transformers interpret
v0.10.0
Transformers Interpreters adalah alat penjelasan model yang dirancang untuk bekerja secara eksklusif dengan? Paket Transformers.
Sejalan dengan filosofi Paket Transformers Transformers Interpreters memungkinkan setiap model Transformers untuk dijelaskan hanya dalam dua baris. Penjelajah tersedia untuk model visi teks dan komputer. Visualisasi juga tersedia di buku catatan dan sebagai file PNG dan HTML yang dapat disimpan.
Lihat aplikasi demo streamlit di sini
pip install transformers - interpretMari kita mulai dengan menginisialisasi model dan tokenizer Transformers, dan menjalankannya melalui `SequenceClasificificationExplainer`.
Untuk contoh ini kami menggunakan distilbert-base-uncased-finetuned-sst-2-english , model distilbert finetuned pada tugas analisis sentimen.
from transformers import AutoModelForSequenceClassification , AutoTokenizer
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
# With both the model and tokenizer initialized we are now able to get explanations on an example text.
from transformers_interpret import SequenceClassificationExplainer
cls_explainer = SequenceClassificationExplainer (
model ,
tokenizer )
word_attributions = cls_explainer ( "I love you, I like you" )Yang akan mengembalikan daftar tupel berikut:
> >> word_attributions
[( '[CLS]' , 0.0 ),
( 'i' , 0.2778544699186709 ),
( 'love' , 0.7792370723380415 ),
( 'you' , 0.38560088858031094 ),
( ',' , - 0.01769750505546915 ),
( 'i' , 0.12071898121557832 ),
( 'like' , 0.19091105304734457 ),
( 'you' , 0.33994871536713467 ),
( '[SEP]' , 0.0 )]Angka atribusi positif menunjukkan sebuah kata berkontribusi positif terhadap kelas yang diprediksi, sementara angka negatif menunjukkan kata berkontribusi negatif terhadap kelas yang diprediksi. Di sini kita dapat melihat bahwa aku mencintaimu mendapatkan perhatian paling besar.
Anda dapat menggunakan predicted_class_index jika Anda ingin tahu apa sebenarnya kelas yang diprediksi:
> >> cls_explainer . predicted_class_index
array ( 1 ) Dan jika model memiliki nama label untuk setiap kelas, kita dapat melihat ini juga menggunakan predicted_class_name :
> >> cls_explainer . predicted_class_name
'POSITIVE' Terkadang atribusi numerik bisa sulit dibaca terutama dalam kasus di mana ada banyak teks. Untuk membantu dengan itu, kami juga menyediakan metode visualize() yang memanfaatkan perpustakaan Captum yang dibangun untuk membuat file HTML yang menyoroti atribusi.
Jika Anda berada di buku catatan, panggilan ke metode visualize() akan menampilkan visualisasi in-line. Sebagai alternatif, Anda dapat meneruskan filepath sebagai argumen dan file HTML akan dibuat, memungkinkan Anda untuk melihat penjelasan HTML di browser Anda.
cls_explainer . visualize ( "distilbert_viz.html" )
Penjelasan atribusi tidak terbatas pada kelas yang diprediksi. Mari kita uji kalimat yang lebih kompleks yang berisi sentimen campuran.
Dalam contoh di bawah ini kita lulus class_name="NEGATIVE" sebagai argumen yang menunjukkan kita ingin atribusi dijelaskan untuk kelas negatif terlepas dari apa prediksi aktual itu. Secara efektif karena ini adalah classifier biner, kami mendapatkan atribusi terbalik.
cls_explainer = SequenceClassificationExplainer ( model , tokenizer )
attributions = cls_explainer ( "I love you, I like you, I also kinda dislike you" , class_name = "NEGATIVE" ) Dalam hal ini, predicted_class_name masih mengembalikan prediksi kelas positif , karena model tersebut telah menghasilkan prediksi yang sama tetapi tetap saja kami tertarik untuk melihat atribusi untuk kelas negatif terlepas dari hasil yang diprediksi.
> >> cls_explainer . predicted_class_name
'POSITIVE'Tetapi ketika kita memvisualisasikan atribusi, kita dapat melihat bahwa kata -kata " ... agak tidak suka " berkontribusi pada prediksi kelas "negatif".
cls_explainer . visualize ( "distilbert_negative_attr.html" )
Mendapatkan atribusi untuk kelas yang berbeda sangat berwawasan untuk masalah multiclass karena memungkinkan Anda untuk memeriksa prediksi model untuk sejumlah kelas yang berbeda dan memeriksa kewarasan bahwa model ini "melihat" hal yang benar.
Untuk penjelasan terperinci tentang contoh ini, silakan checkout notebook klasifikasi multiklas ini.
PairwiseSequenceClassificationExplainer adalah varian dari SequenceClassificationExplainer yang dirancang untuk bekerja dengan model klasifikasi yang mengharapkan urutan input menjadi dua input yang dipisahkan oleh token pemisah model. Contoh umum dari ini adalah model NLI dan cross-encoder yang biasanya digunakan untuk mencetak dua input kesamaan satu sama lain.
Penjelasan ini menghitung atribusi berpasangan untuk dua input yang dilewati text1 dan text2 menggunakan model dan tokenizer yang diberikan dalam konstruktor.
Juga, karena kasus penggunaan umum untuk klasifikasi urutan berpasangan adalah untuk membandingkan dua input kesamaan - model sifat ini biasanya hanya memiliki node output tunggal daripada beberapa untuk setiap kelas. Klasifikasi urutan berpasangan memiliki beberapa fungsi utilitas yang berguna untuk membuat menafsirkan output simpul tunggal lebih jelas.
