muzero general
1.0.0
根据Google DeepMind论文(Schrittwieser等人,2019年11月)和相关的伪代码进行了评论并记录了Muzero的实施。它旨在为每个游戏或强化学习环境(例如健身房)易于适应。您只需要与超参数和游戏类添加游戏文件。请参阅文档和示例。该实施主要用于教育目的。
Muzero的解释性视频
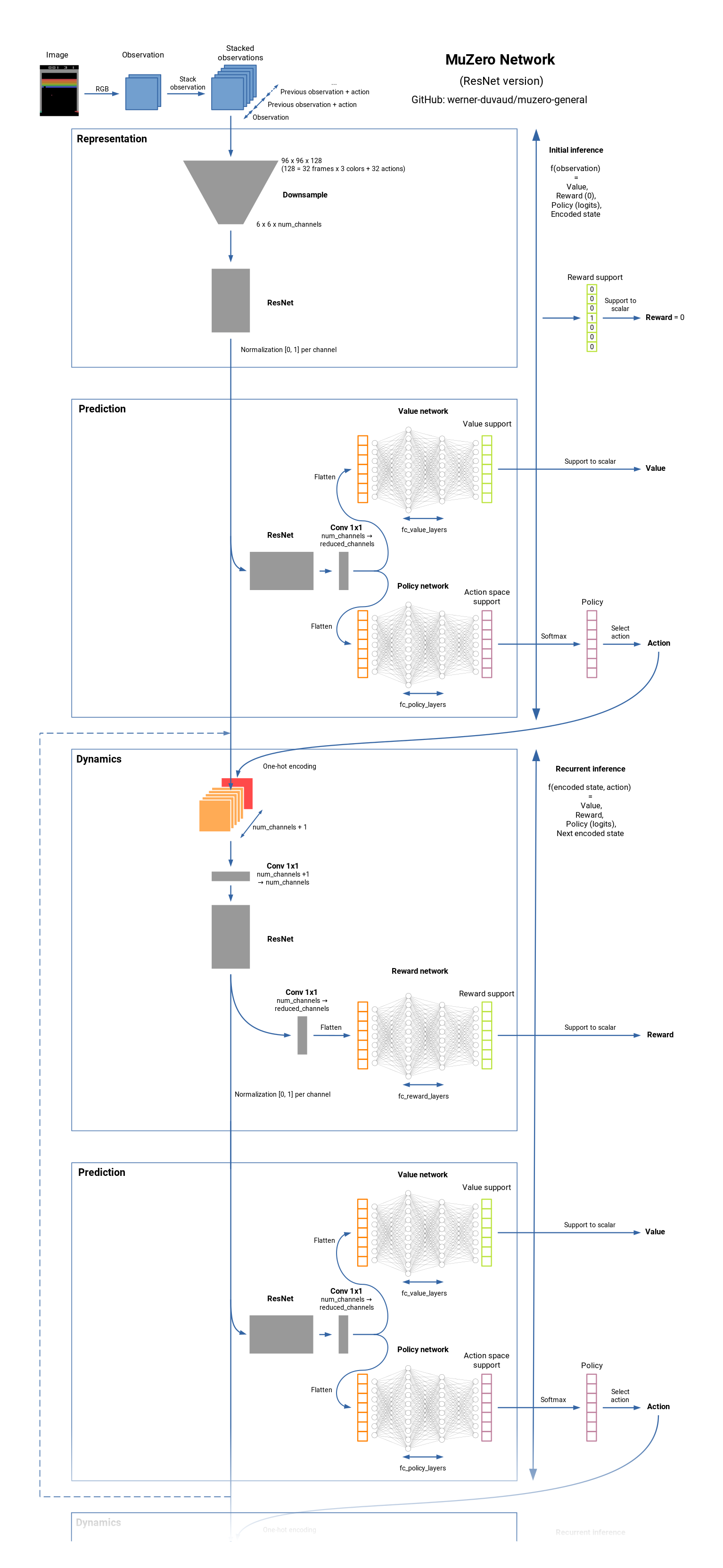
Muzero是棋盘游戏(国际象棋,Go,...)和Atari Games的最先进的RL算法。它是Alphazero的继任者,但在不了解动态的环境的任何知识中。 Muzero了解环境模型,并使用内部表示,该表示仅包含用于预测奖励,价值,政策和过渡的有用信息。 Muzero也接近价值预测网络。看看它的工作原理。
这是一系列功能列表,可能会添加有趣,但在Muzero的论文中不添加。我们愿意做出贡献和其他想法。
