muzero general
1.0.0
تنفيذ معلق وموثق لـ Muzero استنادًا إلى ورقة Google DeepMind (Schrittwieser et al. ، نوفمبر 2019) والرمز الكاذب المرتبط به. إنه مصمم ليكون قابلاً للتكيف بسهولة مع كل الألعاب أو بيئات التعلم التعزيز (مثل الصالة الرياضية). تحتاج فقط إلى إضافة ملف لعبة مع المقاييس الفائقة وفئة اللعبة. يرجى الرجوع إلى الوثائق والمثال. هذا التنفيذ هو في المقام الأول للأغراض التعليمية.
فيديو توضيحي لموزيرو
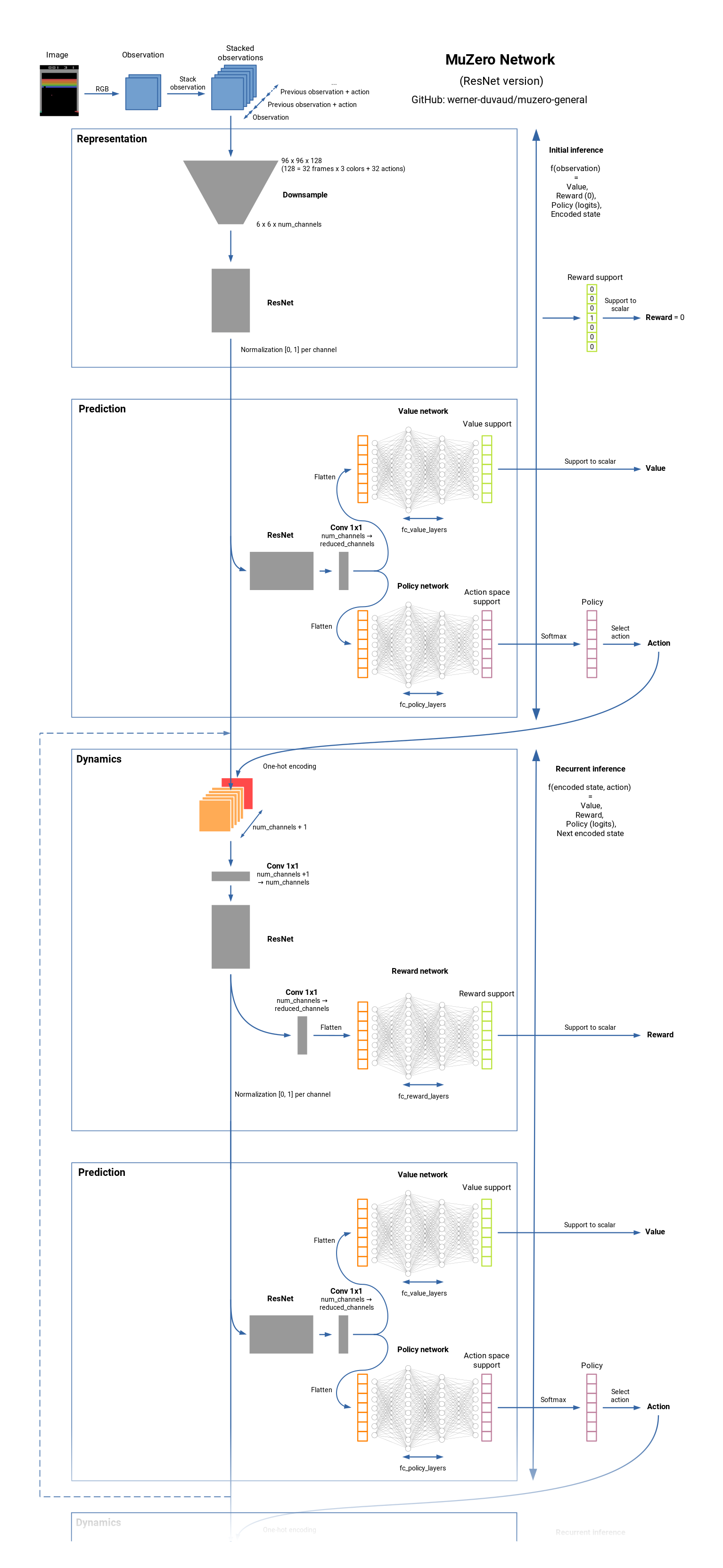
Muzero هي خوارزمية على أحدث طراز RL لألعاب الطاولة (لعبة الشطرنج ، GO ، ...) وأتاري ألعاب. إنه خليفة ألفازيرو ولكن دون أي معرفة بالبيئة الكامنة وراء الديناميات. يتعلم Muzero نموذجًا للبيئة ويستخدم تمثيلًا داخليًا يحتوي فقط على المعلومات المفيدة للتنبؤ بالمكافأة والقيمة والسياسة والتحولات. Muzero قريب أيضًا من شبكات التنبؤ بالقيمة. انظر كيف يعمل.
