muzero general
1.0.0
Google Deepmind Paper (Schrittwieser et al., 2019 년 11 월) 및 관련 의사 코드를 기반으로 Muzero의 주석 및 문서화 구현. 모든 게임이나 강화 학습 환경 (체육관)에 쉽게 적응할 수 있도록 설계되었습니다. 하이퍼 파라미터 및 게임 클래스와 함께 게임 파일 만 추가하면됩니다. 문서와 예제를 참조하십시오. 이 구현은 주로 교육 목적을위한 것입니다.
Muzero의 설명 비디오
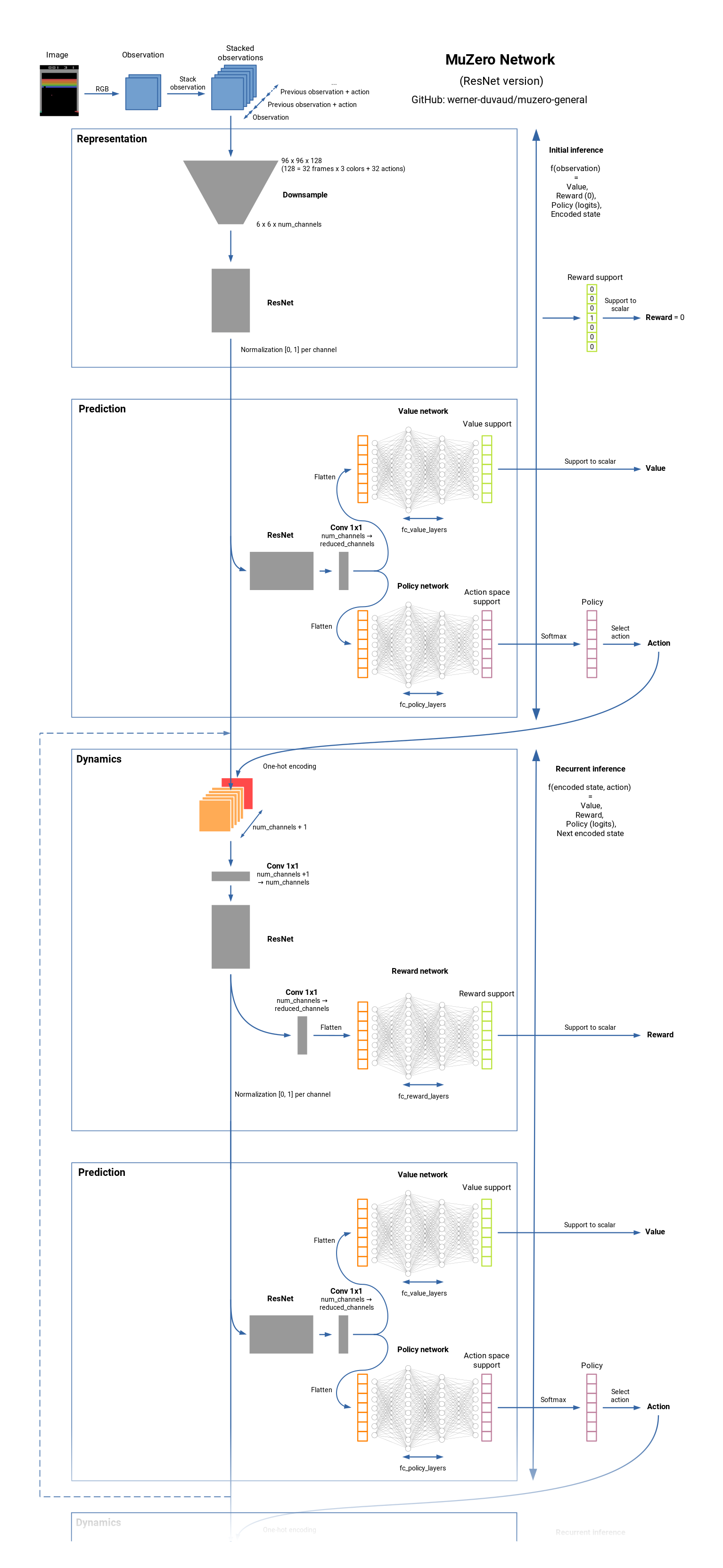
Muzero는 보드 게임 (Chess, Go, ...) 및 Atari Games 용 Art RL 알고리즘의 최첨단입니다. 그것은 Alphazero의 후계자이지만 역학의 근본적인 환경에 대한 지식은 없습니다. Muzero는 환경 모델을 배우고 보상, 가치, 정책 및 전환을 예측하는 데 유용한 정보 만 포함하는 내부 표현을 사용합니다. Muzero는 또한 가치 예측 네트워크에 가깝습니다. 그것이 어떻게 작동하는지보십시오.