Secara default untuk model yang mengeluarkan satu node, atribusi adalah sehubungan dengan input yang mendorong skor lebih dekat ke 1,0, namun jika Anda ingin melihat atribusi sehubungan dengan skor lebih dekat ke 0,0 Anda dapat melewati flip_sign=True . Untuk model berbasis kesamaan ini berguna, karena model mungkin memprediksi skor lebih dekat ke 0,0 untuk dua input dan dalam hal ini kami akan membalik tanda atribusi untuk menjelaskan mengapa kedua input tersebut berbeda.
Mari kita mulai dengan menginisialisasi model cross-encoder dan tokenizer dari rangkaian cross-encoder pra-terlatih yang disediakan oleh kalimat-transformer.
Untuk contoh ini kami menggunakan "cross-encoder/ms-marco-MiniLM-L-6-v2" , cross-encoder berkualitas tinggi yang dilatih pada dataset msmarco Dataset peringkat bagian untuk menjawab pertanyaan dan pemahaman membaca mesin.
from transformers import AutoModelForSequenceClassification , AutoTokenizer
from transformers_interpret import PairwiseSequenceClassificationExplainer
model = AutoModelForSequenceClassification . from_pretrained ( "cross-encoder/ms-marco-MiniLM-L-6-v2" )
tokenizer = AutoTokenizer . from_pretrained ( "cross-encoder/ms-marco-MiniLM-L-6-v2" )
pairwise_explainer = PairwiseSequenceClassificationExplainer ( model , tokenizer )
# the pairwise explainer requires two string inputs to be passed, in this case given the nature of the model
# we pass a query string and a context string. The question we are asking of our model is "does this context contain a valid answer to our question"
# the higher the score the better the fit.
query = "How many people live in Berlin?"
context = "Berlin has a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers."
pairwise_attr = pairwise_explainer ( query , context )Yang mengembalikan atribusi berikut:
> >> pairwise_attr
[( '[CLS]' , 0.0 ),
( 'how' , - 0.037558652124213034 ),
( 'many' , - 0.40348581975409786 ),
( 'people' , - 0.29756140282349425 ),
( 'live' , - 0.48979015417391764 ),
( 'in' , - 0.17844527885888117 ),
( 'berlin' , 0.3737346097442739 ),
( '?' , - 0.2281428913480142 ),
( '[SEP]' , 0.0 ),
( 'berlin' , 0.18282430604641564 ),
( 'has' , 0.039114659489254834 ),
( 'a' , 0.0820056652212297 ),
( 'population' , 0.35712150914643026 ),
( 'of' , 0.09680870840224687 ),
( '3' , 0.04791760029513795 ),
( ',' , 0.040330986539774266 ),
( '520' , 0.16307677913176166 ),
( ',' , - 0.005919693904602767 ),
( '03' , 0.019431649515841844 ),
( '##1' , - 0.0243808667024702 ),
( 'registered' , 0.07748341753369632 ),
( 'inhabitants' , 0.23904087299731255 ),
( 'in' , 0.07553221327346359 ),
( 'an' , 0.033112821611999875 ),
( 'area' , - 0.025378852244447532 ),
( 'of' , 0.026526373859562906 ),
( '89' , 0.0030700151809002147 ),
( '##1' , - 0.000410387092186983 ),
( '.' , - 0.0193147139126114 ),
( '82' , 0.0073800833347678774 ),
( 'square' , 0.028988305990861576 ),
( 'kilometers' , 0.02071182933829008 ),
( '.' , - 0.025901070914318036 ),
( '[SEP]' , 0.0 )] Visualisasi atribusi berpasangan tidak berbeda dengan klasifikasi urutan dijelaskan. Kita dapat melihat bahwa baik dalam query dan context ada banyak atribusi positif untuk kata berlin serta kata -kata population dan inhabitants dalam context , tanda -tanda baik bahwa model kami memahami konteks tekstual dari pertanyaan yang diajukan.
pairwise_explainer . visualize ( "cross_encoder_attr.html" )
Jika kami lebih tertarik untuk menyoroti atribusi input yang mendorong model menjauh dari kelas positif dari output simpul tunggal ini yang dapat kami lewati:
pairwise_attr = explainer ( query , context , flip_sign = True )Ini hanya membalikkan tanda atribusi yang memastikan bahwa mereka sehubungan dengan model output 0 daripada 1.
Penjelasan ini adalah perpanjangan dari SequenceClassificationExplainer dan dengan demikian kompatibel dengan semua model klasifikasi urutan dari paket Transformers. Perubahan kunci dalam penjelasan ini adalah bahwa ia mencaci atribusi untuk setiap label dalam konfigurasi model dan mengembalikan kamus atribusi kata WRT ke setiap label. Metode visualize() juga menampilkan tabel atribusi dengan atribusi yang dihitung per label.
from transformers import AutoModelForSequenceClassification , AutoTokenizer
from transformers_interpret import MultiLabelClassificationExplainer
model_name = "j-hartmann/emotion-english-distilroberta-base"
model = AutoModelForSequenceClassification . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
cls_explainer = MultiLabelClassificationExplainer ( model , tokenizer )
word_attributions = cls_explainer ( "There were many aspects of the film I liked, but it was frightening and gross in parts. My parents hated it." )Ini menghasilkan kamus label pemetaan atribusi kata ke daftar tupel untuk setiap kata dan skor atribusi.
