pd3f
1.0.0
pd3f実験的、慎重に使用します。
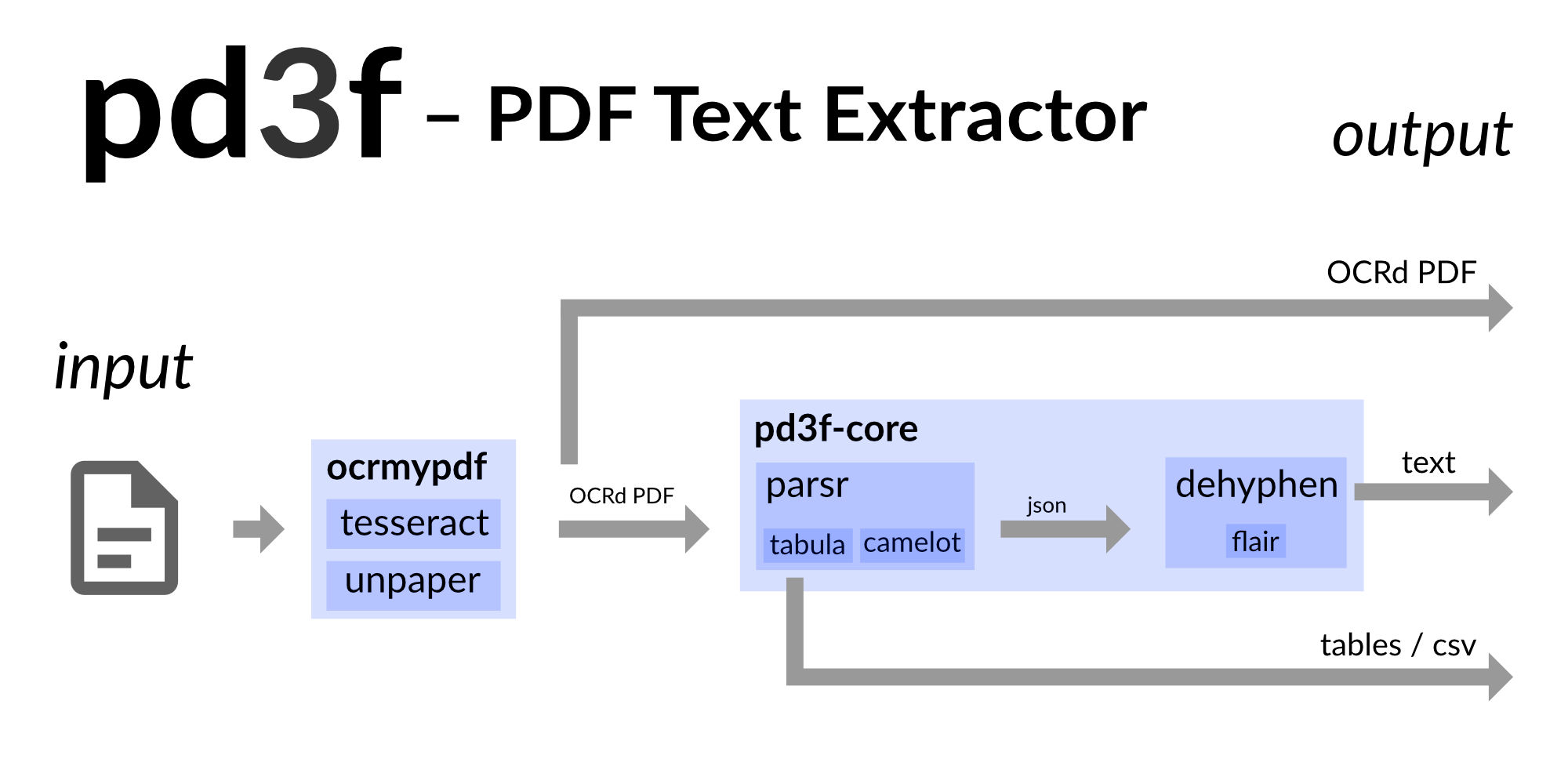
pd3fは、自己ホスト、ローカルファースト、ドッカーベースのPDFテキスト抽出パイプラインです。機械学習の助けを借りて、元の連続テキストを再構築します。
pd3f 、OCRMYPDF(Tesseract)でPDFをスキャンし、キャメロットとタブラでテーブルを抽出できます。 Parsrの出力に基づいています。 PARSRは、テキストの階層を検出し、テキストを単語、行、段落に分割します。
PARSRはPDFに何らかの構造をもたらしますが、テキストは依然としてスクランブルされています。つまり、ハイフンのためです。基礎となるPythonパッケージPD3Fコアは、ハイフン、新しいライン、スペースを削除して、元の連続テキストを再構築しようとします。言語モデルを使用して、元のテキストがどのように見えるかを推測します。
pd3f 、ドイツ語などの長い単語を持つ言語に特に役立ちます。主にドイツの手紙と公式文書を解析するために開発されました。ドイツのpd3fに加えて、英語、スペイン語、フランス語、イタリア語をサポートしています。より多くの言語が後の段階で追加されます。
pd3fには、WebベースのGUIとフラスコベースのマイクロサービス(API)が含まれています。 demo.pd3f.comでデモを見つけることができます。
https://pd3f.com/docs/で完全なドキュメントをご覧ください
PDFは処理が困難であり、情報を抽出するのは困難です。したがって、このツールの結果はあなたを満足させないかもしれません。このソフトウェアを改善するためのより多くの作業がありますが、まったくすべての情報をすぐに抽出することはまずありません。
ここでは、改善されることがいくつかあります。
job.started_atとjob.ended_atに基づいてランタイムを計算します詩をインストールして使用します。
最初に実行:
./dev.sh --build Docker画像がビルドを取得する必要がない場合は、 --buildします。現在、Docker + Poetryはインストールをキャッシュできないため、常に画像を構築することはできません。
質問がある場合、バグを見つけた場合、または新しい機能を提案したい場合は、[問題]ページをご覧ください。
プルリクエストは、バグを修正したり、コードの品質を向上させたりすると、特に歓迎されます。
Affero General Public License 3.0



