SNELL
1.0.0
이것은 우리 논문의 공식 구현입니다. 메모리 사용량이 낮은 스파 스 튜닝 확장.
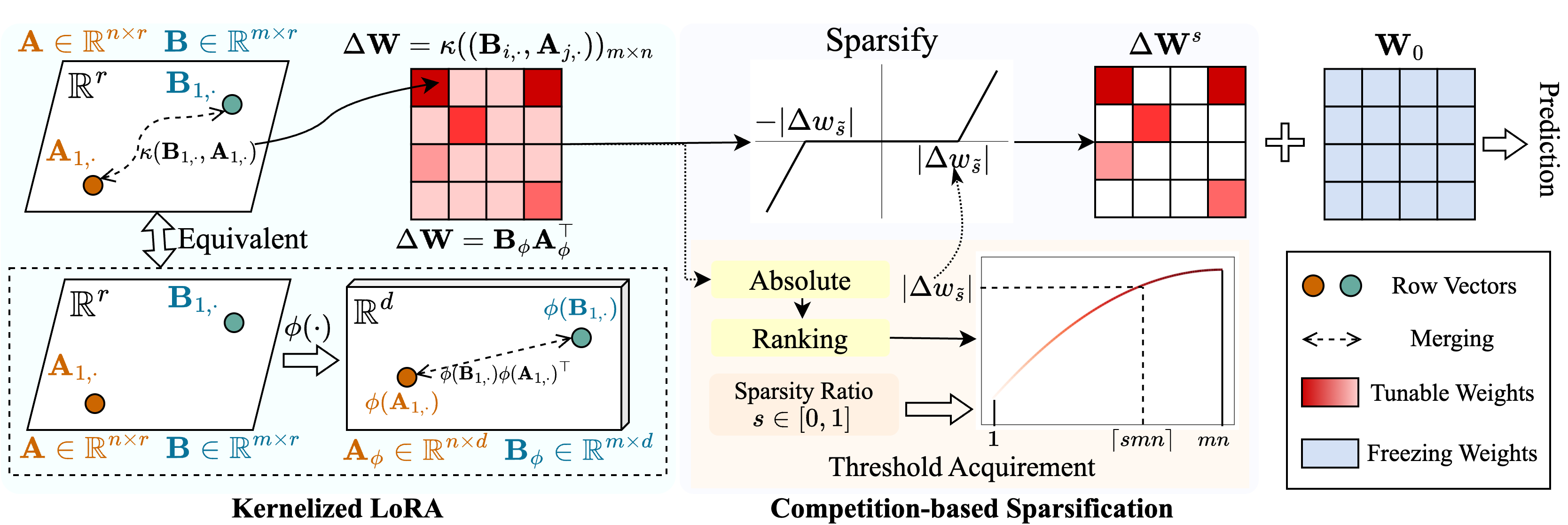
메모리 사용량이 낮은 스파 스 튜닝을 가능하게하기 위해 Snell ( Ker nel ized l ora를 사용한 구문 분석 튜닝)이라는 방법을 제안합니다. Snell은 피할 수있는 매트릭스를 두 개의 학습 가능한 저 순위 행렬로 분해하여 원래 전체 매트릭스의 비용이 많이 드는 저장에서 저장됩니다. 낮은 순위 행렬로 드문 튜닝의 효과를 유지하기 위해 커널 관점에서 저 순위 분해를 확장합니다. 구체적으로, 우리는 비선형 커널 함수를 전체 매트릭스 병합에 적용하고 병합 된 행렬의 순위가 증가합니다. 더 높은 순위를 사용하면 Snell이 사전 훈련 된 모델을 다운 스트림 작업에 대해 드물게 최적화 할 수있는 능력을 향상시킵니다. 드문 튜닝에서 메모리 사용량을 더욱 줄이기 위해 경쟁 기반 스파이즈 화 메커니즘을 소개하여 조정 가능한 무게 인덱스의 저장을 피합니다. 여러 다운 스트림 작업에 대한 광범위한 실험에 따르면 Snell은 메모리 사용이 적은 최첨단 성능을 달성하여 대규모 모델로 드문 튜닝을 통해 효과적인 PEFT를 확장합니다.
