pd3f
1.0.0
pd3fEksperimental, gunakan dengan hati -hati.
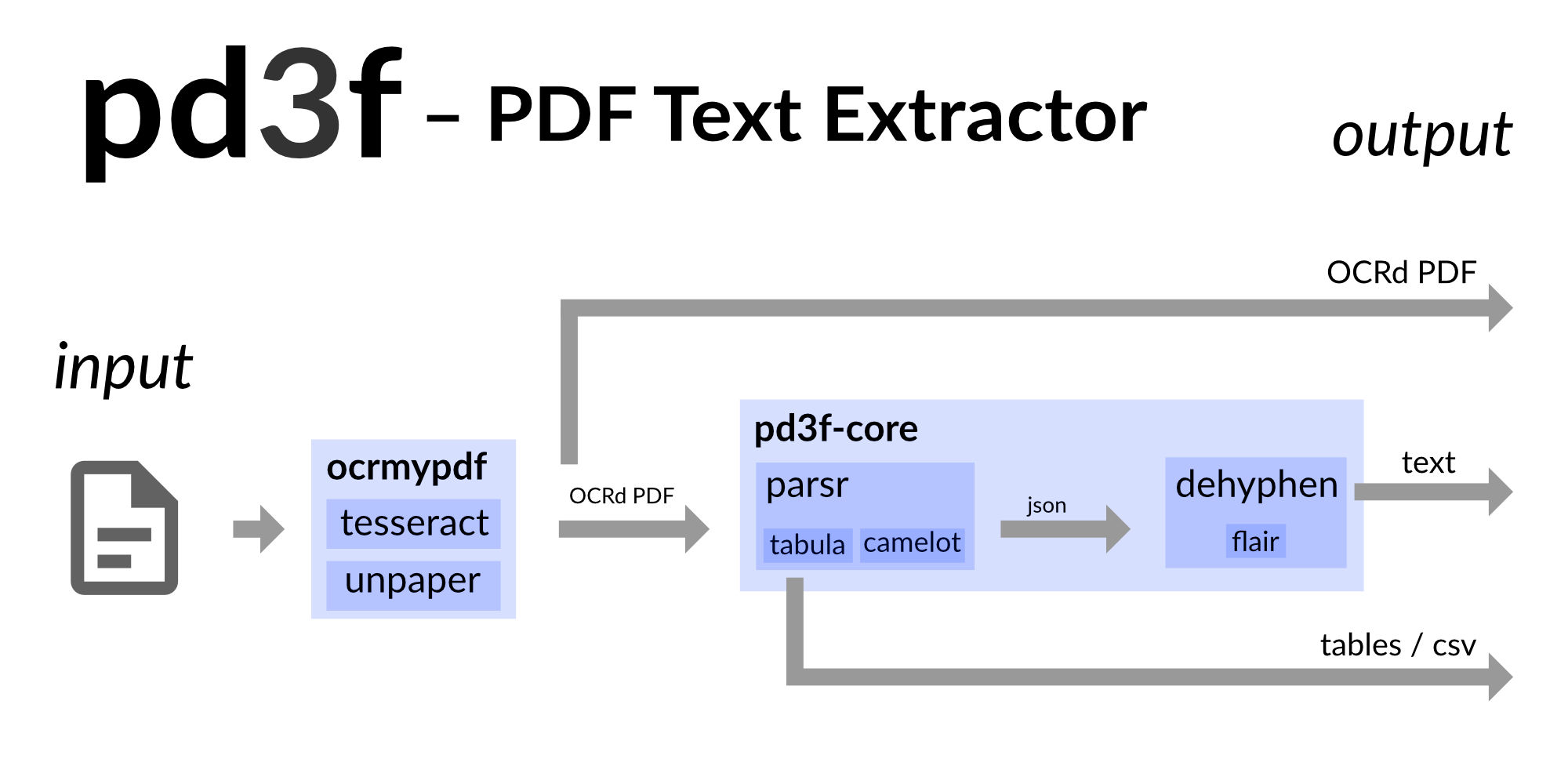
pd3f adalah pipa ekstraksi teks PDF yang di-host sendiri, lokal-pertama dan berbasis Docker. Ini merekonstruksi teks kontinu asli dengan bantuan pembelajaran mesin .
pd3f dapat OCR memindai PDF dengan OCRMYPDF (Tesseract) dan mengekstrak tabel dengan Camelot dan Tabula. Itu dibangun di atas output Parsr. Parsr mendeteksi hierarki teks dan membagi teks menjadi kata -kata, baris, dan paragraf.
Meskipun Parsr membawa beberapa struktur ke PDF, teks masih diacak, yaitu, karena tanda hubung. Paket Python yang mendasari PD3F-Core mencoba merekonstruksi teks kontinu asli dengan menghilangkan tanda hubung, baris baru dan / atau spasi. Ini menggunakan model bahasa untuk menebak bagaimana teks aslinya terlihat.
pd3f sangat berguna untuk bahasa dengan kata -kata panjang seperti Jerman. Itu terutama dikembangkan untuk menguraikan surat -surat Jerman dan dokumen resmi. Selain pd3f Jerman mendukung bahasa Inggris, Spanyol, Prancis dan Italia. Lebih banyak bahasa akan ditambahkan tahap selanjutnya.
pd3f mencakup GUI berbasis web dan Microservice (API) berbasis Flask. Anda dapat menemukan demo di demo.pd3f.com.
Lihat dokumentasi lengkap di: https://pd3f.com/docs/
PDF sulit diproses dan sulit untuk mengekstraksi informasi. Jadi hasil alat ini mungkin tidak memuaskan Anda. Akan ada lebih banyak pekerjaan untuk meningkatkan perangkat lunak ini tetapi sama sekali, tidak mungkin bahwa itu akan berhasil mengekstrak semua informasi dalam waktu dekat.
Di sini beberapa hal yang akan ditingkatkan.
job.started_at dan job.ended_atInstal dan gunakan puisi.
Awalnya jalankan:
./dev.sh --build OMIT --build Jika gambar Docker tidak perlu dibangun. Saat ini Docker + puisi tidak dapat menangani pemasangan sehingga membangun gambar sepanjang waktu tidak keren.
Jika Anda memiliki pertanyaan , menemukan bug atau ingin mengusulkan fitur baru, lihat halaman masalah.
Permintaan tarik sangat disambut ketika mereka memperbaiki bug atau meningkatkan kualitas kode.
Lisensi Publik Umum Affero 3.0



