SNELL
1.0.0
Dies ist die offizielle Implementierung unseres Papiers: Erweiterung der spärlichen Stimmung für den Nutzungsverbrauch mit geringem Speicher.
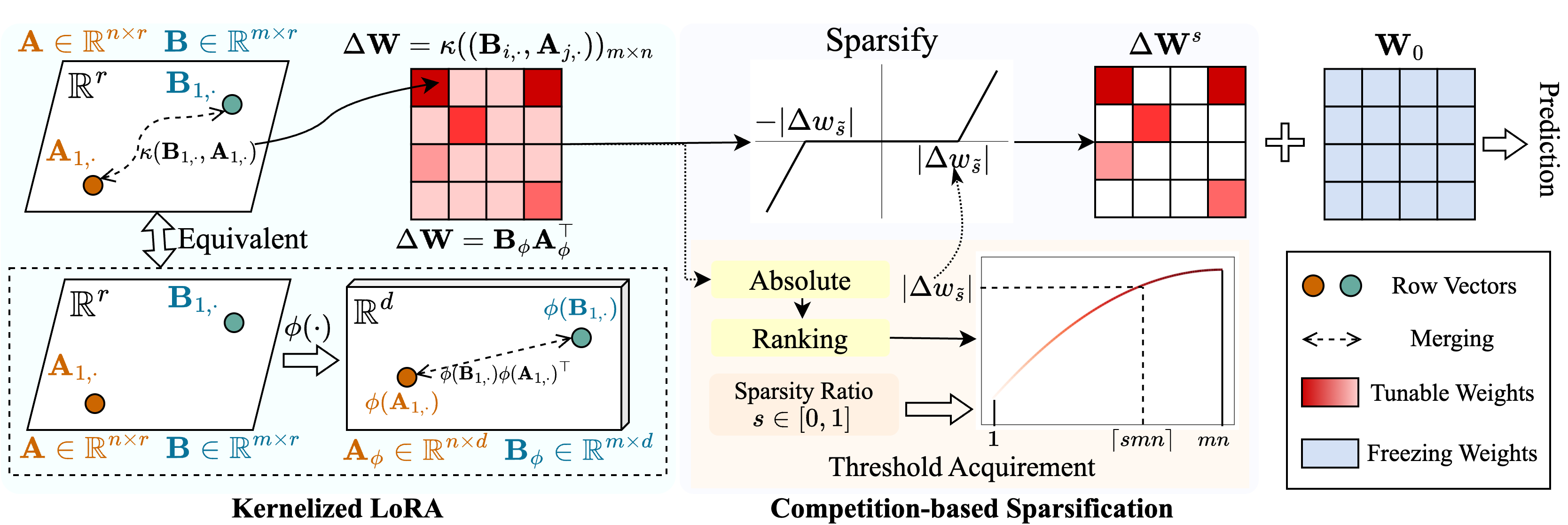
Wir schlagen eine Methode namens Snell ( s Parse Tuning mit ker nel ized l ora) vor, um eine spärliche Abstimmung mit geringem Speicherverbrauch zu ermöglichen. Snell zersetzt die einstellbare Matrix für die Sparsifikation in zwei lernbare niedrigrangige Matrizen und spart vor der kostspieligen Speicherung der ursprünglichen vollständigen Matrix. Um die Wirksamkeit einer spärlichen Abstimmung mit niedrigem Matrizen aufrechtzuerhalten, erweitern wir die Zersetzung mit niedriger Rang aus einer Kernelperspektive. Insbesondere wenden wir nichtlineare Kernelfunktionen auf die Full-Matrix-Verschmelzung an und erhöhen einen Anstieg des Ranges der zusammengeführten Matrix. Die Verwendung höherer Ränge verbessert die Fähigkeit von Snell, das vorgebrachte Modell spärlich für nachgeschaltete Aufgaben zu optimieren. Um den Speicherverbrauch bei spärlicher Abstimmung weiter zu verringern, führen wir einen wettbewerbsbasierten Sparifizierungsmechanismus ein und vermeiden die Speicherung eines einstellbaren Gewichtsindizes. Umfangreiche Experimente an mehreren nachgeschalteten Aufgaben zeigen, dass Snell eine modernste Leistung mit geringer Speicherverwendung erzielt und effektives PEFT mit spärlicher Stimmung auf groß angelegte Modelle erweitert.