> >> word_attributions
{ 'anger' : [( '<s>' , 0.0 ),
( 'There' , 0.09002208622000409 ),
( 'were' , - 0.025129709879675187 ),
( 'many' , - 0.028852677974079328 ),
( 'aspects' , - 0.06341968013631565 ),
( 'of' , - 0.03587626320752477 ),
( 'the' , - 0.014813095892961287 ),
( 'film' , - 0.14087587475098232 ),
( 'I' , 0.007367876912617766 ),
( 'liked' , - 0.09816592066307557 ),
( ',' , - 0.014259517291745674 ),
( 'but' , - 0.08087144668471376 ),
( 'it' , - 0.10185214349220136 ),
( 'was' , - 0.07132244710777856 ),
( 'frightening' , - 0.4125361737439814 ),
( 'and' , - 0.021761663818889918 ),
( 'gross' , - 0.10423745223600908 ),
( 'in' , - 0.02383646952201854 ),
( 'parts' , - 0.027137622525091033 ),
( '.' , - 0.02960415694062459 ),
( 'My' , 0.05642774605113695 ),
( 'parents' , 0.11146648216326158 ),
( 'hated' , 0.8497975489280364 ),
( 'it' , 0.05358116678115284 ),
( '.' , - 0.013566277162080632 ),
( '' , 0.09293256725788422 ),
( '</s>' , 0.0 )],
'disgust' : [( '<s>' , 0.0 ),
( 'There' , - 0.035296263203072 ),
( 'were' , - 0.010224922196739717 ),
( 'many' , - 0.03747571761725605 ),
( 'aspects' , 0.007696321643436715 ),
( 'of' , 0.0026740873113235107 ),
( 'the' , 0.0025752851265661335 ),
( 'film' , - 0.040890035285783645 ),
( 'I' , - 0.014710007408208579 ),
( 'liked' , 0.025696806663391577 ),
( ',' , - 0.00739107098314569 ),
( 'but' , 0.007353791868893654 ),
( 'it' , - 0.00821368234753605 ),
( 'was' , 0.005439709067819798 ),
( 'frightening' , - 0.8135974168445725 ),
( 'and' , - 0.002334953123414774 ),
( 'gross' , 0.2366024374426269 ),
( 'in' , 0.04314772995234148 ),
( 'parts' , 0.05590472194035334 ),
( '.' , - 0.04362554293972562 ),
( 'My' , - 0.04252694977895808 ),
( 'parents' , 0.051580790911406944 ),
( 'hated' , 0.5067406070057585 ),
( 'it' , 0.0527491071885104 ),
( '.' , - 0.008280280618652273 ),
( '' , 0.07412384603053103 ),
( '</s>' , 0.0 )],
'fear' : [( '<s>' , 0.0 ),
( 'There' , - 0.019615758046045408 ),
( 'were' , 0.008033402634196246 ),
( 'many' , 0.027772367717635423 ),
( 'aspects' , 0.01334130725685673 ),
( 'of' , 0.009186049991879768 ),
( 'the' , 0.005828877177384549 ),
( 'film' , 0.09882910753644959 ),
( 'I' , 0.01753565003544039 ),
( 'liked' , 0.02062597344466885 ),
( ',' , - 0.004469530636560965 ),
( 'but' , - 0.019660439408176984 ),
( 'it' , 0.0488084071292538 ),
( 'was' , 0.03830859527501167 ),
( 'frightening' , 0.9526443954511705 ),
( 'and' , 0.02535156284103706 ),
( 'gross' , - 0.10635301961551227 ),
( 'in' , - 0.019190425328209065 ),
( 'parts' , - 0.01713006453323631 ),
( '.' , 0.015043169035757302 ),
( 'My' , 0.017068079071414916 ),
( 'parents' , - 0.0630781275517486 ),
( 'hated' , - 0.23630028921273583 ),
( 'it' , - 0.056057044429020306 ),
( '.' , 0.0015102052077844612 ),
( '' , - 0.010045048665404609 ),
( '</s>' , 0.0 )],
'joy' : [( '<s>' , 0.0 ),
( 'There' , 0.04881772670614576 ),
( 'were' , - 0.0379316152427468 ),
( 'many' , - 0.007955371089444285 ),
( 'aspects' , 0.04437296429416574 ),
( 'of' , - 0.06407011137335743 ),
( 'the' , - 0.07331568926973099 ),
( 'film' , 0.21588462483311055 ),
( 'I' , 0.04885724513463952 ),
( 'liked' , 0.5309510543276107 ),
( ',' , 0.1339765195225006 ),
( 'but' , 0.09394079060730279 ),
( 'it' , - 0.1462792330432028 ),
( 'was' , - 0.1358591558323458 ),
( 'frightening' , - 0.22184169339341142 ),
( 'and' , - 0.07504142930419291 ),
( 'gross' , - 0.005472075984252812 ),
( 'in' , - 0.0942152657437379 ),
( 'parts' , - 0.19345218754215965 ),
( '.' , 0.11096247277185402 ),
( 'My' , 0.06604512262645984 ),
( 'parents' , 0.026376541098236207 ),
( 'hated' , - 0.4988319510231699 ),
( 'it' , - 0.17532499366236615 ),
( '.' , - 0.022609976138939034 ),
( '' , - 0.43417114685294833 ),
( '</s>' , 0.0 )],
'neutral' : [( '<s>' , 0.0 ),
( 'There' , 0.045984598036642205 ),
( 'were' , 0.017142566357474697 ),
( 'many' , 0.011419348619472542 ),
( 'aspects' , 0.02558593440287365 ),
( 'of' , 0.0186162232003498 ),
( 'the' , 0.015616416841815963 ),
( 'film' , - 0.021190511300570092 ),
( 'I' , - 0.03572427925026324 ),
( 'liked' , 0.027062554960050455 ),
( ',' , 0.02089914209290366 ),
( 'but' , 0.025872618597570115 ),
( 'it' , - 0.002980407262316265 ),
( 'was' , - 0.022218157611174086 ),
