SNELL
1.0.0
これは、私たちの論文の公式の実装です。低いメモリ使用量のためのまばらなチューニングを拡大します。
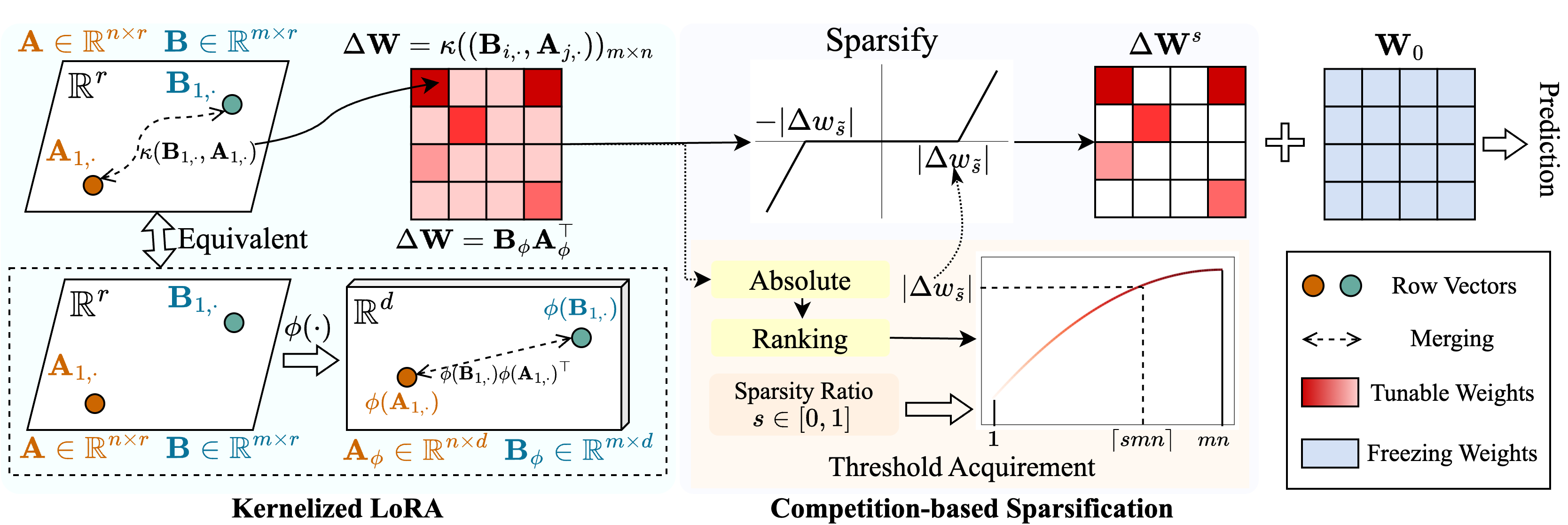
Snell( s Ker nel ized l oraを使用したParse Tuning)と呼ばれる方法を提案して、メモリ使用量が少ないまばらなチューニングを可能にします。 Snellは、調整可能なマトリックスを分解して、2つの学習可能な低ランクマトリックスにスパース化され、元のフルマトリックスの費用のかかるストレージから保存されます。低ランクマトリックスでスパースチューニングの有効性を維持するために、低ランク分解をカーネルの観点から拡張します。具体的には、非線形カーネル関数をフルマトリックスのマージに適用し、マージされたマトリックスのランクが増加します。より高いランクを採用すると、Snellの能力が向上し、下流タスクの事前に訓練されたモデルをまばらに最適化します。スパースチューニングでのメモリ使用量をさらに削減するために、調整可能な重量指数の保存を回避する競合ベースのスパース化メカニズムを導入します。複数の下流タスクに関する広範な実験は、Snellがメモリ使用量が少ない最先端のパフォーマンスを達成し、大規模なモデルにまばらなチューニングで効果的なPEFTを拡張することを示しています。
このリポジトリまたは私たちの論文が便利だと思う場合は、私たちを引用して見つめることを検討してください!
