muzero general
1.0.0
根據Google DeepMind論文(Schrittwieser等人,2019年11月)和相關的偽代碼進行了評論並記錄了Muzero的實施。它旨在為每個遊戲或強化學習環境(例如健身房)易於適應。您只需要與超參數和遊戲類添加遊戲文件。請參閱文檔和示例。該實施主要用於教育目的。
Muzero的解釋性視頻
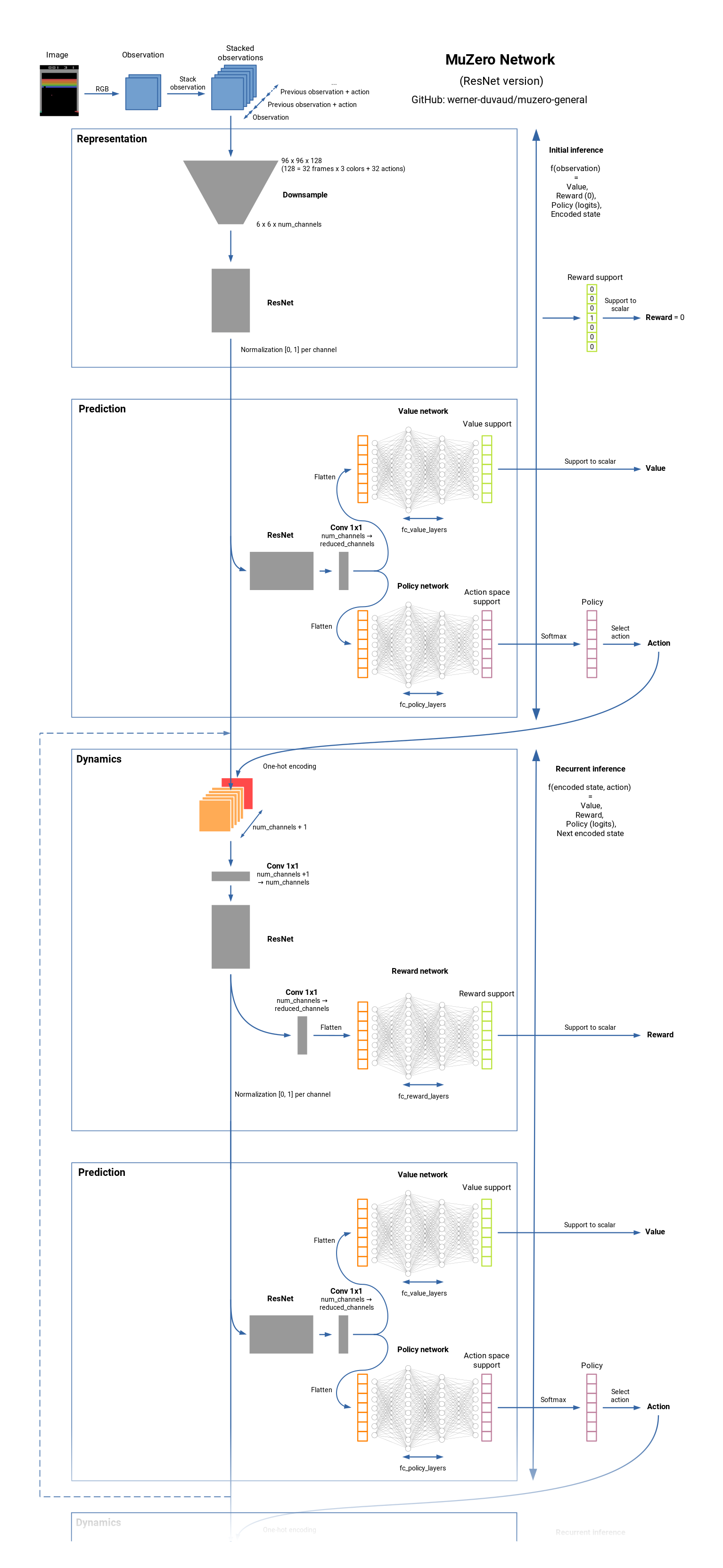
Muzero是棋盤遊戲(國際象棋,Go,...)和Atari Games的最先進的RL算法。它是Alphazero的繼任者,但在不了解動態的環境的任何知識中。 Muzero了解環境模型,並使用內部表示,該表示僅包含用於預測獎勵,價值,政策和過渡的有用信息。 Muzero也接近價值預測網絡。看看它的工作原理。
這是一系列功能列表,可能會添加有趣,但在Muzero的論文中不添加。我們願意做出貢獻和其他想法。