( 'frightening' , - 0.2982516449116045 ),
( 'and' , - 0.01604643529040792 ),
( 'gross' , - 0.04573829263548096 ),
( 'in' , - 0.006511536166676108 ),
( 'parts' , - 0.011744224307968652 ),
( '.' , - 0.01817041167875332 ),
( 'My' , - 0.07362312722231429 ),
( 'parents' , - 0.06910711601816408 ),
( 'hated' , - 0.9418903509267312 ),
( 'it' , 0.022201795222373488 ),
( '.' , 0.025694319747309045 ),
( '' , 0.04276690822325994 ),
( '</s>' , 0.0 )],
'sadness' : [( '<s>' , 0.0 ),
( 'There' , 0.028237893283377526 ),
( 'were' , - 0.04489910545229568 ),
( 'many' , 0.004996044977269471 ),
( 'aspects' , - 0.1231292680125582 ),
( 'of' , - 0.04552690725956671 ),
( 'the' , - 0.022077819961347042 ),
( 'film' , - 0.14155752357877663 ),
( 'I' , 0.04135347872193571 ),
( 'liked' , - 0.3097732540526099 ),
( ',' , 0.045114660009053134 ),
( 'but' , 0.0963352125332619 ),
( 'it' , - 0.08120617610094617 ),
( 'was' , - 0.08516150809170213 ),
( 'frightening' , - 0.10386889639962761 ),
( 'and' , - 0.03931986389970189 ),
( 'gross' , - 0.2145059013625132 ),
( 'in' , - 0.03465423285571697 ),
( 'parts' , - 0.08676627134611635 ),
( '.' , 0.19025217371906333 ),
( 'My' , 0.2582092561303794 ),
( 'parents' , 0.15432351476960307 ),
( 'hated' , 0.7262186310977987 ),
( 'it' , - 0.029160655114499095 ),
( '.' , - 0.002758524253450406 ),
( '' , - 0.33846410359182094 ),
( '</s>' , 0.0 )],
'surprise' : [( '<s>' , 0.0 ),
( 'There' , 0.07196110795254315 ),
( 'were' , 0.1434314520711312 ),
( 'many' , 0.08812238369489701 ),
( 'aspects' , 0.013432396769890982 ),
( 'of' , - 0.07127508805657243 ),
( 'the' , - 0.14079766624810955 ),
( 'film' , - 0.16881201614906485 ),
( 'I' , 0.040595668935112135 ),
( 'liked' , 0.03239855530171577 ),
( ',' , - 0.17676382558158257 ),
( 'but' , - 0.03797939330341559 ),
( 'it' , - 0.029191325089641736 ),
( 'was' , 0.01758013584108571 ),
( 'frightening' , - 0.221738963726823 ),
( 'and' , - 0.05126920277135527 ),
( 'gross' , - 0.33986913466614044 ),
( 'in' , - 0.018180366628697 ),
( 'parts' , 0.02939418603252064 ),
( '.' , 0.018080129971003226 ),
( 'My' , - 0.08060162218059498 ),
( 'parents' , 0.04351719139081836 ),
( 'hated' , - 0.6919028585285265 ),
( 'it' , 0.0009574844165327357 ),
( '.' , - 0.059473118237873344 ),
( '' , - 0.465690452620123 ),
( '</s>' , 0.0 )]} Terkadang atribusi numerik bisa sulit dibaca terutama dalam kasus di mana ada banyak teks. Untuk membantu dengan itu, kami juga menyediakan metode visualize() yang memanfaatkan perpustakaan Captum yang dibangun untuk membuat file HTML yang menyoroti atribusi. Untuk atribusi penjelasan ini akan ditampilkan WRT untuk setiap label.
Jika Anda berada di buku catatan, panggilan ke metode visualize() akan menampilkan visualisasi in-line. Sebagai alternatif, Anda dapat meneruskan filepath sebagai argumen dan file HTML akan dibuat, memungkinkan Anda untuk melihat penjelasan HTML di browser Anda.
cls_explainer . visualize ( "multilabel_viz.html" )
Model yang menggunakan penjelasan ini sebelumnya harus dilatih sebelumnya pada tugas hilir klasifikasi NLI dan memiliki label di konfigurasi model yang disebut "Enctionment" atau "Entailment".
Penjelajah ini memungkinkan atribusi dihitung untuk klasifikasi nol bidikan seperti model. Untuk mencapai ini, kami menggunakan metodologi yang sama yang digunakan dengan memeluk wajah. Bagi mereka yang tidak akrab dengan metode yang digunakan dengan memeluk wajah untuk mencapai klasifikasi nol tembakan seperti yang bekerja dengan ini dengan mengeksploitasi label "ikut" model NLI. Berikut adalah tautan ke makalah yang menjelaskan lebih banyak tentang itu. Daftar model NLI yang dijamin kompatibel dengan penjelasan ini dapat ditemukan di hub model.
Mari kita mulai dengan menginisialisasi model klasifikasi urutan transformer dan tokenizer yang dilatih secara khusus pada tugas NLI, dan meneruskannya ke ZeroshotClassificationExplainer.
Untuk contoh ini kami menggunakan cross-encoder/nli-deberta-base yang merupakan pos pemeriksaan untuk model deberta-base yang dilatih pada dataset dataset SNLI dan NLI. Model ini biasanya memprediksi apakah pasangan kalimat adalah cair, netral, atau kontradiksi, namun untuk nol-shot kami hanya melihat label yang diperlukan.