다음은 추가하기가 흥미롭지 만 Muzero의 논문에 있지 않은 기능 목록입니다. 우리는 기여와 다른 아이디어에 개방적입니다.
모든 공연은 Tensorboard에서 실시간으로 추적 및 표시됩니다.
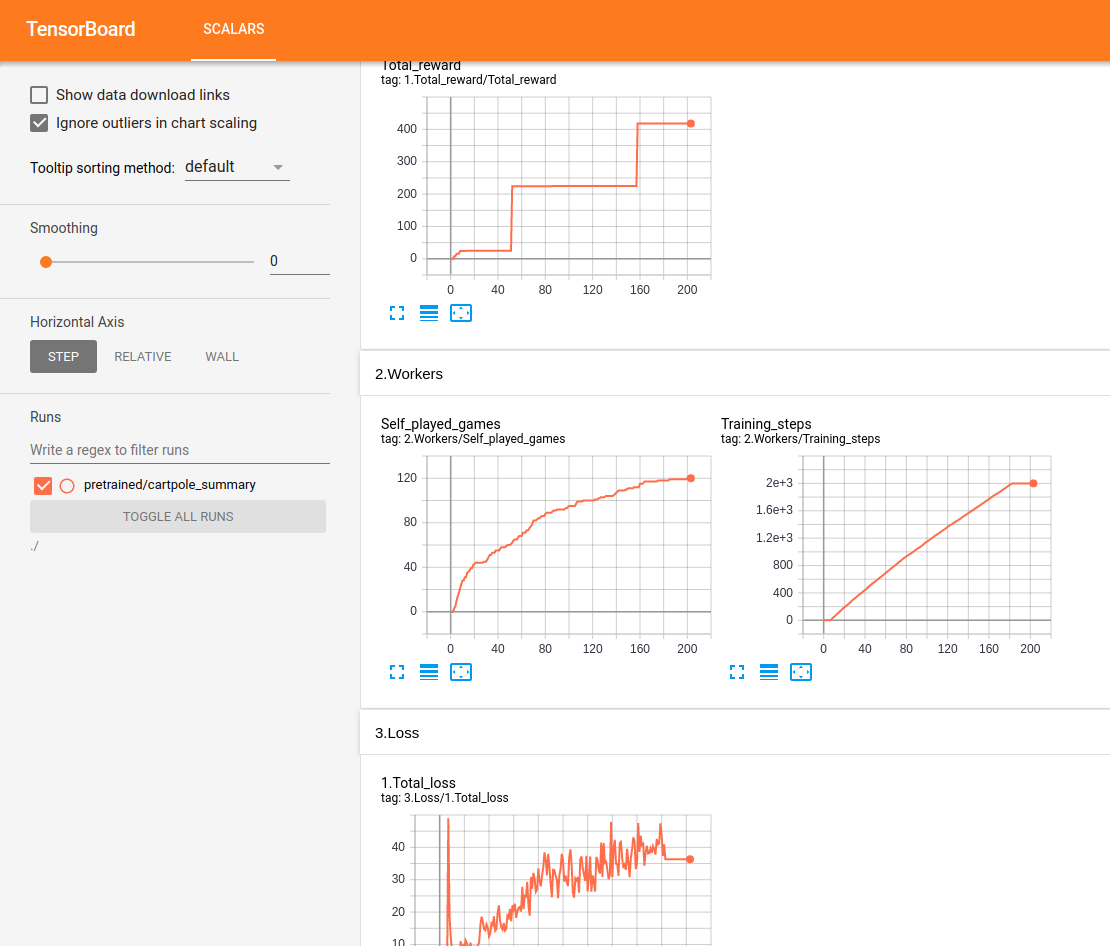
음력 테스트 :
테스트는 16GB RAM / Intel I7 / GTX 1050Ti Max-Q로 Ubuntu에서 수행됩니다. 우리는 진행과 수준을 얻는 수준을 얻습니다. 그러나 우리는 체계적으로 인간 수준에 도달하지 않습니다. 특정 환경의 경우 특정 시간 후에 회귀가 나타납니다. 제안 된 구성은 확실히 최적이 아니며, 우리는 현재 과복가의 최적화에 초점을 맞추지 않습니다. 모든 도움을 환영합니다.