所有表演均在Tensorboard中实时跟踪和显示:
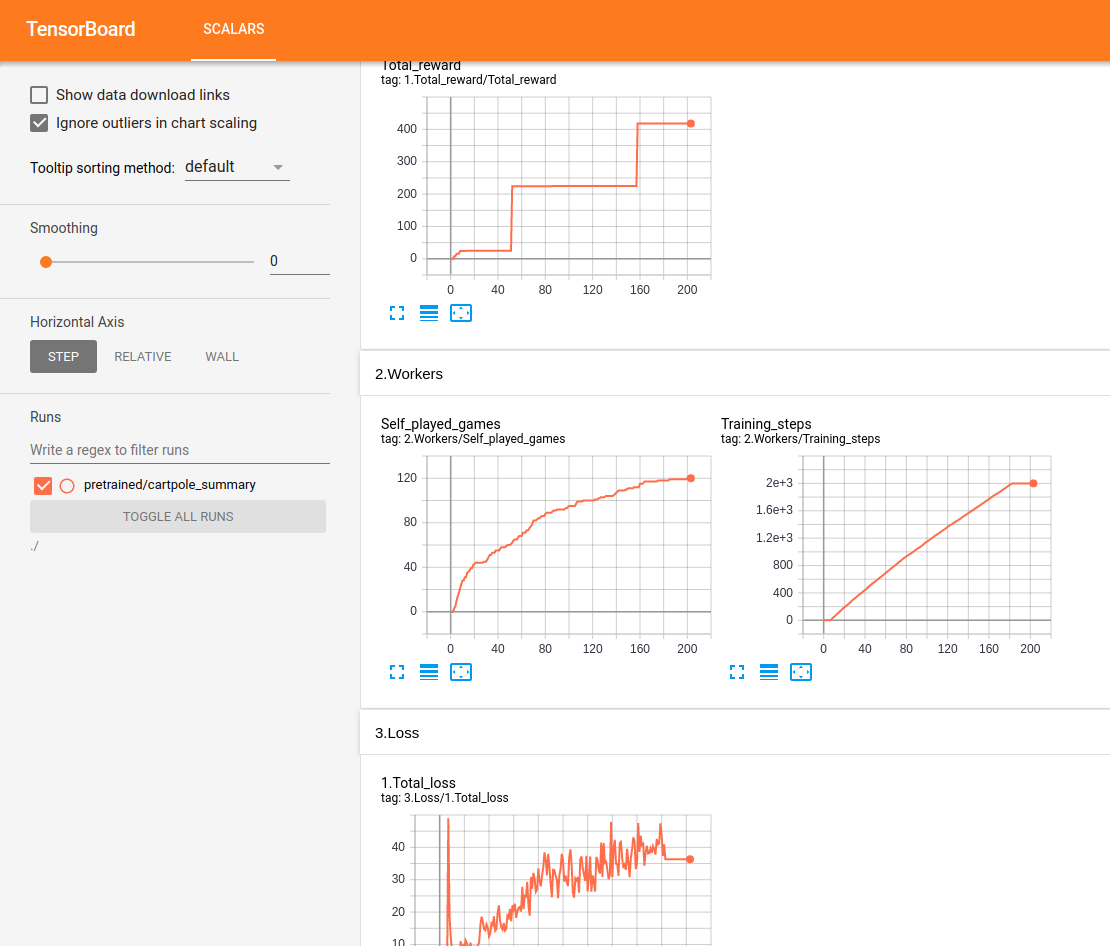
测试Lunar Lander:
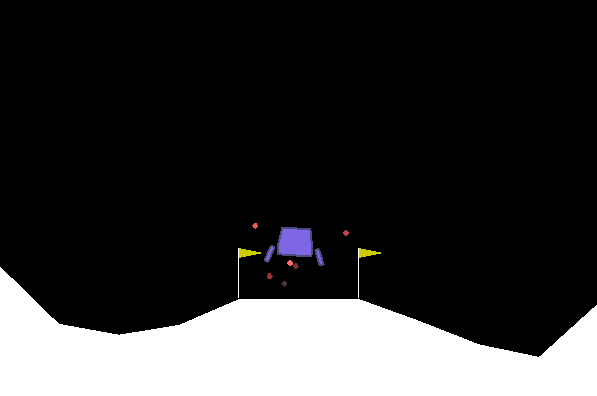
通过16 GB RAM / Intel I7 / GTX 1050TI Max-Q在Ubuntu上进行测试。我们确保获得一个进步和一个确保其学到的水平。但是我们没有系统地达到人类水平。对于某些环境,我们注意到一定时间后的回归。所提出的配置当然不是最佳的,我们现在不集中精力进行超参数的优化。欢迎任何帮助。
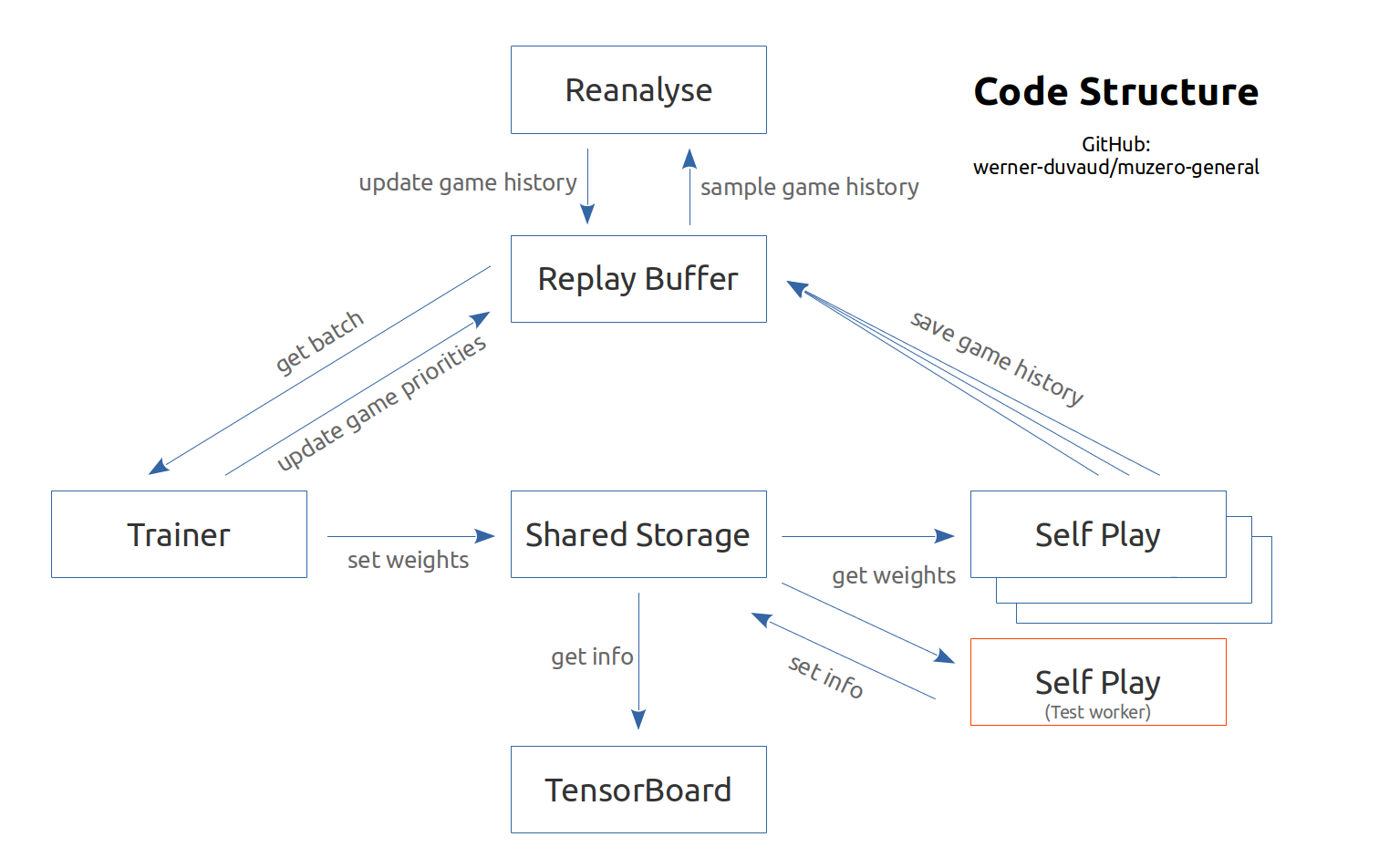
网络摘要:
git clone https://github.com/werner-duvaud/muzero-general.git
cd muzero-general
pip install -r requirements.lockpython muzero.py为了可视化训练结果,请在新的终端中运行:
tensorboard --logdir ./results您可以通过编辑游戏文件夹中各个文件的MuZeroConfig类来调整每个游戏的配置。
如果您想在出版物中引用此存储库(主分支),请使用此Bibtex:
@misc{muzero-general,
author = {Werner Duvaud, Aurèle Hainaut},
title = {MuZero General: Open Reimplementation of MuZero},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { u rl{https://github.com/werner-duvaud/muzero-general}},
}