Perhatikan bahwa kami melewati label khusus kami sendiri ["finance", "technology", "sports"] ke instance kelas. Sejumlah label dapat dilewati termasuk sesedikit satu. Skor label mana pun yang tertinggi untuk upacara dapat diakses melalui predicted_label , namun atribusi itu sendiri dihitung untuk setiap label. Jika Anda ingin melihat atribusi untuk label tertentu, disarankan hanya untuk meneruskan satu label itu dan kemudian atribusi akan dijamin akan dihitung WRT label itu.
from transformers import AutoModelForSequenceClassification , AutoTokenizer
from transformers_interpret import ZeroShotClassificationExplainer
tokenizer = AutoTokenizer . from_pretrained ( "cross-encoder/nli-deberta-base" )
model = AutoModelForSequenceClassification . from_pretrained ( "cross-encoder/nli-deberta-base" )
zero_shot_explainer = ZeroShotClassificationExplainer ( model , tokenizer )
word_attributions = zero_shot_explainer (
"Today apple released the new Macbook showing off a range of new features found in the proprietary silicon chip computer. " ,
labels = [ "finance" , "technology" , "sports" ],
)Yang akan mengembalikan daftar tuple Dict of Attribution berikut untuk setiap label:
> >> word_attributions
{ 'finance' : [( '[CLS]' , 0.0 ),
( 'Today' , 0.144761198095125 ),
( 'apple' , 0.05008283286211926 ),
( 'released' , - 0.29790757134109724 ),
( 'the' , - 0.09931162582050683 ),
( 'new' , - 0.151252730475885 ),
( 'Mac' , 0.19431968978659608 ),
( 'book' , 0.059431761386793486 ),
( 'showing' , - 0.30754747734942633 ),
( 'off' , 0.0329034397830471 ),
( 'a' , 0.04198035048519715 ),
( 'range' , - 0.00413947940202566 ),
( 'of' , 0.7135069733740484 ),
( 'new' , 0.2294990755900286 ),
( 'features' , - 0.1523457769188503 ),
( 'found' , - 0.016804346228170633 ),
( 'in' , 0.1185751939327566 ),
( 'the' , - 0.06990875734316043 ),
( 'proprietary' , 0.16339657649559983 ),
( 'silicon' , 0.20461302470245252 ),
( 'chip' , 0.033304742383885574 ),
( 'computer' , - 0.058821677910955064 ),
( '.' , - 0.19741292299059068 )],
'technology' : [( '[CLS]' , 0.0 ),
( 'Today' , 0.1261355373492264 ),
( 'apple' , - 0.06735584800073911 ),
( 'released' , - 0.37758515332894504 ),
( 'the' , - 0.16300368060788886 ),
( 'new' , - 0.1698884472100767 ),
( 'Mac' , 0.41505959302727347 ),
( 'book' , 0.321276307285395 ),
( 'showing' , - 0.2765988420377037 ),
( 'off' , 0.19388699112601515 ),
( 'a' , - 0.044676708673846766 ),
( 'range' , 0.05333370699507288 ),
( 'of' , 0.3654053610507722 ),
( 'new' , 0.3143976769670845 ),
( 'features' , 0.2108588137592185 ),
( 'found' , 0.004676960337191403 ),
( 'in' , 0.008026783104605233 ),
( 'the' , - 0.09961358108721637 ),
( 'proprietary' , 0.18816708356062326 ),
( 'silicon' , 0.13322691438800874 ),
( 'chip' , 0.015141805082331294 ),
( 'computer' , - 0.1321895049108681 ),
( '.' , - 0.17152401596638975 )],
'sports' : [( '[CLS]' , 0.0 ),
( 'Today' , 0.11751821789941418 ),
( 'apple' , - 0.024552367058659215 ),
( 'released' , - 0.44706064525430567 ),
( 'the' , - 0.10163968191086448 ),
( 'new' , - 0.18590036257614642 ),
( 'Mac' , 0.0021649499897370725 ),
( 'book' , 0.009141161101058446 ),
( 'showing' , - 0.3073791152936541 ),
( 'off' , 0.0711051596941137 ),
( 'a' , 0.04153236257439005 ),
( 'range' , 0.01598478741712663 ),
( 'of' , 0.6632118834641558 ),
( 'new' , 0.2684728052423898 ),
( 'features' , - 0.10249856013919137 ),
( 'found' , - 0.032459999377294144 ),
( 'in' , 0.11078761617308391 ),
( 'the' , - 0.020530085754695244 ),
( 'proprietary' , 0.17968209761431955 ),
( 'silicon' , 0.19997909769476027 ),
( 'chip' , 0.04447720580439545 ),
( 'computer' , 0.018515748463790047 ),
( '.' , - 0.1686603393466192 )]}Kita dapat mengetahui label mana yang diprediksi dengan:
> >> zero_shot_explainer . predicted_label
'technology' Untuk ZeroShotClassificationExplainer metode visualisasi () mengembalikan tabel yang mirip dengan SequenceClassificationExplainer tetapi dengan atribusi untuk setiap label.
zero_shot_explainer . visualize ( "zero_shot.html" )
Mari kita mulai dengan menginisialisasi model penjawab pertanyaan Transformers dan tokenizer, dan menjalankannya melalui QuestionAnsweringExplainer .
Untuk contoh ini kami menggunakan bert-large-uncased-whole-word-masking-finetuned-squad , model Bert finetuned pada skuad.
from transformers import AutoModelForQuestionAnswering , AutoTokenizer
from transformers_interpret import QuestionAnsweringExplainer
tokenizer = AutoTokenizer . from_pretrained ( "bert-large-uncased-whole-word-masking-finetuned-squad" )
model = AutoModelForQuestionAnswering . from_pretrained ( "bert-large-uncased-whole-word-masking-finetuned-squad" )
qa_explainer = QuestionAnsweringExplainer (
model ,
tokenizer ,
)
context = """
In Artificial Intelligence and machine learning, Natural Language Processing relates to the usage of machines to process and understand human language.
Many researchers currently work in this space.
"""
word_attributions = qa_explainer (
"What is natural language processing ?" ,
context ,
)Yang akan mengembalikan dikte berikut yang berisi atribusi kata untuk posisi awal dan akhir yang diprediksi untuk jawabannya.