@InProceedings{Shen_2024_SNELL,
title={Expanding Sparse Tuning for Low Memory Usage},
author={Shen, Shufan and Sun, Junshu and Ji, Xiangyang and Huang, Qingming and Wang, Shuhui},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2024}
}
./train.py :トレーニングのためにこのファイルを実行します。./scripts :事前に訓練されたモデルをSnellを使用してダウンストリームタスクに適応させるためのスクリプト。./lib 、ロギング、トレーニング、およびデータロードのヘルパー機能。./model :微調整のためのバックボーンアーキテクチャと方法。./engine.py :メイントレーニングと評価機能。./dataおよびVTAB-1Kベンチマークの保存。このレポをクローンします:
git clone https://github.com/ssfgunner/SNELL.git
cd SNELLコンドラの仮想環境を作成してアクティブ化します。
conda create -n snell python=3.8 -y
conda activate snell torch==1.12.1およびtorchvision==0.13.1をCUDA==11.3にインストールします。
conda install pytorch==1.12.1 torchvision==0.13.1 cudatoolkit=11.3 -c pytorch他の依存関係をインストールします:
pip install -r requirements.txt
FGVC:VPTに続いてデータセットをダウンロードしてください。
VTAB-1K:元のVTABベンチマークでの一部のデータセットの処理は難しいため、便宜上、SSFが共有する抽出されたVTAB-1Kデータセットをお勧めします。 (ライセンスはVTABベンチマークにあることに注意してください)。
ファイル構造は次のように見えます。
data
├── fgvc
│ ├── cub
│ ├── nabirds
│ └── ...
└── vtab-1k
├── caltech101
├── cifar
└── ...mkdir checkpoints
cd checkpoints
# Supervisedly pre-trained ViT-B/16
wget https://console.cloud.google.com/storage/browser/_details/vit_models/imagenet21k/ViT-B_16.npz
# MAE pre-trained ViT-B/16
wget https://dl.fbaipublicfiles.com/mae/pretrain/mae_pretrain_vit_base.pth
# MoCo V3 pre-trained ViT-B/16
wget https://dl.fbaipublicfiles.com/moco-v3/vit-b-300ep/linear-vit-b-300ep.pth.tar
# Supervisedly pre-trained Swin-Transformer
wget https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22k.pth
# Supervisedly pre-trained ConvNeXt
wget https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_224.pth監視された事前に訓練されたVITをFGVCおよびVTAB-1Kにsnell-32に適応させるためのトレーニングスクリプトを提供しました。
# Fine-tuning supervised pre-trained ViT-B/16 with SNELL-32 for CUB dataset of FGVC
bash scripts/fgvc/snell32/vit_cub_snell.sh
# Fine-tuning supervised pre-trained ViT-B/16 with SNELL-32 for CIFAR dataset of VTAB-1k
bash scripts/vtab/snell32/vit_cifar_snell.sh他のモデルについては、たとえばFGVCで微調整するためのスクリプトを提供します。
python train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=vit_base_patch16_224_in21k_snell --resume=checkpoints/mae_pretrain_vit_base.pth
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " ViT_MAE_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stagepython train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=vit_base_patch16_224_in21k_snell --resume=checkpoints/linear-vit-b-300ep.pth.tar
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " ViT_MoCo_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stagepython train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=swin_base_patch4_window7_224_in22k --resume=./checkpoints/swin_base_patch4_window7_224_22k.pth
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " Swin_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stagepython train.py --data-path=./data/fgvc/ ${DATASET} --init_thres= ${init_thres}
--data-set= ${DATASET} --model_name=convnext_base_in22k --resume=./checkpoints/convnext_base_22k_224.pth
--output_dir= ${save_dir}
--batch-size= ${batch_size} --lr=0.001 --epochs=100 --weight-decay= ${WEIGHT_DECAY} --mixup=0 --cutmix=0
--smoothing=0 --launcher= " none " --seed=0 --val_interval=10 --opt=adamw --low_rank_dim=32
--exp_name= " ConvNeXt_ ${DATASET} " --seed=0
--test --block=BlockSNELLParallel --tuning_model=snell --freeze_stage私たちのコードは、VPT、SSF、およびSPTから変更されています。オープンソースのコードを著者に感謝します。


