muzero general
1.0.0
Google Deepmind Paper(Schrittwieser et al。、2019年11月)および関連する擬似コードに基づいて、Muzeroのコメントと文書化された実装。すべてのゲームや強化学習環境(ジムなど)に簡単に適応できるように設計されています。ハイパーパラメーターとゲームクラスを使用してゲームファイルを追加するだけです。ドキュメントと例を参照してください。この実装は主に教育目的のためのものです。
Muzeroの説明ビデオ
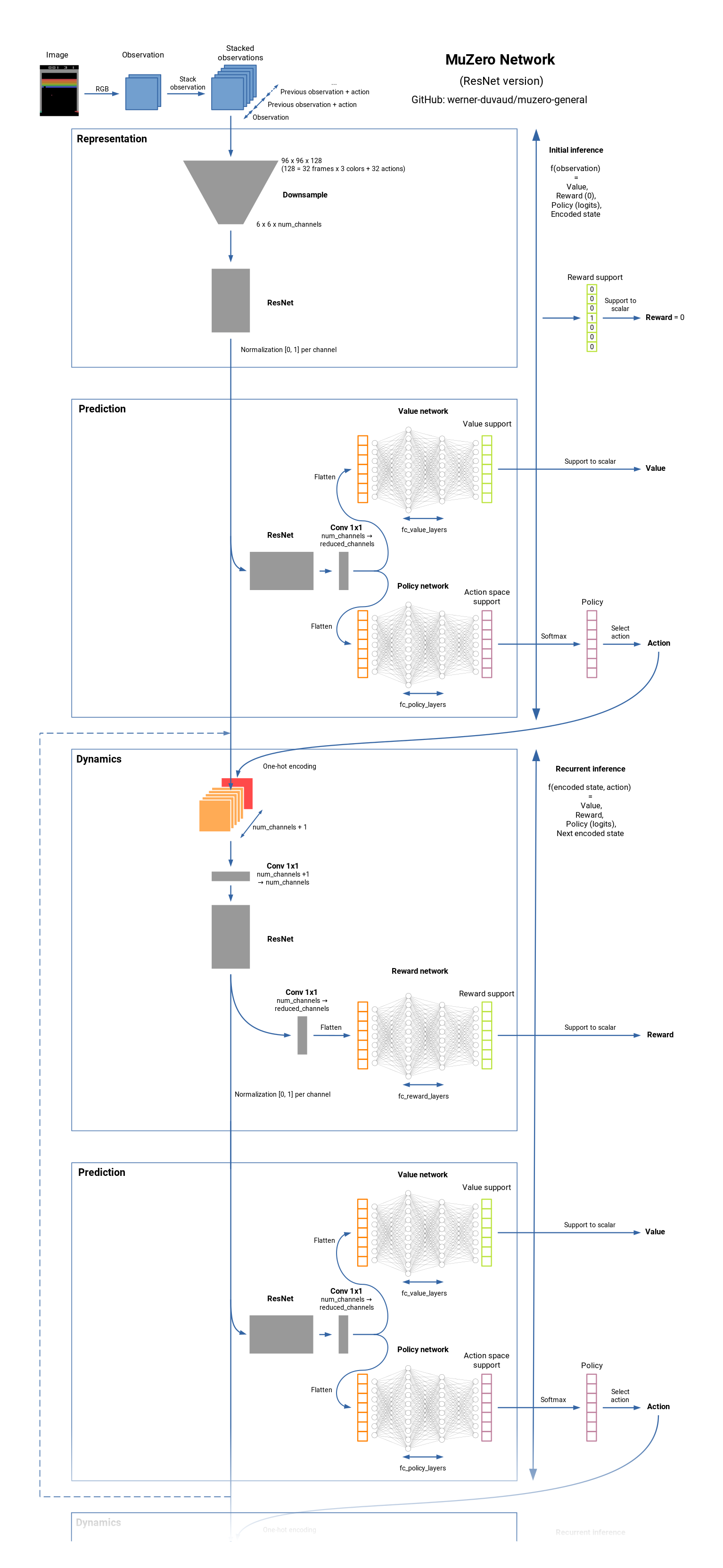
Muzeroは、ボードゲーム(Chess、Go、...)およびAtari Gamesの最先端のRLアルゴリズムです。それはアルファゼロの後継者ですが、ダイナミクスの根底にある環境に関する知識はありません。 Muzeroは、環境のモデルを学習し、報酬、価値、ポリシー、および移行を予測するための有用な情報のみを含む内部表現を使用します。 Muzeroは、値予測ネットワークにも近い。それがどのように機能するかを見てください。