所有表演均在Tensorboard中實時跟踪和顯示:
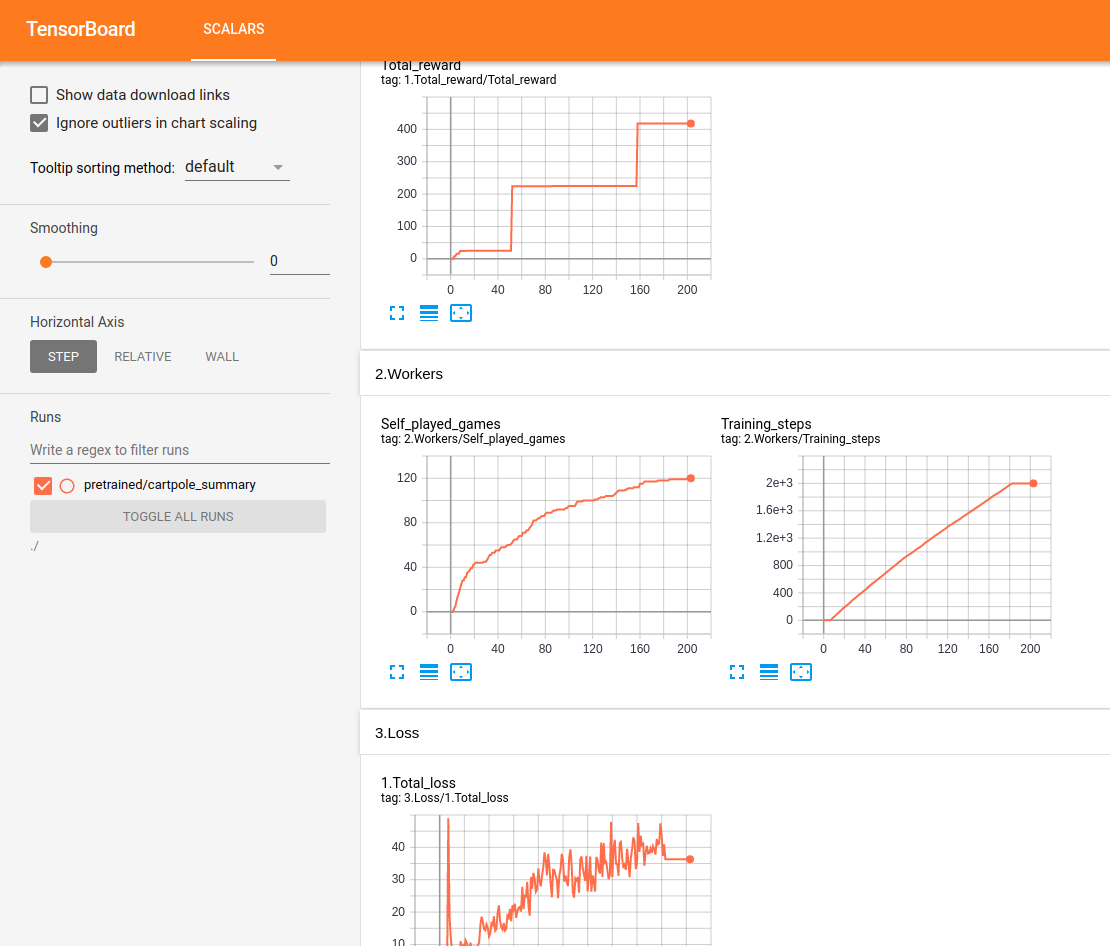
測試Lunar Lander:
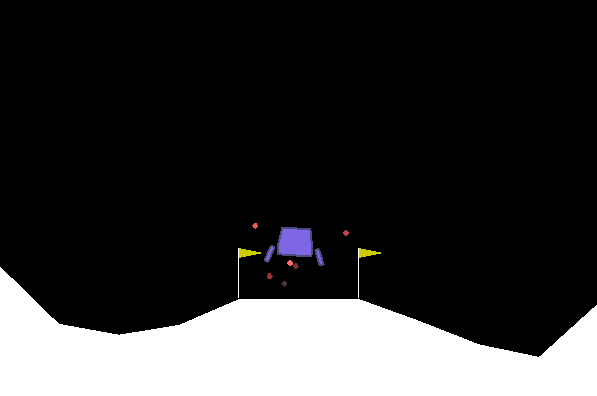
通過16 GB RAM / Intel I7 / GTX 1050TI Max-Q在Ubuntu上進行測試。我們確保獲得一個進步和一個確保其學到的水平。但是我們沒有系統地達到人類水平。對於某些環境,我們注意到一定時間後的回歸。所提出的配置當然不是最佳的,我們現在不集中精力進行超參數的優化。歡迎任何幫助。
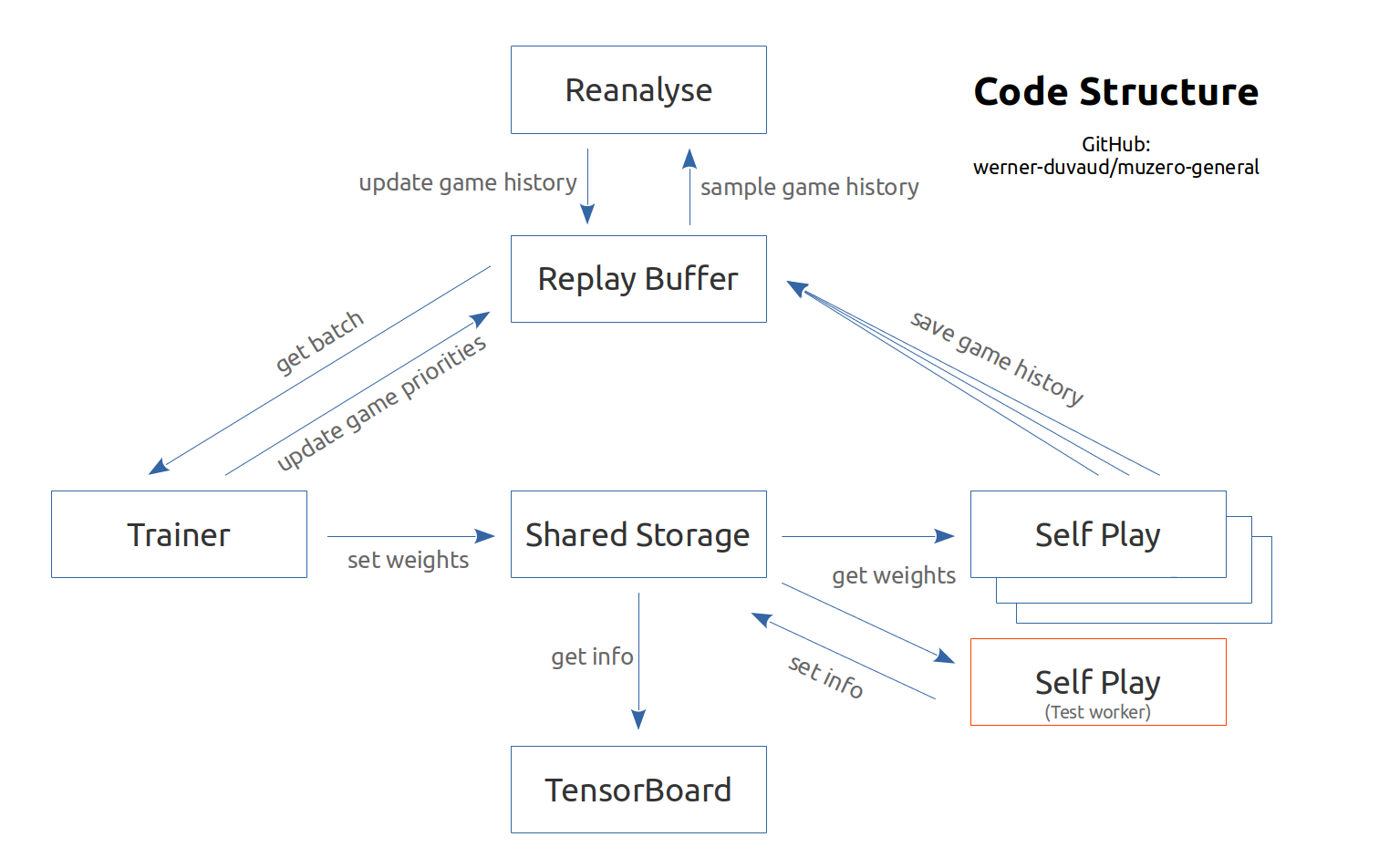
網絡摘要:
git clone https://github.com/werner-duvaud/muzero-general.git
cd muzero-general
pip install -r requirements.lockpython muzero.py為了可視化訓練結果,請在新的終端中運行:
tensorboard --logdir ./results您可以通過編輯遊戲文件夾中各個文件的MuZeroConfig類來調整每個遊戲的配置。
如果您想在出版物中引用此存儲庫(主分支),請使用此Bibtex:
@misc{muzero-general,
author = {Werner Duvaud, Aurèle Hainaut},
title = {MuZero General: Open Reimplementation of MuZero},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { u rl{https://github.com/werner-duvaud/muzero-general}},
}