Wenn Sie dieses Repository oder unser Papier nützlich finden, erwägen Sie uns bitte zu zitieren und zu starren!
@InProceedings{Shen_2024_SNELL,
title={Expanding Sparse Tuning for Low Memory Usage},
author={Shen, Shufan and Sun, Junshu and Ji, Xiangyang and Huang, Qingming and Wang, Shuhui},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2024}
}
./train.py : Führen Sie diese Datei für das Training aus../scripts./lib : Helferfunktionen für IO, Protokollierungen, Training und Datenbelastung../model : Backbone-Architekturen und -Methoden zur Feinabstimmung../engine.py : Haupttraining und Evalfunktionen../data : Speichern von FGVC- und VTAB-1K-Benchmarks.Klonen Sie dieses Repo:
git clone https://github.com/ssfgunner/SNELL.git
cd SNELLErstellen Sie eine virtuelle Konda -Umgebung und aktivieren Sie sie:
conda create -n snell python=3.8 -y
conda activate snell Installieren Sie torch==1.12.1 und torchvision==0.13.1 mit CUDA==11.3 :
conda install pytorch==1.12.1 torchvision==0.13.1 cudatoolkit=11.3 -c pytorchWeitere Abhängigkeiten installieren:
pip install -r requirements.txt
FGVC: Bitte laden Sie die Datensätze nach VPT herunter.
VTAB-1K: Da die Verarbeitung einiger Datensätze in Original-VTAB-Benchmark schwierig ist, empfehlen wir die extrahierten VTAB-1K-Datensätze, die von SSF für die Einfachheit angenommen wurden. (Beachten Sie, dass sich die Lizenz in VTAB -Benchmark befindet).
Die Dateistruktur sollte aussehen wie:
data
├── fgvc
│ ├── cub
│ ├── nabirds
│ └── ...
└── vtab-1k
├── caltech101
├── cifar
└── ...mkdir checkpoints
cd checkpoints
# Supervisedly pre-trained ViT-B/16
wget https://console.cloud.google.com/storage/browser/_details/vit_models/imagenet21k/ViT-B_16.npz
# MAE pre-trained ViT-B/16
wget https://dl.fbaipublicfiles.com/mae/pretrain/mae_pretrain_vit_base.pth
# MoCo V3 pre-trained ViT-B/16
wget https://dl.fbaipublicfiles.com/moco-v3/vit-b-300ep/linear-vit-b-300ep.pth.tar
# Supervisedly pre-trained Swin-Transformer
wget https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22k.pth
# Supervisedly pre-trained ConvNeXt
wget https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_224.pthWir haben Trainingsskripte zur Anpassung des vorgeschriebenen Vit an FGVC und VTAB-1K an Snell-32 zur Verfügung gestellt: beispielsweise mit Snell-32:
# Fine-tuning supervised pre-trained ViT-B/16 with SNELL-32 for CUB dataset of FGVC
bash scripts/fgvc/snell32/vit_cub_snell.sh
# Fine-tuning supervised pre-trained ViT-B/16 with SNELL-32 for CIFAR dataset of VTAB-1k
bash scripts/vtab/snell32/vit_cifar_snell.shFür andere Modelle stellen wir Skripte zur Verfügung, um sie beispielsweise auf FGVC zu optimieren:
python train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=vit_base_patch16_224_in21k_snell --resume=checkpoints/mae_pretrain_vit_base.pth
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " ViT_MAE_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stagepython train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=vit_base_patch16_224_in21k_snell --resume=checkpoints/linear-vit-b-300ep.pth.tar
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " ViT_MoCo_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stagepython train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=swin_base_patch4_window7_224_in22k --resume=./checkpoints/swin_base_patch4_window7_224_22k.pth
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " Swin_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stagepython train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=convnext_base_in22k --resume=./checkpoints/convnext_base_22k_224.pth
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " ConvNeXt_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stageUnser Code wird von VPT, SSF und SPT geändert. Wir danken den Autoren für ihren Open-Sourcing-Code.