これは、追加するのが興味深いが、Muzeroの論文にはない機能のリストです。私たちは貢献やその他のアイデアを受け入れています。
すべてのパフォーマンスは、テンソルボードでリアルタイムで追跡および表示されます。
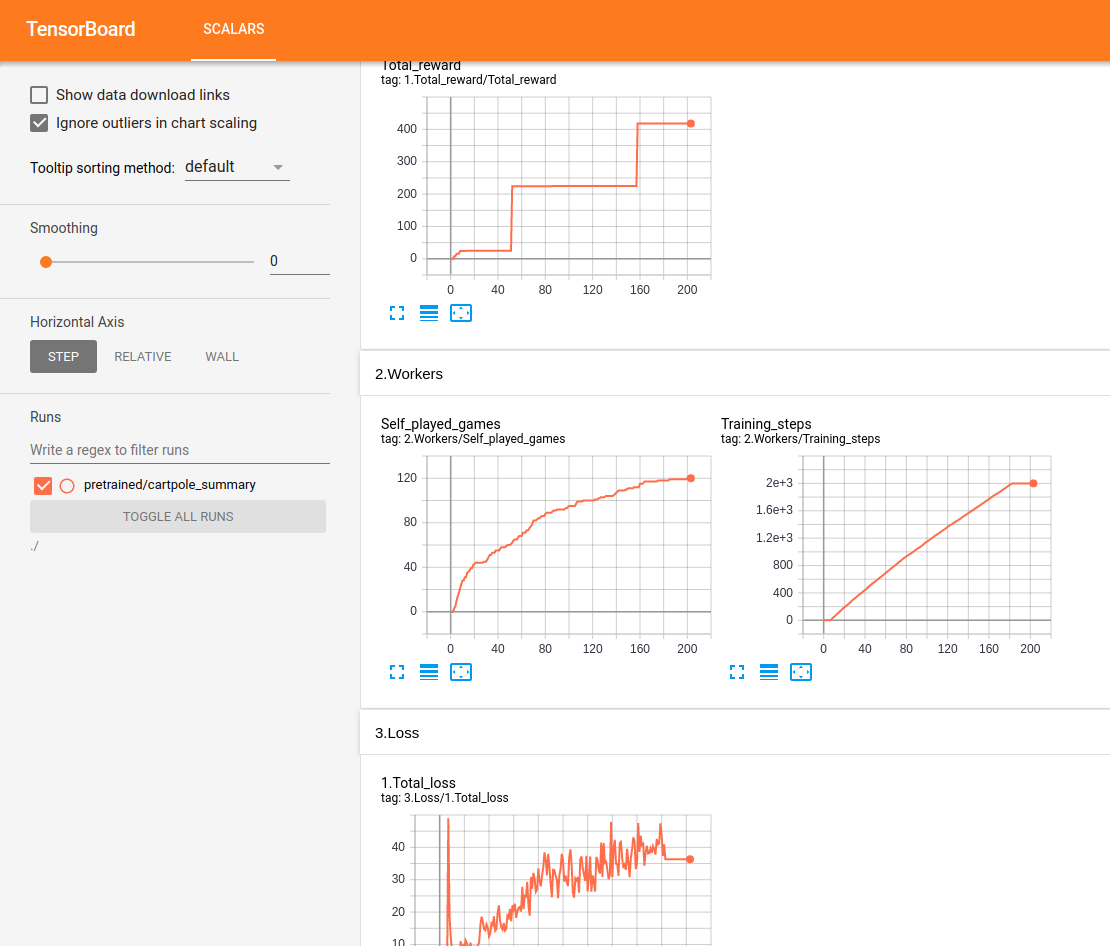
Lunar Landerのテスト:
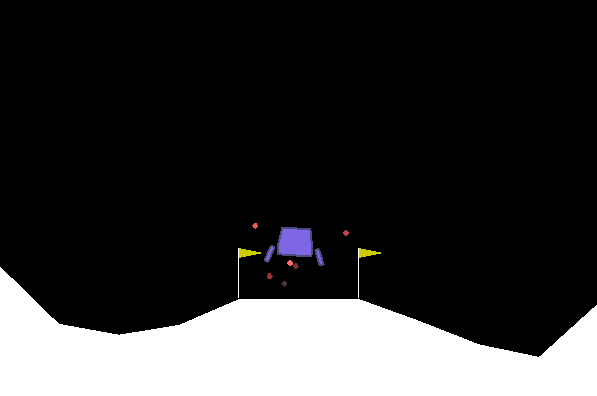
16 GB RAM / Intel I7 / GTX 1050TI MAX-QでUbuntuでテストが行われます。私たちは、それが学習したことを保証する進行とレベルを必ず取得するようにします。しかし、私たちは体系的に人間レベルに到達しません。特定の環境では、特定の時間後に回帰に気付きます。提案された構成は確かに最適ではなく、今のところハイパーパラメーターの最適化に焦点を合わせていません。どんな助けも大歓迎です。
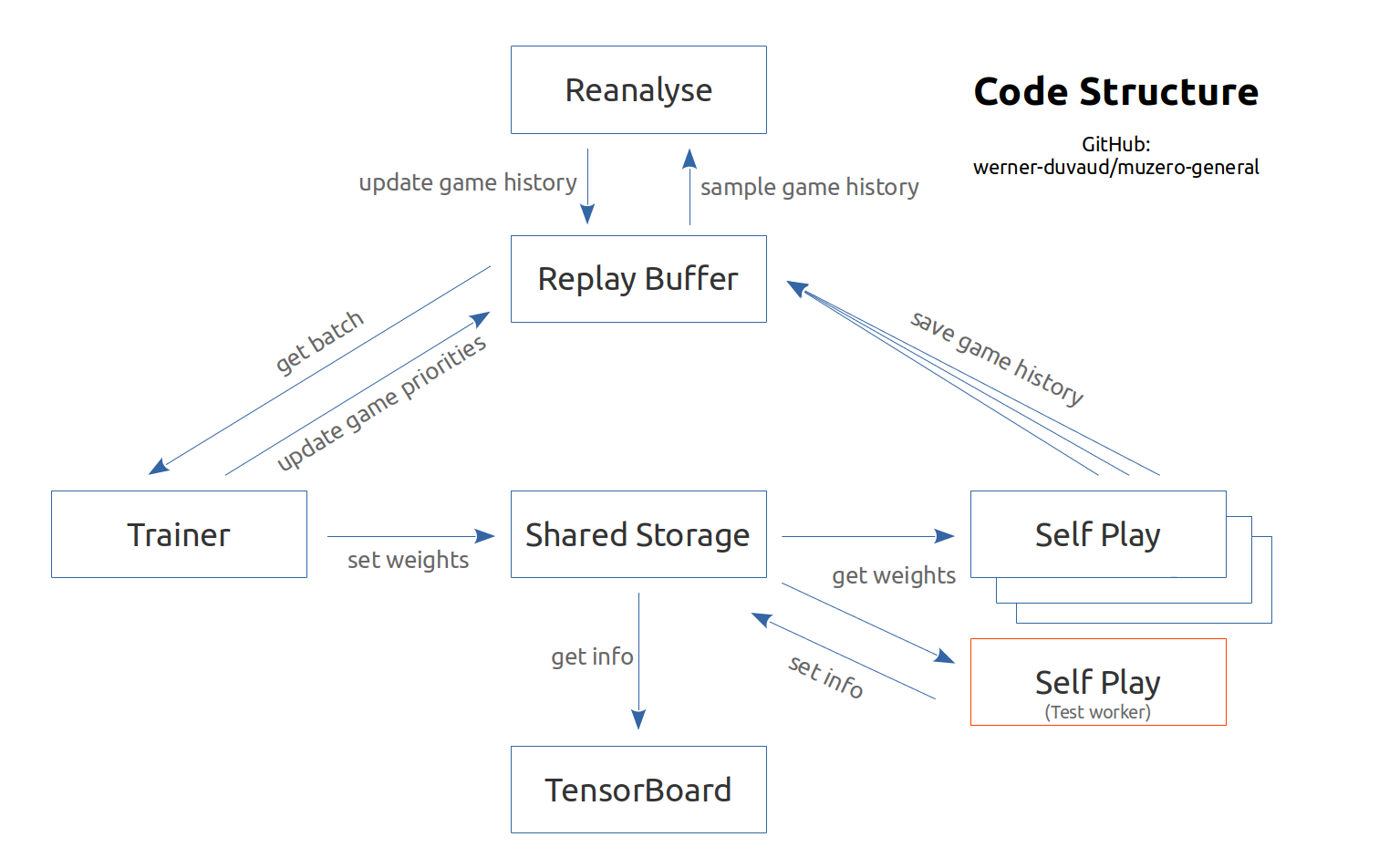
ネットワークの概要:
git clone https://github.com/werner-duvaud/muzero-general.git
cd muzero-general
pip install -r requirements.lockpython muzero.pyトレーニング結果を視覚化するには、新しいターミナルで実行します。
tensorboard --logdir ./resultsゲームフォルダのそれぞれのファイルのMuZeroConfigクラスを編集することにより、各ゲームの構成を適応させることができます。
出版物でこのリポジトリ(マスターブランチ)を引用したい場合は、このbibtexを使用してください。
@misc{muzero-general,
author = {Werner Duvaud, Aurèle Hainaut},
title = {MuZero General: Open Reimplementation of MuZero},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { u rl{https://github.com/werner-duvaud/muzero-general}},
}

