pd3f
1.0.0
pd3f실험적으로 조심스럽게 사용하십시오.
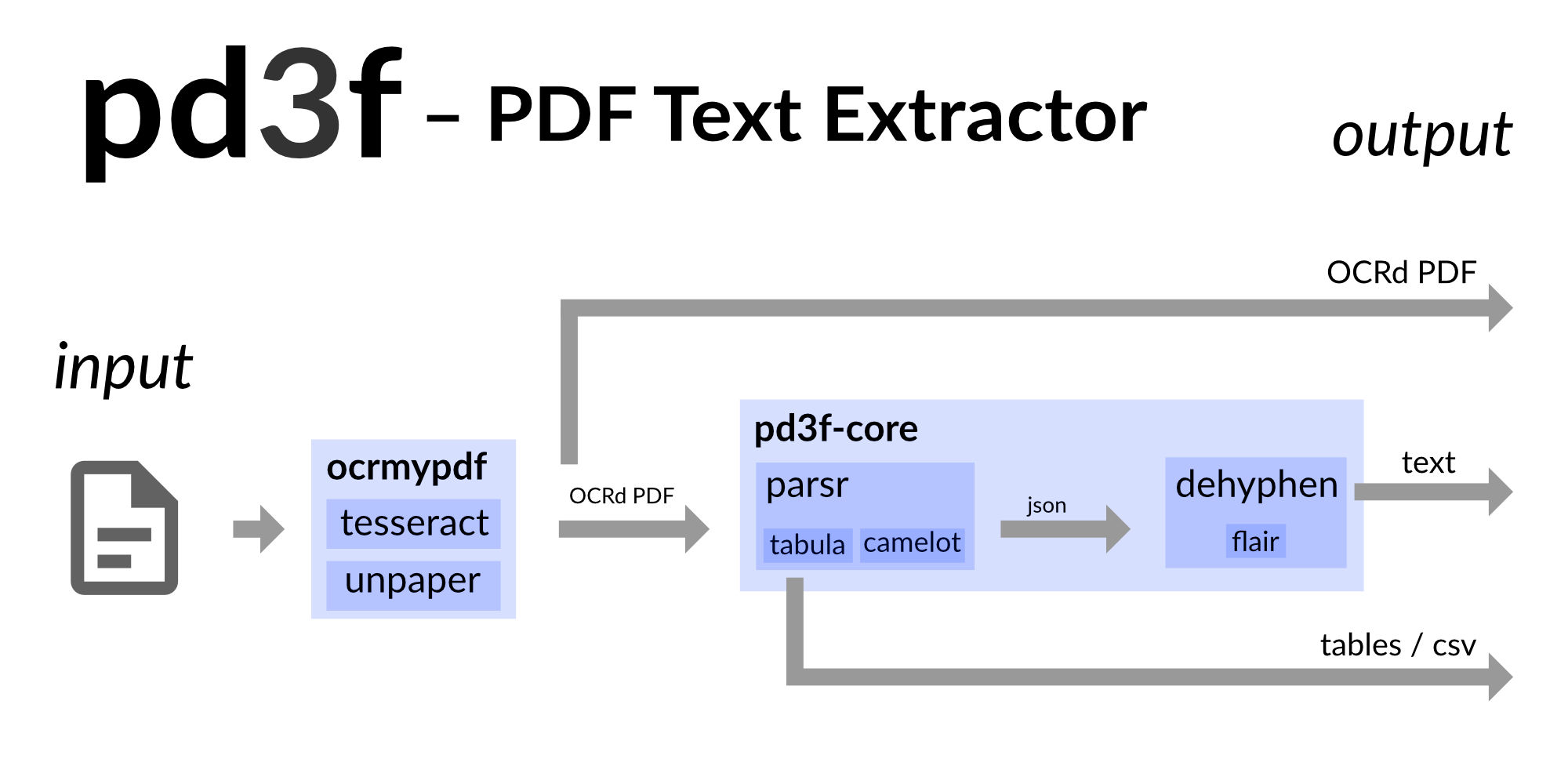
pd3f 는 자체 호스팅, 로컬 우선 및 도커 기반 인 PDF 텍스트 추출 파이프 라인입니다. 기계 학습 의 도움으로 원래 연속 텍스트를 재구성합니다 .
pd3f OCRMYPDF (TesserAct)로 PDF를 스캔하고 Camelot 및 Tabula와 함께 테이블을 추출 할 수 있습니다. 그것은 Parsr의 출력에 기반을두고 있습니다. PARSR은 텍스트의 계층 구조를 감지하고 텍스트를 단어, 줄 및 단락으로 나눕니다.
PARSR이 PDF에 약간의 구조를 가져 오지만 하이픈으로 인해 텍스트가 여전히 뒤섞여 있습니다. 기본 Python 패키지 PD3F-Core는 하이픈, 새 선 및 / 또는 공백을 제거하여 원래 연속 텍스트를 재구성하려고합니다. 언어 모델을 사용하여 원본 텍스트의 모양을 추측합니다.
pd3f 는 독일어와 같은 긴 단어가있는 언어에 특히 유용합니다. 그것은 주로 독일어 편지와 공식 문서를 구문 분석하기 위해 개발되었습니다. 독일 pd3f 외에도 영어, 스페인어, 프랑스어 및 이탈리아어를 지원합니다. 더 많은 언어가 나중에 추가 될 것입니다.
pd3f 에는 웹 기반 GUI 및 플라스크 기반 마이크로 서비스 (API)가 포함됩니다. Demo.pd3f.com에서 데모를 찾을 수 있습니다.
https://pd3f.com/docs/에서 전체 문서를 확인하십시오.
PDF는 처리하기 어렵고 정보를 추출하기가 어렵습니다. 따라서이 도구의 결과는 귀하를 만족시키지 못할 수 있습니다. 이 소프트웨어를 개선하기위한 더 많은 작업이있을 것이지만, 완전히 모든 정보를 곧 성공적으로 추출하지는 않을 것입니다.
여기서 개선 될 몇 가지.
job.started_at 및 job.ended_at 에 따라 런타임을 계산합니다시를 설치하고 사용하십시오.
처음 실행 :
./dev.sh --build 생략 --build 이미지가 빌드 할 필요가없는 경우 건물. 현재 Docker + Poetry는 설치를 캐시 할 수 없으므로 이미지를 항상 구축하지 못합니다.
질문이 있거나 버그를 찾거나 새로운 기능을 제안하려면 문제 페이지를 살펴보십시오.
풀 요청은 버그를 고치거나 코드 품질을 향상시킬 때 특히 환영합니다.
Affero General Public License 3.0



