_ner_viz.html" )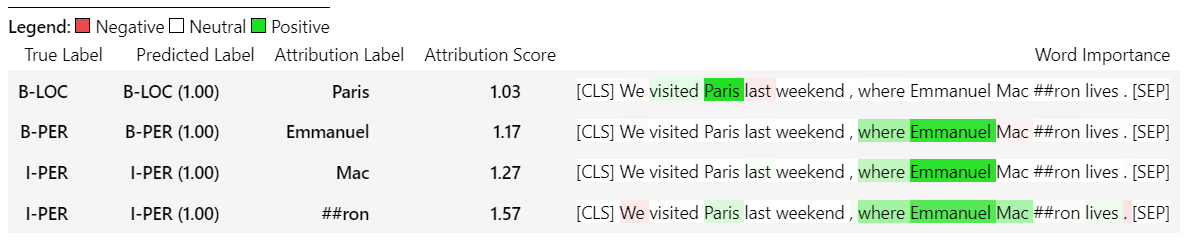
TokenClassificationExplainer仕組みの詳細については、ノートブックノートブック/ner_example.ipynbを確認できます。
ImageClassificationExplainerは、画像分類(SWIN、VITなど)のためにトレーニングされているTransformersライブラリのすべてのモデルと連携するように設計されています。その画像内のすべてのピクセルの属性を提供します。これは、 visualizeメソッドに組み込まれている説明者を使用して簡単に視覚化できます。
画像の分類の初期化は非常にシンプルです。必要なのは、ハッグフェイスとその機能抽出器を使用するために、画像分類モデルがFinetunedまたは訓練されたものです。
この例では、1000の可能なクラスから予測するImagenet-21Kで事前に訓練されたVision Transformer(VIT)モデルであるgoogle/vit-base-patch16-224を使用しています。
from transformers import AutoFeatureExtractor , AutoModelForImageClassification
from transformers_interpret import ImageClassificationExplainer
from PIL import Image
import requests
model_name = "google/vit-base-patch16-224"
model = AutoModelForImageClassification . from_pretrained ( model_name )
feature_extractor = AutoFeatureExtractor . from_pretrained ( model_name )
# With both the model and feature extractor initialized we are now able to get explanations on an image, we will use a simple image of a golden retriever.
image_link = "https://imagesvc.meredithcorp.io/v3/mm/image?url=https%3A%2F%2Fstatic.onecms.io%2Fwp-content%2Fuploads%2Fsites%2F47%2F2020%2F08%2F16%2Fgolden-retriever-177213599-2000.jpg"
image = Image . open ( requests . get ( image_link , stream = True ). raw )
image_classification_explainer = ImageClassificationExplainer ( model = model , feature_extractor = feature_extractor )
image_attributions = image_classification_explainer (
image
)
print ( image_attributions . shape )これは、次のタプルのリストを返します。
> >> torch . Size ([ 1 , 3 , 224 , 224 ])画像を扱っているため、視覚化はテキストモデルよりもさらに簡単です。
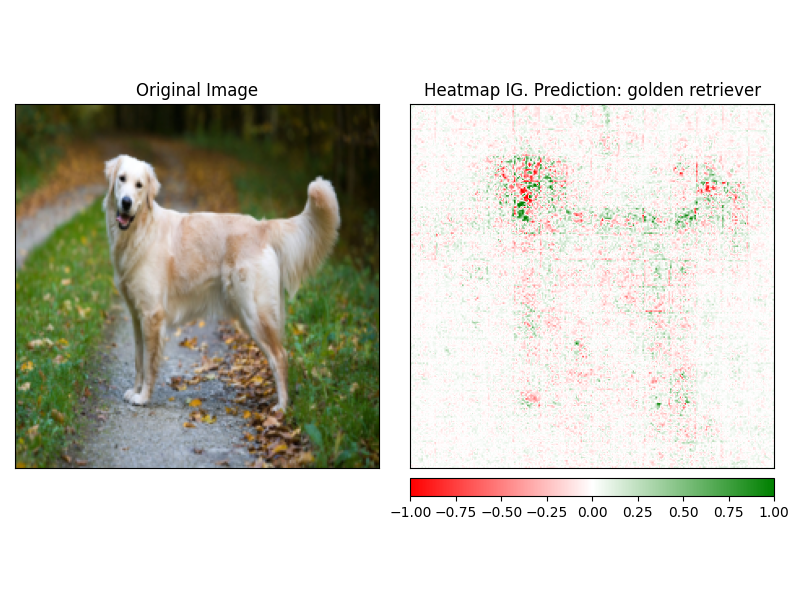
魅力は、説明者のvisualize方法を使用して簡単に視覚化できます。現在、4つのサポートされている視覚化方法があります。
heatmap - 正と否定的な帰属のヒートマップは、画像の寸法を使用して描かれます。overlay - ヒートマップは、元の画像のグレースケールバージョンでオーバーレイされていますmasked_image魅力の絶対値は、元の画像上にマスクを作成するために使用されますalpha_scaling各ピクセルのアルファチャネル(透明性)を正規化された属性値に等しく設定します。 image_classification_explainer . visualize (
method = "heatmap" ,
side_by_side = True ,
outlier_threshold = 0.03
)
image_classification_explainer . visualize (
method = "overlay" ,
side_by_side = True ,
outlier_threshold = 0.03
)
image_classification_explainer . visualize (
method = "masked_image" ,
side_by_side = True ,
outlier_threshold = 0.03
)
image_classification_explainer . visualize (
method = "alpha_scaling" ,
side_by_side = True ,
outlier_threshold = 0.03
)
このパッケージはまだアクティブな開発中であり、さらに計画されています。 1.0.0リリースの場合、私たちは次のことを目指しています。
貢献をしたい場合は、貢献ガイドラインをチェックアウトしてください
このリポジトリのメンテナーは@cdpierseです。
ご質問、提案、または貢献したい場合(してください?)、[email protected]にご連絡ください
また、モデルの説明可能性と解釈可能性が興味深いと思う場合は、Captumをチェックすることを強くお勧めします。
このパッケージは、Pytorch CaptumとHugging Faceのチームによって行われている信じられないほどの仕事の肩に立っており、それぞれMLとモデルの解釈可能性のフィールドで行っている驚くべき仕事のためではないにしても存在しません。
このパッケージ内のすべての属性は、Pytorchの説明可能性パッケージのcaptumを使用して計算されます。 Captumに関連するいくつかの有用なリンクについては、以下を参照してください。
統合された勾配(IG)とITレイヤー統合勾配(LIG)のバリエーションは、変圧器の解釈が現在構築されているコア属性法です。以下は、元の論文や、内側のメカニズムを説明するいくつかのビデオリンクを含むいくつかの有用なリソースです。トランスフォーマーの内部で何が起こっているのか興味がある場合は、これらのリソースの少なくとも1つをチェックすることを強くお勧めします。
Captumリンク
以下は、Captumを使用してこのパッケージをまとめるのに役立つリンクです。 @DavideFioccoにご洞察力のある要点をありがとう。