فيما يلي قائمة بالميزات التي قد تكون مثيرة للاهتمام لإضافتها ولكنها ليست في ورقة Muzero. نحن منفتحون على المساهمات والأفكار الأخرى.
يتم تتبع جميع العروض وعرضها في الوقت الفعلي في Tensorboard:
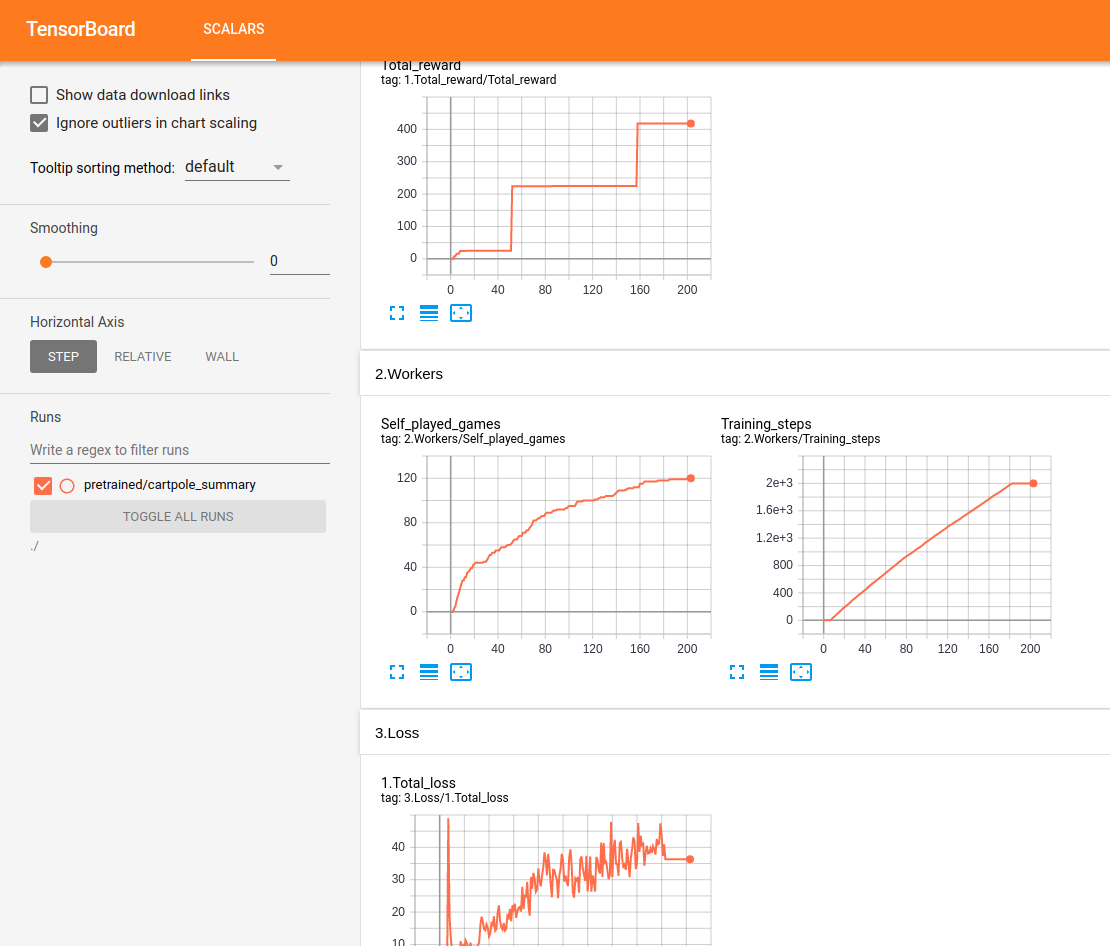
اختبار Lunar Lander:
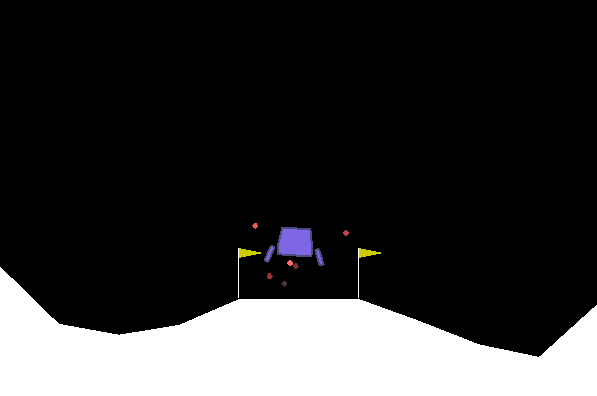
تتم الاختبارات على Ubuntu مع ذاكرة الوصول العشوائي 16 جيجابايت / Intel I7 / GTX 1050TI MAX-Q. نتأكد من الحصول على تقدم ومستوى يضمن أنه تعلم. لكننا لا نصل بشكل منهجي إلى مستوى بشري. بالنسبة لبيئات معينة ، نلاحظ الانحدار بعد وقت معين. التكوينات المقترحة ليست مثالية بالتأكيد ولا نركز في الوقت الحالي على تحسين المقاييس المفرطة. أي مساعدة موضع ترحيب.