> >> word_attributions
{ 'start' : [( '[CLS]' , 0.0 ),
( 'what' , 0.9177170660377296 ),
( 'is' , 0.13382234898765258 ),
( 'natural' , 0.08061747350142005 ),
( 'language' , 0.013138062762511409 ),
( 'processing' , 0.11135923869816286 ),
( '?' , 0.00858057388924361 ),
( '[SEP]' , - 0.09646373141894966 ),
( 'in' , 0.01545633993975799 ),
( 'artificial' , 0.0472082598707737 ),
( 'intelligence' , 0.026687249355110867 ),
( 'and' , 0.01675371260058537 ),
( 'machine' , - 0.08429502436554961 ),
( 'learning' , 0.0044827685126163355 ),
( ',' , - 0.02401013152520878 ),
( 'natural' , - 0.0016756080249823537 ),
( 'language' , 0.0026815068421401885 ),
( 'processing' , 0.06773157580722854 ),
( 'relates' , 0.03884601576992908 ),
( 'to' , 0.009783797821526368 ),
( 'the' , - 0.026650922910540952 ),
( 'usage' , - 0.010675019721821147 ),
( 'of' , 0.015346787885898537 ),
( 'machines' , - 0.08278008270160107 ),
( 'to' , 0.12861387892768839 ),
( 'process' , 0.19540146386642743 ),
( 'and' , 0.009942879959615826 ),
( 'understand' , 0.006836894853320319 ),
( 'human' , 0.05020451122579102 ),
( 'language' , - 0.012980795199301 ),
( '.' , 0.00804358248127772 ),
( 'many' , 0.02259009321498161 ),
( 'researchers' , - 0.02351650942555469 ),
( 'currently' , 0.04484573078852946 ),
( 'work' , 0.00990399948294476 ),
( 'in' , 0.01806961211334615 ),
( 'this' , 0.13075899776164499 ),
( 'space' , 0.004298315347838973 ),
( '.' , - 0.003767904539347979 ),
( '[SEP]' , - 0.08891544093454595 )],
'end' : [( '[CLS]' , 0.0 ),
( 'what' , 0.8227231947501547 ),
( 'is' , 0.0586864942952253 ),
( 'natural' , 0.0938903563379123 ),
( 'language' , 0.058596976016400674 ),
( 'processing' , 0.1632374290269829 ),
( '?' , 0.09695686057123237 ),
( '[SEP]' , - 0.11644447033554006 ),
( 'in' , - 0.03769172371919206 ),
( 'artificial' , 0.06736158404049886 ),
( 'intelligence' , 0.02496399001288386 ),
( 'and' , - 0.03526028847762427 ),
( 'machine' , - 0.20846431491771975 ),
( 'learning' , 0.00904892847529654 ),
( ',' , - 0.02949905488474854 ),
( 'natural' , 0.011024507784743872 ),
( 'language' , 0.0870741751282507 ),
( 'processing' , 0.11482449622317169 ),
( 'relates' , 0.05008962090922852 ),
( 'to' , 0.04079118393166258 ),
( 'the' , - 0.005069048880616451 ),
( 'usage' , - 0.011992752445836278 ),
( 'of' , 0.01715183316135495 ),
( 'machines' , - 0.29823535624026265 ),
( 'to' , - 0.0043760160855057925 ),
( 'process' , 0.10503217484645223 ),
( 'and' , 0.06840313586976698 ),
( 'understand' , 0.057184000619403944 ),
( 'human' , 0.0976805947708315 ),
( 'language' , 0.07031163646606695 ),
( '.' , 0.10494566513897102 ),
( 'many' , 0.019227154676079487 ),
( 'researchers' , - 0.038173913797800885 ),
( 'currently' , 0.03916641120002003 ),
( 'work' , 0.03705371672439422 ),
( 'in' , - 0.0003155975107591203 ),
( 'this' , 0.17254932354022232 ),
( 'space' , 0.0014311439625599323 ),
( '.' , 0.060637932829867736 ),
( '[SEP]' , - 0.09186286505530596 )]}Kita bisa mendapatkan rentang teks untuk jawaban yang diprediksi dengan:
> >> qa_explainer . predicted_answer
'usage of machines to process and understand human language' Untuk Metode QuestionAnsweringExplainer , metode visualisasi () mengembalikan tabel dengan dua baris. Baris pertama mewakili atribusi untuk posisi awal jawaban dan baris kedua mewakili atribusi untuk posisi akhir jawaban.
qa_explainer . visualize ( "bert_qa_viz.html" )
Saat ini adalah penjelasan eksperimental di bawah pengembangan aktif dan belum sepenuhnya diuji. API penjelasan dapat berubah seperti metode atribusi, jika Anda menemukan bug, beri tahu saya.
Mari kita mulai dengan menginisialisasi model classfication token transformers dan tokenizer, dan menjalankannya melalui TokenClassificationExplainer .
Untuk contoh ini kami menggunakan dslim/bert-base-NER , model Bert Finetuned pada dataset pengenalan entitas CONLL-2003.
from transformers import AutoModelForTokenClassification , AutoTokenizer
from transformers_interpret import TokenClassificationExplainer
model = AutoModelForTokenClassification . from_pretrained ( 'dslim/bert-base-NER' )
tokenizer = AutoTokenizer . from_pretrained ( 'dslim/bert-base-NER' )
ner_explainer = TokenClassificationExplainer (
model ,
tokenizer ,
)
sample_text = "We visited Paris last weekend, where Emmanuel Macron lives."
word_attributions = ner_explainer ( sample_text , ignored_labels = [ 'O' ]) Untuk mengurangi jumlah atribusi yang dihitung, kami memberi tahu penjelasan untuk mengabaikan token yang diprediksi labelnya adalah 'O' . Kami juga dapat memberi tahu penjelasan untuk mengabaikan indeks tertentu yang menyediakan daftar sebagai argumen dari parameter ignored_indexes .