이 저장소 나 논문이 유용하다고 생각되면 우리를 인용하고 쳐다 보는 것을 고려하십시오!
@InProceedings{Shen_2024_SNELL,
title={Expanding Sparse Tuning for Low Memory Usage},
author={Shen, Shufan and Sun, Junshu and Ji, Xiangyang and Huang, Qingming and Wang, Shuhui},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2024}
}
./train.py : 교육을 위해이 파일을 실행하십시오../scripts : 미리 훈련 된 모델을 Snell을 사용하여 다운 스트림 작업에 적용하기위한 스크립트../lib : IO, 로깅, 교육 및 데이터 로딩의 헬퍼 기능../model : 백본 아키텍처 및 미세 조정 방법../engine.py : 주요 교육 및 평가 기능../data : FGVC 및 VTAB-1K 벤치 마크 저장.이 저장소를 복제하십시오.
git clone https://github.com/ssfgunner/SNELL.git
cd SNELL콘다 가상 환경을 만들고 활성화하십시오.
conda create -n snell python=3.8 -y
conda activate snell torch==1.12.1 및 torchvision==0.13.1 CUDA==11.3 설치하십시오.
conda install pytorch==1.12.1 torchvision==0.13.1 cudatoolkit=11.3 -c pytorch다른 종속성 설치 :
pip install -r requirements.txt
FGVC : VPT를 따라 데이터 세트를 다운로드하십시오.
VTAB-1K : 원래 VTAB 벤치 마크에서 일부 데이터 세트를 처리하는 것이 까다 롭기 때문에 편의를 위해 SSF가 공유하는 추출 된 VTAB-1K 데이터 세트를 권장합니다. (라이센스는 VTAB 벤치 마크에 있습니다).
파일 구조는 다음과 같아야합니다.
data
├── fgvc
│ ├── cub
│ ├── nabirds
│ └── ...
└── vtab-1k
├── caltech101
├── cifar
└── ...mkdir checkpoints
cd checkpoints
# Supervisedly pre-trained ViT-B/16
wget https://console.cloud.google.com/storage/browser/_details/vit_models/imagenet21k/ViT-B_16.npz
# MAE pre-trained ViT-B/16
wget https://dl.fbaipublicfiles.com/mae/pretrain/mae_pretrain_vit_base.pth
# MoCo V3 pre-trained ViT-B/16
wget https://dl.fbaipublicfiles.com/moco-v3/vit-b-300ep/linear-vit-b-300ep.pth.tar
# Supervisedly pre-trained Swin-Transformer
wget https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22k.pth
# Supervisedly pre-trained ConvNeXt
wget https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_224.pth예를 들어 SNELL-32를 사용하여 감독 된 미리 훈련 된 VIT를 FGVC 및 VTAB-1K에 적응하기위한 교육 스크립트를 제공했습니다.
# Fine-tuning supervised pre-trained ViT-B/16 with SNELL-32 for CUB dataset of FGVC
bash scripts/fgvc/snell32/vit_cub_snell.sh
# Fine-tuning supervised pre-trained ViT-B/16 with SNELL-32 for CIFAR dataset of VTAB-1k
bash scripts/vtab/snell32/vit_cifar_snell.sh다른 모델의 경우 FGVC에서 미세 조정을위한 스크립트를 제공합니다.
python train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=vit_base_patch16_224_in21k_snell --resume=checkpoints/mae_pretrain_vit_base.pth
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " ViT_MAE_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stagepython train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=vit_base_patch16_224_in21k_snell --resume=checkpoints/linear-vit-b-300ep.pth.tar
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " ViT_MoCo_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stagepython train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=swin_base_patch4_window7_224_in22k --resume=./checkpoints/swin_base_patch4_window7_224_22k.pth
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " Swin_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stagepython train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=convnext_base_in22k --resume=./checkpoints/convnext_base_22k_224.pth
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " ConvNeXt_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stage우리의 코드는 VPT, SSF 및 SPT에서 수정되었습니다. 오픈 소스 코드에 대해 저자에게 감사드립니다.