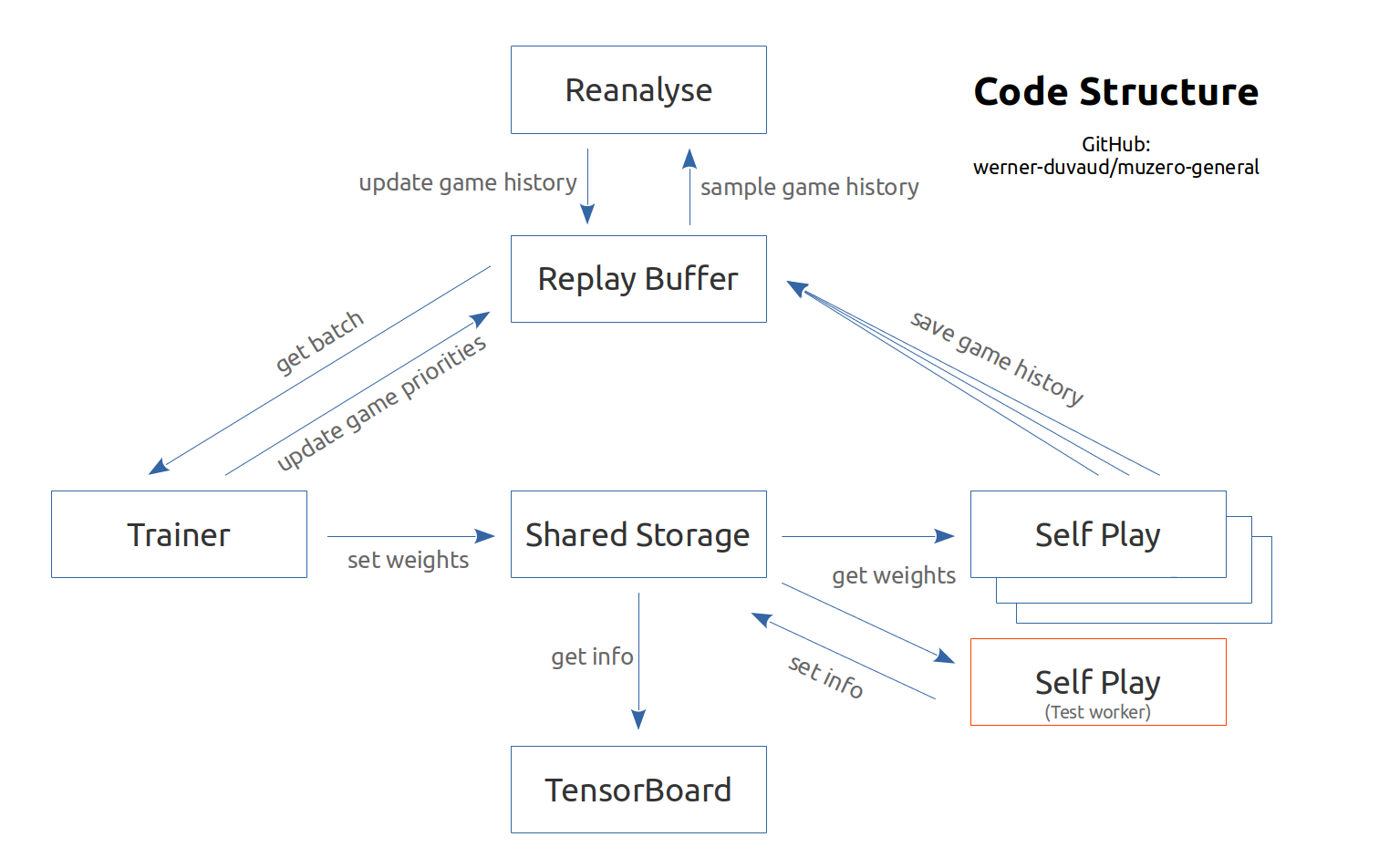
ملخص الشبكة:
git clone https://github.com/werner-duvaud/muzero-general.git
cd muzero-general
pip install -r requirements.lockpython muzero.pyلتصور نتائج التدريب ، قم بالتشغيل في محطة جديدة:
tensorboard --logdir ./results يمكنك تكييف تكوينات كل لعبة عن طريق تحرير فئة MuZeroConfig للملف المعني في مجلد الألعاب.
يرجى استخدام هذا bibtex إذا كنت تريد الاستشهاد بهذا المستودع (الفرع الرئيسي) في منشوراتك:
@misc{muzero-general,
author = {Werner Duvaud, Aurèle Hainaut},
title = {MuZero General: Open Reimplementation of MuZero},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { u rl{https://github.com/werner-duvaud/muzero-general}},
}

