pd3f
1.0.0
pd3f實驗,謹慎使用。
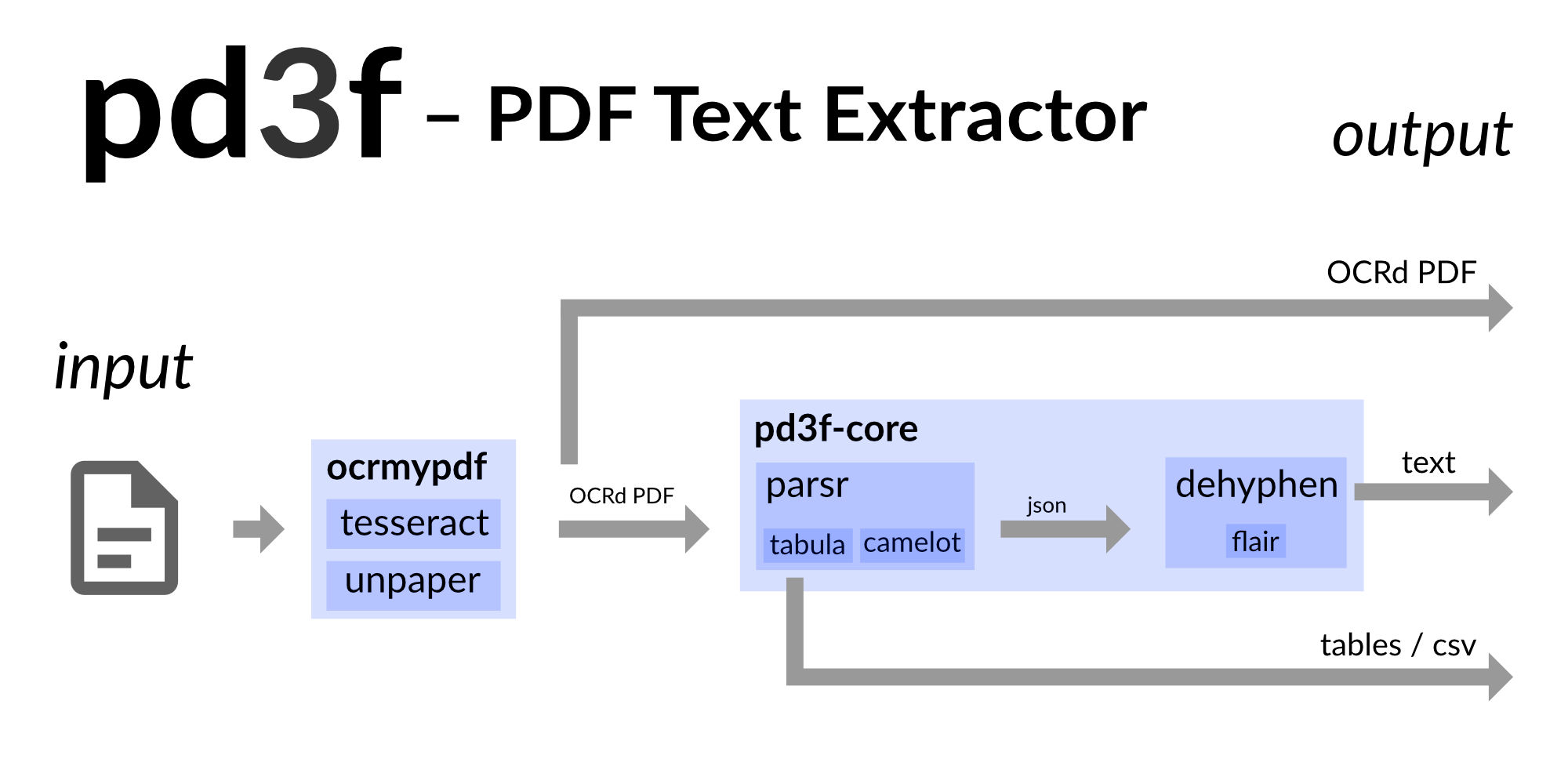
pd3f是PDF文本提取管道,基於自託管,本地優先和基於Docker。它在機器學習的幫助下重建了原始的連續文本。
pd3f可以用OCRMYPDF(Tesseract)OCR掃描PDF,並用Camelot和Tabula提取表。它建立在PARSR的輸出之上。 PARSR檢測文本的層次結構,並將文本分為單詞,行和段落。
即使PARSR為PDF帶來了一些結構,但由於連字符,文本仍然被擾亂。基礎Python軟件包PD3F核心試圖通過刪除連字符,新線條和 /或空格來重建原始的連續文本。它使用語言模型來猜測原始文本的樣子。
pd3f對於諸如德語之類的語言特別有用。它主要是為了解析德國信件和官方文件。除了德國pd3f ,還支持英語,西班牙語,法語和意大利語。將在以後添加更多語言。
pd3f包括基於Web的GUI和基於燒瓶的微服務(API)。您可以在demo.pd3f.com上找到演示。
在以下網址查看完整文檔:https://pd3f.com/docs/
PDF很難處理,很難提取信息。因此,此工具的結果可能無法滿足您的需求。將有更多的工作來改進該軟件,但總的來說,它不太可能很快成功提取所有信息。
在這裡,有些事情會得到改善。
job.started_at和job.ended_at計算運行時安裝和使用詩歌。
最初運行:
./dev.sh --build省略--build如果碼頭圖像不需要構建。現在,Docker + Poetry無法緩存安裝,因此始終構建圖像是不酷的。
如果您有問題,找到錯誤或想提出新功能,請查看“問題”頁面。
拉動請求在修復錯誤或提高代碼質量時特別受到歡迎。
Affero通用公共許可證3.0



