aimon python sdk
v0.8.0
Aimon ayuda a los desarrolladores a construir, enviar y monitorear aplicaciones LLM de manera más confidencial y confiable con su sistema de última generación y multimodelo para detectar problemas de calidad de LLM. Ayuda a la perfección tanto con las evaluaciones fuera de línea como con el monitoreo de la producción continua. Aimon ofrece detección de alucinación rápida, confiable y rentable. También respalda otras métricas de calidad importantes, como la integridad, la concisión y la toxicidad. Lea nuestra publicación de blog para obtener más detalles.
Únete a nuestra comunidad en Slack

La siguiente es una lista de métricas de calidad que están actualmente disponibles y en nuestra hoja de ruta. Comuníquese para expresar su interés en cualquiera de estos.
| Métrico | Estado |
|---|---|
| Alucinación modelo (pasaje y nivel de oración) | ✓ |
| Lo completo | ✓ |
| Concisión | ✓ |
| Toxicidad | ✓ |
| Adhesión de instrucciones | ✓ |
Aimon admite instrumentación asincrónica o detecciones sincrónicas para las métricas mencionadas anteriormente. Use estos pasos para comenzar con el uso de Aimon SDK y el producto.
pip install aimon en su terminal. from aimon import Detect
detect = Detect ( values_returned = [ 'context' , 'generated_text' ], config = { "hallucination" : { "detector_name" : "default" }})
@ detect
def my_llm_app ( context , query ):
# my_llm_model is the function that generates text using the LLM model
generated_text = my_llm_model ( context , query )
return context , generated_textanalyze_prod .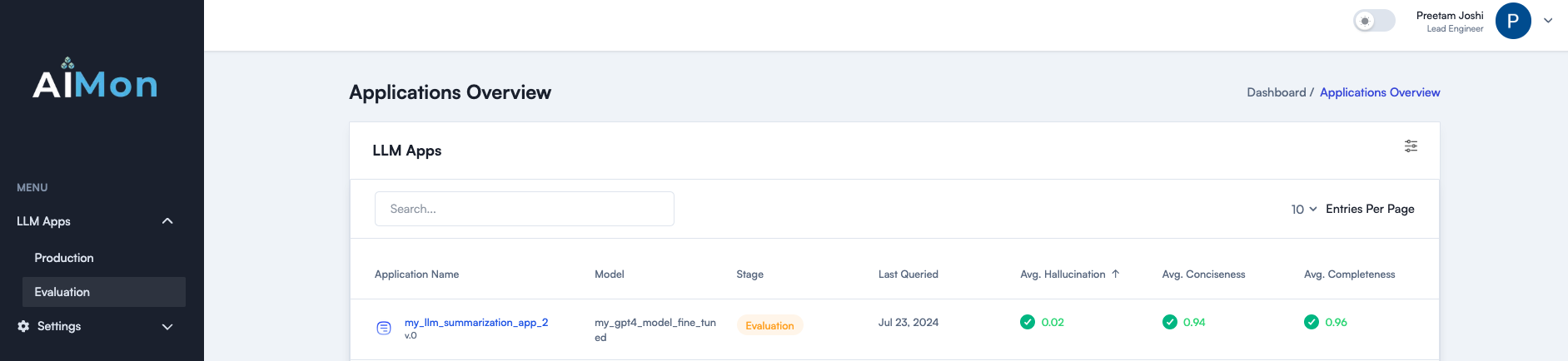
Para demostrar la efectividad de nuestro sistema, la comparamos con los puntos de referencia populares de la industria para la tarea de detección de alucinación. La siguiente tabla muestra nuestros resultados.
Algunas conclusiones clave:
✅ Aimon es 10 veces más barato que GPT-4 Turbo.
✅ Aimon es 4x más rápido que GPT-4 Turbo.
✅ Aimon proporciona la conveniencia de una API totalmente alojada que incluye la explicabilidad de horneado.
✅ Soporte para una longitud de contexto de hasta 32,000 tokens (con planes para expandir esto aún más en el futuro cercano).
En general, Aimon es 10 veces más barato, 4 veces más rápido y cerca o incluso mejor que GPT-4 en los puntos de referencia, lo que lo convierte en una opción adecuada para la detección de alucinaciones fuera de línea y en línea.
| Métrico | Aimon confía v1 | GPT-4 Turbo (LLM-as-a-Judge) |
|---|---|---|
| Longitud de contexto | 32,000 | 128,000 |
| Verdadero conjunto de datos Precisión/retirada | 0.808 / 0.922 | 0.810 / 0.926 |
| Sumpa (prueba) precisión equilibrada | 0.778 | 0.756 |
| Sumadora (prueba) AUC | 0.809 | 0.780 |
| Prueba de clasificación de cualquier escala para la precisión de las alucinaciones | 0.665 | 0.741 |
| Prueba de clasificación de cualquier escala para alucinaciones rel. Exactitud | 0.804 | 0.855 |
| Avg. Estado latente | 417 ms | 1800 ms |
| Costo (tokens de 15 millones en todos los conjuntos de datos de referencia) excluyendo el nivel gratuito | $ 15 | $ 158 |
| Totalmente alojado | ✅ | ✅ |
| Explicación | Puntajes automáticos a nivel de oración | Razonamiento detallado con ingeniería rápida adicional |
Hay una falta de conjuntos de datos de referencia estándar de la industria para estas métricas. Pronto publicaremos un conjunto de datos de evaluación. ¡Manténganse al tanto! ⌛
Consulte el sitio web Aimon.ai para más detalles.
Únase a nuestra comunidad Slack para las últimas actualizaciones y discusiones sobre confiabilidad generativa de IA.


