pd3f
1.0.0
pd3f实验,谨慎使用。
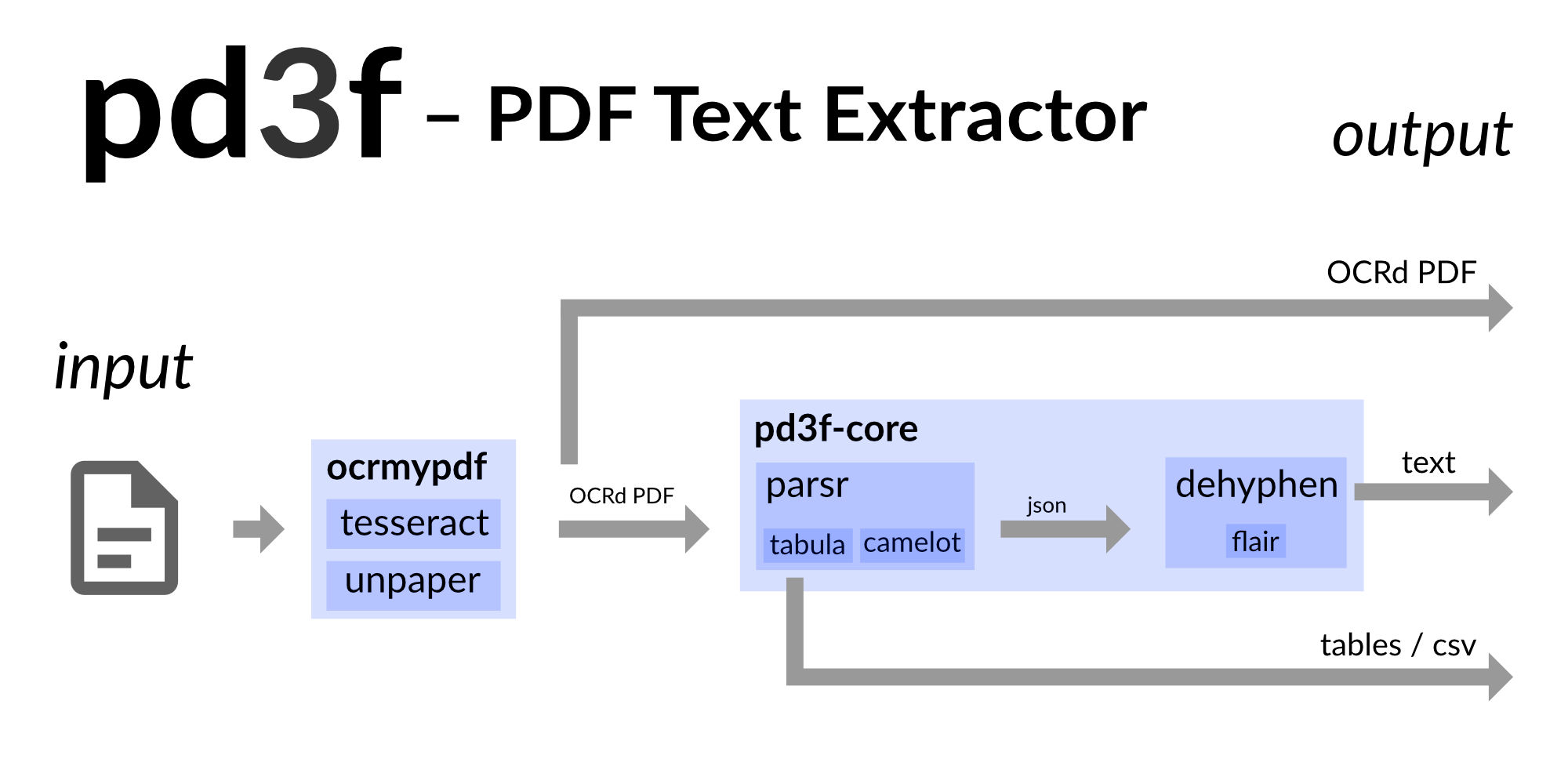
pd3f是PDF文本提取管道,基于自托管,本地优先和基于Docker。它在机器学习的帮助下重建了原始的连续文本。
pd3f可以用OCRMYPDF(Tesseract)OCR扫描PDF,并用Camelot和Tabula提取表。它建立在PARSR的输出之上。 PARSR检测文本的层次结构,并将文本分为单词,行和段落。
即使PARSR为PDF带来了一些结构,但由于连字符,文本仍然被扰乱。基础Python软件包PD3F核心试图通过删除连字符,新线条和 /或空格来重建原始的连续文本。它使用语言模型来猜测原始文本的样子。
pd3f对于诸如德语之类的语言特别有用。它主要是为了解析德国信件和官方文件。除了德国pd3f ,还支持英语,西班牙语,法语和意大利语。将在以后添加更多语言。
pd3f包括基于Web的GUI和基于烧瓶的微服务(API)。您可以在demo.pd3f.com上找到演示。
在以下网址查看完整文档:https://pd3f.com/docs/
PDF很难处理,很难提取信息。因此,此工具的结果可能无法满足您的需求。将有更多的工作来改进该软件,但总的来说,它不太可能很快成功提取所有信息。
在这里,有些事情会得到改善。
job.started_at和job.ended_at计算运行时安装和使用诗歌。
最初运行:
./dev.sh --build省略--build如果码头图像不需要构建。现在,Docker + Poetry无法缓存安装,因此始终构建图像是不酷的。
如果您有问题,找到错误或想提出新功能,请查看“问题”页面。
拉动请求在修复错误或提高代码质量时特别受到欢迎。
Affero通用公共许可证3.0