Yang akan mengembalikan dikte berikut termasuk label yang diprediksi dan atribusi untuk masing -masing token, kecuali yang diprediksi sebagai 'o':
> >> word_attributions
{ 'paris' : { 'label' : 'B-LOC' ,
'attribution_scores' : [( '[CLS]' , 0.0 ),
( 'we' , - 0.014352325471387907 ),
( 'visited' , 0.32915222186559123 ),
( 'paris' , 0.9086791784795596 ),
( 'last' , 0.15181203147624034 ),
( 'weekend' , 0.14400210630677038 ),
( ',' , 0.01899744327012935 ),
( 'where' , - 0.039402005463239465 ),
( 'emmanuel' , 0.061095284002642025 ),
( 'macro' , 0.004192922551105228 ),
( '##n' , 0.09446355513057757 ),
( 'lives' , - 0.028724312616455003 ),
( '.' , 0.08099007392937585 ),
( '[SEP]' , 0.0 )]},
'emmanuel' : { 'label' : 'B-PER' ,
'attribution_scores' : [( '[CLS]' , 0.0 ),
( 'we' , - 0.006933030636686712 ),
( 'visited' , 0.10396962390436904 ),
( 'paris' , 0.14540758744233165 ),
( 'last' , 0.08024018944451371 ),
( 'weekend' , 0.10687970996804418 ),
( ',' , 0.1793198466387937 ),
( 'where' , 0.3436407835483767 ),
( 'emmanuel' , 0.8774892642652167 ),
( 'macro' , 0.03559399361048316 ),
( '##n' , 0.1516315604785551 ),
( 'lives' , 0.07056441327498127 ),
( '.' , - 0.025820924624605487 ),
( '[SEP]' , 0.0 )]},
'macro' : { 'label' : 'I-PER' ,
'attribution_scores' : [( '[CLS]' , 0.0 ),
( 'we' , 0.05578067326280157 ),
( 'visited' , 0.00857021283406586 ),
( 'paris' , 0.16559056506114297 ),
( 'last' , 0.08285256685903823 ),
( 'weekend' , 0.10468727443796395 ),
( ',' , 0.09949509071515888 ),
( 'where' , 0.3642458274356929 ),
( 'emmanuel' , 0.7449335213978788 ),
( 'macro' , 0.3794625659183485 ),
( '##n' , - 0.2599031433800762 ),
( 'lives' , 0.20563450682196147 ),
( '.' , - 0.015607017319486929 ),
( '[SEP]' , 0.0 )]},
'##n' : { 'label' : 'I-PER' ,
'attribution_scores' : [( '[CLS]' , 0.0 ),
( 'we' , 0.025194121717285252 ),
( 'visited' , - 0.007415022865239864 ),
( 'paris' , 0.09478357303107598 ),
( 'last' , 0.06927939834474463 ),
( 'weekend' , 0.0672008033510708 ),
( ',' , 0.08316907214363504 ),
( 'where' , 0.3784915854680165 ),
( 'emmanuel' , 0.7729352621546081 ),
( 'macro' , 0.4148652759139777 ),
( '##n' , - 0.20853534512145033 ),
( 'lives' , 0.09445057087678274 ),
( '.' , - 0.094274985907366 ),
( '[SEP]' , 0.0 )]},
'[SEP]' : { 'label' : 'B-LOC' ,
'attribution_scores' : [( '[CLS]' , 0.0 ),
( 'we' , - 0.3694351403796742 ),
( 'visited' , 0.1699038407402483 ),
( 'paris' , 0.5461587414992369 ),
( 'last' , 0.0037948102770307517 ),
( 'weekend' , 0.1628100955702496 ),
( ',' , 0.4513093410909263 ),
( 'where' , - 0.09577409464161038 ),
( 'emmanuel' , 0.48499459835388914 ),
( 'macro' , - 0.13528905587653023 ),
( '##n' , 0.14362969934754344 ),
( 'lives' , - 0.05758007024257254 ),
( '.' , - 0.13970977266152554 ),
( '[SEP]' , 0.0 )]}} Untuk TokenClassificationExplainer metode visualisasi () mengembalikan tabel dengan baris sebanyak token.
ner_explainer . visualize ( "bert_ner_viz.html" )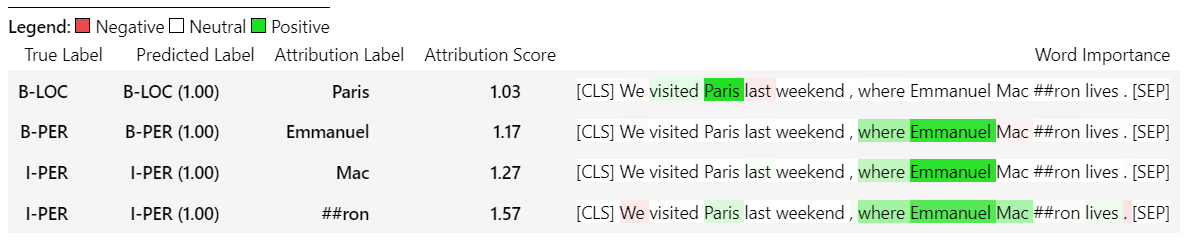
Untuk detail lebih lanjut tentang cara kerja TokenClassificationExplainer , Anda dapat memeriksa notebook notebooks/ner_example.ipynb.
ImageClassificationExplainer dirancang untuk bekerja dengan semua model dari pustaka Transformers yang dilatih untuk klasifikasi gambar (Swin, Vit, dll). Ini memberikan atribusi untuk setiap piksel dalam gambar yang dapat dengan mudah divisualisasikan menggunakan metode penjelasan yang dibangun dalam metode visualize .
Menginisialisasi Klasifikasi Gambar sangat sederhana, yang Anda butuhkan adalah model klasifikasi gambar yang lebih tinggi atau dilatih untuk bekerja dengan Huggingface dan ekstraktor fiturnya.
