SNELL
1.0.0
Esta é a implementação oficial do nosso artigo: expandir o ajuste esparso para baixo uso da memória.
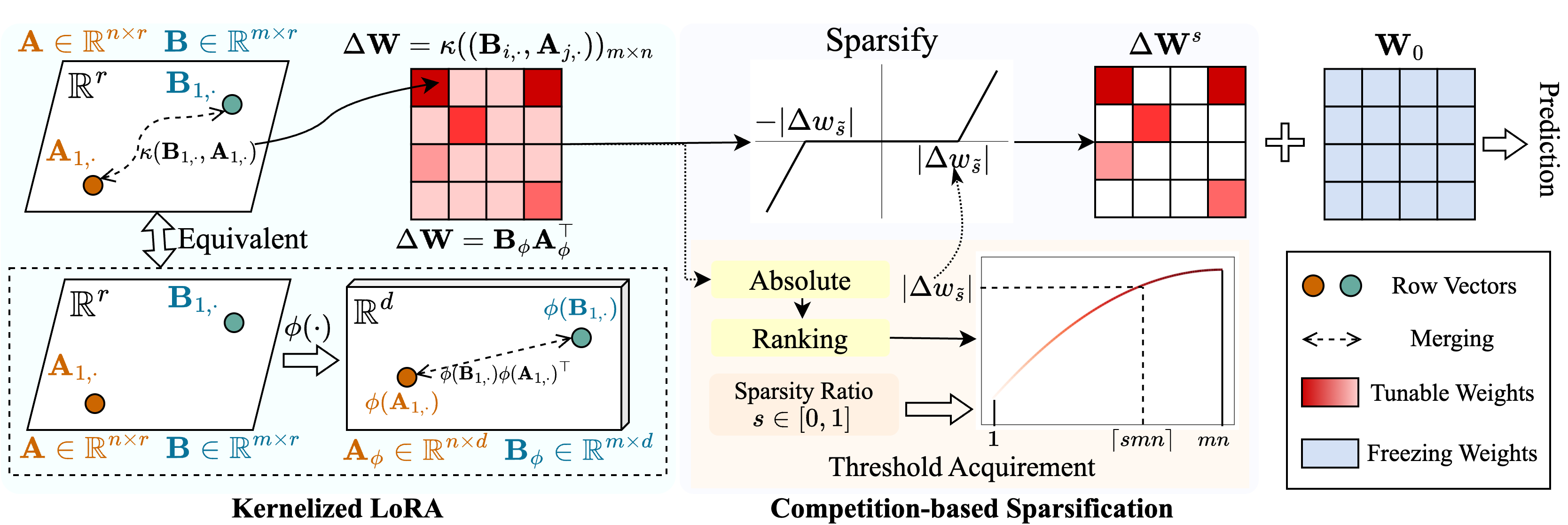
Propomos um método chamado Snell ( o ajuste de parse com o Ker Nel Ized L Ora) para permitir o ajuste esparso com baixo uso de memória. Snell decompõe a matriz ajustável para escarsificação em duas matrizes de baixo rank aprendidas, economizando do armazenamento caro da matriz completa original. Para manter a eficácia do ajuste esparso com matrizes de baixo rank, estendemos a decomposição de baixo rank da perspectiva do kernel. Especificamente, aplicamos funções de kernel não lineares à fusão da matriz completa e adquirimos um aumento na classificação da matriz mesclada. O empregado de classificações mais altas aumenta a capacidade do SNELL de otimizar o modelo pré-treinado escassamente para tarefas a jusante. Para reduzir ainda mais o uso de memória no ajuste esparso, introduzimos um mecanismo de escarsificação baseado em competição, evitando o armazenamento de índices de peso ajustáveis. Experiências extensas em várias tarefas a jusante mostram que o SNELL atinge o desempenho de ponta com baixo uso de memória, estendendo o PEFT eficaz com ajuste esparso a modelos em larga escala.
Se você achar esse repositório ou nosso artigo útil, considere citar e nos encarar!
@InProceedings{Shen_2024_SNELL,
title={Expanding Sparse Tuning for Low Memory Usage},
author={Shen, Shufan and Sun, Junshu and Ji, Xiangyang and Huang, Qingming and Wang, Shuhui},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2024}
}
./train.py : Execute este arquivo para treinamento../scripts : Scripts para adaptar modelos pré-treinados às tarefas a jusante com o Snell../lib : funções auxiliares para IO, loggings, treinamento e carregamento de dados../model : Arquiteturas e métodos de backbone para ajuste fino../engine.py : Funções principais de treinamento e avaliação../data : armazenando benchmarks FGVC e VTAB-1K.Clone este repo:
git clone https://github.com/ssfgunner/SNELL.git
cd SNELLCrie um ambiente virtual do CONDA e ative -o:
conda create -n snell python=3.8 -y
conda activate snell Instale torch==1.12.1 e torchvision==0.13.1 com CUDA==11.3 :
conda install pytorch==1.12.1 torchvision==0.13.1 cudatoolkit=11.3 -c pytorchInstale outras dependências:
pip install -r requirements.txt
FGVC: Faça o download dos conjuntos de dados após o VPT.
VTAB-1K: Como o processamento de alguns conjuntos de dados no benchmark VTAB original é complicado, recomendamos os conjuntos de dados VTAB-1K extraídos compartilhados pela SSF por conveniência. (Observe que a licença está no benchmark VTAB).
A estrutura do arquivo deve parecer:
data
├── fgvc
│ ├── cub
│ ├── nabirds
│ └── ...
└── vtab-1k
├── caltech101
├── cifar
└── ...mkdir checkpoints
cd checkpoints
# Supervisedly pre-trained ViT-B/16
wget https://console.cloud.google.com/storage/browser/_details/vit_models/imagenet21k/ViT-B_16.npz
# MAE pre-trained ViT-B/16
wget https://dl.fbaipublicfiles.com/mae/pretrain/mae_pretrain_vit_base.pth
# MoCo V3 pre-trained ViT-B/16
wget https://dl.fbaipublicfiles.com/moco-v3/vit-b-300ep/linear-vit-b-300ep.pth.tar
# Supervisedly pre-trained Swin-Transformer
wget https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22k.pth
# Supervisedly pre-trained ConvNeXt
wget https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_224.pthFornecemos scripts de treinamento para adaptar o VIT pré-treinado supervisionado ao FGVC e VTAB-1K com Snell-32, por exemplo:
# Fine-tuning supervised pre-trained ViT-B/16 with SNELL-32 for CUB dataset of FGVC
bash scripts/fgvc/snell32/vit_cub_snell.sh
# Fine-tuning supervised pre-trained ViT-B/16 with SNELL-32 for CIFAR dataset of VTAB-1k
bash scripts/vtab/snell32/vit_cifar_snell.shPara outros modelos, fornecemos scripts para ajustá-los no FGVC, por exemplo:
python train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=vit_base_patch16_224_in21k_snell --resume=checkpoints/mae_pretrain_vit_base.pth
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " ViT_MAE_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stagepython train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=vit_base_patch16_224_in21k_snell --resume=checkpoints/linear-vit-b-300ep.pth.tar
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " ViT_MoCo_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stagepython train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=swin_base_patch4_window7_224_in22k --resume=./checkpoints/swin_base_patch4_window7_224_22k.pth
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " Swin_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stagepython train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=convnext_base_in22k --resume=./checkpoints/convnext_base_22k_224.pth
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " ConvNeXt_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stageNosso código é modificado a partir de VPT, SSF e SPT. Agradecemos aos autores por seu código de código aberto.


