SNELL
1.0.0
這是我們論文的官方實施:擴大稀疏調整以減少內存使用情況。
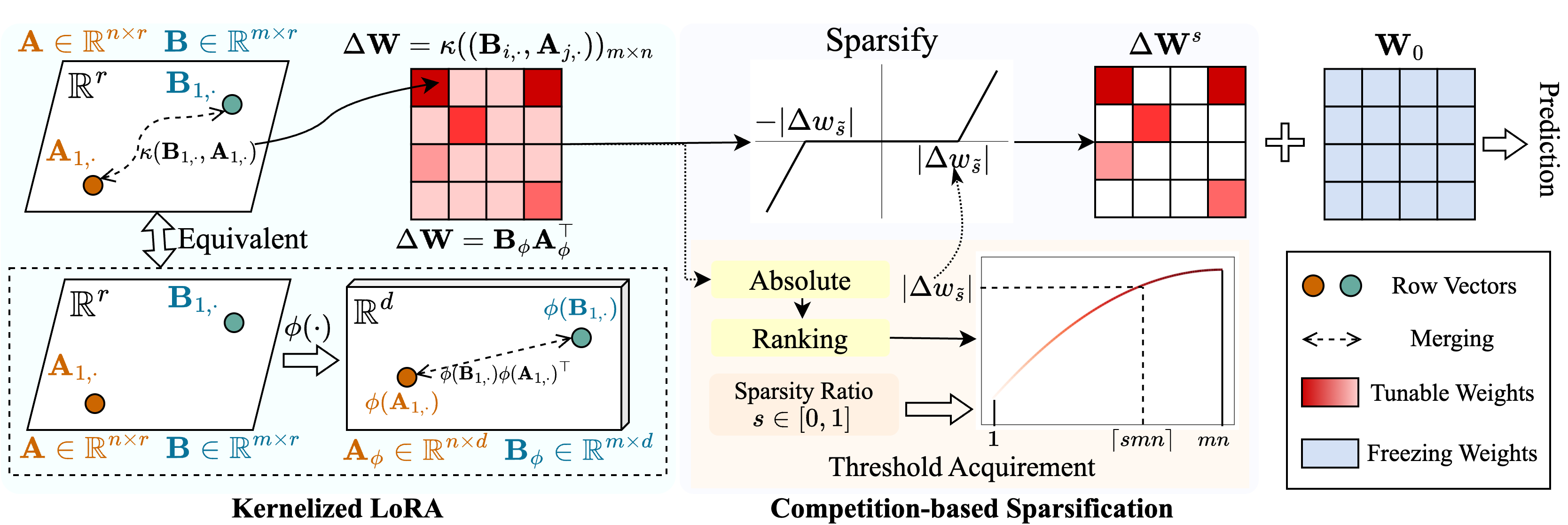
我們提出了一種稱為Snell(用Ker nel ized l ora進行調整)的方法,以使稀疏調諧使用低記憶使用。 Snell將稀疏性的可調矩陣分解為兩個可學習的低級矩陣,從原始完整矩陣的昂貴存儲中節省下來。為了保持低級矩陣稀疏調整的有效性,我們從內核角度擴展了低級別的分解。具體而言,我們將非線性內核函數應用於全矩陣合併並增加合併矩陣的等級。採用較高的等級可以增強SNELL對下游任務優化稀疏訓練模型的能力。為了進一步減少稀疏調整中的內存使用量,我們引入了一種基於競爭的稀疏機制,避免了可調重量索引的存儲。在多個下游任務上進行了廣泛的實驗表明,Snell以低內存使用的方式實現了最先進的性能,從而擴展了有效的PEFT,並稀疏地調整到大型模型。
如果您發現此存儲庫或我們的論文有用,請考慮引用和凝視我們!
@InProceedings{Shen_2024_SNELL,
title={Expanding Sparse Tuning for Low Memory Usage},
author={Shen, Shufan and Sun, Junshu and Ji, Xiangyang and Huang, Qingming and Wang, Shuhui},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2024}
}
./train.py :運行此文件進行培訓。./scripts :用於使用Snell調整預訓練的模型到下游任務的腳本。./lib :用於IO,登錄,培訓和數據加載的輔助功能。./model :用於微調的骨乾架構和方法。./engine.py :主要培訓和評估功能。./data :存儲FGVC和VTAB-1K基準。克隆這個倉庫:
git clone https://github.com/ssfgunner/SNELL.git
cd SNELL創建一個conda虛擬環境並激活它:
conda create -n snell python=3.8 -y
conda activate snell安裝torch==1.12.1和torchvision==0.13.1 with CUDA==11.3 :
conda install pytorch==1.12.1 torchvision==0.13.1 cudatoolkit=11.3 -c pytorch安裝其他依賴項:
pip install -r requirements.txt
FGVC:請在VPT之後下載數據集。
VTAB-1K:由於原始VTAB基準測試中某些數據集的處理非常棘手,因此我們建議SSF共享的提取的VTAB-1K數據集為方便起見。 (請注意,許可證是在VTAB基準中)。
文件結構應該看起來像:
data
├── fgvc
│ ├── cub
│ ├── nabirds
│ └── ...
└── vtab-1k
├── caltech101
├── cifar
└── ...mkdir checkpoints
cd checkpoints
# Supervisedly pre-trained ViT-B/16
wget https://console.cloud.google.com/storage/browser/_details/vit_models/imagenet21k/ViT-B_16.npz
# MAE pre-trained ViT-B/16
wget https://dl.fbaipublicfiles.com/mae/pretrain/mae_pretrain_vit_base.pth
# MoCo V3 pre-trained ViT-B/16
wget https://dl.fbaipublicfiles.com/moco-v3/vit-b-300ep/linear-vit-b-300ep.pth.tar
# Supervisedly pre-trained Swin-Transformer
wget https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22k.pth
# Supervisedly pre-trained ConvNeXt
wget https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_224.pth我們提供了培訓腳本,以通過SNELL-32調整受監督的預訓練的VIT對FGVC和VTAB-1K。
# Fine-tuning supervised pre-trained ViT-B/16 with SNELL-32 for CUB dataset of FGVC
bash scripts/fgvc/snell32/vit_cub_snell.sh
# Fine-tuning supervised pre-trained ViT-B/16 with SNELL-32 for CIFAR dataset of VTAB-1k
bash scripts/vtab/snell32/vit_cifar_snell.sh對於其他模型,我們提供腳本以在FGVC上微調它們:例如:
python train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=vit_base_patch16_224_in21k_snell --resume=checkpoints/mae_pretrain_vit_base.pth
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " ViT_MAE_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stagepython train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=vit_base_patch16_224_in21k_snell --resume=checkpoints/linear-vit-b-300ep.pth.tar
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " ViT_MoCo_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stagepython train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=swin_base_patch4_window7_224_in22k --resume=./checkpoints/swin_base_patch4_window7_224_22k.pth
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " Swin_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stagepython train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=convnext_base_in22k --resume=./checkpoints/convnext_base_22k_224.pth
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " ConvNeXt_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stage我們的代碼根據VPT,SSF和SPT進行了修改。我們感謝作者的開源代碼。