Untuk contoh ini kami menggunakan google/vit-base-patch16-224 , model Vision Transformer (VIT) yang pra-terlatih di ImageNet-21K yang memprediksi dari 1000 kelas yang mungkin.
from transformers import AutoFeatureExtractor , AutoModelForImageClassification
from transformers_interpret import ImageClassificationExplainer
from PIL import Image
import requests
model_name = "google/vit-base-patch16-224"
model = AutoModelForImageClassification . from_pretrained ( model_name )
feature_extractor = AutoFeatureExtractor . from_pretrained ( model_name )
# With both the model and feature extractor initialized we are now able to get explanations on an image, we will use a simple image of a golden retriever.
image_link = "https://imagesvc.meredithcorp.io/v3/mm/image?url=https%3A%2F%2Fstatic.onecms.io%2Fwp-content%2Fuploads%2Fsites%2F47%2F2020%2F08%2F16%2Fgolden-retriever-177213599-2000.jpg"
image = Image . open ( requests . get ( image_link , stream = True ). raw )
image_classification_explainer = ImageClassificationExplainer ( model = model , feature_extractor = feature_extractor )
image_attributions = image_classification_explainer (
image
)
print ( image_attributions . shape )Yang akan mengembalikan daftar tupel berikut:
> >> torch . Size ([ 1 , 3 , 224 , 224 ])Karena kami berurusan dengan visualisasi gambar bahkan lebih mudah daripada di model teks.
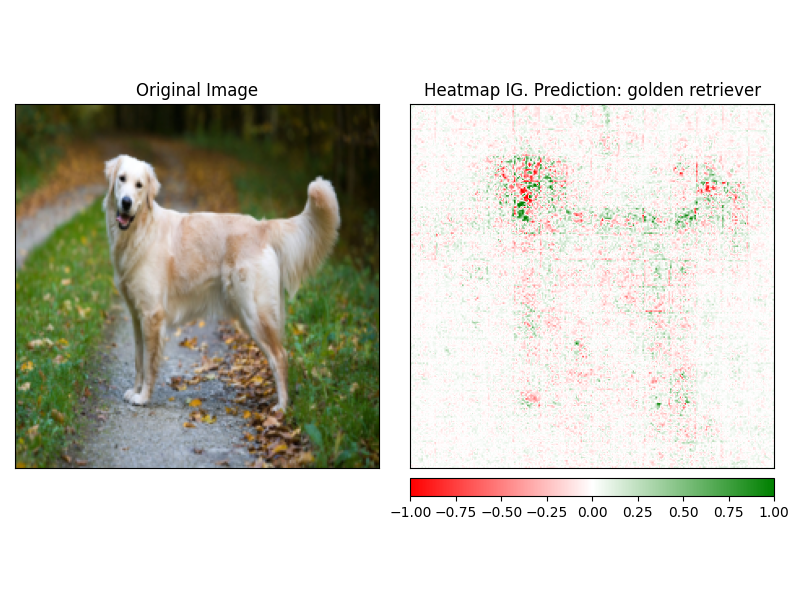
Attrbutions dapat dengan mudah divisualisasikan menggunakan metode visualize dari penjelajah. Saat ini ada 4 metode visualisasi yang didukung.
heatmap - Panas dari atribusi positif dan negatif diambil dalam menggunakan dimensi gambar.overlay - Panasnya overlay di atas versi abu -abu dari gambar aslimasked_image - Nilai absolut attrbutions digunakan untuk membuat topeng di atas gambar aslialpha_scaling - Sets Alpha Channel (transparansi) dari setiap piksel untuk sama dengan nilai atribusi yang dinormalisasi. image_classification_explainer . visualize (
method = "heatmap" ,
side_by_side = True ,
outlier_threshold = 0.03
)
image_classification_explainer . visualize (
method = "overlay" ,
side_by_side = True ,
outlier_threshold = 0.03
)
image_classification_explainer . visualize (
method = "masked_image" ,
side_by_side = True ,
outlier_threshold = 0.03
)
image_classification_explainer . visualize (
method = "alpha_scaling" ,
side_by_side = True ,
outlier_threshold = 0.03
)
Paket ini masih dalam pengembangan aktif dan ada lebih banyak yang direncanakan. Untuk rilis 1.0.0 yang ingin kami miliki:
Jika Anda ingin memberikan kontribusi, silakan periksa pedoman kontribusi kami
Pemelihara repositori ini adalah @cdpierse.
Jika Anda memiliki pertanyaan, saran, atau ingin memberikan kontribusi (silakan lakukan?), Jangan ragu untuk menghubungi [email protected]
Saya juga sangat menyarankan untuk memeriksa Captum jika Anda menemukan model penjelasan dan interpretabilitas menarik.
Paket ini berdiri di pundak pekerjaan luar biasa yang dilakukan oleh tim di Pytorch Captum dan memeluk wajah dan tidak akan ada jika bukan karena pekerjaan luar biasa yang mereka berdua lakukan di bidang ML dan interpretabilitas model masing -masing.
Semua atribusi dalam paket ini dihitung menggunakan paket kemampuan penjelasan Pytorch. Lihat di bawah untuk beberapa tautan berguna yang terkait dengan Captum.
Gradien terintegrasi (IG) dan variasi gradien terintegrasi lapisan IT (LIG) adalah metode atribusi inti di mana Transformers Interpreters saat ini dibangun. Di bawah ini adalah beberapa sumber daya yang berguna termasuk kertas asli dan beberapa tautan video yang menjelaskan mekanika dalam. Jika Anda ingin tahu tentang apa yang terjadi di dalam Transformers Interpreters, saya sangat merekomendasikan untuk memeriksa setidaknya satu dari sumber daya ini.
Tautan captum
Di bawah ini adalah beberapa tautan yang saya gunakan untuk membantu saya mengumpulkan paket ini menggunakan Captum. Terima kasih untuk @DavIdefiocco atas inti Anda yang sangat berwawasan.