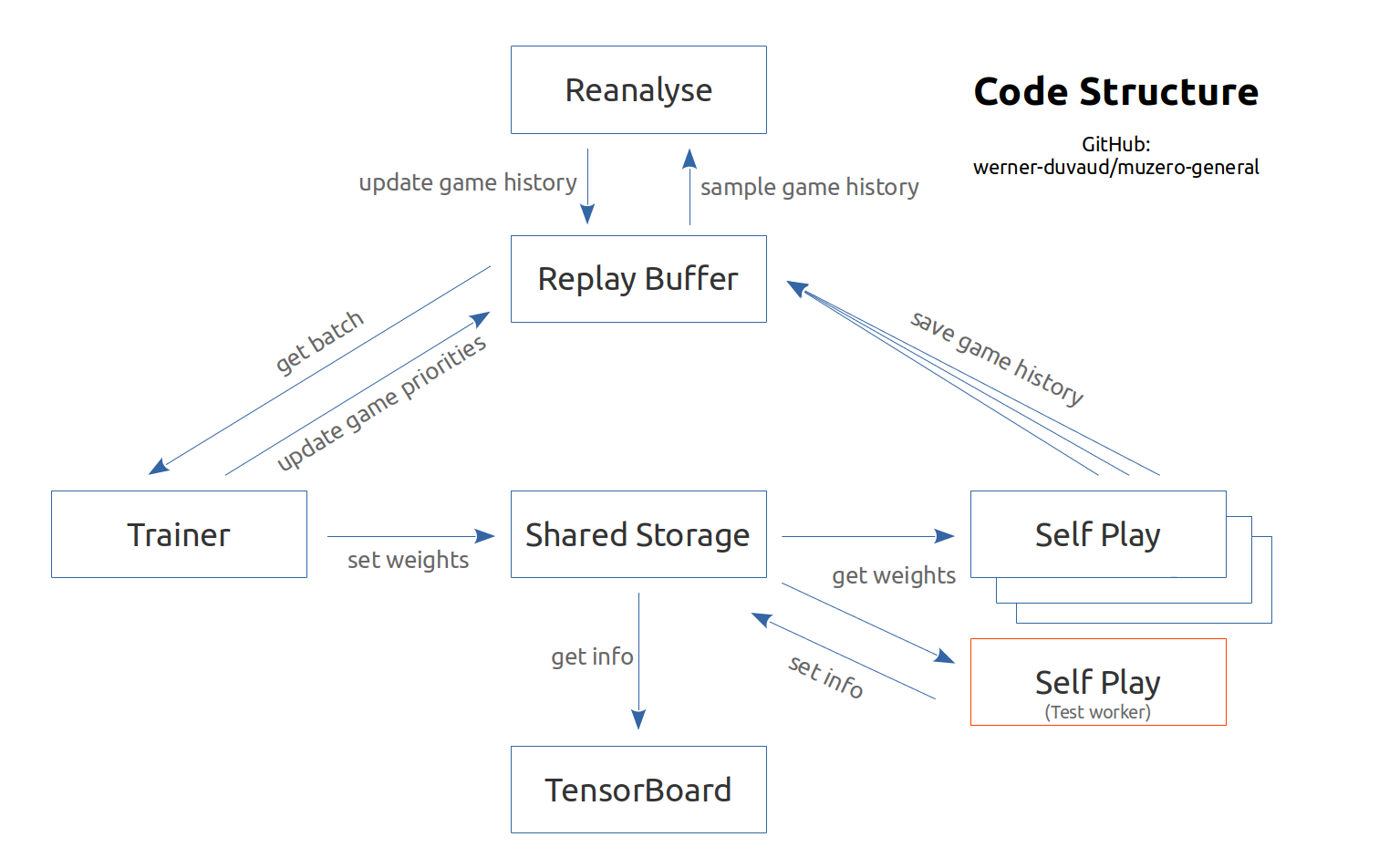
네트워크 요약 :
git clone https://github.com/werner-duvaud/muzero-general.git
cd muzero-general
pip install -r requirements.lockpython muzero.py교육 결과를 시각화하려면 새로운 터미널에서 실행하십시오.
tensorboard --logdir ./results 게임 폴더에서 각 파일의 MuZeroConfig 클래스를 편집하여 각 게임의 구성을 조정할 수 있습니다.
출판물 에서이 저장소 (마스터 브랜치)를 인용하려면이 Bibtex를 사용하십시오.
@misc{muzero-general,
author = {Werner Duvaud, Aurèle Hainaut},
title = {MuZero General: Open Reimplementation of MuZero},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { u rl{https://github.com/werner-duvaud/muzero-general}},
}

